回归与矩阵分解的业务过程时间预测算法
2019-11-11李帅标赵海燕陈庆奎
李帅标,赵海燕,陈庆奎,曹 健
1(上海理工大学 光电信息与计算机工程学院 上海市现代光学系统重点实验室 光学仪器与系统教育部工程研究中心,上海 200093) 2(上海交通大学 计算机科学与技术系,上海 200030)E-mail:2609215537@qq.com
1 引 言
为了在这个竞争激烈的社会环境中生存,企业必须实现高效的工作流程.时间作为业务流程中的重要因素,在近几年得到了越来越多的关注,企业对时间方面的要求也越来越苛刻[1].幸运的是,在信息技术快速发展的前提下,越来越多的企业正在使用业务流程信息系统(Process-Aware Information Systems,PAISs)来支持他们的业务[2].系统将业务流程执行的踪迹和已执行活动的信息或属性记录在称为事件日志的文件中,使企业积累大量数据信息.近些年来,很多学者开始研究如何对业务过程的执行时间进行预测的问题.
对具有复杂性和灵活性的业务过程来说,准确的时间预测并不容易,因为其执行方案和性能随时间会发生变化,所以准确的预测结果取决于当前活动上下文环境[3].上下文环境对预测的结果和精确度有很大的影响,如时间、位置以及场景等信息.例如,对于快递业务而言,即使运送的路线相同,也会因为不同的季节导致的交通状况不同从而使得时间具有很大差别.因此考虑上下文环境对业务过程进行时间预测是极其重要的.
近年来,矩阵分解算法(Matrix Factorization,MF)的应用越来越广泛,传统矩阵分解技术主要包括奇异值分解(Singular Value Decomposition,SVD)[4]、非负矩阵分解(Non-negative Matrix Factorization,NMF)[5]和概率矩阵分解(Probabilistic Matrix Factorization,PMF)[6]等.上述模型的共同特性是将高维矩阵转换为多个低维矩阵乘积来达到降维的目的,其中以概率矩阵分解应用最为广泛[7].基于矩阵分解的算法是假设最终结果受到多个隐特征的影响,通过隐特征空间将用户与物品联系起来.又因存在的隐特征无法准确的归纳为某些具体特征,故矩阵分解模型也被称为隐语义模型.因此,在假设结果受到隐特征或不可列举因子影响的前提下,我们结合矩阵分解思想提出一种基于回归与联合概率矩阵分解(Regression and Collective Probabilistic Matrix Factorization,RCPMF)的算法用于业务过程时间的预测.在该算法中,对于可观测的特征部分,我们使用回归模型进行学习;对于不可观测的特征部分(隐因子或潜在特征),我们使用联合概率矩阵分解模型进行学习;最后将两部分的结果相结合作为最终的预测结果.
2 相关工作
目前很多学者在对业务过程时间方面进行预测时都考虑了上下文环境因素,其实验结果表明考虑上下文信息对预测效果有积极影响[12].
文献[8]中,Polato等人使用了一种ε-SVR机器学习算法对业务过程进行剩余执行时间的预测.该方法使用业务过程的历史踪迹活动属性信息训练ε-SVR模型,并通过编码技术将部分踪迹的特征转换为适合模型输入的格式,输出的值即为估计的剩余执行时间.文献[9,10]中,Folino等人根据上下文特征对日志踪迹进行聚类,然后,对于每个聚类创建剩余活动时间预测模型.为了对新的业务过程进行预测,首先根据其特征将其聚类,然后使用属于特定集群的模型进行预测.在文献[11]中,作者利用事件日志的上下文信息生成决策树用来发现业务流程特征之间相关性.并在此基础上想对业务过程剩余时间进行预测.由于决策树需要将数值离散化,降低了方法准确性,故作者没有提供相关的预测示例.在文献[12]中,Polato等人考虑事件的附加属性以改进时间预测质量.该方法利用了在标记变迁系统(An Annotated Transition System)添加朴素贝叶斯分类器和支持向量回归器的想法,实验结果表明考虑附加属性能够对预测结果产生积极影响.另外,Leitner 等人[13]根据记录的历史数据,使用WEKA 机器学习框架来构建回归模型.对于正在运行的业务过程,将可用的特征信息输入预测回归模型,输出服务水平协议(Service Level Agreement,SLA)值,即时间预测值.通过与规定的SLA值比较判断该业务过程是否会超时.
以上是对业务过程活动时间方面的相关预测方法的介绍,上述方法虽然考虑活动的附加属性,但没有考虑业务过程受到了许多因素的影响,虽然有些因素是明确的,但是还有许多难以明确建模的隐因素对业务过程时间具有很大的影响.针对这一特点,我们将回归模型与联合概率矩阵分解模型应用于业务过程活动的时间预测.实验结果表明,该算法考虑了更多的上下文环境特征,具有更高的预测精度.
3 基于回归与联合概率矩阵分解的业务过程时间预测算法
3.1 算法思想介绍
本文所提出的算法是为了解决在不同上下文环境下可观测特征与不可观测特征对结果有所影响的问题.该算法不只是局限于某种特定的上下文环境,其上下文环境可根据具体的业务过程背景有所不同,例如时间上下文或位置上下文等,故该算法在一定程度上满足灵活性与通用性.
该算法假设结果受到可观测特征与不可观测特征的影响,在确定上下文环境类型后,对于可观测特征部分,使用回归模型进行学习,对于不可观测特征部分,使用联合概率矩阵分解进行学习.
3.2 问题的定义
为了方便进行形式化描述,本文所使用的符号标记如表1所示.

