用于知识表示学习的对抗式负样本生成
2019-10-31张钊吉建民陈小平
张钊 吉建民 陈小平

摘 要:知识表示学习目的是将知识图谱中符号化表示的关系与实体嵌入到低维连续向量空间。知识表示模型在训练过程中需要大量负样本,但多数知识图谱只以三元组的形式存储正样本。传统知识表示学习方法中通常使用负采样方法,这种方法生成的负样本很容易被模型判别,随着训练的进行对性能提升的贡献也会越来越小。为了解决这个问题,提出了对抗式负样本生成器(ANG)模型。生成器采用编码解码架构,编码器读入头或尾实体被替换的正样本作为上下文信息,然后解码器利用编码器提供的编码信息为三元组填充被替换的实体,从而构建负样本。训练过程采用已有的知识表示学习模型与生成器进行对抗训练以优化知识表示向量。在链接预测和三元组分类任务上评估了该方法,实验结果表明该方法对已有知识表示学习模型在FB15K237、WN18和WN18RR数据集上的链接预测平均排名与三元组分类准确度都有提升。
关键词:知识表示学习;知识图谱;生成对抗网络;深度学习;知识图谱嵌入
中图分类号:TP391.1
文献标志码:A
Adversarial negative sample generation for knowledge representation learning
ZHANG Zhao, JI Jianmin*, CHEN Xiaoping
School of Computer Science and Technology, University of Science and Technology of China, Hefei Anhui 230027, China
Abstract:
Knowledge graph embedding is to embed symbolic relations and entities of the knowledge graph into low dimensional continuous vector space. Despite the requirement of negative samples for training knowledge graph embedding models, only positive examples are stored in the form of triplets in most knowledge graphs. Moreover, negative samples generated by negative sampling of conventional knowledge graph embedding methods are easy to be discriminated by the model and contribute less and less as the training going on. To address this problem, an Adversarial Negative Generator (ANG) model was proposed. The generator applied the encoder-decoder pipeline, the encoder readed in positive triplets whose head or tail entities were replaced as context information,
and then the decoder filled in the triplets of the replaced entities coding information provided by the encoder,
and then the decoder filled the replaced entity with the triplet using the encoding information provided by the encoder,
