基于Spark 的大规模单图频繁子图算法
2019-11-12蒋来好朱志祥赵子晨
蒋来好 朱志祥 赵子晨
(1.西安邮电大学计算机学院 西安 710061)(2.陕西省信息化工程研究院 西安 710061)
1 引言
教育信息化、网络化是高校现代化的必经之路。随着校园卡存储事物的繁琐及工作量的增加,进而保存在服务器中的数据量正以惊人的速度增长,因此服务器的负担也随之加大,而作为管理者们期望从这些庞大的数据中获取有用的信息。目前,校园一卡通的数据挖掘[1]越来越被重视,但对消费流水数据的深入研究则不多见,主要因为针对大规模的消费流水数据没有合适的处理算法[2],频繁轨迹挖掘和频繁子图的研究也主要针对于社交网络,但发现学生频繁消费行为特征[3]、解决学生人际关系问题,以及预防恶劣事件的发生,不仅对构建和谐校园环境有着十分重要的作用,也给一卡通建设提供了可参照的标准。
目前频繁子图的研究主要集中在图集的研究,像社交网络或万维网链接图等,应用于校园卡消费数据的研究则不多见,而单图数据并不适合被划分为图集再操作,主要因为大规模单图的顶点数量经常在百万级别以上,远超图集中的单个图,这样最后得到的频繁模式子[4~6]图规模也远比图集上大。不仅在支持度计算比图集要复杂,在子图同构中进行测试时也要消耗更多的时间。频繁子图挖掘问题的核心实质是顶点的单图挖掘,针对单图频繁子图的挖掘已有文献[7~9],2014 年提出GRAMI 算法[9]模型将难点转为限制约束问题,该算法在单机频繁子图挖掘中的效果最好。但是GRAMI算法是单机算法,面对大规模图的运行效率较低,也无法在支持度较低的频繁子图中挖掘。现分布式环境[10~13]下的单图频繁子图挖掘算法[14~16],都针对于有向图且需要指定子图顶点个数k,不能支持子图增长模式的挖掘,针对图集的其他分布式频繁子图挖掘算法[17]大多是基于MapReduce 框架[18],Spark框架非常适合迭代计算模型,对比MapReduce无需要多次读写磁盘,也不会造成大量的IO 及序列化和反序列化的开销。基于上述问题,本文提出如下算法:
1)提出基于密度聚类的DP-DBSCAN 数据转化算法,将我校一卡通数据转化为频繁子图的准备数据集。
2)基于次优树按照广度优方法搜索生成候选子图的方法将大规模单图并行化,提出了基于Spark[19~20]的频繁子图挖掘架构。
3)提出分布式大规模单图的频繁子图挖掘算法FSMBUS。
2 频繁子图的基本定义
定义1 子图和子图同构:给定一个图G=(V ,E,L ),其中V 和E 分别表示顶点和边的集合,L 是关于顶点和边的标签映射函数,现有一个图S 其中S=(VS,ES,LS),当且仅当VS⊆V,ES⊆E,LS(υ)=L(υ),对于每一个v ∈VS∪ES都成立时,则称S 是G 的一个子图。 S 与G 的子图同构,即存在一个映射函数:f:VS→V ,函数满足:
1)∀υ∈VS,LS(υ)=L(f(υ));
2)∀(u,υ)∈ES;(f(u),f(υ))∈E
