具有通信约束的分布式SOR多智能体轨迹估计算法
2019-10-31卢虎蒋小强闵欢
卢虎,蒋小强,闵欢
空军工程大学 信息与导航学院,西安 710077
多智能体(无人机、机器人等)同步定位与建图技术(MSLAM)是机器感知的核心技术,在MSLAM过程中,多智能体的轨迹估计是后端优化部分的一个重要环节,每个智能体利用自身测量和其他智能体的关联位姿,优化自身的轨迹以减小累积误差,可以极大提高复杂场景三维地图构建速度和定位精度,是复杂人工智能的核心技术之一。
现有多智能体轨迹估计研究涉及通信受限[1-2]、异质结构[3-4]、一致性分析[5]以及鲁棒位置重识[6]等多个技术领域;在具体实现算法上,从卡尔曼滤波[7]、信息滤波[8]、粒子滤波[9-10]到当下基于最大似然的位姿图优化方法均有涉及。但是,现有研究[11-14]基本都是将多个多智能的测量结果集中到中心节点来进行位姿的估计和优化,具有信息传输量大、易受干扰、对硬件性能要求过高等诸多技术缺陷。由于通信约束是实际应用中影响系统性能的关键因素,仅利用局部信息传输的分布式轨迹估计算法一直是MSLAM领域的研究热点,如Aragues等[15]提出分布式雅克比迭代法,对二维运动的位姿轨迹进行估计;Knuth和Barooah[16]基于黎曼优化提出了一种分布式算法,实现了三维条件下异构机器人之间的协作定位;Schuster等[17]结合滤波和图优化的各自优势,提出了一种解耦的分布式多机器人轨迹优化算法。但是,上述这3种算法均要求智能体共享自身的全部信息,大规模群体条件下,会对整个集群系统的通信带宽造成极大负荷,且系统拓扑结构扩展性差。
虽然,Cunningham等[18-19]发现上述方法具有信息交换量大的不足,并基于因子图理论[20]中的变量消元算法,提出了DDF-SAM和DDF-SAM 2.0算法,通过对因子图中的位姿进行变量消元和边缘化操作,实现了智能体之间共享只包含地图点的因子图以优化自身轨迹,在一定程度上降低了信息交换量,也使得高斯消元法成为分布式轨迹估计的主流算法。但是,高斯消元法仍存在两个重要缺陷:① 边缘化操作会使代表测量值的Hessian矩阵变得稠密,使得信息交换量随智能体之间的关联位姿数呈二次方增长;② 需要好的线性化点,在大规模场景下很难保证智能体之间的一致线性化。