表1 符号表Table 1 Notations
表1中US表示不同隐特征矩阵所对应的用户数目集合,E表示不同用户隐特征矩阵与物品隐特征矩阵的时间偏差矩阵集合.
3.3 概率矩阵分解模型
目前,以概率方式预测用户对物品的喜爱程度的矩阵分解模型被大部分的研究人员使用.在本文中,我们使用概率矩阵分解的思想预测业务活动的时间偏差.在假设用户隐特征向量、物品隐特征向量以及活动时间偏差服从高斯分布的前提下,首先利用贝叶斯公式推导用户隐特征向量与物品隐特征向量的后验概率,然后利用随机梯度下降法(Stochastic Gradient Descent,SGD)进行求导[14].
已知时间偏差数据的条件概率分布函数如公式(1)所示.式中U表示n=1时,U的用户隐特征矩阵集合,即U=U1;E表示n=1时,E的时间偏差矩阵集合,即E=E1:
(1)

(2)
(3)
根据贝叶斯推理,隐特征向量U和V的后验概率分布函数:
(4)
根据公式(4),通过用户物品时间偏差矩阵,我们能够学习用户和物品的隐特征向量,相应的概率模型图如图1所示.
3.4 RCPMF模型框架
本文提出一种回归与联合概率矩阵分解的业务过程时间预测算法,该算法主要有以下几个部分组成:
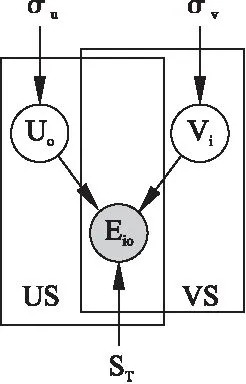
图1 概率矩阵分解图模型Fig.1 Graph model for probabilistic matrix factorization
1)获取可观测特征.根据已有的事件日志文件,通过数据预处理、特征筛选、特征提取等步骤获取对时间有影响的活动特征.
2)求取时间偏差.根据可观测特征,使用普通最小二乘法求取最优的回归系数,通过回归模型预测活动执行时间,最后将预测时间与活动真实执行时间之差作为回归模型预测所产生的时间偏差.
3)学习隐特征矩阵.在假设时间偏差受到不同隐特征矩阵影响的前提下,将时间偏差矩阵集合E中不同的偏差矩阵融入到概率矩阵分解中,将最大化联合后验概率设定为目标函数,通过随机梯度下降算法学习最优的用户隐特征矩阵集合与物品隐特征矩阵集合.
4)预测时间偏差.根据不同部分的用户隐特征矩阵和物品隐特征矩阵计算得到在其对应部分所预测的时间偏差.
5)业务活动持续时间预测结果.将回归模型预测时间与联合概率矩阵分解预测不同部分的时间偏差相结合作为最终的时间预测结果.
3.4.1 回归模型
本文所使用的回归模型为线性回归模型,我们假设在回归模型中所使用的上下文特征已经消除特征多重共线性,线性回归表示每个特征对整体预测结果所做的贡献,通过加权求和的方式预测最终结果.假定输人特征数据存放在矩阵Χ中,而回归系数存放在向量w中,通过利用平方误差求出向量w使得预测时间值和真实时间y值之间的差值最小.平方误差公式如下:
(5)

图2 联合概率矩阵分解图模型Fig.2 Graph model of collective probabilistic matrix factorization
通过对(5)式使用普通最小二乘法(ordinary least squares)即可求出最优系数向量.
3.4.2 联合概率矩阵分解模型
在不确定上下文环境时,我们不知道其结果受到多少种因素或场景的影响,因此将影响因素数目或场景数目设置为n,场景集合S={S1,S2,…,Sn},故所提出的联合概率矩阵分解部分的图模型如图2所示.
根据模型得用户数目集合US={US1,US2…USn},用户隐特征矩阵集合U={U1,U2,…,Un},时间偏差矩阵集合E={E1,E2,…,En}.为了便于理解推导过程,在此处将影响结果的场景数目设置为2进行推导,即S={S1,S2}.
联合概率矩阵分解图模型基于以下假设:
1)假设物品隐特征矩阵Vi,场景S1中用户隐特征矩阵U1的先验概率服从高斯分布且相互独立,则满足下列公式.
(6)
(7)
其中N(x|μ,σ2)表示均值为μ,方差为σ2的高斯分布概率密度函数,I为单位矩阵.同理可得场景S2中用户隐特征矩阵U2满足公式(8).
成分不同,安全剂量不同。对乙酰氨基酚的日常最大用量为每4小时1次,每次15mg/kg,如孩子体重超过44千克,可参考成人剂量1000mg/次或4000mg/日。布洛芬的日常最大用量为每6小时1次,每次10mg/kg,如孩子体重超过44千克,可参考成人剂量600mg/次或2400mg/日。
(8)