并且LS(u,υ)=L(f(u),f(v)),其中f 是一个单映射函数,称S 在G 中的一个嵌入。
定义2 频繁子图:给定一个图G 和一个最小支持度τ ,Sup(G,S)表示子图S 在G 中属于同构图的计数,当Sup(G,S)≥τ 时S 为G 的一个频S=(VS,ES,LS)繁子图。
定义3 MNI 支持度:f 为子图在G 中的同构映射集合,f 集合的长度为m,同时为f 集合上每一个υ 去重之后的映射函数,其中υ ∈VS,则其MNI支持度计算方式表示为

定 义 4CSP 模 型 s=(VS,ES,LS) 为G=(V,E,L)的一个子图,在G 中查找子图S 的同构用CSP( X,D,C )模型来表示:
1)X 所包含的变量xi表示VS中的各个顶点υ;
2)D 是各个xi∈X 数据域的集合,每个数据域都是V 的一个子集;
3)C 表示有如下约束条件:
(1)xi1≠xi2,表示在同一个同构映射中顶点最多被分配一次,即要保证顶点的不重复性;
(2)L(xi)=LS(υ),表示所分配的顶点标签一定要与子图的标签一一对应,即顶点一致性;
(3)L(xi1,xi2)=Ls(υ1,υ2)表示被分配的顶点之间边的标签应与子图边标签相互对应,即为弧一致性;
定理1子图S 中任意一个有效分配对应G 的CSP模型,即S 是G 中的子图同构。
有效分配的意思是指在CSP 模型中满足条件C 的约束,如图1(b)在图1(a)中的一个有效分配为(v1,v2,v3) ={u0,u1,u3} ,因为u0,u1,u3的顶点ID互不相同,顶点标签(IE,DB,IR)与边标签(12,4)也刚好与图1(b)一一对应。而图1(a)中这3 个顶点u0,u1,u3组成的的图正好为图1(b)的同构。
根据定义4 和定理1 可推出,通过使用CSP 模型在候选子图拓扑结构中,由约束条件寻找真实图中的同构映射。将图1(b)在图1(a)中进行的频繁子图查找转变成CSP模型为

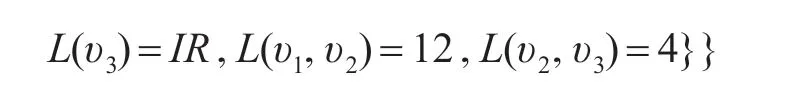
再根据约束条件在数据域中寻找其对应的有效 分 配 为{u0,u1,u3},{u7,u6,u5},{u7,u6,u8},即 同 构映射,然后再由MNI支持度的计算值判断该候选子图是否为频繁子图。
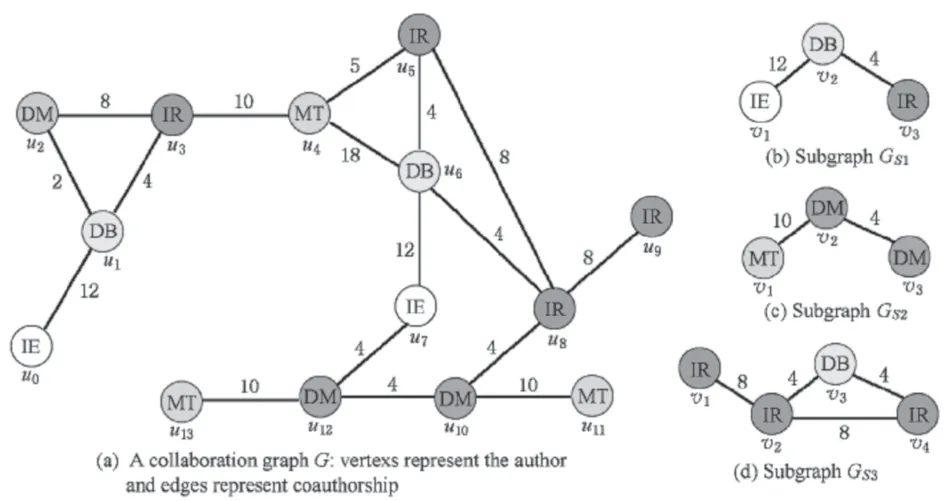
图1 合作网络图样例
3 候选子图的生长
次优树是FFSM 算法[20]提出的一种高效的候选子图生长策略,邻接矩阵M 存储每个图,其对角线存储顶点标签,非对角线存储顶点与顶点相连边的标签。
定义5标准的邻接矩阵CAM:给定一个n×n的邻接矩阵M 表示有n 个顶点的图G,定义M 的编码为该矩阵中包括对角线的下三角,并按顺序m1,1m2,1m2,2…mm,1,mm,2…mn,n-1mn,n构 成 的 序 列,记为code(M) ,按字典序比较得到max(code(M))称为标准编码,对应的矩阵称为标准邻接矩阵。