在此背景下,本文针对通信约束场景下多智能体最大似然轨迹估计问题,提出了一种基于超松弛迭代法(Successive Over-Relaxation, SOR)的分布式估计算法,旨在兼顾最小化信息交换量和保证轨迹估计精度,算法通过将轨迹估计转化为二次优化问题,并重新参数化为线性问题,最后采用分布式SOR算法分别求解,从而达到位姿优化的目的;此外,由于对估计量的初始值采用了标记初始化方法[21],减少了收敛所需的迭代次数,极大程度满足了多智能体系统的实时性要求。
1 多智能体轨迹估计模型
考虑三维空间中一组智能体的集合Ω={α,β,γ,…},定义时刻i智能体α的位姿为xαi,这里xαi∈SE(3)(SE(3)为三维空间中的特殊欧式群);又定义xαi=(Rαi,tαi),其中Rαi∈SO(3)为旋转矩阵(SO(3)为特殊正交群),tαi∈R3为平移向量。
显然,智能体α的轨迹可以表示为时序上排列的位姿集合xα=[xα1,xα2,xα3,…],如图1所示。
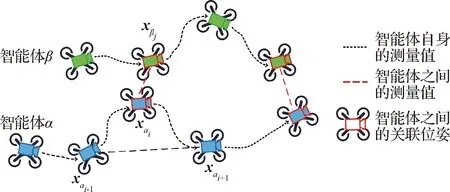
图1 多智能体轨迹估计示意图
1.1 通用量测模型
假设每个智能体可直接获得两类相对位姿的测量信息:智能体自身的测量和智能体间的测量,其中,智能体自身的测量由里程计信息(时间上连续的位姿,如图1中的xαi和xαi+1)和回环测量(时间上不连续的位姿,图1中的xαi-1和xαi+1)组成;智能体间的测量为不同智能体某时刻的相对位姿(可以通过视线内观测、相遇点测量和回环检测等方式得到) 图1中连接xαi和xβj的红线。
显然,两种不同类型的测量均为某一对智能体位姿之间的相对测量,记为xαi和xβj,测量模型可以表示为
(1)

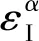
1.2 最大似然位姿估计
设x=[xα,xβ,xγ,…]为所有智能体待估计轨迹,又可知所有测量相互独立,则x的最大似然估计为
(2)
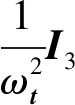
则x≐{(Rαi,tαi),∀α∈Ω,∀i}的最大似然估计可以通过求解集中式目标函数得到:
(3)
为求解式(3),通常方法是先通过中心服务器或者指定一个智能体收集所有智能体的位姿轨迹和测量值ε,然后利用流形上的迭代优化[23]、快速近似[24]和凸松弛[25]等方法来进行全局的优化求解,实际中由于计算能力和通信带宽的约束,集中式方法在绝大多数应用场景下不具有可扩展性,而分布式的方法则能很好地解决这个问题,因此需要设计一种分布式的方法来求解式(3)。
