基于K 均值聚类的非均匀分簇路由算法∗
2019-11-12孙顺远
孙 丽 孙顺远,2
(1.江南大学物联网工程学院 无锡 214122)(2.江南大学轻工过程先进控制教育部重点实验室 无锡 214122)
1 引言
随着无线通信和低功耗嵌入式技术的迅速发展,以低功耗、低成本、分布式和自组织为特点的无线传感器网络(WSN)孕育而生,带来了一场信息技术的变革[1]。现今,WSN已经融入人们的日常生活中,广泛应用在军事、环境、监测、家庭、车辆追踪、交通流量、医疗卫生等诸多领域[2]。WSN在监测区域内分布着大量廉价微型传感器节点,这些节点以无线通信的方式组成多跳自组织网络。所有传感器节点和数据获取单元采集的信号,通过无线通信的方式传输给簇头,簇头将收集到的数据进行聚集和压缩后,最终传输给基站[3]。而基站则通过在整个网络中转发查询信息的方式来请求传感器节点采集数据。当传感器节点发现与查询信息匹配的数据时,路由返回响应消息到基站。通过网络中被选为簇头节点的移植,可以实现网络中能量消耗的最小化。但在整个无线通信过程中,网络也存在着能量消耗过快,储存和计算能力不足的问题。为解决传感器节点过早死亡,能量消耗不均衡以及有效延长网络寿命的问题,提出了许多路由算法,其中低功耗自适应集簇分层型(LEACH)路由协议就是WSN中分簇路由协议的典型代表[4]。
文献[5]改进的LEACH 通信协议在簇建立阶段,采用主副簇头交替策略,减少簇头选择次数,从而减少了每轮进行簇头选择时能量的消耗,同时将初始能量和剩余能量以及主副簇头选择次数作为参数加入到阈值的计算中。文献[6]结合文献[5]在优化阈值计算的基础上,增加了最优簇半径的概念,在控制簇头数量的同时使得簇头节点的位置分布更加合理,均衡了网络能量消耗。文献[7]将节点相对密度加入到阈值的计算中,同时引入全网簇头选择和簇内簇头选择两种方式,有效减少了频繁簇头选择而导致的能量消耗问题。在文献[8]中,针对传统LEACH 协议不适合大规模网络的缺点,提出了采用模拟退火算法确定局部集中式的分簇方法。研究发现,LEACH 协议分为簇建立和数据稳定传输两个阶段。在对LEACH 协议的不断改进中,不管是把节点的初始能量、剩余能量和被选为簇头的次数加入到阈值中,还是引入最优簇半径、相对密度和模拟退火算法,都有效均衡了能量消耗,延长了整个网络的生命周期。但是上述研究都是对簇建立阶段的进一步改进,传输方式仍然是簇头到基站的直接传输。这种传输方式在数据传输过程中不利于距离基站较远的簇头,会使此类簇头因距离太远而消耗过多能量,加速节点的死亡,从而缩短网络寿命。文献[9]HRPNC 采用分层和竞争机制相结合的方式选取簇头,使簇头节点分布更加合理,同时在数据稳定传输阶段文献采用簇内节点单跳和簇间簇头节点多跳的两种方式进行数据传输,进一步减少数据传输过程中的能耗。文献[10]在簇头选择过程中将节点剩余能量和位置分布采用加权和的方法加入到阈值的计算中,同时引入融合节点的概念,将簇头节点的任务重新分配,将数据传输的任务分配给融合节点。在数据传输过程中,提出AF-DK 算法,为数据传输节点找到最优的传输路径。文献[11]提出一种新的能量均衡多跳路由算法,在确保簇头数最优的情况下,簇头选择时加入节点能量和位置分布,同时引入PEGASIS 协议中节点成链思想,将簇头与基站的直接传输方式改成簇头间的多跳路由传输。
LEACH 协议的大部分改进涉及CH 选择的方式[12],而不是在CH 选择阶段选出最优的簇头数。本文对LEACH 协议进行分析,结合K-means算法,提出了一种基于K 均值聚类的非均匀分簇路由算法。该算法在簇头选择之前,根据最优簇头数K,利用K-means算法,将节点分为K 个类(或簇)。同时,在每个簇中根据节点到其他节点的最短距离确定簇头(有线连接),且簇头固定不变,简化了LEACH 协议中的簇建立阶段,有效减少了网络中频繁进行簇头选择和簇建立过程的能量消耗,使得网络生命周期得以延长。
2 LEACH路由协议
LEACH 协议是一种以循环方式随机选择CH,执行簇的重构过程的无线传感器网络分层路由协议,其中节点细节由CH处理。CH收集簇内节点的数据将其压缩并转发到基站(sink)。为了降低能耗,增加网络寿命,LEACH 使用了包含许多迭代的分层方法。每次迭代都包含LEACH 协议的簇建立和稳定数据传输的两个阶段。在簇的建立阶段,根据网络中所需CH的总数和目前为止每个节点被当选为CH 的次数来选择CH 节点,节点被选为CH 的次数越多再被选为CH的概率越小。节点随机选择0~1 的数,如果所选随机数小于阈值T(n),则该节点成为本轮的CH。阈值计算公式如下:

其中:p 为簇头占所有节点的百分比;G 为包含过去1 p 轮中未被选为簇头的节点的集合;r 为当前轮数。
在CH 节点选择完毕后,通过广播告知整个网络所选簇头节点的基本信息,网络中的其他节点根据接收到的信号强度加入相对应的簇,并通知相应的CH,完成簇的建立过程。基于每个簇中的节点数,CH 采用TDMA 方式为每个节点发送时分配一个时隙。如果在当前轮中已经选择了节点作为CH,则阈值T(n)被设置为零。因此,在下一1 p 轮中,节点将不再被选为CH。在基于阈值的方案中,节点建立长距离到达CH,有利CH 将在多轮后不利,从而延长主要节点的使用寿命。在稳态阶段,簇内节点定期收集传感器数据,并将其转发到分配时隙中的CH,CH 将收集到的数据进行聚合,发送给基站。在此过程中给除非节点到了分配的传输时间,否则簇内节点处于关闭状态[13]。
3 LEACH协议改进算法
3.1 最优簇头选择
假设簇内传输阶段很长,所有数据节点都可以将数据发送给它们的CH,并且簇间传输足够长,所有CH都可以将它们的数据发送给基站。在将数据转发到BS 之前,CH 需要进行数据聚合和压缩。根据空间密度函数,求得传感器节点概率最优的被选为CH。
节点发送M 比特数据,距离为l 时的能量消耗为

其中:Eelec表示每比特的能量消耗;εfs和εmp是功率放大器的能量损耗系数;l 为传输距离。lc为传输距离的门限值。lc的计算公式为

节点接收M 比特数据时的能量消耗:

每一轮中CH的能量消耗为
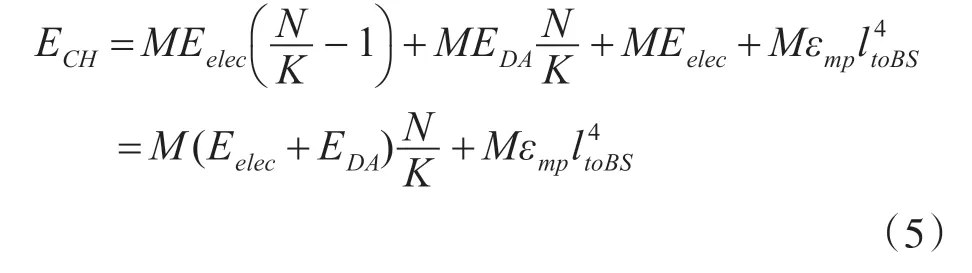
其中,N 为网络的随机分布的节点数;K 为网络的簇头数;EDA为融合每比特数据时的能量。
普通节点的能量消耗为

一个簇中所有节点的能量消耗为

假设在面积为A2的网络区域中随机分布N个传感器节点,簇头节点位于每个簇的中心,则节点密度系数为,考虑节点的非均匀分布:

整个网络的能量消耗为

根据上式可知,网络总能耗是关于簇头数K的函数,根据函数求极限可得:
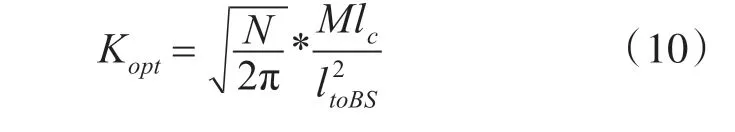
则,一个普通节点成为簇头的最优概率为