定义6次优树:如果图G矩阵M 的极大子矩阵是另一个图的标准邻接矩阵时,则称该矩阵M是次优邻接矩阵,记作次优CAM,其中每个CAM同时又是下一个次优CAM,由次优CAM 构成的树就叫作次优树。
给定2个次优邻接矩阵M 和N ,通过M 与N的连接操作生成新矩阵称之为FFSM-JOIN[20],M或N 扩展频繁边生成新矩阵称FFSM-Extension[20]。现以空为根节点,频繁边为第1层叶子,第2层叶子节点是次优邻接矩阵由频繁边通过上述两大算子生成,同理依次不断迭代上述过程,就可以生成当前层的下一层次优树,这样就能枚举出不会重复的候选子图。图1(d)在生长过程中形成的次优树为图2,图2 的树根节点为空其他节点代表图1(d)的一个子图。其中白色背景的为CAM,灰色背景的为次优CAM,通过当前的父节点FFSM-JOIN或FFSM-Extension算子生成下一层节点。
4 频繁子图挖掘算法
FSMBUS 算法是在Spark 框架下,以迭代式RDD 设计的一种分布式算法。通过使用次优树作为候选子图的生长策略,将候选子图边数作为第二次迭代的增量。在图2 的次优树中我们可以发现:在计算支持度时直接影响孩子节点的是确定当前候选子图是否频繁,树每层边的数量与支持的计算互不影响。如图3 所示是FSMBUS 的流程框架,其中主要包含数据预处理和数据挖掘阶段。数据挖掘是算法的核心部分,按广度搜索进行次优树的生长,并行计算每一层中CAM 的候选子图是否频繁。如果是非频繁,剪枝其候选子图然后继续生长次优树开始下一次的迭代。第i 次迭代生成边数为i+2 的频繁子图并且作为第i+1次迭代的输入,一直到候选子图全部为非频繁时迭代结束。算法主要解决了两大难点,一个是候选搜索数据域的构建另一个是支持度的计算。
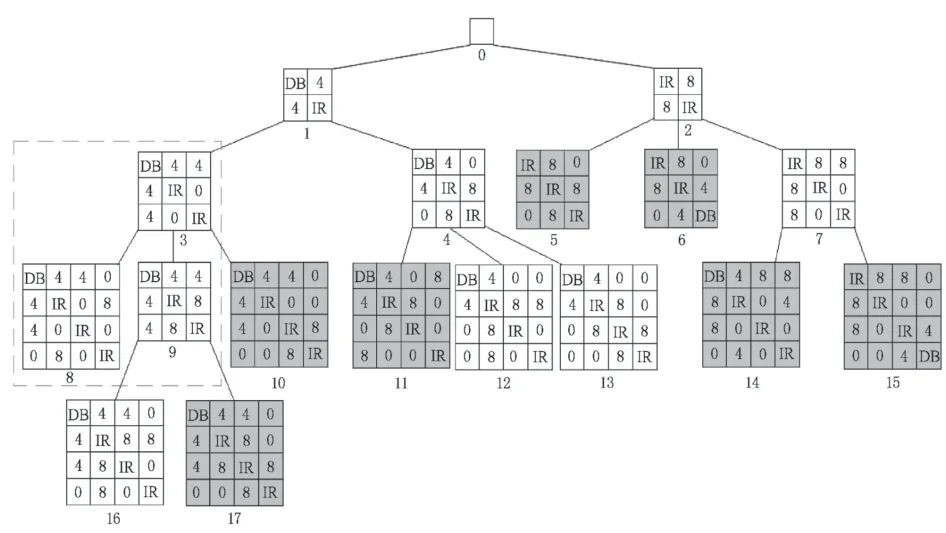
图2 次优树
4.1 数据预处理
一卡通流水数据的分布紧密情况和上下课时间直接相关,为得到学生一起消费的频繁子图,提出基于密度聚类的DP-DBSCAN数据转化算法。
给定数据集D=D1+D2+…Dn,Dn表示第n天的数据集,所有对象标记为“unvisited”,从D1开始选择第一条消费轨迹点v0=x0( y0,t0),标记为“visited”,并按消费顺序检查v0的ε 邻域中是否为空,如果不是,创建一棵以x0为根结点的B+树,并对ε 邻域中包含的所有对象xi( i =0…n )按树的结构存储到集合N ,否则选择下一个未访问对象。N 中标记为“unvisited”的对象改为“visited”,并检查该ε 邻域,如果是非空,则ε 邻域中的所有对象都被插入到当前叶结点的下一层,依次检查当前叶结点,迭代N 中所有未访问对象,直到N 不再变化时提取B+树的每个分支,生成FP 树的时空轨迹序列。对剩下未访问的对象,生成过程继续,直到所有对象被访问结束循环下一个数据集。算法伪代码如下所示。
算法:数据转换算法DP-DBSCAN输入:
·D:一个包含n个对象的数据集
·Di:按天划分的小数据集
·ε:度量方法—欧氏距离
输出:轨迹树表集
方法:
① 标记所有对象为unvisited;
② do
③ for D 中每个Di
④ 按顺序选择一个unvisited对象vi=xi(yi,ti) ;
⑤ 标记vi为visited
⑥ if vi的ε 邻域内非空
⑦ 以xi为根结点创建一颗B+树;
⑧ 令N 为vi的ε 邻域中的对象集合;
⑨ for N 中每个叶结点vi
⑩if vi为unvisited
⑪ 标记vi为visited;
⑫ if vi的ε 邻域非空,邻域内所有对象对应的xi插入到当前叶结点的下一层;
⑬ end for
⑭ 提取B+树的每条分支,生成FP 树的时空轨迹序列:
⑮ else按顺序访问下一个未访问对象
⑯ end for
⑰ 输出Di的所有时空轨迹序列集;
⑱ until 没有标记为unvisited的对象;
DBSCAN 的核心是利用满足设定条件时不断迭代的原理发现任意簇,而DP-DBSCAN 则是借其思想设计出在相邻时间地点一起消费的轨迹序列。当满足在ε 值范围内(即相邻的消费时间和地点),则生成一次一起消费的记录。该算法按天分块、流水顺序查询,依据欧氏距离划分,B+树存储,通过提取每条分支得到在相邻时间、地点一起消费的n条学生id轨迹序列:
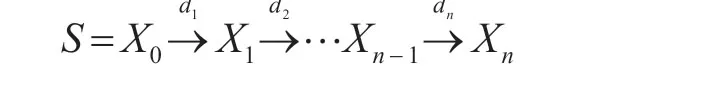
S 表示一条时空属性关系标签的轨迹序列,Xn表示经过累计卡次降序排序后带有关系标签的id-学生证号,dn是按顺序从1…n 依次添加的关系标签值,用来描述具体消费关系的亲密指数,当dn<4时称两节点间属闺蜜关系,4 ≤dn<8 为饭友,8 ≤dn≤12 为同学,其他情况不做标记表示陌生。
按起始标签为srcLabel,边标签为attr,目标标签为dstLabel 的三元组格式进行存储,由MNI 支持度策略过滤掉非频繁边,次优树中的第一层频繁子图是频繁边,频繁边两端对应的顶点映射存储在频繁边RDD,而这些顶点映射就是CSP模型中的有效分配。图3 是挖掘阶段,因此需要先初始化一个当前频繁子图RDD 作为挖掘阶段的初始输入,然后每次迭代当前父级频繁子图的RDD。在准备阶段中,频繁边RDD 转换成当前的频繁子图数据集,即频繁边,Di存储对应变量中有效分配顶点,同时Di的各个顶点也会存储候选子图上相邻顶点的索引位置及其ID。
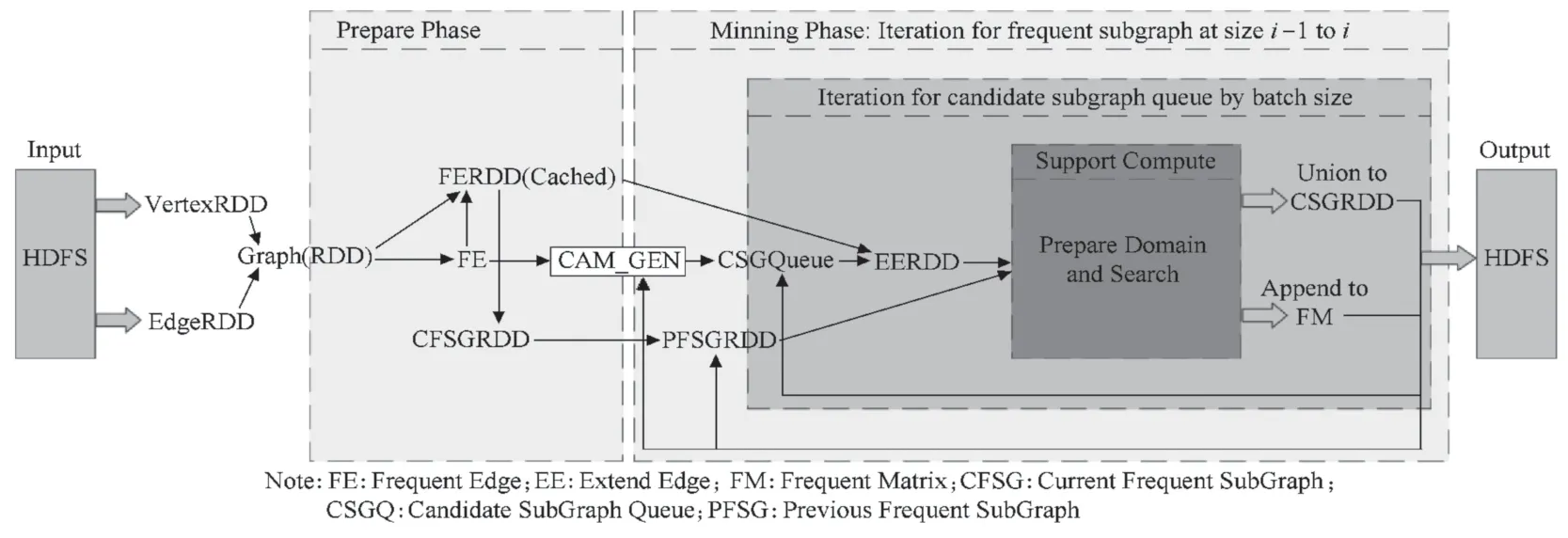
图3 FSMBUS算法的流程框架图
Domain 的结构如图4(a)所示,表示一个候选子图的结构,每个候选子图中含有k 个顶点,Vx表示D1中的有效分配顶点,{k-2 →{υy}}表示D1的υx与Dk-2的υy相连,在Dk-2上会对称的存在与D1相连的信息,所以该算法可以应用在无向图的挖掘中。将Domain 的结构对应图4(b),可以得到u1和u3,u6和u5,u6和u8分别都有边相连,与传统的存储结构相比,该结构可以直接计算候选子图的支持度。