2 基于SOR的分布式轨迹估计
2.1 分级求解策略
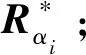
2.1.1 旋转矩阵的松弛初始化
将式(3)中的第2项提取出来,作为旋转估计的目标函数:
(4)
这里Rαi∈SO(3),根据文献[26]可将式(4)改写为无约束的形式:
(5)
将式(5)的结果反投影到特殊正交群SO(3),便可以得到旋转估计值。
简洁起见,改写式(5)为
(6)
式中:r为由所有未知旋转量Rαi(∀α∈Ω,∀i)按列展开后整合成的单个向量,矩阵Ar和向量br均为已知量。
至此问题转化为常规的线性最小二乘问题:
(7)
2.1.2 完整位姿估计
(8)
将式(8)的非线性指数映射进行一阶展开:
(9)
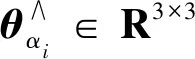
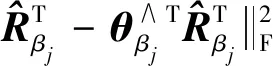
(10)
将所有的待求解量θαi、tαi(∀α∈Ω,∀i)表示为单个向量p,则式(10)可以简化为
(11)
进一步可得
(12)
2.2 分布式算法描述
2.1节的分级位姿优化方法中,将非线性的式(3)转化为了两个线性最小二乘问题式(7)和式(12),通常可以用集中式两级求解方法进行一次迭代的整体求解;但在多智能体场景中,式(7)和式(12)对应的Hessian具体结构也决定了其可以用完全分布式的方法来求解。
本节将具体阐述一种新型的只需共享部分位姿的、基于超松弛迭代法(SOR)的分布式求解方法。
在式(7)和式(12)中,若待求解量r和p按所归属的不同的智能体分为多个子向量形式,r=[rα,rβ,rγ,…],p=[pα,pβ,pγ,…];则式(7)和式(12)均可表示为通用形式:
(13)
式中:x为待求解的未知量,根据x的块结构,可以将矩阵H和向量g划分为等式右的形式,因此又有:
(14)
将式(14)中与xα相关的项提出来,得到
(15)
式(15)表示的等式集合本质上跟式(13)相等,但式(15)中每个等式均与特定智能体相关联,清晰地表示了每个智能体待估计变量与其他变量的关系,易于分布式求解。