(9)

(10)
用户与物品之间存在的时间偏差受不同场景的影响,所以联合概率矩阵分解部分将不同场景中用户与物品的关系矩阵的分解结合起来.由图2可以推出U1,U2,V的后验概率分布函数.后验分布函数的对数函数满足公式(11):
(11)
其中,C是一个独立于参数的常量.最大化方程(11)等价于最小化方程(12):
(12)

根据随机梯度下降法,如下所示:
(13)
(14)
(15)
公式(13)-公式(15)在算法中用于更新各个隐特征向量值.
4 实验和结果分析
4.1 实验数据
为了验证模型,本文使用两种不同业务过程的数据集.第一个实验数据集来自国内某服装企业2015年1月-2018年4月在面料采购环节所记录的真实数据,该数据集反应了不同面料供应商在生产不同类型的面料时所花费时间的真实情况.原始数据集包括133个供应商,7337种面料类型,11219条供应商生产面料所需时间的记录.第二个实验数据集来自福特GoBike自行车2017年6月-2018年6月所记录骑行时间的真实数据,该数据集反应不同年龄的用户在行驶不同路径所需时间的真实情况.原始数据集包括53种用户年龄等级,10895条行驶路径,35658条不同年龄等级用户骑行不同路径所需时间的记录.
4.2 场景分析
对数据集1与数据集2中过程持续时间分析如图3所示.

图3 业务过程活动持续时间分析Fig.3 Business process activity duration analysis
图3(a)表示企业在不同季节采购面料的时间分布,图3(b)图表示用户在不同季节骑行的时间分布.从图中可粗略估计,数据集1中,冬季订购面料所需要的时间比夏季要多;数据集2中,秋季骑行时间比冬季要长.通过对数据集的分析与探索,我们发现活动时间随着不同季节呈现出季节性变动规律;另一方面,根据经验所得,在不同季节中,这两种活动时间都会受到一定影响.因此在本文中考虑上下文场景为时间因素,且主要研究季节因素的影响.
根据季节效应的特性,我们将n取值为4,得US={US1,US2,US3,US4},U={U1,U2,U3,U4},E={E1,E2,E3,E4},令A=U1,B=U2,C=U3,D=U4,E=E1,F=E2,G=E3,H=E4,σE=σE1,σF=σE2,σG=σE3,σH=σE4,其中ABCD表示四季所对应的用户隐特征矩阵,EFGH表示四季所对应的时间偏差矩阵.
假设用户与物品之间存在的时间偏差受不同季节的影响,通过3.4.2小节中联合概率矩阵分解模型推导过程将不同季节的用户与物品的关系矩阵的分解、夏季用户与物品的关系矩阵的分解、秋季用户与物品的关系矩阵的分解以及冬季用户与物品的关系矩阵的分解结合起来,取后验分布函数的对数函数满足公式(16).
(16)
最大化方程(16)并根据SGD得各部分隐特征向量迭代公式:
(17)
(18)
(19)
(20)
(21)
4.3 评价指标
本文使用均方根误差(Root Mean Squared Error,RMSE)作为评测指标.RMSE计算实际观测值与预测值之间的标准差,其值越小表示模型预测的结果要好.计算公式如下:
(22)

4.4 方法比较
为了验证RCPMF方法的预测精度,将该方法与一些时间预测方法进行比较.在本文中使用历史平均值(Mean Value,MV)方法、移动平均(Moving Average,MA)方法、指数平滑(Exponential Smoothing,ES)方法、K近邻(k-Nearest Neighbour,KNN)方法、线性回归(Linear Regression,LR)以及支持向量回归(Support Vector Regression,SVR)方法与所提出RCPMF模型进行比较.为了验证模型的效果,我们将训练集与测试集分别按照8:2、6:4、4:6以及2:8进行划分[15].另外,实验过程部分放置在GitHub(1)https://github.com/woyaogithub/Collective-probabilistic-matrix-factorization.git.
4.5 迭代次数分析

图4 不同迭代次数的RMSE值(数据集1)Fig.4 RMSE values for different iterations(data set 1)