and then the decoder filled the triplets of the replaced entities coding information provided by the encoder,
so as to generate negative samples. Several existing knowledge graph embedding models were used to play an adversarial game with the proposed generator to optimize the knowledge representation vectors. By comparing with existing knowledge graph embedding models, it can be seen that the proposed method has better mean ranking of link prediction and more accurate triple classification result on FB15K237, WN18 and WN18RR datasets.
Key words:
knowledge representation learning; knowledge graph; generative adversarial network; deep learning; knowledge graph embedding
0 引言
知識图谱(Knowledge Graph, KG)是由一系列相互关联的实体节点组成的网络,通常以三元组(头实体,关系,尾实体)的形式表示,表示头实体和尾实体之间存在一条关系。近年来有很多大型知识图谱被构建出来,比如 WordNet[1]、DBpedia[2]、Freebase[3]。而大型知识图谱面临的一个主要问题就是由知识图谱中稀疏离散表示的知识导致的高计算复杂性,同时也很难衡量知识的相似性与相关性。所以近年来有大量工作关注知识表示学习(如TransE[4]、TransH[5]、TransD[6]、DistMult[7]、ComplEx[8]等),这些工作为知识图谱补全和关系抽取等任务提供了大量便利。知识表示学习目标是将知识图谱中的实体和关系嵌入到低维连续向量空间,同时由分值函数计算知识的可信度。在训练模型时,需要正样本和负样本进行判别训练并对结果进行排序。然而考虑到存储空间利用率,大部分知识图谱仅存储正样本,所以传统的知识表示学习模型多数采用负采样[4]的方式构建负样本。在这种方法下,三元组的头实体或者尾实体被从实体集合中随机采样得到的新实体替换,从而构成负样本。采样过程一般遵循实体集合上的均匀分布或者伯努利分布。这种方法简单而高效,但是由于知识图谱的稀疏性问题,随机采样得到的绝大部分实体很难与正样本中的关系与实体组成一个可信样本,比如对正样本(合肥,位于,安徽)通过负采样得到的负样本可以是(合肥,位于,香蕉),这些低质量的三元组可以很容易被模型判别,导致代价函数快速收敛甚至随着训练过程的进行无法对提升模型性能提供帮助。
近年来在生成对抗网络(Generative Adversarial Network, GAN)[9]的启发下,部分工作开始使用对抗式训练框架生成负样本。KBGAN[10]使用两个不同的知识表示模型作为生成器与判别器进行对抗训练来优化知识表示。用于负采样的生成式对抗网络(Generative Adversarial Net For NEGative sampling, GAN4NEG)[11]关注基于翻译距离的知识表示学习模型中零损失的问题。本文提出了一种对抗式负样本生成器(Adversarial Negative Generator, ANG)用于生成负样本,同时使用已有知识表示学习模型作判别器在对抗式训练框架下进行对抗训练。针对链接预测和三元组分类两个任务在FB15K237[12]、WN18[4]、WN18RR[13]三个数据集上进行了实验,结果表明本文方法在链接预测(Link prediction)平均排名(Mean Ranking, MR)和三元组分类(Triple Classification)准确度上有明显提升。