图4 Domain存储结构
4.2 数据挖掘阶段
数据挖掘阶段是通过迭代的方式实现候选子图的生成、候选搜索数据域的构建以及支持度的计算,即该过程是计算出所有频繁子图。
定义7 外/内边:在子图生长的过程中,如果扩展边需要引入新顶点,则称该扩展边E 为外边,否则为内边。
步骤1 候选子图的生成:第i 次迭代由第i-1次迭代产生的频繁子图进行FFSM-Join 和FFSM-Extend 后产生候选子图,而FFSM-Join 和FFSM-Extend 算子生成的新候选子图,其实质都是在父级子图上添加一条边,因此都称之为扩展边。对于产生的新候选子图的数据结构,除了自身的拓扑结构外还包含其父级子图的ID 号和对应该子图的扩展边,而候选搜索数据域就基于以上2 个数据构建。
步骤2 构建候选搜索数据域:在计算支持度之前应先取得当前候选子图所对应的顶点数据,称为候选搜索数据域,使用Domain 结构存储。FSMBUS 是通过使用增量的方式得到对应的CD,每一个候选子图都包含父级子图IDK 信息和它的扩展边信息,连接扩展边对应的父级子图的有效分配数据,即当前后选子图的CD。
步骤3 支持度计算:频繁子图挖掘的核心是支持度的计算,该过程需要进行子图NP 完全问题的同构测试,FSMBUS 通过启发式方法对候选搜索数据域进行支持度的搜索计算,其伪代码如下:
算法1 支持度计算IsFrequent(D,τ)
输入:D 表示当前候选子图的数据域,τ 表示最小支持度;
输出:当候选子图的支持度大于τ 时返回true,否则false.
①val solDomain,nonCandidateMap;/分别存储有效和无效的分配项/
②val search IndexOrder=getOrder(D);/获取搜索顺序/
③for each i in seachIndexOrder
④ if CheckFrequnet(solDomain)return true;
⑤ for each υ in D(i);/使用回朔的方法进行有效分配搜索/
⑥ If υ 包含在solDomain(i)中
⑦Go to next υ;
⑧Instance=SearchBackTraking(υ);/回溯法的有效分配搜索/
⑨ If instance=empty
⑩nonCandidateMap(i),add(υ);
⑪ If D(i),size-nonCandidateMap(i),
⑫ Size <τ return false;
⑬ else
⑭ solDomain(i),add(instance)
⑮ If solDomain(i),size ≥τ go to next i;
⑯ If solDomain(i),size ≤τ return false
⑰ If checkFrequen(tsolDomain)return true;
⑱return true.