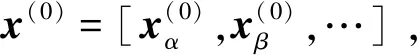
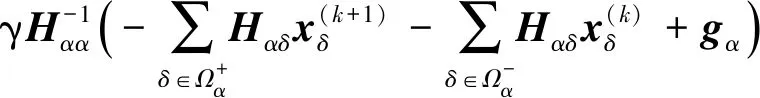
(16)

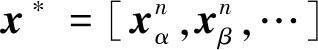
2.3 分布式SOR算法的信息交换策略
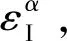
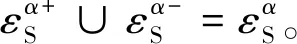
(17)
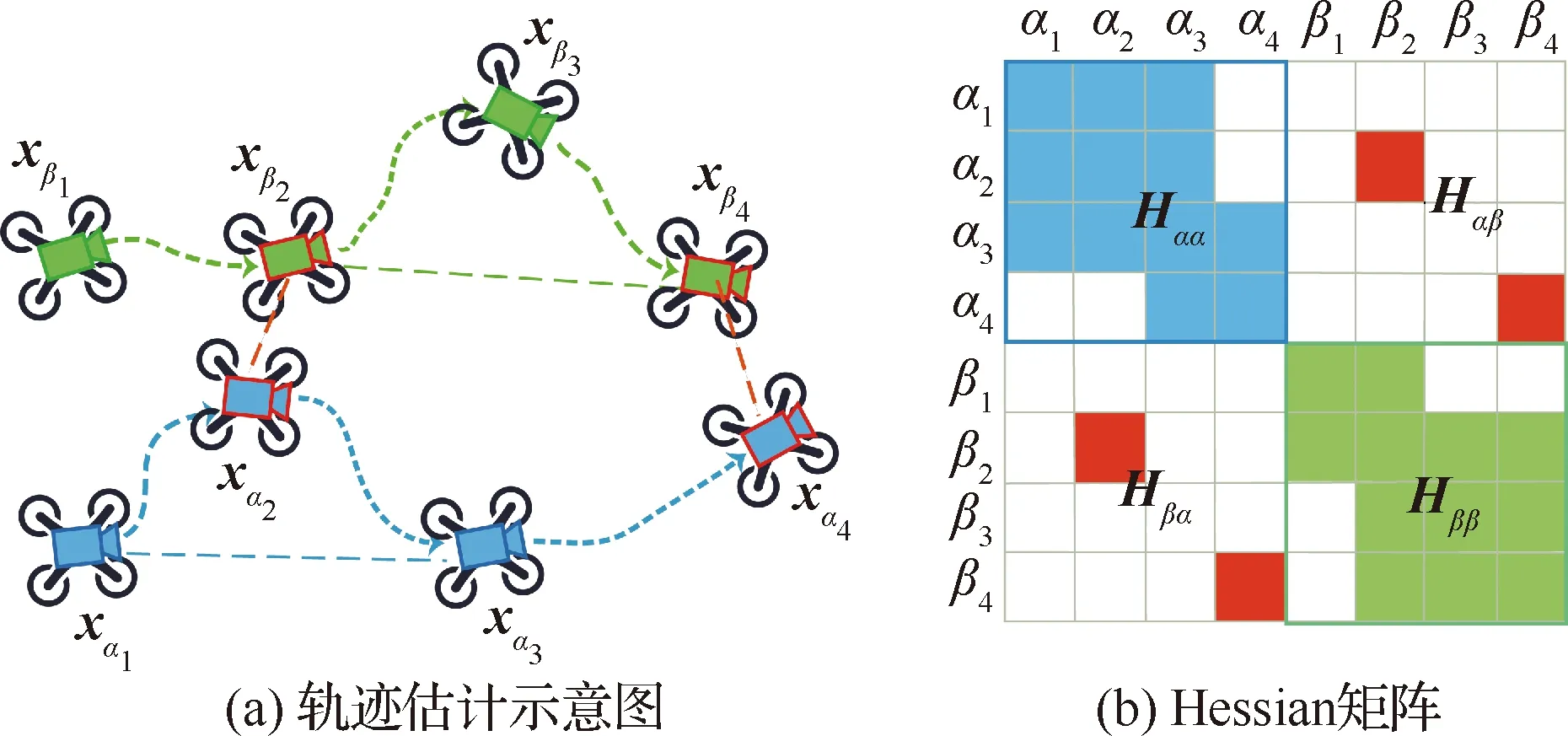
图2 轨迹估计示意图及其对应的Hessian矩阵
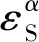
2.4 标记初始化方法
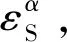
(18)
迭代完成后同样对β进行标记;重复上述步骤,直至所有智能体均完成初始化。
综上,本文算法的整体流程如图3所示。
3 实验分析
3.1 实验数据设置
3.1.1 仿真数据集设置
为了测试本文算法对智能体规模的可扩展性和收敛性,共设置了7种不同的测试数据:分别是数量为2、4、9、16、25、36、49的多智能体轨迹仿真数据。如图4所示,各种颜色的立方体代表不同的智能体,每个智能体在立方体表面上运动,其中立方体的顶点表示待优化的智能体位姿,边表示智能体自身内部测量值(即顶点间的相对位姿);当智能体处于相邻的顶点时,可以进行局部的通信(模拟通信受限条件)和测量,产生智能体间测量值,如图4中连接不同智能体的灰色边。仿真中设置测量噪声的标准差为:σR=3°,σt=0.2 m,仿真结果取10次Monte-Carlo仿真的平均值。
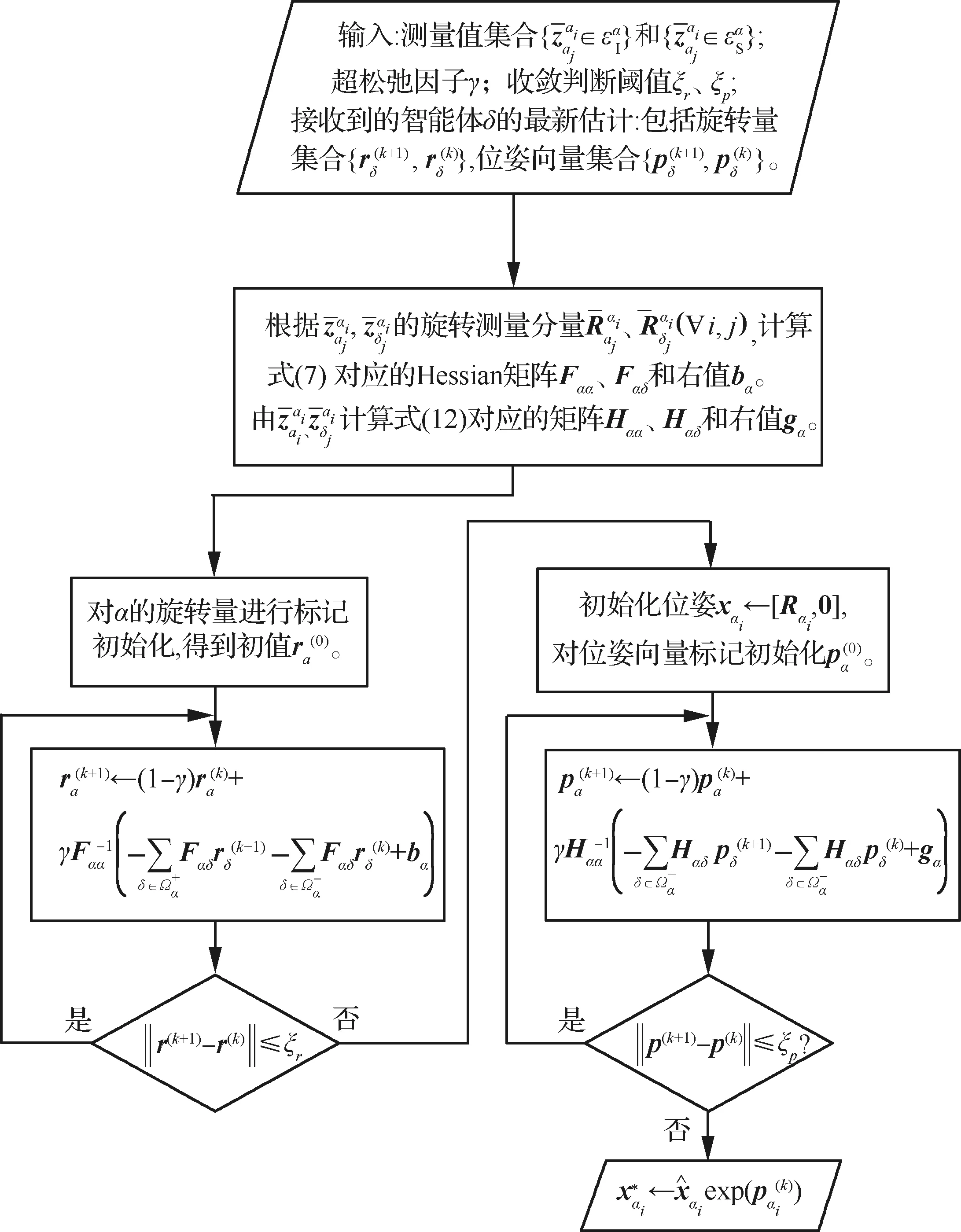
图3 整体算法流程
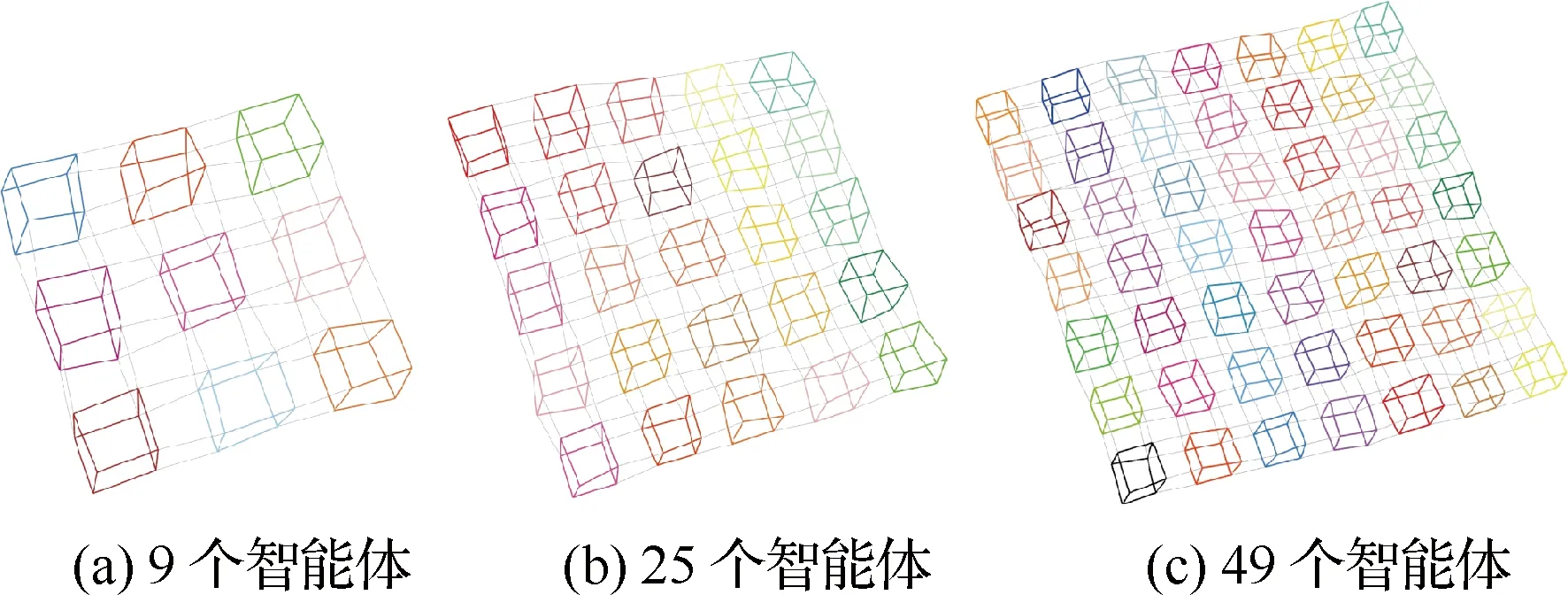
图4 仿真实验数据设置
3.1.2 实测数据集设置
为了分析对比不同测试条件下最优松弛因子选取的差异,选取分割CSAIL实测数据集进行实验,如图5所示,蓝色和绿色细线代表两个智能体的里程计轨迹,蓝色和绿色粗线表示机智能体自身回环测量,深蓝色粗线表示智能体之间的回环测量。