1 知识表示学习相关工作
知识表示学习目标是为知识图谱中以三元组(h,r,t) 表示的知识建模,将其实体与关系嵌入到低维连续向量空间中。在知识表示模型中,关系被定义为头实体和尾实体之间的映射,通过一个分值函数f(h,r,t)对每个三元组计算可信度分值,存在于知识图谱中的三元组(正样本)会比不存在的三元组(负样本)分值高。
目前主要有两类知识表示学习模型:翻译距离(Translation Distance)模型和语义匹配(Semantic Matching)模型。TransE首先引入了基于翻译距离的分值函数,在这种模型下,关系向量r被视作从头实体h到尾实体t的翻译,当h+r与t距离越小时,三元组可信度越高。TransH在其基础上作了扩展,使其更适用于一对多,多对多等复杂关系建模。另外还有很多TransE模型的变体在不同方面提升了性能,比如TransD、TransR[14]。RESCAL[15]是比较早期使用基于语义匹配的分值函数的工作之一,这类模型也被称作矩阵分解模型。在这类模型中,关系向量被视为头实体与尾实体之间的映射矩阵,用h Mr t矩阵乘积来衡量三元组可信度,ComplEx、DistMult和HolE[16]是这一类方法的变体。同时也有许多其他类型的模型使用神经网络来拟合分值函数比如NTN[17]和ConvE[18]等。
在知识表示模型训练过程中需要正样本和负样本,模型通过对正样本和负样本打分并排序计算代价函数,同时优化知识表示向量。由于大多数知识图谱不提供负样本,上述模型都是采用负采样方法生成,但是这一方法很难生成高质量的负样本。KBGAN首先提出使用生成对抗网络进行知识表示模型训练。在KBGAN中,用预训练的语义匹配模型作为生成器,用预训练的翻译距离模型作为判别器进行对抗式训练,最终采用判别器中的知识表示向量进行评估。在GAN4NEG中,作者提出翻译距离模型中使用负采样方法会导致零损失问题,也就是随着训练的进行,由于分值较差的负样本很快被排到正确的位置,正负样本之间的区别几乎与负样本无关,导致损失函数降为零。他们使用一个两层全连接神经网络作为生成器为正样本生成相应负样本。基于类似的想法,ACE(Adversarial Constrastive Estimation)[19]为自然语言处理中常用的噪声对比估计方法,提出了一个更通用的对抗式负采样方法。但是由于经典生成对抗网络是为生成连续的数据设计的,在梯度反向传播时要求完全可微分,而生成实体时采样过程阻断了梯度的反向傳播。为了将生成对抗网络扩展为支持生成离散自然语言词组,很多自然语言生成工作[19-21]以及上述模型都使用REINFORCE[22]方法来完成梯度反向传播。
2 对抗式知识表示学习
2.1 符号约定
本文中使用E代表知识图谱中的实体集合,R代表关系集合,ξ和ξ′代表正样本(h,r,t)和对应的负样本。S代表一组三元组ξ,其中h,t∈E, r∈R,S中ξ对应的负样本集合表示如下:
S′ξ={(h′,r,t)|h′∈E}∪{(h,r,t′)|t′∈E}
2.2 目标知识表示模型
为了检验对抗式负样本生成器的性能,本文实现了几个代表性的基于翻译距离的模型(TransE[4],TransH[5],TransD[6])和基于语义匹配的模型(ComplEx[8], DistMult[7])作为判别器,也作为知识表示目标模型。判别器内部的知识表示向量用于模型的评估。它们的分值函数在表1中说明。
翻译距离模型使用基于距离的分值函数来估计三元组的置信度。在这类模型中关系作为头实体和尾实体之间的翻译向量,分值函数越小意味着置信度越高,同时使用Margin Ranking Loss作为损失函数:
LD=∑ξ∈S∑ξ′∈S′ξ[f(ξ)-f(ξ′)+γ]+(1)
其中:[x]+ 表示x的绝对值,γ表示间隔(margin)距离。
语义匹配模型使用基于语义相似度的分值函数。在这类模型中关系被表示为一个矩阵,代表了头实体与尾实体之间的相互关系。这类模型使用Logistic Loss作为损失函数:
LD=∑ξ∈S∑ξ′∈S′ξ[l(+1, f(ξ))+l(-1, (ξ′))](2)
其中l(β,x)是Softplus激活函数:
l(β,x)=1β*ln(1+exp(β*x)) (3)
在这两类模型的原始实现中,S′ξ都是使用负采样方法构建的;而在本文的对抗式训练框架中,S′ξ是由生成器提供的,这一生成器可以更好地利用正样本中的信息来生成置信度更高的负样本。使用上述模型作为判别器,通过对抗训练优化LD,同时使用分值函数来估计ξ′的回报:
RD=-f(ξ′)(4)
2.3 对抗式负样本生成器
为了给判别器提供高质量的负样本,生成器需要使用对应的正样本作为额外信息。在MaskGAN[21]的启发下,本文的生成器采用了一个基于Seq2Seq[23]的编码解码架构,如图1。示例中实体到解码器(decoder)表示的是采样过程,是补全的尾实体,〈s〉表示的是开始解码的标志。
训练过程中,对每一批正样本中的三元组,用〈m〉标记以相同的概率替换其头或者尾实体(非同时替换),表示为m(ξ′)。m(ξ′)作为一个由双向GRU[24]组成的编码器(encoder)的输入,编码成正样本的向量表示。解码器(decoder)的目的是根据标记补全m(ξ′)中缺失的部分,其为由一个单层GRU单元和一个全连接层组成的神经网络,输入是编码器编码得到的正样本隐藏表示向量以及上一个时间步中编码器输出的实体或关系标记。编码器按顺序在头实体,关系与尾实体上解构其条件分布,经过softmax激活函数后,解码器根据输出的概率分布采样得到正样本中以〈m〉表示的缺失的实体t,补全的实体在图1中用表示,然后补全的三元组ξ′作为负样本。然而,由于采样过程会导致输出不可微,从而无法进行梯度反向传播,所以需要使用策略梯度[25](Policy Gradients)方法进行训练。训练目标定义为最大化生成实体填充的负样本对应的回报(Reward)期望,如下:
EG[RD]=Eξ′~G(m(ξ;θ))RD(ξ′)
θEG[RD]=RD(ξ′)θ ln p(ξ′|ξ;θ)=
-f(ξ′)θ ln p(ξ′|ξ;θ)
(5)
在标准的强化学习算法中,本文的生成器可以看作其中的策略网络,判别器可以看作值网络,生成器内部表示策略分布,输入的正样本可以看作强化学习中的状态(state),输出补全的负样本可以看作策略网络输出的动作(action)。判别器为选择的动作进行评估,给出回报(reward),然后通过策略梯度方式进行反向传播。整个训练过程优化目标是最大化策略网络输出动作的分值期望。
2.4 对抗式训练框架
首先对生成器使用极大似然估计进行预训练,即最大化生成器还原输入正样本的概率。然后使用对抗式训练框架对生成器和目标知识表示学习模型进行训练,训练算法如算法 1所示。
算法1 用于知识表示学习的生成式对抗训练算法。
输入:预训练的生成器G,判别器D,训练集S={(h,r,t)} ;
输出:从D中学习得到的知识表示向量。
有序号的程序——————————Shift+Alt+Y
程序前
1)
Loop
2)
For G steps do
3)
从S中采樣一批正样本Spos
4)
For each ξ∈Spos
5)
通过用〈m〉替换ξ中的h或t构建m(ξ)
6)
生成器G通过编码m(ξ),生成负样本ξ′加入到负样本集合Sneg中
7)
End for
8)
判别器D用式(4)计算Rξ′
9)
用式(5)更新Gθ
10)
End for
11)
判别器D用Spos和Sneg通过式(1)和式(2)计算LD
12)
通过DθLD 更新Dθ
13)
End loop
程序后
由于生成器在整个知识库实体集合上估计条件概率分布,生成的负样本可能仍存在于知识库三元组集合中,这类负样本不能被视为错误的三元组,否则会误导目标知识表示模型的训练。在传统的负采样算法中,为了避免这种情况是通过重采样来过滤错误的负样本的,由于知识库的稀疏性,随机重采样得到的负样本为正样本的概率很小。然而在本文的方法中,由于生成负样本时考虑了正样本作为额外信息,采样得到的负样本实际为正样本的概率不可忽略,因为正样本分值函数更高,也意味着其回报更高。所以本文在训练时给此类假负样本一个较大的负的回报作为惩罚,并强制其不参与目标知识表示模型的训练。