在计算支持度时依次遍历变量X 的数据域,通过构建深度优先的搜索路径,进行有效分配的搜索,直至MNI支持度大于τ 或者当前变量的有效分配,与剩余候选项个数之和小于τ 时停止。在算法1 中,行③~⑤是遍历数据域,行⑦是有效分配的搜索,行⑧~⑮是剪枝过程中频繁条件的判断。最后的计算结果如果是频繁子图,将会根据non-CandidateMap 搜索整个数据域进行剪枝,其目的是为了减少候选子图的搜索空间及RDD的存储空间。
FSMBUS算法伪代码:
算法2 FSMBUS(v_path,e_path)
输入:v_path 表示输入图顶点,e_path 表示边的文件存储路径,τ 表示最小支持度;
输出:S 为返回的频繁子图的集合。
①val G=Graph(v_path,e_path);
②val FE=G,groupby.filter.map.filter.filter.collect;/检测频繁边/
③val FERDD=(G,FE),fliter.flatMap.groupby.collect;/获取频繁边的信息/
④val CFGRDD=FERDD.map.cache;/初始化频繁边/
⑤val matrixMap=Cam_Init(ConnectSplit(FE)); /将频繁边分割并转为矩阵/
⑥while matrixMap.size>0
⑦S,union(matrixMap.matrix);/添加频繁子图/
⑧matrixMap=Cam_Gener(matrixMap);
/使用CamCode进行连接和扩展/
⑨val candidateSubGQueue=matrixMap
.enqueue;/形成候选子图队列/
⑩val PFSGRDD=CFSGRDD;
⑪ while candidateSubGQueue.size>0
⑫ val batchFreqSubGRDD=sc,Parallelize(candidateSubGQueue.dequeue(batch-Size))
⑬ .join(FERDD).map.join(PFSGRDD).map{
⑭ D=Domain_Construct(); /候选子图候选数据域构建/
⑮ InFrequent_detect();/非频繁检测/
⑯ IsFrequent(D,τ);}/支持度计算(算法1)/
⑰ if batchFreqSubGRDD.count>0
⑱ matrixMap.add(batchFreqSub-GRDD,matrix);