图5 不同迭代次数的RMSE值(数据集2)Fig.5 RMSE values for different iterations(data set 2)

图6 不同正则化参数值的RMSE值(数据集1)Fig.6 RMSE values for different regularization parameter values(data set 1)

图7 不同正则化参数值的RMSE值(数据集2)Fig.7 RMSE values for different regularization parameter values(data set 2)
在联合概率矩阵分解部分,本文使用SGD对目标函数进行求解,因此在本节分析迭代次数对RCPMF模型的影响.为了实验方便,在后续实验中设置λF、λG、λH、λA、λB、λC、λD与λ值相同.
在数据集1中,我们将训练集与测试集按照8:2进行划分.通过多次实验,设置学习速率α=0.001,潜在特征向量维数d=5,参数λ设置为由4.5小节得到的实验结果.迭代次数对预测精度的影响如图4所示.
如图4所示,横坐标表示算法迭代的次数,纵坐标表示RMSE值.由图可知,随着迭代次数的增加,算法的RMSR值下降并趋于平稳,说明我们的算法达到了收敛状态.故在后面的实验,我们均选择迭代次数的值为50.
在数据集2中,我们同样将训练集与测试集按照8:2进行划分.通过多次实验,设置学习速率α=0.0005,潜在特征向量维数d=5,参数λ设置为由4.5小节得到的实验结果.迭代次数对预测精度的影响如图5所示.
如图5所示,横坐标表示算法迭代的次数,纵坐标表示RMSE值.由图可知,随着迭代次数的增加,算法的RMSE值下降并趋于平稳,说明我们的算法达到了收敛状态.同样,我们也选择50作为后面实验的迭代次数值.
4.6 正则化参数分析
正则化参数用来防止模型过拟合,所以正则化参数值的选择对模型预测的精度具有很大影响.在数据集一中,我们选择与4.4小节中相同的的数据集与参数值.正则化参数λ的对预测精度的影响,如图6所示.
根据图6观察可知,正则化参数λ的值对预测时间的精度有着一定的影响.在[0.9,1.8]范围内,随着λ值的增加,模型预测的RMSE值呈下降趋势,但是,当λ的值超过1.8以后,模型预测时间的RMSE值开始增加.因此,在第一个数据集中,我们将正则化参数λ设置为1.8.
同样,在第二个数据集中,我们选择与4.4小节中相同的的数据集与参数值.正则化参数λ的对预测精度的影响,如图7所示.
根据图7观察可知,正则化参数λ的值对预测时间的精度有着一定的影响.在[1.48,1.5]范围内,随着λ值的增加,模型预测的RMSE值呈下降趋势,但是,当λ的值超过1.5以后,模型预测时间的RMSE值呈上升趋势.因此,在第二个数据集中,我们将正则化参数λ设置为1.5.
4.7 对比实验分析
本节主要比较本文所提出的RCPMF算法与对比算法的预测效果,从实验数据随机抽取20%、40%、60%以及80%的训练集对算法进行实验.数据集1实验结果如表2所示,数据集2实验结果如表3所示.

表2 不同预测方法的RMSE值(数据集1)Table 2 RMSE values for different prediction methods(data set 1)
由表2和表3所示,随着训练集的增大,本文所提出的方法在两个数据集中均比其对比算法的的精度高.另外,随着训练集的数目增大,训练模型预测的效果的精度呈上升趋势.其中,在数据集1中,模型预测最好的情况下,其RMSE值比其他方法降低了1.032~10.654;在数据集2中,模型预测最好的情况下,其RMSE值比其他方法降低了4.305~13.336.通过上述分析,模型在数据集1中所取的最好结果参数组合为:训练集与测试集比例为8:2,迭代次数值为50,学习速率值为0.001,正则化参数值为1.8;模型在数据集2中所取的最好结果参数组合为:训练集与测试集比例为8:2,迭代次数值为50,学习速率值为0.0005,正则化参数值为1.5.

表3 不同预测方法的RMSE值(数据集2)Table 3 RMSE values for different prediction methods(data set 2)
5 总结与展望
本文结合回归技术与联合概率矩阵分解模型提出了一种应用于不同上下文场景下的时间预测方法.在考虑上下文场景为时间因素且分析季节因素影响的条件下,结合业务过程活动在执行过程中可观测特征部分与不可观测特征部分进行时间预测.通过对数据集不同程度的划分并将本文提出的算法与相关业务活动时间预测方法进行比较,在以RMSE作为评价指标的前提下,发现该算法具有更高的预测精度.本文所提出的模型为预测活动的执行时间,所以下一步我们会考虑以该模型为基础,将当前预测的活动时间及其自身属性添加到特征信息列表中,在此基础上对该业务过程的下一个活动执行时间进行预测,通过此方法以达到预测业务过程的剩余执行时间的目的.