同时模式崩溃也是生成对抗网络中常见的问题。模式崩溃的意思是随着训练的进行,生成器所生成的候选实体很快集中到很少的几个样本,在这种情况下由于负采样方法可以采样到更大范围的样本,本文的方法可能会弱于负采样方法。为了避免这种问题,本文使用了 ε-greedy[26]策略来平衡生成器探索与利用负样本的过程。
3 实验方案与结果分析
在链接预测(Link Prediction)和三元组分类(Triple Classification)任务上评估了本文方法,在实验中使用了三个翻译距离模型和两个语义匹配模型与生成器进行对抗式训练,实验使用判别器的实体关系表示向量进行评估。
3.1 数据集
在实验中使用了3个知识表示学习中的常用数据集:FB15K237、WN18和WN18RR,数据集详细数据如表2。
3.2 实现细节
在预训练阶段使用极大似然法(Maximum Likelihood Estimation, MLE)训练生成器,根据在验证集上的三元组预测准确率选择最佳模型,在WN18和WN18RR数据集上实体和关系向量维度为50,在FB15K237上维度为100,优化器使用Adam[27]。
在对抗式训练环节,ε范围是1.0到0.4,间隔γ在FB15K237上为1.0,在WN18和WN18RR上为3.0,生成器优化器为SGD,学习率为0.01。判别器的优化器翻译距离模型选择Adam,使用默认参数,语义匹配模型选择Adagrad[28],WN18和WN18RR的学习率为0.1,FB15K237的学习率为0.01。实验运行了1000轮,每一轮将训练集划分为100个批次训练。
3.3 实验结果
3.3.1 链接预测
链接预测(Link Prediction)是知识库补全中的一项主要任务,其目的是为给定的三元组预测缺失的头或尾实体。链接预测主要是通过为一系列从知识库取出的候选实体评分并进行排序来评价模型性能。
实验中,首先轮流将测试集三元组的头实体替换为E中的所有实体,然后为每一个生成的三元组评分并降序排列,然后在尾实体上实施相同的过程。每一组排序结果中正确的三元组被记录下来,测试完成后将正确三元组的平均排名(Mean Rank, MR)以及正确三元组排序在前10%的比例(HIts@10)作为评价标准。由于某些生成的三元组可能也是正确的三元组(存在于S),这会导致某些生成的三元组会比所预测的三元组排名要高,而实际上这种情况不能说生成的三元组应该比所预测的三元组置信度更高,所以将排名中的正确三元组过滤掉作为最终结果。
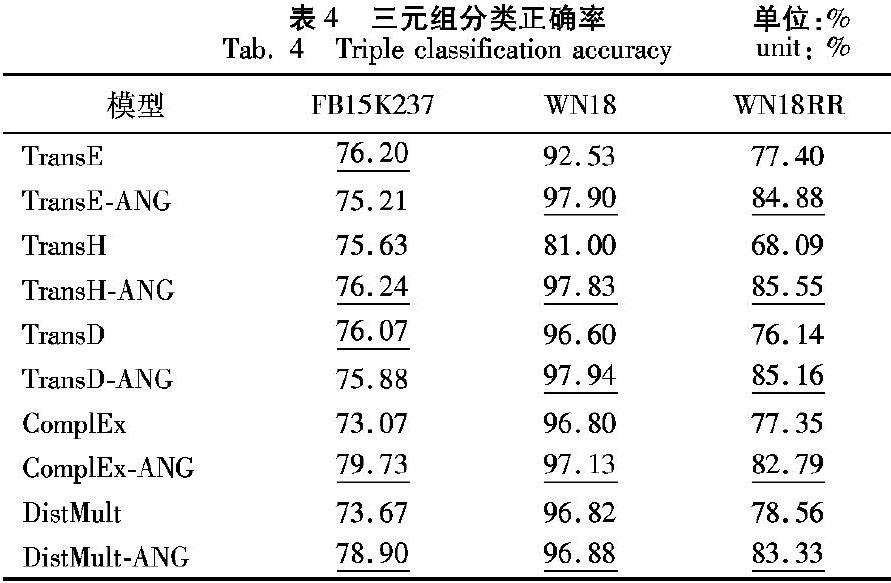
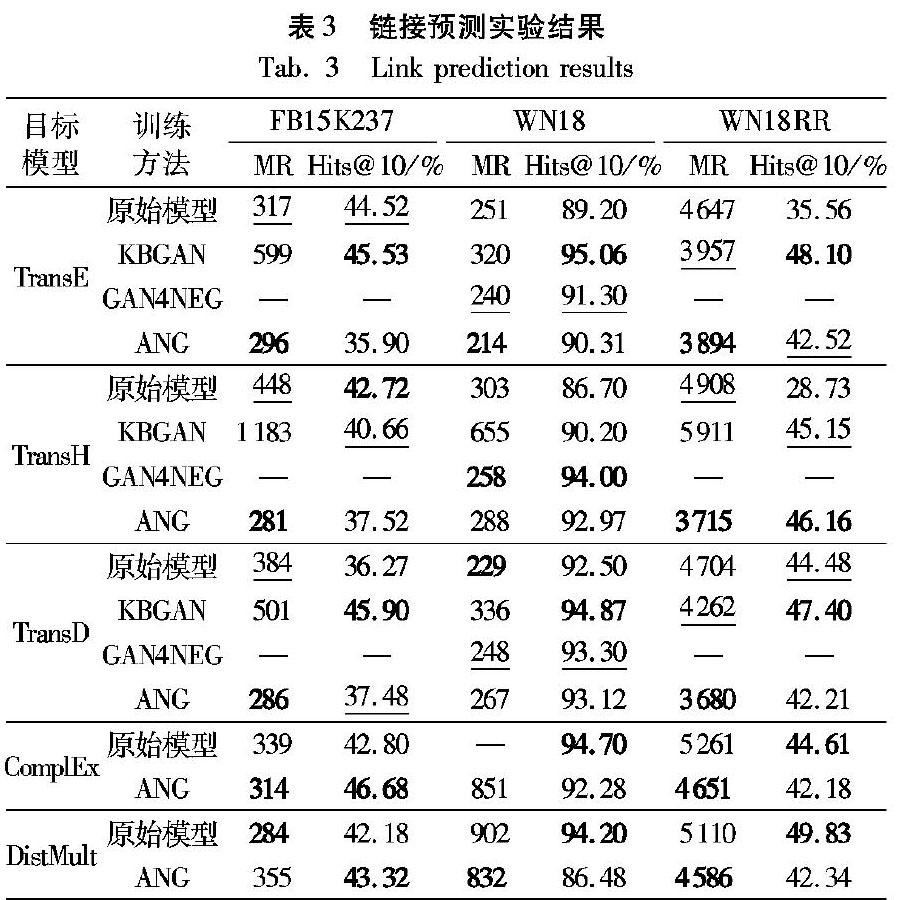
表3列出了本文模型与基准模型和相关方法(KBGAN、GAN4NEG)在链接预测任务上不同数据集的性能对比。粗体表示的是对比实验中的最优结果,下划线表示的是次优结果。
表中表3中原始基准模型在WN18数据集上的实验结果都是从原始论文中获得,在FB15K237和WN18RR上的结果是使用OpenKE[29]工具包在与本实验相同的参数设置下得到,相关模型KBGAN的结果是用作者提供的代码在其预设参数下训练得到,GAN4NEG作者没有提供代码,所以仅列出其在WN18上的实验结果。KBGAN和GAN4NEG实验结果都是在有预训练的情况下得到。从结果可以看出,ANG模型在平均排名(MR)评价标准上超过了大部分基准模型与相关方法,Hits@10评价标准也在大部分实验设置中比基准模型表现好。在Hits@10标准中,由于本模型中生成器输出的采样空间为整个知识库实体集合,而KBGAN和GAN4NEG中都是在生成器输入前从实体集合中随机挑选一个较小的候选实体集合,然后生成器在候选集合中挑选条件概率最大的实体,所以其在训练过程中可以更好地对排名相近的三元组进行判别,而本文方法采样空间更大,所以对最终正样本平均排名(MR)优化效果更好。
3.3.2 三元组分类
