基于BI-GRU-CRF 模型的中文分词法
2019-11-06车金立唐力伟邓士杰苏续军
车金立,唐力伟,邓士杰,苏续军
(陆军工程大学石家庄校区火炮工程系,石家庄 050003)
0 引言
中文分词作为自然语言处理(Natural Language Processing,NLP)中重要的基础性任务,已经广泛应用于信息检索、文本分类、机器翻译、智能问答等多个领域,并且分词任务的准确率直接影响着后续任务的性能。然而中文与英语等其他语言不同,由一组汉字连续书写而成,并没有像英语中空格这样明显的单词间的划分标志,词语间的划分较为模糊,给中文分词带来极大的难度。
随着国际中文分词竞赛Bakeoff 的开展,许多研究学者广泛参与,使得中文分词技术逐渐成为研究的热点并取得了极大的发展[1]。目前中文分词主要方法包括:基于词典的方法;基于统计模型的方法;基于深度神经网络的方法。
基于词典的方法也称为基于字符串匹配的方法或机械分词法,是较早的中文分词方法,主要是将输入的句子与人工构建的词典进行比对,识别出包含在词典中的词语,进而实现对句子的切分。按照扫描的方式,其主要分为双向扫描、正向匹配、逆向匹配法等[2]。该方法的优点是针对性较强,面对词典中包含的词语切分准确率较高,但缺点也显而易见:不能很好地处理未登录词与歧义问题,且面向不同领域的适应性较差,人工维护词典的成本较高。基于统计模型的方法通常将中文分词作为序列标注问题来处理,解决了未登录词的识别问题,并且逐渐成为主流。Xue 等[3]首先提出将语料标注为(B,M,E,S)的四标注集,并基于最大熵(Maximum Entropy,ME)模型实现了中文分词。钱智勇等[4]则对古汉语及现代汉语的分词标注技术进行了研究,并基于隐马尔科夫(Hidden Markov Model,HMM)模型实现了对《楚辞》的分词。Collobert 等[5]基于子分类的条件随机场(Conditional Random Fields,CRF)实现了中文分词。Zhao 等[6]在CRF 的基础上,提供了更多的标签选择,以改进分词的效果。然而这些基于统计模型的方法需要大量的统计特征,分词的性能严重依赖于人工设计特征的好坏,且随着特征的增多,训练易于过拟合,泛化能力较差,训练时间也随之增长。
近年来,深度神经网络依靠其可从原始数据中自动提取深层次抽象特征的优势,避免了复杂的人工特征设计,使其在语音识别[7]、计算机视觉[8]等领域取得了显著成效。与此同时,在NLP 任务中,深度学习也显示出了其特有的优势[9]。Zheng 等[10]率先将神经网络引入到中文分词领域,并利用感知器算法加速了训练过程。之后,Chen 等人为了解决一般神经网络不能学习长距离信息的问题,先后将GRNN(Gated Recursive Neural Network)模型[11]和LSTM(Long Short-Term Memory)模型[12]用于中文分词,利用门单元实现了对历史信息的选择,解决了长距离信息依赖的问题。然而,LSTM 结构相对复杂,训练时间较长,Cho 等[13]提出了一种改进模型GRU。Jozefowicz 等[14]验证了GRU 模型在许多问题中比LSTM 模型更易于训练,且能够取得与LSTM相当的结果。但是无论是LSTM 还是GRU 模型,都只能记住过去的信息,即上文信息,无法对未来的也就是下文信息进行处理,因此,Graves 等[15]提出了双向RNN 模型,解决了同时捕获两个方向长距离信息的问题。金宸等[16]则基于双向LSTM 实现了中文分词,并引入贡献率来对权重进行调节,取得了不错的效果。
上述基于深度神经网络的分词方法在进行分词时,对每个字标签的预测都是相互独立的,并没有考虑前后标签的依赖关系,只是对神经网络的输出加入了维特比算法来进行动态规划。因此,本文采用在双向GRU 网络层后加入一层CRF 层,实现对整个句子的标注序列进行预测,既能利用双向GRU 网络实现对上下文信息的利用,也可以利用CRF 层实现更好的分词性能。最后的实验结果表明,BI-GRU-CRF 模型比CRF、GRU 和BI-GRU 模型有更好分词性能。
1 BI-GRU-CRF 网络模型
BI-GRU-CRF 模型是对双向GRU 网络和CRF层的结合。本节首先通过介绍循环神经网络(Recurrent Neural Network,RNN)和GRU 单元的基本结构,进而构建双向GRU 网络,之后再将双向GRU 网络与CRF 层结合,构建BI-GRU-CRF 模型。
1.1 传统RNN 网络
不同于卷积神经网络(Convolutional Neural Network,CNN),RNN 在隐藏层节点间加入了相互连接,其目的就是将隐含层的前一状态加入进来辅助当前数据的处理,充分地利用历史信息,其基本结构如图1 所示。正是这种可以利用前面序列信息的结构使得RNN 在自然语言处理领域得到了广泛的应用。