3.2 基于K-means算法的非均匀成簇方法
LEACH 协议中簇头采用随机选择的方式,CH数目不确定,过多或过少,都会造成CH节点多余的能量消耗。同时,CH节点位置分布不均匀,也会使得网络中距离基站较远的CH节点因为能量消耗过快而过早死亡。本文根据最优概率算法,计算网络中的最优簇头数K ,然后,基于K 均值聚类算法,将网络中的节点随机分布在K 个簇内,在每个簇中选择靠近类中心的节点作为CH。此时,簇的建立阶段完成,在以后的每一轮中都不在变化,从而减少网络中簇建立过程的能量消耗,有效提高了网络寿命。
其算法非均匀分簇的步骤如下所示:
1)从网络中N 个节点的集合{ x1,x2,…,xN}中随机取K(K ≤N) 个节点,作为K 个初始簇C={C1,C2,…,CK}的各自的初始聚类中心;
2)计算聚类对象的均值(中心对象),根据均值,计算每个对象与这些中心对象的距离;并根据最小距离重新对相应对象进行划分,即对以下表达式求最小值:
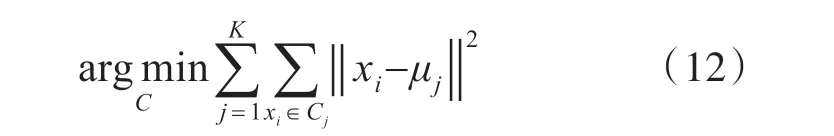
其中,μj表示聚类对象的中心坐标值。
3)根据聚类结果,重新计算每个(有变化)聚类的均值(中心对象),计算方法是取簇中所有元素各自维度的算术平均值;
4)将N个节点按照新的中心重新聚类;
5)循环2)到4)直到每个聚类不再发生变化,得到K 个簇。
3.3 算法描述
//网络初始化
//簇建立过程
Kopt=Cal culate() //计算最优簇头数
Unequal clustering
D=Calculate()//计算节点到聚类中心的距离
t=find()//节点属于第t类
//循环迭代将所有节点分成K个簇中
Election of Cluster-heads
n=find()//根据节点与聚类中心的距离,找出距离聚类中心最近的节点作为CH,n为CH的id
Broadcast()//簇头广播消息给簇内成员
Receive_msg()//节点接收簇头发送的消息
//数据传输过程
SendDatatoCH() //簇内节点发送数据到CH
If(id==id_head)
ReNodeData() //接收簇内节点的数据
SendDatatoBS()
End
4 仿真结果及分析
本文采用Matlab 进行仿真实验。为验证本文算法的优越性,对传统LEACH[14]协议、SEP[15]以及本文新的算法进行仿真,并对实验结果从网络剩余节点数,剩余能量以及网络吞吐量三个方面进行性能对比分析。将100个节点随机分布在100 100的区域中,表1为仿真参数。

表1 仿真参数
图1 表示网络中簇建立后的节点分布图。每个普通节点的初始能量为0.5J,根据最优簇头数,结合K 均值聚类算法将节点分成5个簇,分别用不同颜色表示,每个簇中距离聚类中心最近的节点为CH,CH 采用有线连接,在整个仿真过程中固定不变。

图1 簇中节点分布
通过对LEACH 协议、SEP 协议以及本文算法的网络生命周期的分析,研究随着网络中仿真轮数的增加,剩余节点的数量变化。在图2 中,所提出的算法的第一个死亡节点要比另外两个协议提高约900 轮,而在1400 轮本文算法的死亡节点约为10 个,从图中清晰地看出本文算法的网络寿命比现有协议明显改善。并且在整个网络的生命周期结束前保证整个网络基本具有相同的规模,有效地提高了网络稳定性。

图2 剩余节点数
图3 表示网络中随着仿真轮数的不断增加剩余能量的变化曲线。图中SEP 协议由于存在高级和普通两种节点,所以能量是高于LEACH 协议的,而本文算法中,由于假定CH节点能量无限,因此只考虑普通节点的剩余能量。仿真发现,LEACH 和SEP 协议的剩余能量相差不是很大,SEP 协议的剩余能量略高于LEACH 协议,而本文算法的剩余能量明显高于LEACH 和SEP,相应的网络寿命也大大长于两者。这主要因为本文算法提前完成簇的建立,并在此后的每一轮中不在更改,有效减少了网络不断进行簇头选择和簇建立消耗的能量,提高了网络生命周期。

图3 剩余能量
5 结语
本文根据K 均值聚类算法,利用最优簇头数,将随机分布在网络中的节点分成几个簇,并将距离聚类中心最近的节点作为簇头,此后每一轮簇保持不变,简化LEACH 协议的簇建立阶段,有效减少了网络不断进行簇头选择和簇建立的能量消耗。仿真结果表明,本文算法比传统LEACH 协议、SEP 协议优势更加显著,使簇头数目和位置分布更加合理,节点死亡数和传输过程中的能量消耗大大减少,有效延长了网络寿命。