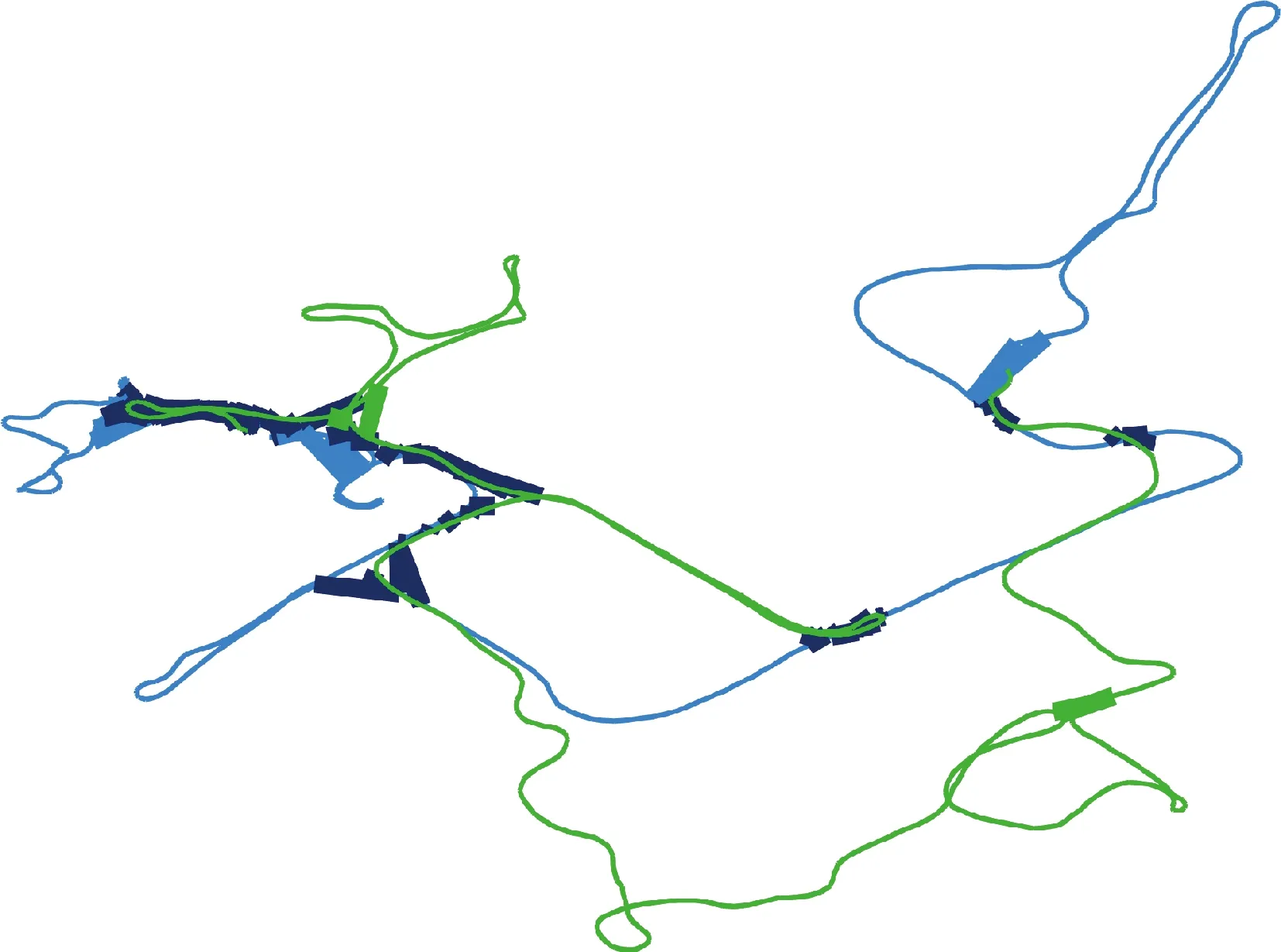
图5 CSAIL实测数据集
在SOR算法中,通过求解式(7)和式(12),分别使式(6)和式(11)式达到最小值,可知第k次迭代整体的旋转估计误差为
(19)
第k次迭代整体的位姿向量误差可定义为
(20)
随着迭代次数的增加,er(k)、ep(k)将逐步收敛,迭代次数越多,求解的精度就越高。实验中未做特殊说明,判断两种误差收敛的阈值通常设置为ξr=ξp=10-2。
3.2 实验结果
3.2.1 松弛因子影响分析
1) 仿真数据集实验
为了分析松弛因子的选择对实验结果的影响和确定对应数据集的最优松弛因子,选取智能体规模为49的仿真数据场景,在(0,2)范围内对γ选取了9种不同的值进行实验,图6表示在不同的γ值下,整体的姿态估计误差和位姿向量估计误差随迭代次数的变化情况,可知当γ∈(0,2)时,分布式SOR算法总能收敛,而且,γ选取在1附近能达到较快的收敛速度,收敛误差也较小。为了获得最佳松弛因子,进一步选取γ∈[0.8,1.2],步长取0.05,得到如图7和图8结果。
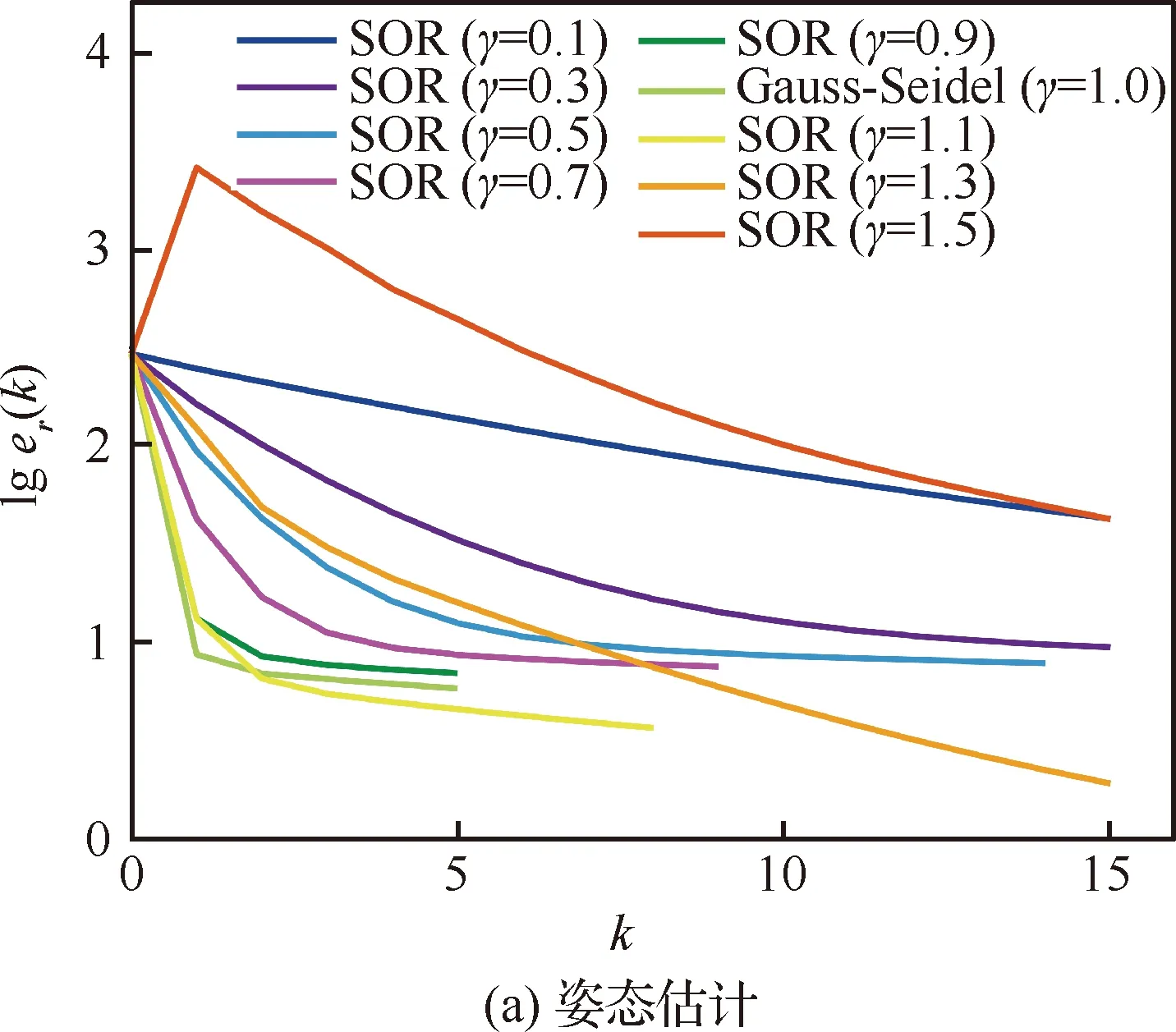
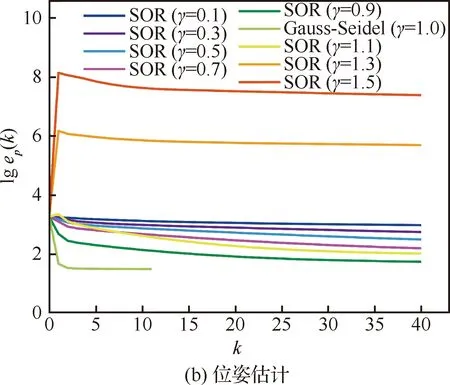
图6 仿真数据集中不同γ下旋转和位姿的收敛过程
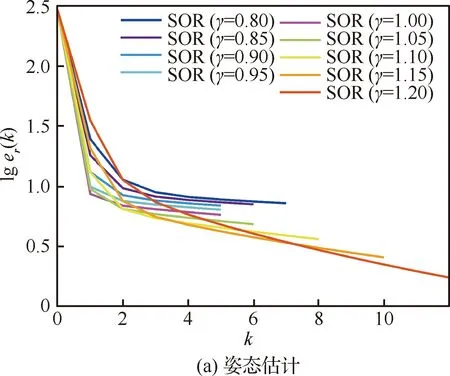
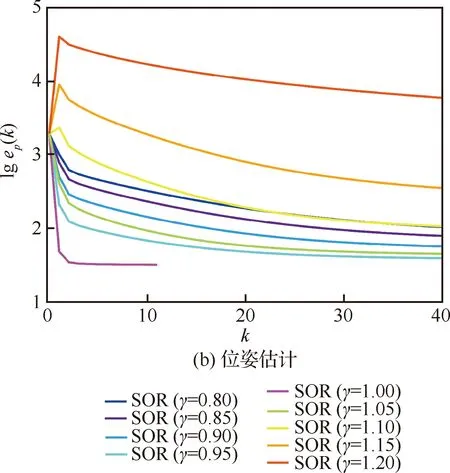
图7 仿真数据集中不同γ下旋转和位姿的收敛过程
在松弛因子γ选取步长较小的情况下,从位姿估计曲线图7(b)可以看出,松弛因子1可使位姿估计结果达到最优。
图8为姿态估计和位姿估计两个过程的迭代次数随松弛因子γ的变化曲线,易知γ=1.00将使旋转和位姿估计两步均达到最快的收敛速度。
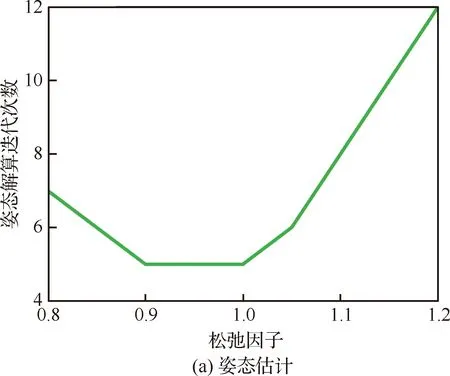
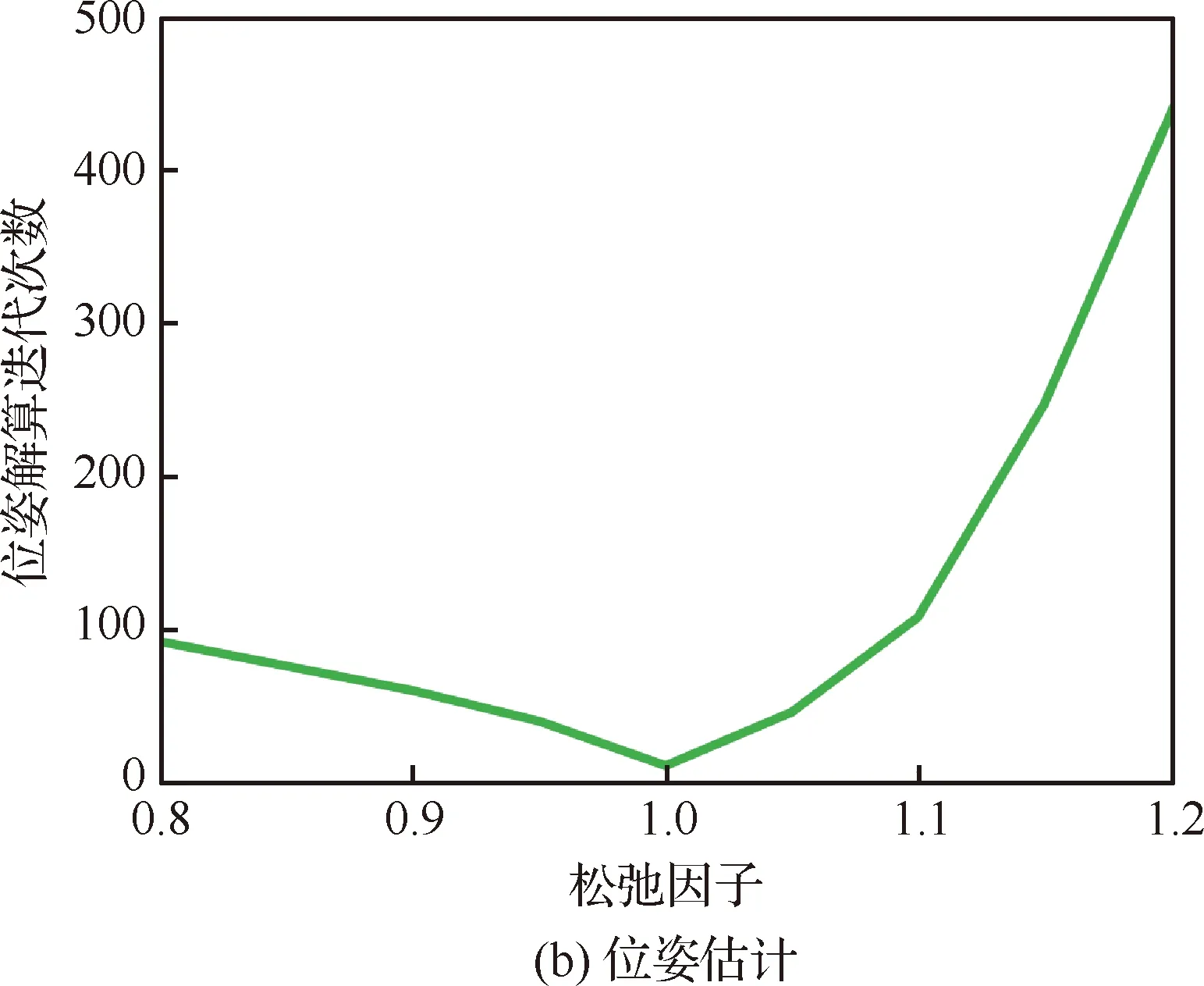
图8 仿真数据集中不同γ下收敛所需的迭代次数
综上可得,在仿真合成数据集的实验中,最优松弛因子γ约为1.00,因此接下来几个小节仿真数据集下的实验,将固定γ=1.00。
2) CSAIL数据集实验