三元组分类(Triple Classification)目的是判断给定三元组(h,r,t)是正样本还是负样本,也即是否存在于知识图谱中。由于标准测试集中不存在负样本,所以本文使用了与NTN[15]中相同的方法来构建测试集中的负样本。首先将测试集中三元组的头尾交换,然后根据交换后的实体是否在数据集中相应位置上出现过进行过滤,得到的三元组作为负样本,然后为验证集进行同样操作得到验证集中的负样本。进行三元组分类测试时,首先在验证集上进行分类测试,为每个关系r最大化分类准确率得到分类阈值δr,测试三元组(h,r,t)分值大于閾值δr时分类为正,否则为负。训练过程中使用验证集测试模型效果,然后在测试集上给出三元组分类准确率。
表4列出了本文模型和基准模型在三元组分类任务上的结果对比。由于相关方法KBGAN和GAN4NEG中没有给出在这三个数据集上三元组分类的结果,在此不作比较。实验表明,在大多数数据集上,ANG的表现都要明显好于基准模型。
4 结语
本文提出了一种用于知识表示学习的对抗式负样本生成器(ANG),ANG可以在传统知识表示学习模型训练过程中提供高质量的负样本,避免了负采样方法导致的模型快速收敛、模型难以优化的问题,同时实现了对抗式训练框架用于训练传统知识表示学习模型,通过生成器与目标模型的对抗式训练提升模型性能。由于训练框架与模型无关,本文提出的生成器与训练框架也可扩展用于其他知识表示学习模型的训练。在链接预测和三元组分类任务上评估了本文模型,实验结果表明通过在生成负样本时使用正样本提供的信息可以有效提高负样本生成的质量,为模型优化提供更好的负样本数据。
目前本文方法在链接预测Hits@10评价标准上弱于同类生成式算法,主要由于生成器采样空间较大,采样效率较低,为提高这一指标可以考虑压缩生成器实体采样空间,或者使用深度强化学习中经验池的方法对生成空间进行多次采样以加速优化生成器实体概率分布。
参考文献
[1]MILLER G A. WordNet: a lexical database for English [J]. Communications of the ACM, 1995, 38(11): 39-41.
[2]AUER S, BIZER C, KOBILAROV G, et al. DBpedia: a nucleus for a Web of open data [C]// Proceedings of the 2007 International Semantic Web Conference, LNCS 4825. Berlin: Springer, 2007: 722-735.
[3]BOLLACKER K, EVANS C, PARITOSH P, et al. Freebase: a collaboratively created graph database for structuring human knowledge [C]// Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data. New York: ACM, 2008: 1247-1250.
[4]BORDES A, USUNIER N, GARCIA-DURAN A, et al. Translating embeddings for modeling multi-relational data [C]// Proceedings of the 2013 Advances in Neural Information Processing Systems. 2013: 2787-2795.
BORDES A, USUNIER N, GARCIA-DURN A, et al. Translating embeddings for modeling multi-relational data [EB/OL]. [2019-01-06]. http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.447.6132&rep=rep1&type=pdf.