⑲ CFSGRDD.union(batchFreqSub-GRDD);
⑳ return S
行①~⑤是数据准备阶段,行⑥~⑲是最核心的数据挖掘部分,行⑮是非频繁检测优化,行②是在算法1 中的搜索顺序选择。行⑨~⑫可以看出FSMBUS 是先将候选子图压入队列,然后再批量取出计算,主要因为存储候选子图的Domain 数据需要消耗很大空间,很容易造成集群内存溢出,所以不会一次性将所有候选子图同时并行计算,而是采用队列的形式批处理。通过控制参数BatchSize 可以有效地解决内存溢出问题,这说明FSMBUS具有良好的鲁棒性。
5 实验结果与分析
实验用的是普通PC 机,FSMBUS 使用Scala2.10.4 进行开发,集群环境为Spark1.2.0,运行的模式为Spark On Yarn,其中Yarn 对应的Hadoop 版本为2.2.0,所有节点均使用普通PC机,运行时的通用参数driver-memory 为6GB,executor-memory 为6GB。
YikaTong:我校最近几年的一卡通数据经DP-DBSCAN 算法转换后的学生一起消费轨迹集。顶点的标签为我校一卡通学生id,边表示2 个学生之间存在一起消费关系,边的标签为2 个学生之间消费亲密程度是闺蜜、饭友,还是同学。为了对比海量数据处理在分布式平台上的显著性,以及频繁子图挖掘算法FSMBUS 的优越性,增加两个数据集Twitter 和PldWeb 进行更全面的实验对比分析。实验数据集描述如表1所示。

表1 实验数据集描述
为了评估FSMBUS 的性能,实验部分选择与下列算法进行对比:
1)GRAMI:文献[7]提出的算法,它为单机环境下的算法。
2)FSMBUS-H:本文提出的FSMBUS 算法在Hadoop2.2.0环境下实现,FSMBUS-H算法使用迭代式的MapReduce进行挖掘,利用HDFS进行数据共享。
3)NAVFSM:因为目前还没有在分布式下的单图处理方法,所以本文通过用暴力的枚举方式,提出基于Spark平台的朴素单图上的分布式频繁子图算法。
FSMBUS 算法与GRAMI、FSMBUS-H、NAVFSM 算法的对比实验结果如图5~7所示。在相同最小支持度下FSMBUS算法的运行时间最少,最快是GRAMI 算 法 的20 倍;FSMBUS 算 法 的 性 能 最 高,FSMBUS-H 性能次之,主要是因为在运行时需要多次从HDFS 读写数据,但是在PldWeb 数据集上支持度在110000 时FSMBUS-H 性能超过了FSMBUS,这是由于Spark 内存不足时要进行磁盘的溢写和垃圾回收;在超大规模的PldWeb 数据集上会出现OOM 异常,基本无法正常运行。
