一种改进的差分进化算法及其在SVM 中的应用
2019-10-31王珂周瑶赵媛媛
王珂,周瑶,赵媛媛
(西安建筑科技大学,西安710055)
0 引言
作为一个信息大平台,互联网的舆论功能为信息交流提供了一个便捷的渠道。然而网络上的信息良莠不齐,及时准确发现网络中的舆情信息和热点事件并加以监督与引导,对社会的和谐稳定发展具有重要意义,尤其是根据分析的结果对舆情进行预测,这对有关部门很有必要[1-2]。
网络舆情研究与分析的重要依托技术是文本分类。文本分类作为舆情监管的基础,其重要性不言而喻。SVM 是文本分类中应用最为广泛的一个算法。SVM[3]自提出之日起至今虽然只有短短二十多年,但是它在分类问题中表现出来的优越性能备受机器学习领域学者的青睐。影响SVM 的分类效率和模型预测性能的主要因素是核参数[4],但传统的核参数选择并没有一套可遵循的理论方法,往往依靠经验进行穷举或通过交叉验证进行大量实验选取合适的参数,这些方法不仅需要依靠大量的人力物力,而且最终并不能得到令人满意的结果。本文针对SVM 这一问题提出了差分进化算法智能选取核参数。
差分进化算法是一种智能优化算法,用它来智能选取SVM 的核参数可以避免人为经验产生的偶然与误差,同时还可以节省人力物力。差分进化算法相较其他优化算法有较多优势,如:参数少,算法简单,易于实现。但也因为其容易陷入早熟收敛这一特性而受到很多局限。因此,本文首先要对标准DE 算法进行改进,再令其进行SVM 的参数寻优。本文是对标准差分进化算法进行改进,并用该算法优化SVM 的核参数,最后将其应用到分类问题中,实质上是对差分进化算法的改进与应用。
1 差分进化算法的改进
1.1 DE算法基本原理
差分进化算法是一种智能随机搜索算法[5]。变异、交叉、选择是差分进化算法的主要操作算子。其基本思想是:首先初始化各参数,随机生成初始种群,然后从初始种群中随机选择两个不同的个体,利用其向量差与第三个个体按照一定的规则生成新的变异个体。然后利用该变异个体与父代的目标个体进行交叉生成试验个体。判断试验个体的适应度与目标个体适应度值的大小,适应度高的保留,差的淘汰,不断迭代,直至逼近全局最优解[6]。然而标准差分寻优算法受到种群大小、F 值、CR 以及变异策略等的影响。
1.2 标准DE局限性分析
DE 算法因其实现简单,算法鲁棒性好而备受关注,但差分进化算法也有自身的局限性,即易陷入局部极优而出现早熟收敛[7],造成这种现象主要是因为随着迭代次数的增加,种群多样性降低,使得个体差异太小从而导致算法不能达到全局最优点。差分进化算法的收敛速度主要受其控制参数和变异策略的影响[8]。
变异因子F 决定着种群的多样性和收敛速度,F一般取值范围在[0,2]。当F 较大时全局搜索能力提高,不易陷入早熟收敛,但收敛速度减慢;反之,算法的收敛速度加快,对种群扰动小,易陷入局部极优出现早熟收敛。交叉概率CR 通常的取值范围为[0,1],当CR较大时,局部搜索能力加强收敛速度加快,易陷入局部极优;反之,CR 取值较小时,种群多样性增加有利于全局搜索。
1.3 改进的DE算法
为了避免标准DE 易陷入早熟收敛这一特点,本文提出了一种自适应组合优化差分进化算法(Adaptive Combinatorial Optimization Differential Evolution,ACODE)。在搜索前期注重全局搜索能力,在后期主要进行精确的局部搜索,加快收敛速度。因此需要合理选取F 和CR 的值[9-10]。
为了使算法在搜索前期进行全局搜索,F 取值应较大,CR 较小;后期进行局部搜索则需要F 小CR 大,F 和CR 的值需要进行动态变化。
为使得搜索前期取较大的F,较小的CR,搜索后期有较小的F 和较大的CR,本文使F 和CR 动态变化。
本文F 和CR 的动态变化如式(1-2)所示。
其中Fmax、Fmin 分别为F 的取值上限和下限,CRmin、CRmax 分别为CR 取值的上限和下限,其中最大进化代数用T 表示,当前进化代数用t 表示。
DE 中还存在一个重要影响因素,即变异策略。式(3)和(4)是其中两种常见的变异模式,通常情况下使用单一且固定的变异模式,最常采用的是DE/rand/1。
DE/rand/1:
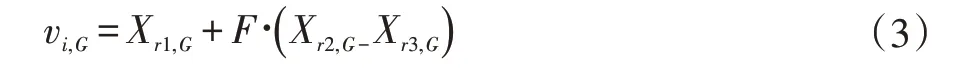
DE/best/1:

其中,变异个体决定着优化的方向,同时影响着全局最优解的搜索能力。为了既能保证种群的多样性又能提高收敛速度,本文采取自适应的变异策略,使搜索前期采用式(3)保证全局搜索,后期采用式(4)保证收敛速度。具体变异策略如式(5)。