图1 RNN 结构示意图
如图1 所示,隐藏层节点间相互连接,为了解其内部结构,将RNN 网络进行展开,如下页图2 所示。

图2 RNN 展开结构示意图
图2 中x(t)为输入,在分词中代表第t 个汉字的字向量。state(t)为第t 个RNN 节点输出的隐藏状态,其计算依赖于前一节点的状态state(t-1)与当前的输入x(t):
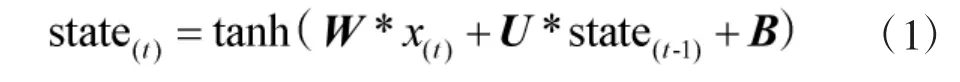
式中,W 为输入层到隐藏层的权值矩阵,U 为上一时刻隐藏层到这一时刻隐藏层的权值矩阵,B 为偏置参数矩阵,tanh 为激活函数。
o(t)则为输出,在分词中表示第t 个汉字的标签概率,其计算依赖于当前节点的状态:
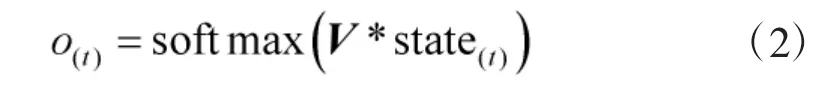
式中,V 为隐藏层到输出层的权值矩阵,则作为分类函数。另外,为了减少参数数量,RNN 网络训练中的参数是共享的,即上文中的W,U,B,V。
1.2 GRU 单元
理论上,RNN 网络可以利用隐藏层状态state(t)来捕获前面所有输入的信息,然而现实却并非如此。Bengio[17]与Pascanu[18]的相关研究证明,传统的RNN 网络在处理长距离信息问题时,隐藏层节点只是简单地使用tannh 函数,使得训练易于陷入梯度消失或梯度爆炸的问题当中。
因此,为解决上述问题,LSTM[19]和GRU[13]单元先后被提出,用于替换传统RNN 网络中的函数层。二者都是基于门(gates)来实现的单元结构,其中LSTM 拥有输入门(input gates)、遗忘门(forget gates)和输出门(output gates)3 个门结构。而GRU 相对LSTM 来说更加简洁和高效,它只具有重置门(reset gates)和更新门(update gates)两个门结构,其中更新门则是将LSTM 中的输入门和遗忘门进行了合并,GRU 单元的内部结构如图3 所示。

图3 GRU 单元的内部结构
图3可用公式表示为:

其中,zt表示更新门,为当前隐藏节点的候选值,ht-1为前一隐藏节点的激活值,ht则为当前隐藏节点的激活值。由式(3)可以看出,更新门的作用就是来控制“遗忘”多少历史信息ht-1和“记忆”多少当前信息。zt越大,GRU 单元就越能记住更多的当前信息并遗忘更多的历史信息。更新门的计算为:
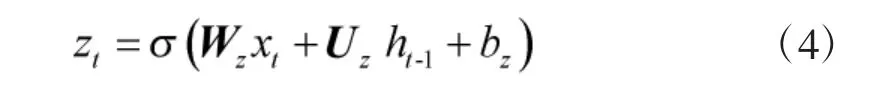
而当前隐藏节点的候选值计算为:


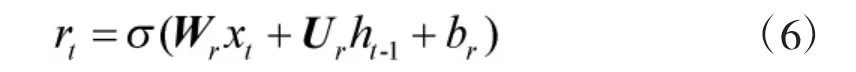
以上所有的W 和U 都是用于训练的权重矩阵,rt的作用是控制多少输入信息xt和多少历史信息ht-1会对h~t产生影响。rt越大,xt对于h~t所起到的影响越小,而ht-1所起到的影响越大。因此,通过重置门和更新门两个门结构,每个GRU 单元都具有了学习长距离信息的能力,缓解了传统RNN 网络结构训练时带来的梯度消失或爆炸的难题。
1.3 双向GRU 网络
本文也将中文分词作为一种序列标注任务来处理,而在面对许多前文一样的句子时,如“你好”、“你们”、“你是谁”等单向的RNN 网络并不能很好地处理,只能将这些句子处理成一样的结果。而显然“你们”是一个词,而在“你是谁”中“你”则应当被划分为一个词。可见,对于同一序列,后文的信息也十分重要,因此,能同时利用前文信息和后文信息的双向RNN 网络[15]更适于处理中文分词任务,该网络的基本结构如图4 所示。
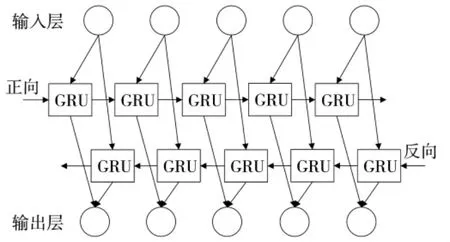
图4 双向RNN 网络模型
图4 模型多加入了一层隐含层,将序列信息按照前向和后向两个方向输入到模型中,并且这两个隐藏层都连接着输出层,因此,该模型可以同时利用两个方向的长距离信息。而只需将前向和后向两个隐藏层中的节点替换为GRU 单元,就构成了双向GRU(BI-GRU)网络。
1.4 BI-GRU-CRF 模型
1.4.1 CRF 模型
在预测最终的标签序列时,标签间的前后关系也十分重要,例如在(B,M,E,S)标签集上进行分词预测时,标签B 的后面不可能还是B。而CRF 作为序列预测的一种概率模型,可以联合考虑相邻标签间的相关性,而得到全局最优的标记序列作为结果,实现对整个预测序列进行优化,其链式结构图如图5 所示。
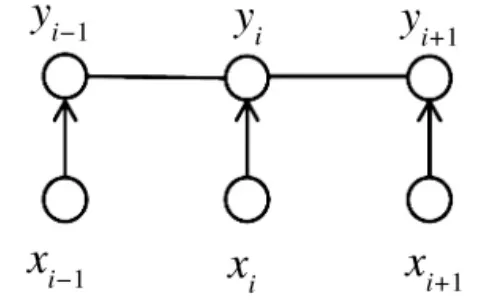
图5 CRF 链式结构
1.4.2 BI-GRU-CRF 模型
BI-GRU-CRF 模型就是将双向GRU 网络与CRF 模型进行结合,在双向GRU 网络的隐藏层后加入CRF 线性层,其基本结构如图6 所示。

图6 BI-GRU-CRF 网络结构
该网络模型可以有效利用双向GRU 层获取输入序列中的上下文信息作为特征,并通过CRF 层利用前后的标签信息对当前的标签进行预测,实现对句子的最优分词标注。