由于松弛因子的选取与系数矩阵有关,因此最优松弛因子需要根据不同实验条件(对应不同的测试数据)的实际情况来进行调整。在CSAIL数据集上,选取松弛因子γ∈[0.80,1.20],步长为0.05进行实验,得到图9和图10所示结果。
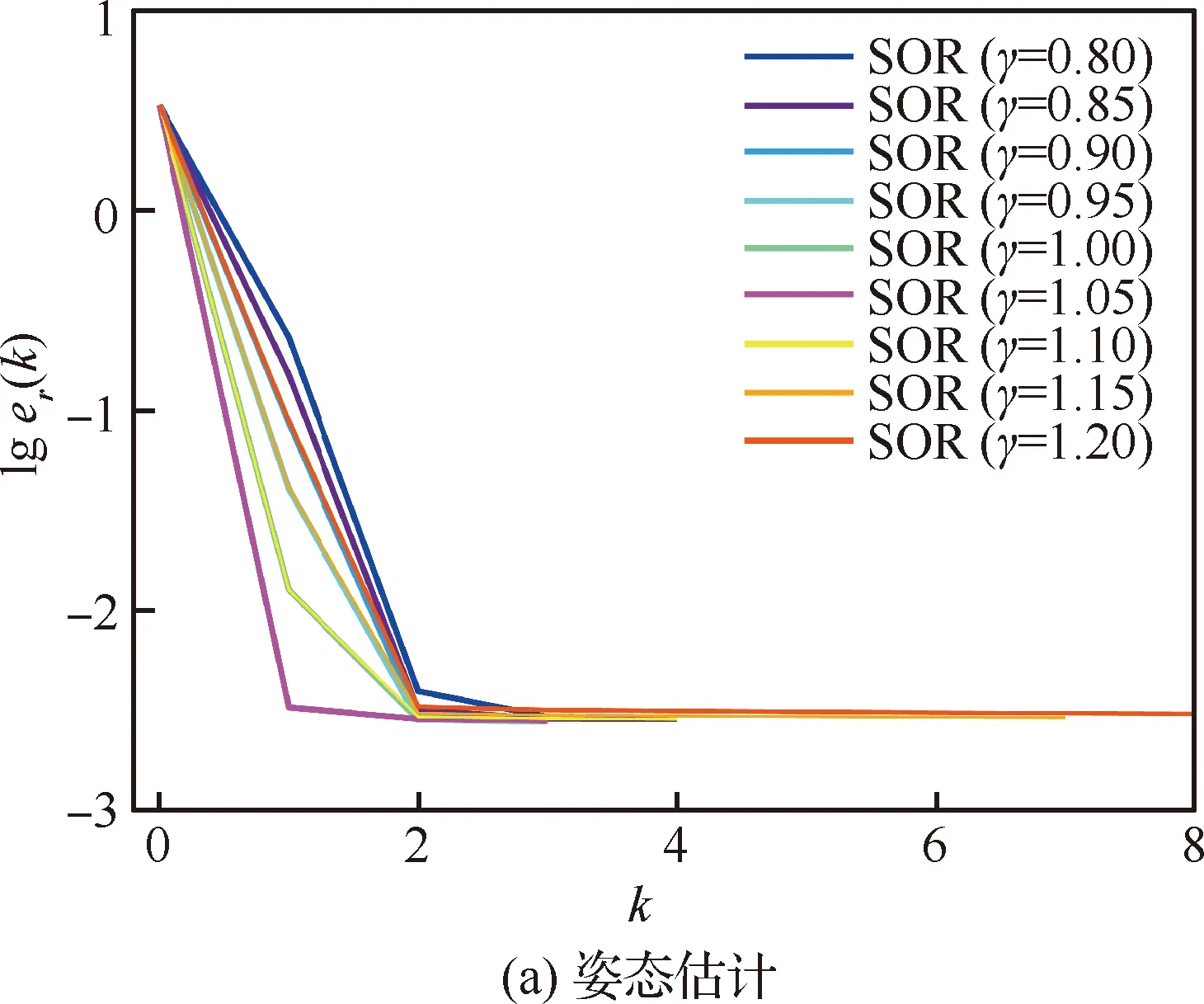
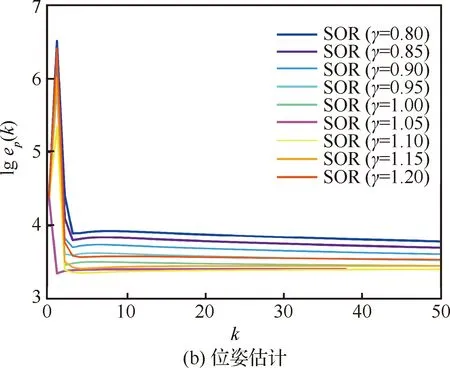
图9 CSAIL中不同γ下旋转和位姿的收敛过程
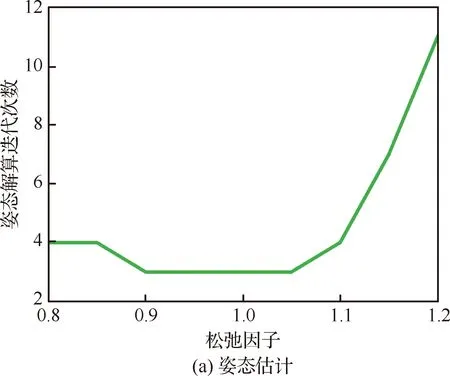
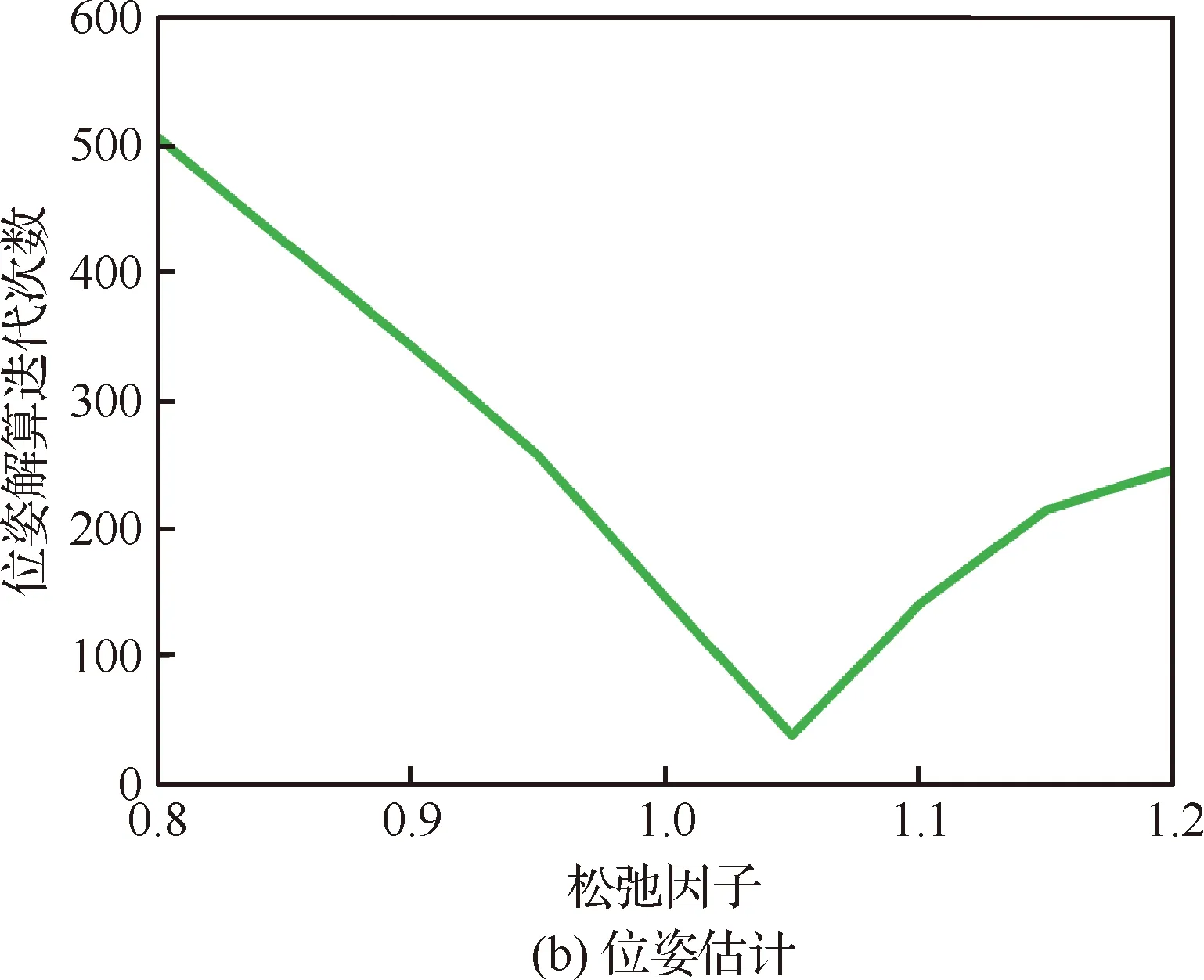
图10 CSAIL不同γ下收敛所需的迭代次数
综合分析姿态估计和位姿估计两个过程的估计误差和迭代次数,可以得出CSAIL数据集上最优松弛因子在1.05附近取得。
综上,在不同的测试条件下,可以对松弛因子γ进行调整,从而使分布式SOR多智能体轨迹估计算法的收敛速度和估计精度达到最优效果。
3.2.2 局部收敛误差分析和迭代停止条件
本节仍以49个智能体的轨迹仿真数据为测试样本,对每个智能体上运行的分布式SOR算法的收敛性进行分析,进而给出分布式求解过程的收敛性与整体收敛性的关系。
如图11所示,不同的颜色代表不同的智能体上算法的收敛过程,eri(k)和epi(k)分别为第i个智能体在第k次迭代时的姿态和位姿求解误差。由于本文算法建立在位姿图的基础上,其利用各个智能体下短间隔可靠的局部里程计测量和回环测量构建一个涵盖全部智能体的全局优化问题,因此算法并不保证每个智能体的局部位姿达到最优,而是使全局位姿最优,如图11(a)姿态解算过程最上方的蓝色曲线,其误差值从-1增长至收敛值,而其他智能体姿态则减小至收敛值,但从整体来看,如图6(a)中γ=1时的曲线,姿态误差则呈下降趋势。从图11(b)的位姿误差变化趋势可得同样结论。图11(c)和图11(d)为迭代过程中姿态和位姿估计值的变化量,经过几次迭代之后,变化量会很快减小到10-2量级,如3.1节提到,实验中设定的收敛阈值为ξr=ξp=10-2,当估计值的变化小于阈值时,就认为算法收敛,进而停止迭代。
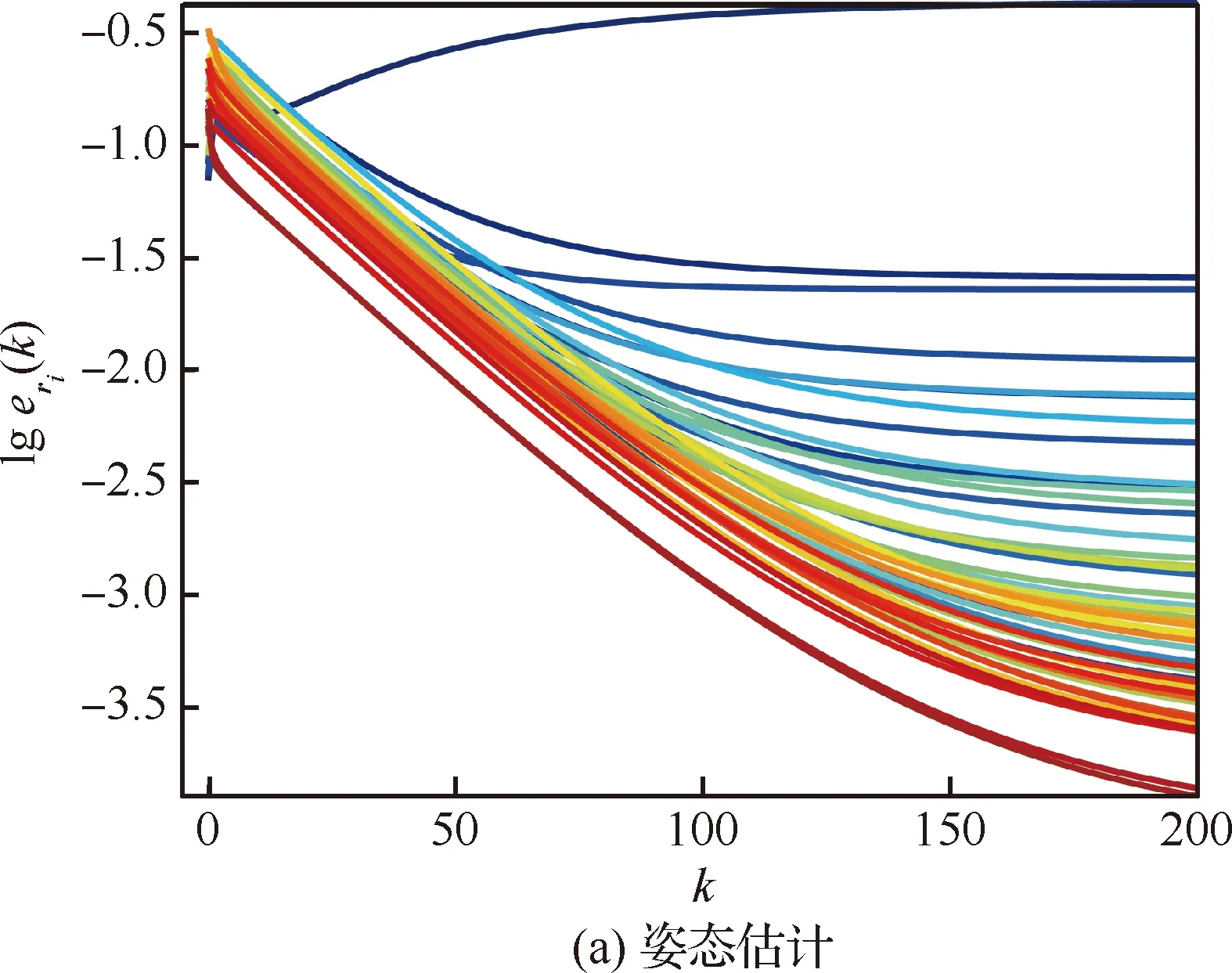
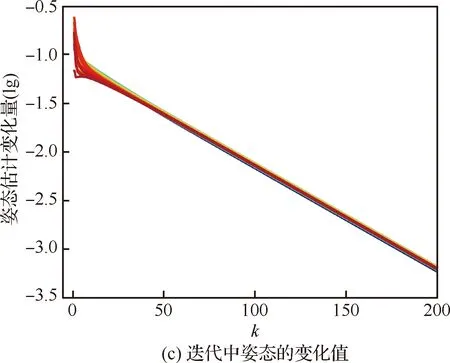