[5]WANG Z, ZHANG J, FENG J, et al. Knowledge graph embedding by translating on hyperplanes [C]// AAAI ‘14: Proceedings of the 28th AAAI Conference on Artificial Intelligence. Menlo Park, CA: AAAI Press, 2014: 1112-1119.
[6]JI G, HE S, XU L, et al. Knowledge graph embedding via dynamic mapping matrix [C]// Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2015, 1: 687-696.
[7]YANG B, YIH W, HE X, et al. Embedding entities and relations for learning and inference in knowledge bases [J]. arXiv preprint arXiv:1412.6575, 2014.
YANG B, YIH W, HE X, et al. Embedding entities and relations for learning and inference in knowledge bases [EB/OL]. [2019-01-06]. https://arxiv.org/pdf/1412.6575.pdf.
[8]TROUILLON T, WELBL J, RIEDEL S, et al. Complex embeddings for simple link prediction [C]// International Conference on Machine Learning. 2016: 2071-2080.
TROUILLON T, WELBL J, RIEDEL S, et al. Complex embeddings for simple link prediction [EB/OL]. [2019-01-06]. https://arxiv.org/pdf/1606.06357.pdf.
[9]GOODFELLOW I, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial nets [C]// NIPS ‘14: Proceedings of the 27th International Conference on Neural Information Processing Systems. Cambridge, MA: MIT Press, 2014, 2: 2672-2680.
[10]CAI L, WANG W Y. KBGAN: adversarial learning for knowledge graph embeddings [C]// Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers). 2018: 1470-1480.
CAI L, WANG W Y. KBGAN: adversarial learning for knowledge graph embeddings [EB/OL]. [2019-01-08]. https://arxiv.org/pdf/1711.04071.pdf.
[11]WANG P, LI S, PAN R. Incorporating GAN for negative sampling in knowledge representation learning [C]// Thirty-Second AAAI Conference on Artificial Intelligence. 2018.
WANG P, LI S, PAN R. Incorporating GAN for negative sampling in knowledge representation learning [EB/OL]. [2019-01-08]. https://arxiv.org/pdf/1809.11017.pdf.
[12]TOUTANOVA K, CHEN D. Observed versus latent features for knowledge base and text inference [C]// Proceedings of the 3rd Workshop on Continuous Vector Space Models and their Compositionality. 2015: 57-66.
TOUTANOVA K, CHEN D. Observed versus latent features for knowledge base and text inference [EB/OL]. [2019-01-08]. http://citeseerx.ist.psu.edu/viewdoc/download;jsessionid=332E017631F63128927CF06ABF216792?doi=10.1.1.709.9449&rep=rep1&type=pdf.
[13]DETTMERS T, MINERVINI P, STENETORP P, et al. Convolutional 2D knowledge graph embeddings [C]// Thirty-Second AAAI Conference on Artificial Intelligence. 2018.
DETTMERS T, MINERVINI P, STENETORP P, et al. Convolutional 2D knowledge graph embeddings [EB/OL]. [2019-01-08]. https://arxiv.org/pdf/1707.01476.pdf.
[14]LIN Y, LIU Z, SUN M, et al. Learning entity and relation embeddings for knowledge graph completion [C]// AAAI ‘15: Proceedings of the 29th AAAI Conference on Artificial Intelligence. Menlo Park, CA: AAAI Press, 2015: 2181-2187.
[15]NICKEL M, TRESP V, KRIEGEL H P. A three-way model for collective learning on multi-relational data [C]// ICML ‘11: Proceedings of the 28th International Conference on International Conference on Machine Learning. Bellevue, Washington: Omnipress, 2011: 809-816.
[16]NICKEL M, ROSASCO L, POGGIO T. Holographic embeddings of knowledge graphs [C]// Thirtieth Aaai conference on artificial intelligence. 2016.
NICKEL M, ROSASCO L, POGGIO T. Holographic embeddings of knowledge graphs [EB/OL]. [2018-12-25]. https://arxiv.org/pdf/1510.04935v2.pdf.
[17]SOCHER R, CHEN D, MANNING C D, et al. Reasoning with neural tensor networks for knowledge base completion [C]//NIPS ‘13: Proceedings of the 26th International Conference on Neural Information Processing Systems. Lake Tahoe, Nevada: Curran Associates, 2013: 926-934.