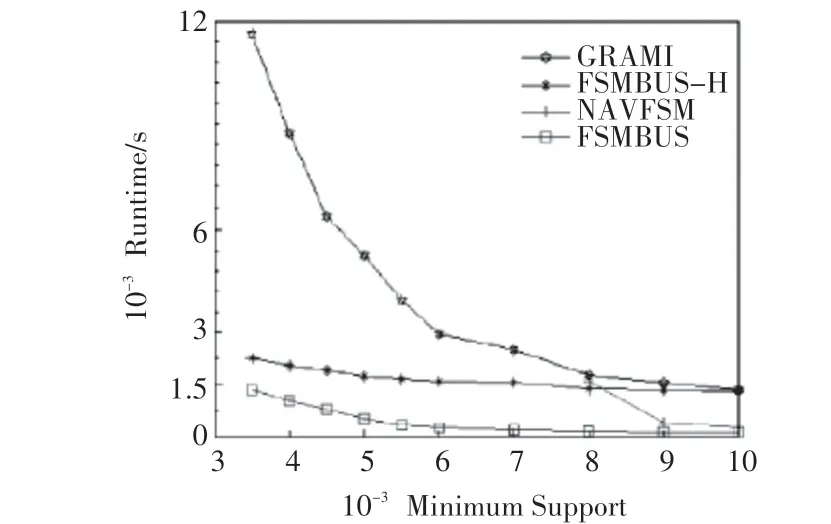
图5 YiKaTong数据集
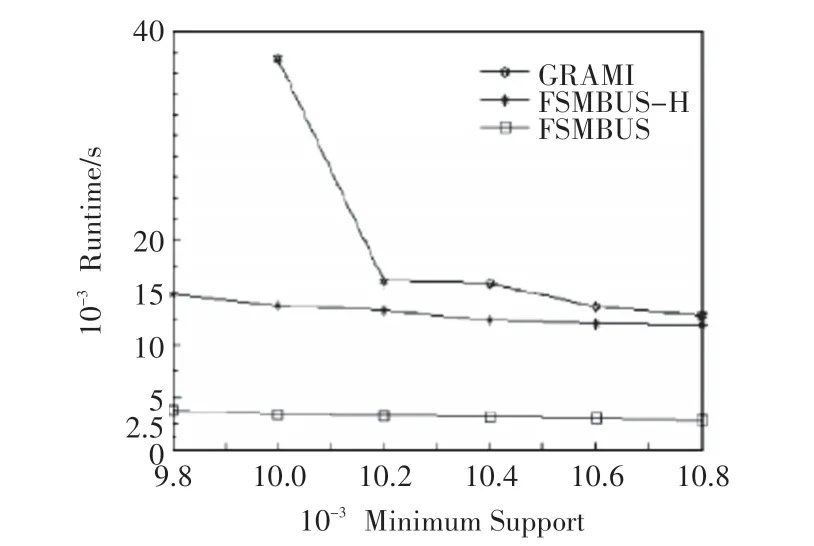
图6 Twitter数据集
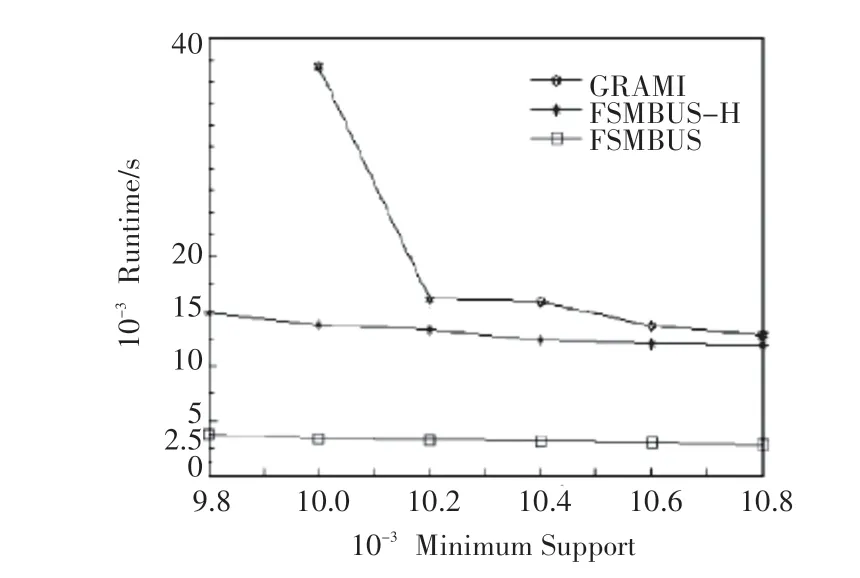
图7 PldWeb数据集
根据上述实验结果分析可以得出以下结论:
1)FSMBUS 算法与GRAMI 相比,可以支承更低的支持度和更大的数据集,在相同的数据集下运算速度是GRAMI 3~20倍,主要因为FSMBUS是运行在Spark 的分布式算法,可以并行运算最耗时的支持度,每次迭代结果存储在内存中,只有当内存不足时才将数据溢写到本地磁盘。同时FSMBUS在计算支持度前会先优化候选子图的非频繁检测来减少非频繁子图的搜索;通过本文提出的数据结构,在搜索时减少了CSP 约束的判断次数,支持更低支持度阈值的计算。
2)对比Hadoop 环境,Spark 基于内存运算,在内存足够的情况下除了输入输出外不会频繁读写HDFS 而产生额外的开销,通过DAG 的作业执行和RDD间的相互依赖,可高效地处理FSMBUS的迭代式算法任务。
3)根据本文提出的FSMBUS 算法,选定关系度范围值是同学、饭友、闺蜜的三种类别,如图8 是该算法部分放大后的结果图。通过改变支持度分析图形的边缘点进而发现孤立消费人群,图节点边数较多的同学可作为评选班级干部时考虑其交际能力的一个依据,同时也可以通过输入关系度范围帮助用户发现未来可能会认识的消费人群。
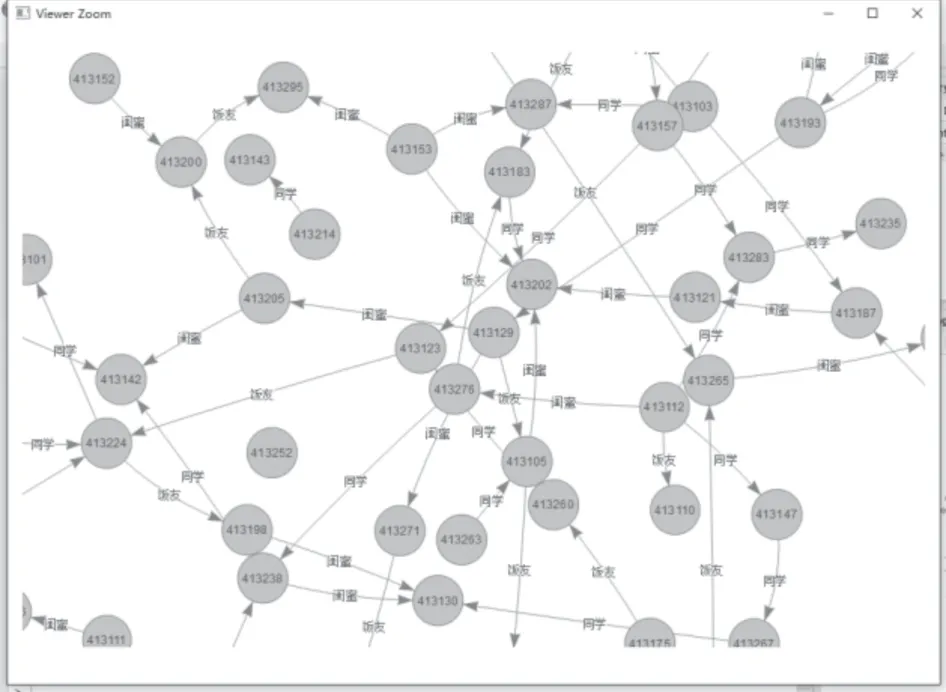
图8 学生频繁消费关系子图
6 结语
本文提出了一种基于Spark的分布式并行单图上的频繁子图挖掘算法FSMBUS,候选子图的生长是根据次优树按广度优先的方式增长,并行计算候选子图的支持度,通过迭代的RDD 挖掘大规模单图频繁子图。实验表明FSMBUS 算法不仅能支持更低的支持度和更大规模的数据集,还比在Hadoop平台上的运行效率高2~4 倍。将该算法应用与我校一卡通消费数据,分析学生频繁消费关系轨迹图,通过调整支持度进一步研究孤立消费人群。同时该算法也可以扩展应用在社交网络上的频繁子图挖掘,跟据挖掘结果帮助企业决策提出可靠的依据。