在前期有助于保持种群的多样性,后期提高收敛速度,但是如果后期还没有找到最优解,则容易陷入局部最优产生早熟收敛。本文采用新增随机个体来逃出局部极优。如果搜索停滞则增加新的个体。搜索停滞即新生成的个体适应度值等于原种群个体的适应度,使得种群个体难以更新从而导致搜索停滞现象。
每个个体i 在迭代过程中使得目标函数未改进的次数记作count,若个体i 的目标函数在某次迭代中得到改进则count 的值保持不变,否则count+1,若新个体等于原始个体L 次则说明L 次该个体未得到更新,表明此个体性能较差已经陷入局部极优,则随机生成一个新个体代替它。如式(6)和(7)所示:
If

则:

1.4 算法步骤
ACODE 算法具体操作步骤如下:
(1)初始化种群规模,进化代数t+1,最大迭代次数T,控制参数CR 和F 按照式(1)和式(2)设置。
(2)计算个体适应度。
(3)判断步骤2 得到的适应度和迭代次数是否达到算法终止条件,如果适应度达到理论最优值或者满足t=T 则输出结果,否则转到步骤4
(4)对当代种群,根据改进的变异策略式(5)进行变异操作,生成中间变异个体vi( g+1)
(5)交叉操作,对t+1 代变异个体vi( g+1) 进行交叉操作产生t+1代实验个体ui,j( j+1)
(6)选择操作,对t+1 代实验个体ui,j( j+1) 进行选择操作产生t+1代个体xi( g+1)
(7)判断是否存在停滞现象并解决参见式(6)和式(7)
(8)t=t+1,返回步骤2。
1.5 算法性能评价
本文采用基准函数测试ACODE 算法的性能。这里标准DE 的CR 和F 的值均设置0.8。而ACODE 算法中的CR 和F 分别按照式子(1)和(2)进行自适应变化,且变异策略也按照式子(5)进行自适应变化。为避免实验偶然性,保证测试质量,算法独立运行20 次,算法迭代次数为1000,种群大小为100,维数为10。结果如表1 所示,收敛曲线图分别如图1-3 所示。
测试函数如下:
(1)Sphere 函数:

(2)Rastrigin 函数:
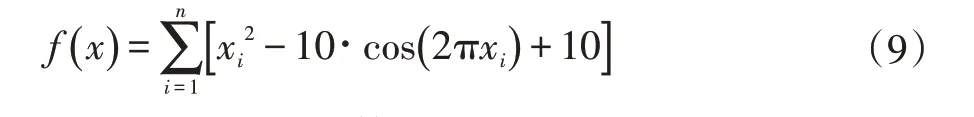
(3)Rosenbrock 函数:


表1 基准函数测试结果
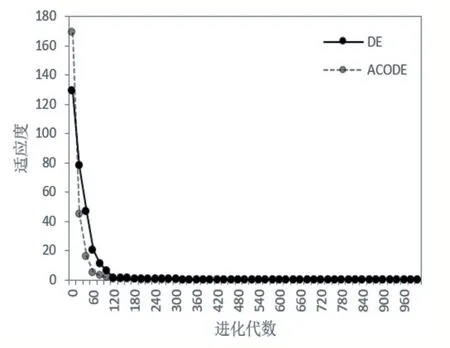
图1 Sphere函数收敛曲线图
从表1 可以看出,对于Sphere 函数,两种算法皆表现出较高的精度,但改进的DE 算法明显比标准DE 算法得到的值更优;对于Rastrigrin 函数,ACODE 算法收敛精度更高,说明该算法能更好地避免局部极优;对于Rosenbrock 函数,可看出ACODE 算法的平均值略差于DE 算法,而其最优值略优于DE 算法。从收敛曲线看,对于三种基准函数而言,ACODE 算法均有优越的收敛性能,极好地避免了局部极优。
综上,ACODE 算法可克服标准DE 算法自身的缺陷,并在基准函数测试中性能较好,寻优能力较强。

图2 Rastrigrin函数收敛曲线图

图3 Rosenbrock函数收敛曲线图
2 基于ACODE算法的SVM核参数优化
由于ACODE 算法对SVM 参数优化的效果还不能完全确定,因此本文将ACODE 算法应用到具体的分类过程中。本文以搜狗语料库为实验数据集,共选取十类,每类数据集有220 篇文档,其中每篇训练集占200篇,剩下的为测试集。算法流程图如图4 所示。
首先初始化ACODE-SVM 算法中的参数,其中,种群规模M=20,最大进化代数gmax=100,其他参数设定依照前文,SVM 的惩罚参数C 和核函数的参数g 的上下限均设为[0.0001,1000]。使用ACODE 算法对SVM 进行最优参数选择,利用得到的参数进行模型的训练和测试,并与未优化的模型的结果进行对比,表2 是本次的实验结果。

图4 ACODE-SVM流程图

表2 三种算法的实验结果对比
从表2 可以看出,整体而言采用ACODE-SVM 算法训练所得模型的准确率比未优化的值更高,分类结果更准确。
3 结语
本文研究分类问题中影响SVM 分类效率的主要因素:核参数和惩罚因子。由于差分进化算法相比较其他智能算法而言控制参数较少,具有较强的全局搜索能力,鲁棒性好,很适合参数寻优问题,因此本文引入差分进化算法优化SVM 的参数并对其进行改进,实验表明基于ACODE-SVM 的优化算法大大提高了SVM 的分类准确率。