[18]BOSE A J, LING H, CAO Y. Adversarial Contrastive Estimation [C]// Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2018: 1021-1032.
BOSE A J, LING H, CAO Y. Adversarial contrastive estimation [EB/OL]. [2019-01-09]. https://arxiv.org/pdf/1805.03642.pdf.
[19]YU L, ZHANG W, WANG J, et al. SeqGAN: sequence generative adversarial nets with policy gradient [C]// Proceedings of the 31st AAAI Conference on Artificial Intelligence. 2017.
YU L, ZHANG W, WANG J, et al. SeqGAN: sequence generative adversarial nets with policy gradient [EB/OL]. [2019-01-09]. https://arxiv.org/pdf/1609.05473.pdf.
[20]WANG J, YU L, ZHANG W, et al. IRGAN: a minimax game for unifying generative and discriminative information retrieval models [C]// Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2017: 515-524.
[21]FEDUS W, GOODFELLOW I, DAI A M. MaskGAN: better text generation via filling in the_[J]. arXiv preprint arXiv:1801.07736, 2018.
FEDUS W, GOODFELLOW I, DAI A M. MaskGAN: better text generation via filling in the_ [EB/OL]. [2019-01-09]. http://export.arxiv.org/pdf/1801.07736.
[22]SUTTON R S, BARTO A G. Reinforcement learning: an introduction [EB/OL]. [2019-01-08]. http://users.umiacs.umd.edu/~hal/courses/2016F_RL/RL9.pdf.
[23]SUTSKEVER I, VINYALS O, LE Q V. Sequence to sequence learning with neural networks [C]// Advances in neural information processing systems. 2014: 3104-3112.
SUTSKEVER I, VINYALS O, LE Q V. Sequence to sequence learning with neural networks [EB/OL]. [2019-01-08]. https://arxiv.org/pdf/1409.3215.pdf.
[24]CHO K, van MERRIENBOER B, GULCEHRE C, et al. Learning phrase representations using RNN encoder-decoder for statistical machine translation [C]// Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2014: 1724-1734.
CHO K, van MERRIENBOER B, GULCEHRE C, et al. Learning phrase representations using RNN encoder-decoder for statistical machine translation [EB/OL]. [2019-01-08]. https://arxiv.org/pdf/1406.1078.pdf.
[25]SUTTON R S, MCALLESTER D A, SINGH S P, et al. Policy gradient methods for reinforcement learning with function approximation [C]// Advances in neural information processing systems. 2000: 1057-1063.
SUTTON R S, MCALLESTER D A, SINGH S P, et al. Policy gradient methods for reinforcement learning with function approximation [EB/OL]. [2019-01-09]. https://www.docin.com/p-1195188340.html.
[26]WATKINS C J C H. Learning from delayed rewards [D]. Cambridge: Kings College, 1989.
[27]KINGMA D P, BA J. Adam: a method for stochastic optimization[J]. arXiv preprint arXiv:1412.6980, 2014.
KINGMA D P, BA J L. Adam: a method for stochastic optimization [EB/OL]. [2019-01-09]. https://arxiv.org/pdf/1412.6980.pdf.
[28]DUCHI J, HAZAN E, SINGER Y. Adaptive subgradient methods for online learning and stochastic optimization [J]. Journal of Machine Learning Research, 2011, 12: 2121-2159.
[29]HAN X, CAO S, LV X, et al. OpenKE: an open toolkit for knowledge embedding [C]// Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. 2018: 139-144.
HAN X, CAO S, LV X, et al. OpenKE: an open toolkit for knowledge embedding [EB/OL]. [2019-01-09]. http://nlp.csai.tsinghua.edu.cn/~lzy/publications/emnlp2018_openke.pdf.
This work is partially supported by the National Natural Science Foundation of China (U1613216, 61573386), the Science and Technology Planning Project of Guangdong Province (2017B010110011).
ZHANG Zhao, born in 1994, M.S. candidate. His research interests include knowledge representation learning, knowledge graph, natural language processing.
JI Jianmin, born in 1984, Ph. D., associate professor. His research interests include cognitive robot, knowledge representation and reasoning.
CHEN Xiaoping, born in 1955, Ph. D., professor. His research interests include logic based artificial intelligence, multi-agent system, intelligent robot.