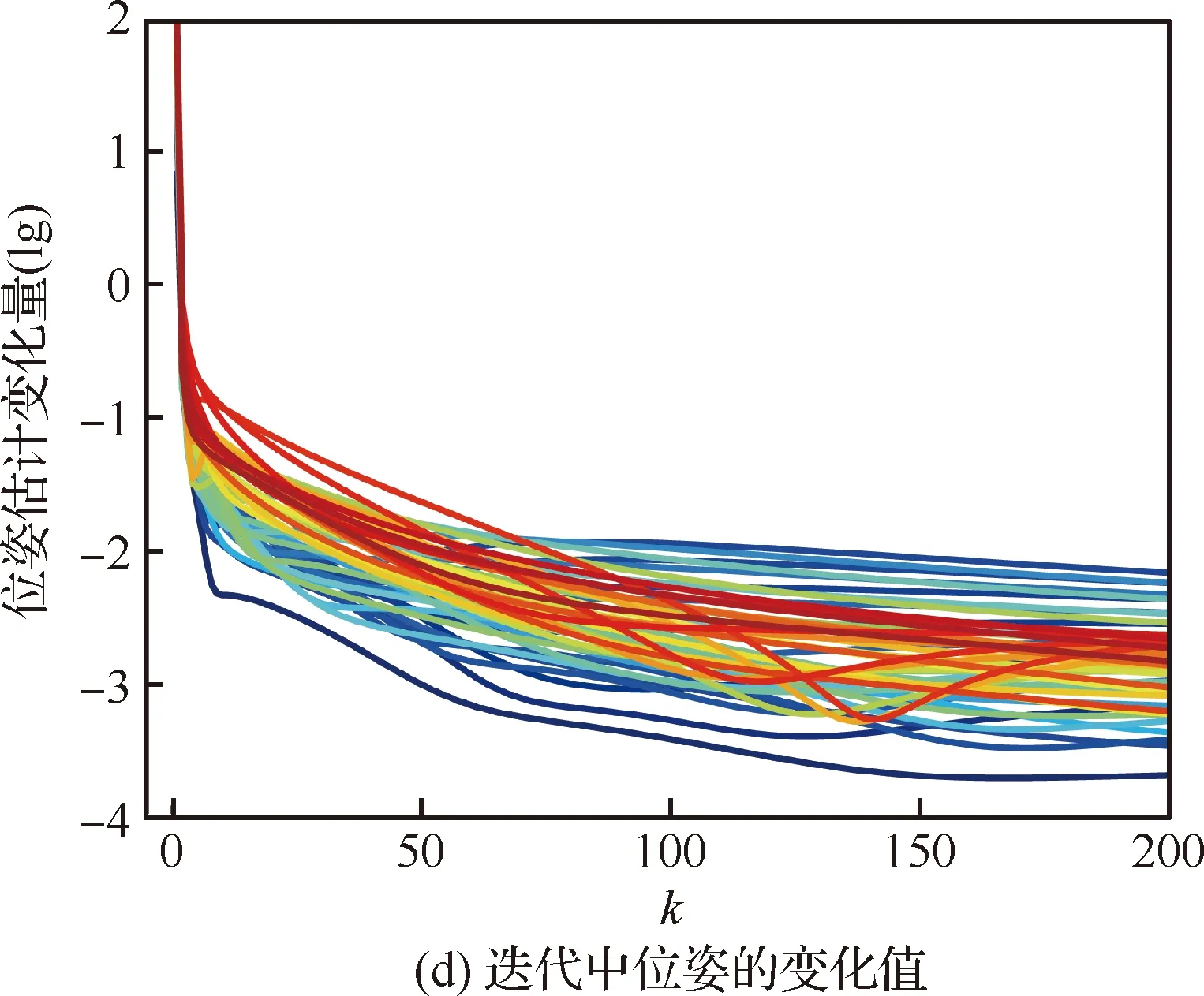
图11 每个智能体上算法的收敛性
图12为在49个智能体数据场景下,算法迭代10次和1 000次时整体的位姿(位姿中的平移部分)轨迹,可以看出在迭代10次时,相较于初始的轨迹,估计位姿的精度已经有了很大的提高,且相对于迭代1 000次的结果,误差并没有特别明显的改观。因此,可以认为本文算法在迭代次数较少的情况下也能取得较高的估计精度。
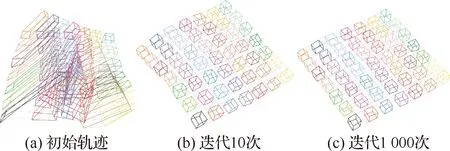
图12 估计轨迹的可视化图
3.2.3 不同智能体下算法的扩展性
为了分析智能体数量对算法性能的影响,分别在不同的数据场景下进行实验,图13为7种仿真数据(2、4、9、16、25、36和49个智能体)下运行的结果,可以看出整体的姿态估计和位姿估计过程均能很快收敛,且由图13(b)可知,对于位姿解算来说,智能体数量规模的增大会使整体的收敛误差增大,但每个智能体的平均误差相当,因此算法对智能体规模的适应性和可扩展性较强。
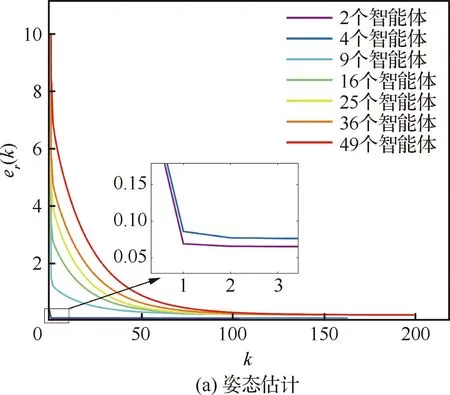
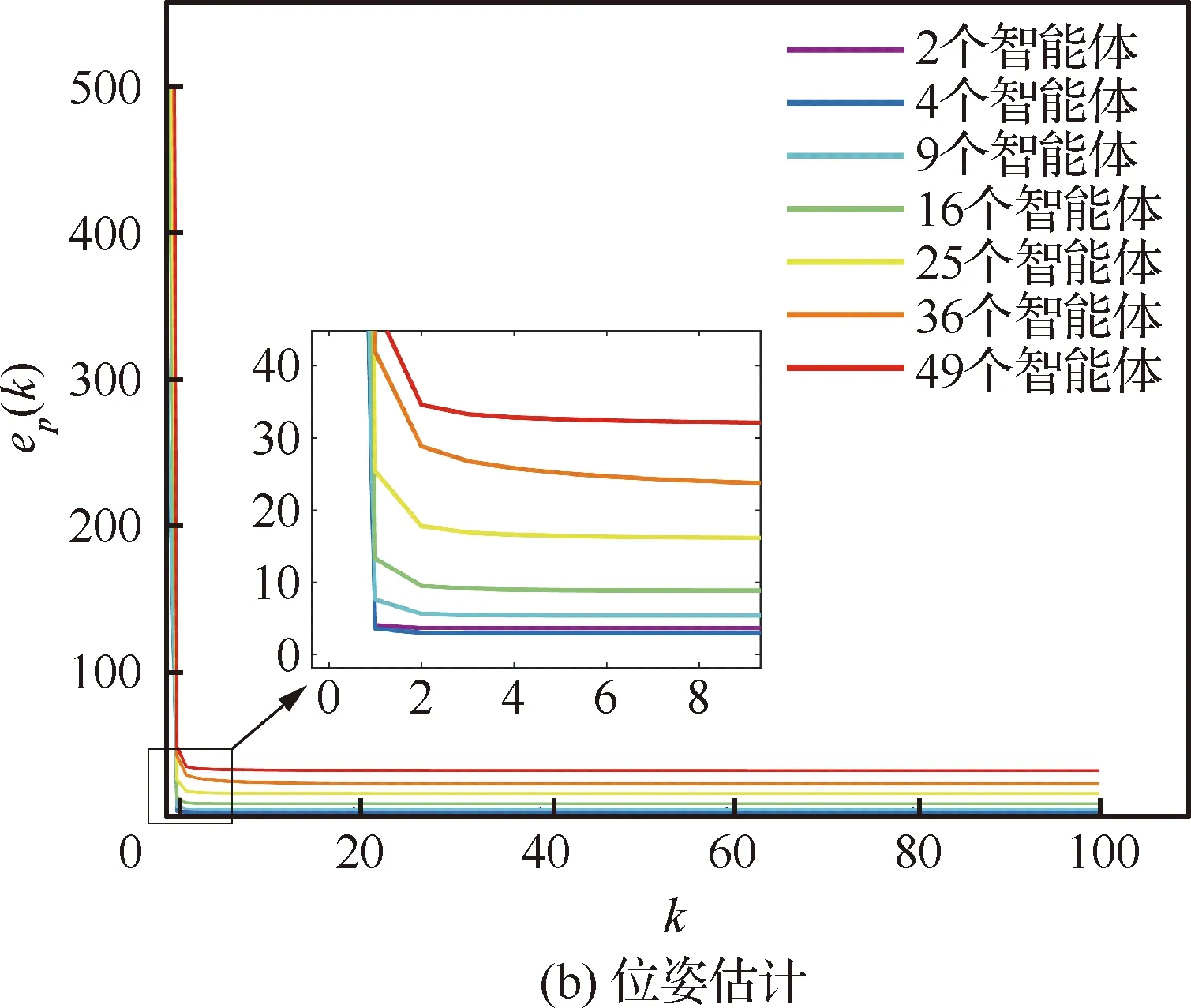
图13 不同规模智能体下算法的收敛性
3.2.4 标记初始化对收敛速度的影响
2.4节中提出了一种标记初始化方法,相对于分别将r(0)、p(0)初始化为零向量的方法,标记初始化方法则能加速算法的收敛速度。如图14所示,为49个智能体实验数据场景下的初始化方法的对比,可以看出标记初始化方法减少了姿态估计和位姿估计的迭代次数,其中在位姿估计过程上体现尤为明显。由于优化过程中信息交换量与迭代次数呈线性关系(每次迭代均要进行通信),标记初始化方法进一步减少了数据传输量。因此,在本节的其他实验分析中,均默认采用了标记初始化方法。
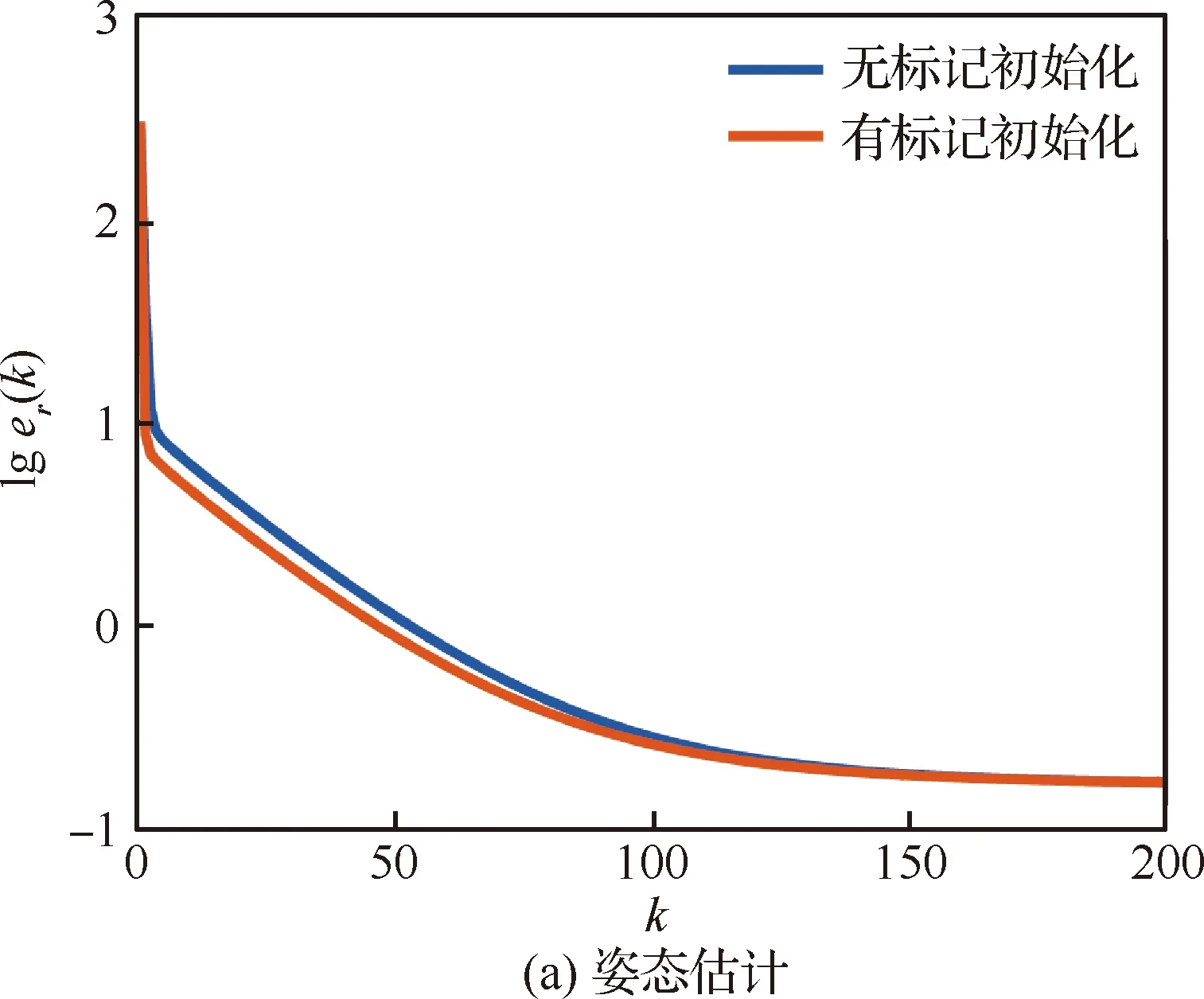
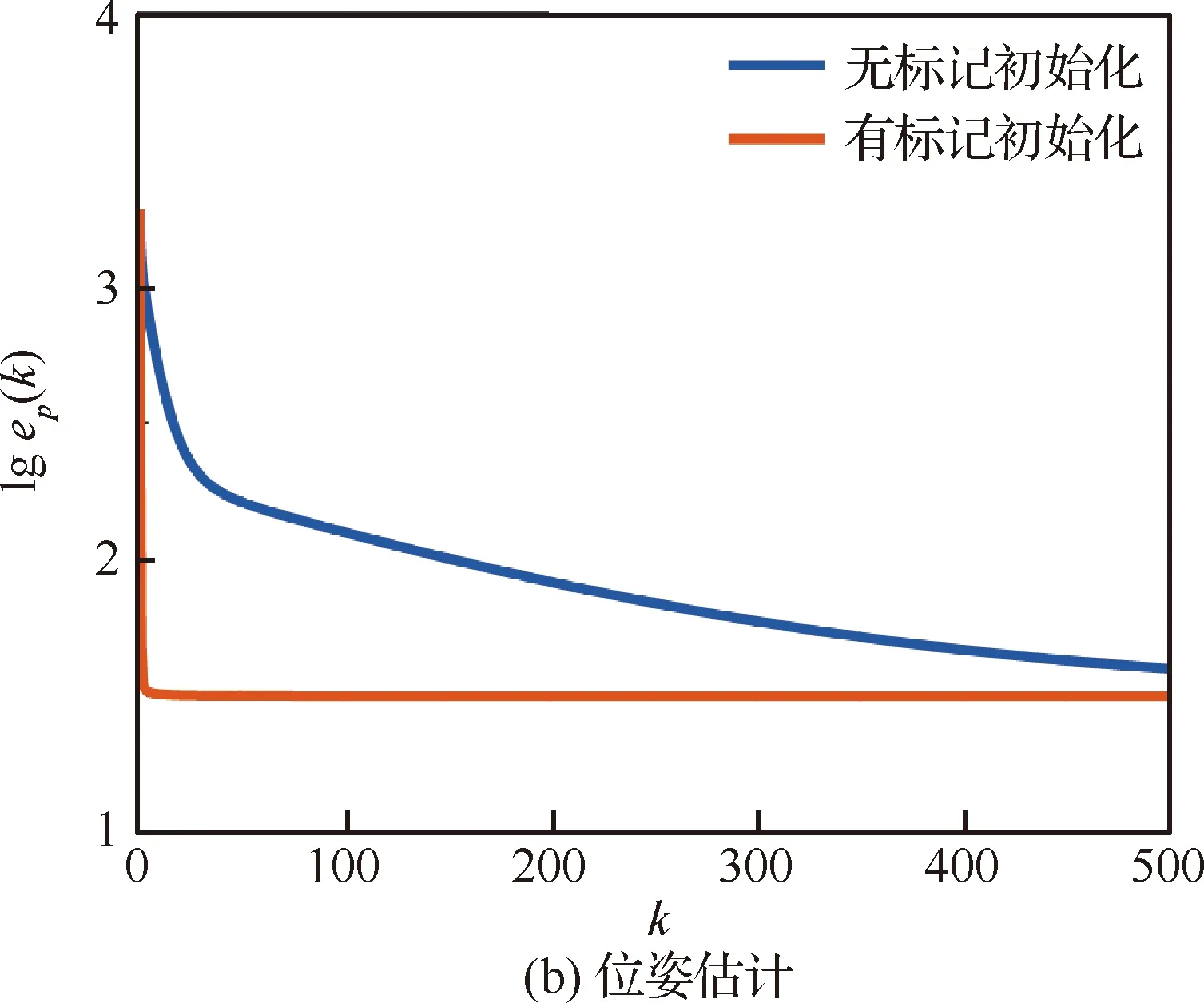
图14 有标记初始化和无标记初始化收敛过程对比
3.2.5 算法精度分析
为了评估本文算法的轨迹估计精度,分别对位置误差和旋转误差进行分析。类似文献[28]提出的方法,定义绝对位置误差(Absolute Translation Error,ATE)和绝对旋转误差(Absolute Rotation Error, ARE)两种策略:
(21)
(22)
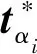
表1为本文算法、集中式两级求解算法和初始情况下的ATE和ARE值。可以看出,当判断阈值ξr=ξp=10-2时,本文所提分布式算法可以达到集中式算法的精度水平,且当智能体规模为49时,本文算法的位置误差仍然小于0.15 m,旋转误差小于0.03°。
当ξr=ξp=10-1时,相对于10-2条件下的估计结果,精度虽有所下降,但在实验中各规模大小的智能体场景下,位置估计精度仍能达到分米级,且旋转估计误差小于0.1°。
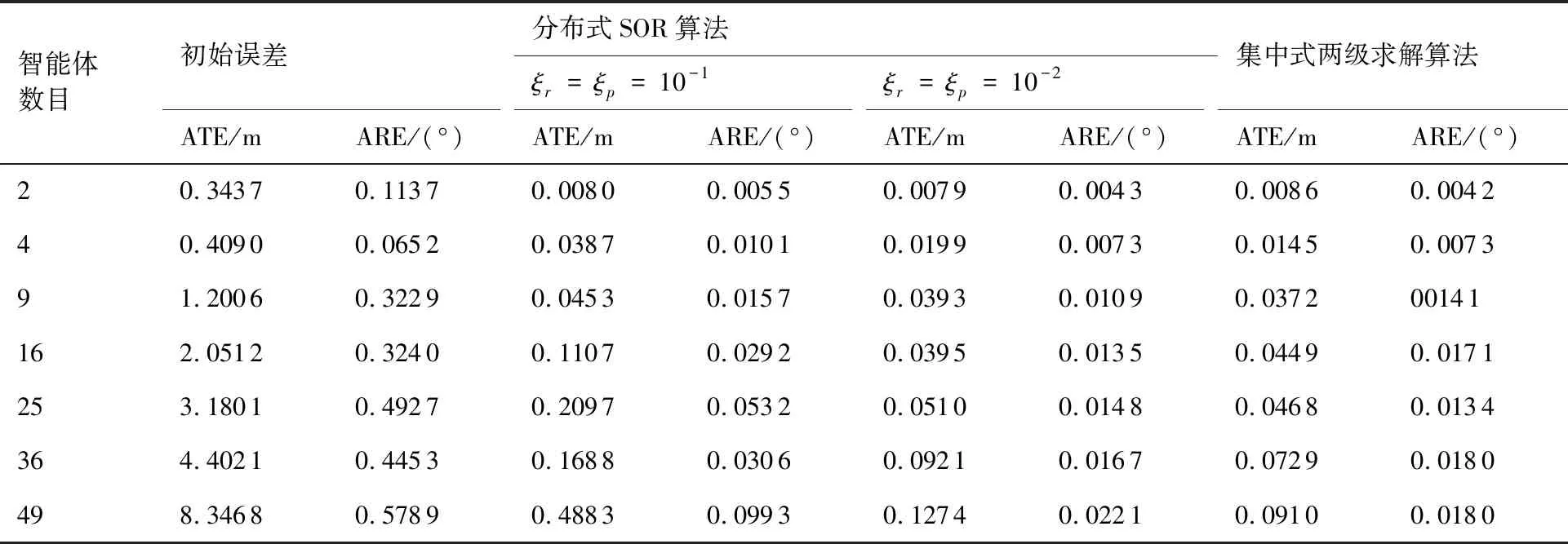
表1 ATE和ARE误差对比
3.2.6 信息交换量分析
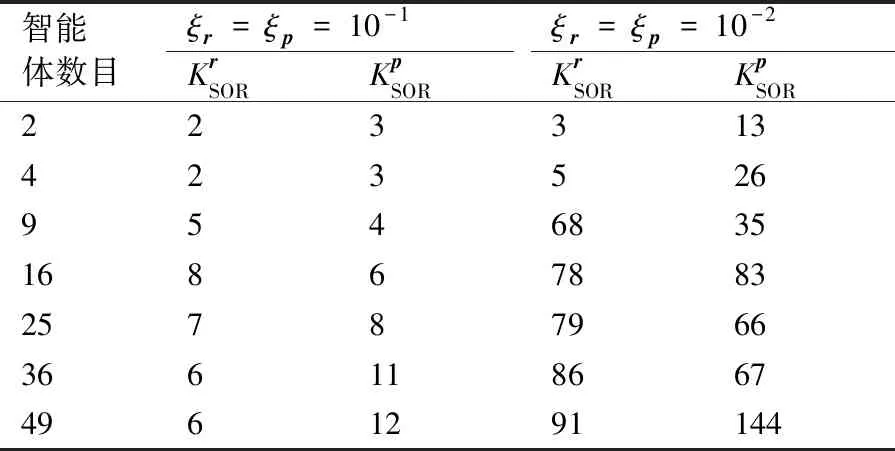
表2 不同阈值下算法的迭代次数
图15为本文算法与DDF-SAM算法的信息传输量对比,分析可知,即使判断阈值设为10-2(即迭代次数较大条件),本文算法的信息传输量在小集群条件下仅为DDF-SAM的0.01%,在49个智能体的大规模集群实验条件下,信息传输量也只达到DDF-SAM的0.06%,而且可以看出,DDF-SAM的信息交换量随智能体数目增长大致呈二次曲线,而本文算法基本为线性增长。
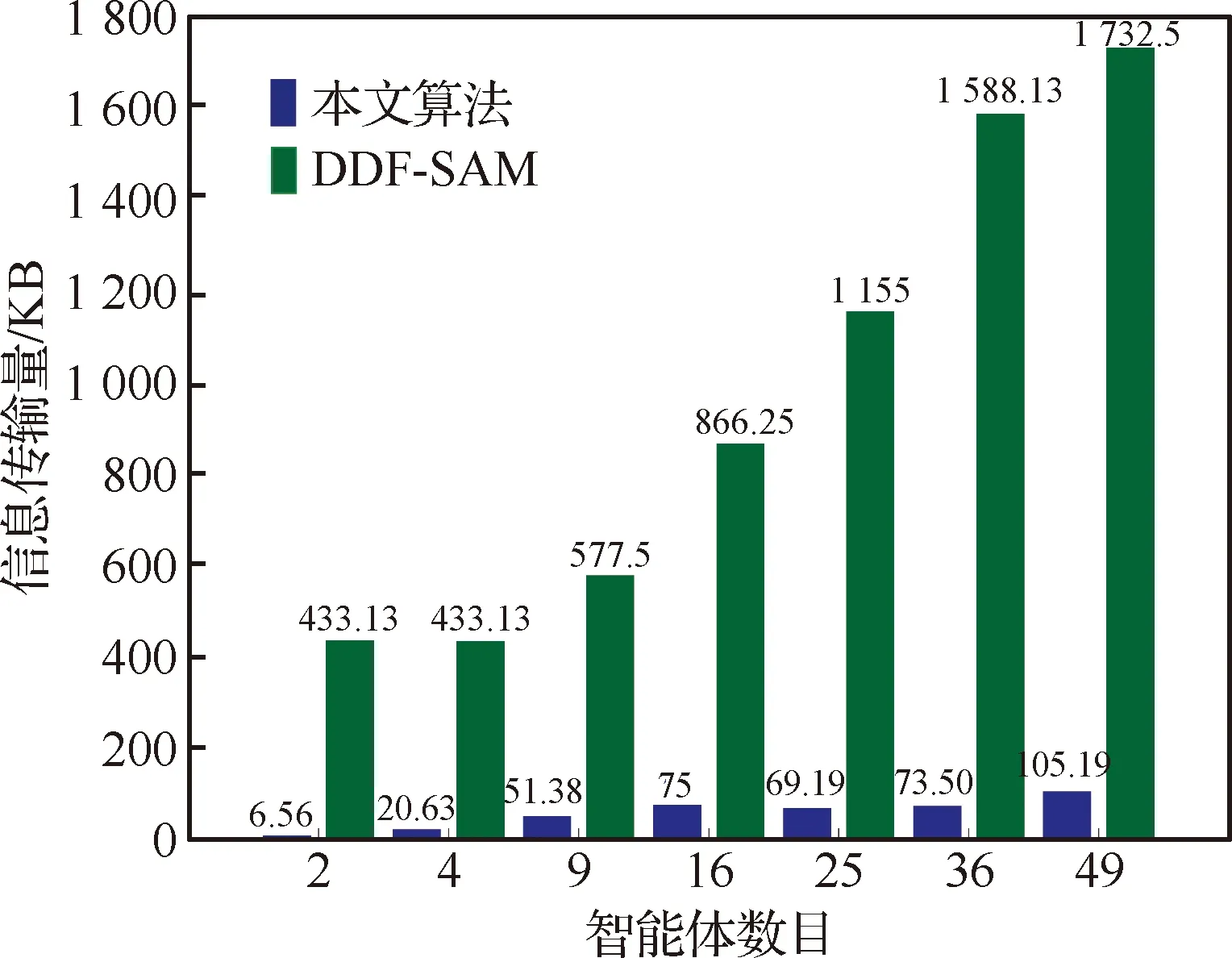
图15 信息传输量对比
4 结 论
1) 提出了一种基于超松弛迭代法的分布式两级多智能体轨迹估计算法,利用多智能体之间相对位姿的测量,达到优化自身位姿轨迹的效果。实验表明,所提算法有以下优势:① 分布式SOR算法的信息交换少,且只需进行局部信息传输,能适应通信受限的条件;② 收敛所需的迭代次数较少(即所需通信次数),且能达到跟集中式算法同样的精度;③ 算法对智能体规模的适应性强,能应对大规模场景下多智能体的轨迹估计。
2) 本文所提分布式估计算法的信息交换量与智能体之间的关联位姿数呈线性关系,且不需要线性化点,因而能很好地扩展到大规模多智能体场景中。由于迭代过程只要求智能体之间共享与相对测量相关的部分轨迹数据,即智能体不会存储其他智能体的完整轨迹,因此也满足隐秘性要求的应用场景。