式中,Pn×k为双向GRU 层输出的概率矩阵,n 为输入文本序列中汉字的个数,k 为输出标签的种类,即pi,j表示第i 个字被标记为第j 个标签的概率。而式中A为状态转移矩阵,Aij代表从第i 个标签转移到第j个标签的概率,则标签序列为y 的条件概率为:
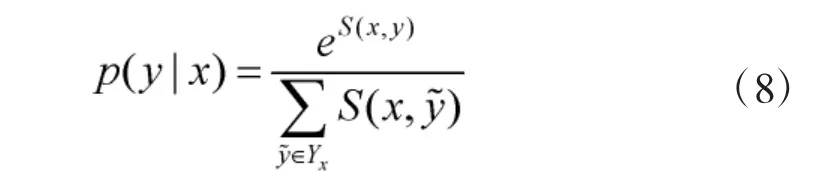
式中,Yx为所有可能的标签序列的集合,在训练中,则使用其似然函数:
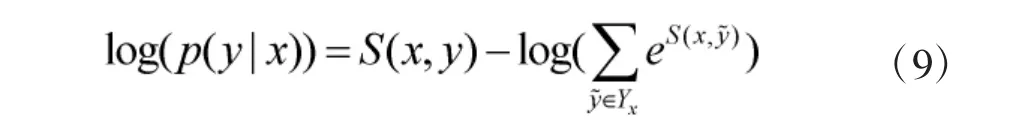
之后通过式(9)可在预测时得到整体概率最大的一组标签序列:
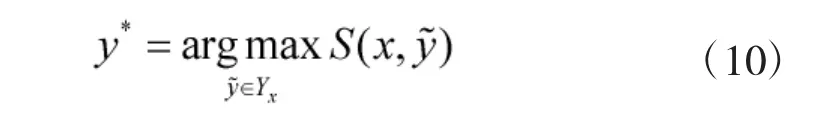
2 模型训练
Zheng 等在文献[10]中提出了将深度神经网络应用于中文分词的基本框架,本文在该框架的基础上加入了BI-GRU-CRF 网络模型,具体训练流程如图7,使其能够综合利用中文句子的上下文信息以及预测标签间的前后依赖关系,实现最优的分词标注。

图7 BI-GRU-CRF 分词模型训练流程图
2.1 训练语料及标注
本文将采用由中文分词竞赛Bakeoff 提供的分词训练中常用的训练语料PKU、MSRA,以及由本文构建的军事领域分词语料(记为MSC)来对分词模型进行训练。并采用序列标注分词中常用的四词位标注法(B,M,E,S),以及文献[6]提出的更能表达词位信息的六词位标注法(B,B1,B2,M,E,S),分别对语料进行预处理,进行分词效果的对比。
2.2 字符向量化
按照分词模型的训练流程,在将文本序列输入到BI-GRU-CRF 模型训练前,需要将文字转化为低维的字符向量抽象表示字的特征[20],作为神经网络的输入进行训练,同时文献[21]指出,将预训练得到的字向量作为输入可以取得较好的分词效果。
为此首先需要建立一个大小为d×N 的汉字字典,其中d 为字向量的维度,N 为汉字的个数,通过word2vec[22]的方法预训练得到每个字的字向量。这样在进行分词训练时就可将输入的文本对照字典查询得到相应的字向量,使文本序列变为实值矩阵输入到神经网络模型进行训练。
2.3 Dropout
Dropout 是目前防止深度神经网络训练过拟合的常用方法,其基本原理是按照一定比例p 暂时将网络节点从训练中舍弃,不更新其对应的权重,但在预测过程中则启用所有的节点。本文在两层GRU 网络后都加入了Dropout 层以提高分词模型的性能。
3 实验
3.1 实验设置
本文将基于PKU、MSRA 及MSC 语料集进行实验,其中,PKU 和MSRA 语料分别提供了训练集和测试集,便于训练及测试,对于MSC 语料集则选取80 %作为训练集,20 %作为测试集。并且为了便于评估模型的分词性能,本文采用SIGHAN 规定的标准评估指标:准确率P(precision),召回率R(recall)及F1 值来对模型进行评估。其相应的计算公式如下:

3.2 超参数设置
在训练前首先需要确定对模型分词性能影响比较大的一些超参数,本文在PKU 语料上基于BI-GRU-CRF 模型进行了实验,结果如图8 所示,根据实验结果,具体参数值见表1。

表1 超参数数值
在选择字向量维度时,维度过低则难以表达字的特征,而维度过高又会导致模型难以训练,因此,依据实验结果选取字向量维度为200。对于隐藏层节点数,随着隐藏层节点数量的增加分词效果趋于稳定,当隐藏层节点数为128 时可较好平衡分词精度与训练速度。而在对Dropout 比例进行选择时,比例过高将导致节点工作数过少,模型拟合效果较差,实验结果显示比例设为0.2 时效果较好。最后在选择初始学习速率时,学习速率过低会导致训练时间过长,而过高将导致模型过拟合,影响分词性能,设为0.002 时可较好地平衡两者关系。
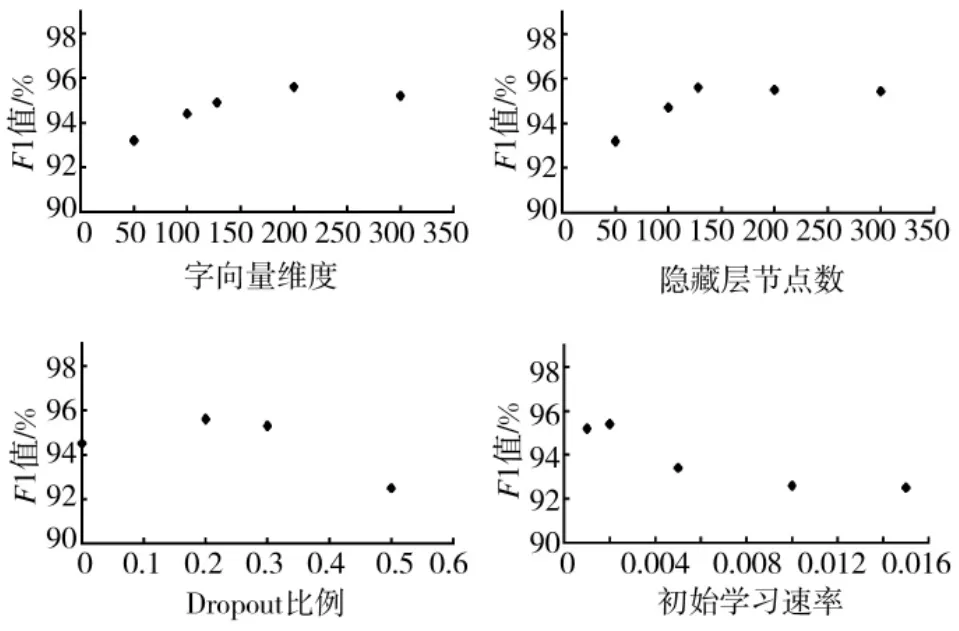
图8 不同超参数对实验效果的影响
3.3 模型对比实验
本文基于BI-GRU-CRF 网络结构实现了中文分词模型,分别在PKU、MSRA 及MSC 语料集上进行了分词测试,并与其他几个典型的分词模型(CRF、GRU、BI-GRU 等模型)进行了性能对比。另外,为比较不同标注方法对模型性能的影响,分别以四词位标注(4tag) 与六词位标注(6tag)对BI-GRU-CRF 模型性能进行测试。以上实验结果见下页表2 所示。
从表2 可以看出,采用六词位标注法的模型性能好于采用四词位标注法的模型。以及基于BI-GRU-CRF 模型的中文分词算法在准确率、召回率及F1 值3 项指标上均明显好于CRF、GRU、BI-GRU 模型,且能够避免传统CRF 模型中复杂的特征工程。
另外,表3 中列出了一些其他学者在分词领域研究的成果与本文分词模型的对比。其中Tseng[23]为基于CRF 实现的中文分词算法,Collobert[5]为基于子分类CRF 实现的中文分词,Chen[12]为加入了双字符嵌入向量的LSTM 模型且挂载了分词词典,Yao[21]为堆叠了3 层的BI-LSTM 模型。本文在未挂载词典与堆叠神经网络层数的情况下,仍能取得相近的分词效果,证明了BI-GRU-CRF 模型对于中文分词的良好性能。

表2 不同模型的分词性能对比

表3 BI-GRU-CRF 模型和其他学者成果(F1 值)对比
4 结论
本文在GRU 神经网络的基础上提出了一种BI-GRU-CRF 分词模型,该模型不仅继承了GRU单元易于训练的特性,且可以同时利用双向上下文信息与相邻标签间的相关性进行分词。利用该模型加入预训练得到的字向量,分别在PKU、MSRA、MSC 语料集上采用四词位及六词位标注法进行实验,同时与前人研究成果进行对比,结果表明BI-GRU-CRF 模型具有良好的分词性能,且六词位标注法可以改进分词效果。今后工作包括堆叠GRU网络层数与挂载分词词典来改善分词结果并应用于特定领域检验分词性能。
