“货到人”拣选系统机器人任务分配的鲁棒双层规划模型
2019-10-27刘金芳
李 腾, 冯 珊, 宋 君, 刘金芳
(哈尔滨商业大学 管理学院,黑龙江 哈尔滨 150028)
0 引言
随着互联网经济的发展,电子商务行业在订单呈现多品类、小批量,高频次特点的背景下,为了提高消费者对配送时效的需求,越来越关注高效的物流体系。拣选作业是占整个物流作业时间最多的环节,拣选效率的提高更加受到企业的重视,传统的拣选方式是人工主导型,这种“人到货”的拣选方式效率较低,因此新型的“货到人”的拣选方式越来越受到青睐[1]。目前,应用最广泛的“货到人”拣选系统为美国亚马逊的Kiva系统。本文主要研究以Kiva为代表的基于移动机器人的“货到人”拣选系统。其机器人任务分配是指将每个任务分别分配给系统中的机器人执行,由机器人将货物所在的货架搬运至拣选台以供拣选,即货动人不动,在这种多机器人、多任务、并行作业的系统中如何调度机器人并将任务合理地分配给机器人决定着整个系统的运行效率与成本[2]。
近年来,很多学者对不同应用领域的机器人调度与任务分配问题进行了研究。Nielsen等[3]对配送能力约束下的机器人调度问题进行了研究,利用改进的遗传算法解决了机器人每次的配送量。周炳海等[4]考虑机器人之间的协同调度,以最小化机器人数量和降低能耗成本为目标,利用聚类启发式方法与自适应大邻域搜索算法验证了协同调度的优势。沈博闻等[5]将物流任务进行分解,考虑了路径成本与等待时间成本,对机器人调度进行研究并验证了智能调度的有效性。
多机器人任务分配主要分为集中式任务分配与分布式任务分配,集中式任务分配不适于解决大规模任务分配问题,所以许多学者分别利用基于市场机制方法、拍卖算法与群合作法等分布式任务分配方法解决该问题。苏丽颖等[6]提出了一种基于分布式的任务分配方法,利用组合拍卖的理论建立模型,证明了这种方法能够得到合理的任务分配结果。周菁与慕德俊[7]针对多机器人系统任务分配问题,通过设计分布式的多机器人系统,实现了以负载平衡为优化目标的任务分配。Arif等[8]将多机器人任务分配问题表示为多旅行商问题的一个推广,并利用EA算法进行最优任务分配。Janati等[9]提出了一种基于聚类的多机器人任务分配方法,利用遗传算法与模仿学习算法相结合进行求解,节省了运行时间。
从上述文献可知,将机器人调度与任务分配问题相结合的研究较少,现有研究多数以时间或运行成本为优化目标,没有考虑机器人的空闲成本,并且上述文献都是在确定的环境下进行决策,对不确定环境下的机器人调度与任务分配问题尚未解决,而“货到人”拣选系统中的环境往往是不确定的,系统中的不确定因素必须加以考虑。因此,本文将机器人的平均空闲率作为目标函数进行任务分配,参考了车辆调度问题[10,11],将二者结合建立了双层规划模型,在机器人完成所有任务平均空闲率最小的同时,通过机器人调度使其成本最小化,既可以解决机器人的调度问题,同时也可以实现机器人的任务分配。考虑了机器人在完成任务过程中由于调度、避障、路径规划等导致的行走距离不确定因素,利用鲁棒优化的相关理论建立鲁棒双层规划模型。进而提高系统的鲁棒性,降低成本。
1 问题描述及符号定义
“货到人”拣选系统机器人的任务分配问题可以描述为:系统接受订单后,将订单按照一定规则分批处理,系统需要确认每个订单中货物所在货架的位置,然后调度系统中一定数量的机器人,并将任务进行分配。在机器人完成任务的过程中,机器人首先从初始位置移动到货架所在位置并将其搬运至拣选台,拣选人员根据货物的信息在该货架上拣选货物,将其放在指定的区域。当系统中所有拣选台都被其他机器人占用时,机器人就会进行排队等待,直到被拣选完毕。拣选完成后,机器人将货架搬运到该货架的原来位置,在此位置等待下一次任务的分配。要求每个机器人同时只可以搬运一个货架,每个货架同时只能由一个机器人进行搬运。图1为机器人完成单个任务的流程,可以分解为3个步骤。
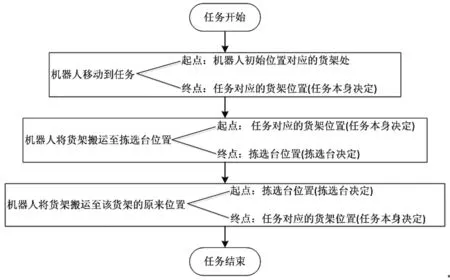
图1 机器人完成单个任务的流程图
为了便于构建模型,本文做出以下假设:
(1)初始时刻,系统中所有的机器人处于空闲状态。
(2)完成任务时,所有机器人的电量一直大于20%。
(3)系统中所有机器人的初始位置是随机的。
(4)系统中所有的任务分布在不同的货架中,并且不存在缺货现象。
(5)机器人将货架搬回后,在该货架位置等待下一个任务的分配。
(6)忽略机器人在拣选台的等待时间。
符号定义如下:
(1)R为机器人集,n为拣选系统中机器人的数量,Ri表示拣选系统中的第i个机器人,其中i∈[1,n];Z为任务集,m为拣选系统中任务的数量,Zj表示拣选系统中的第j个任务,其中j∈[1,m];P为拣选台集,p为拣选系统中拣选台的数量,Pk表示拣选系统中的第k个拣选台,其中k∈[1,p];
(2)(xAi,yAi)表示机器人Ri的位置坐标,(xBj,yBj)表示任务Zj的位置坐标,(xPk,yPk)表示拣选台Pk的位置坐标;
(3)d1ioj表示机器人Ri从初始位置到任务Zj所行走的距离的标称值,d2ijk表示机器人Ri从任务Zj到拣选台Pk时所行走的距离的标称值,d3ikj表示机器人Ri从拣选台Pk回到任务Zj时所行走的距离的标称值,本文所有距离计算均采用曼哈顿距离,即
d1ioj=|xAi-xBj|+|yAi-yBj|
(1)
d2ijk=|xBj-xPk|+|yBj-yPk|
(2)
d3ikj=|xPk-xBj|+|yPk-yBj|
(3)
(4)Dij为机器人Ri完成任务Zj所行走的总距离,即
Dij=d1ioj+d2ijk+d3ikj
(4)
(5)W为所有机器人Ri和所有任务Zj之间距离段集合;
(6)Vi表示机器人Ri的行走速度;
(7)T0为所有机器人完成任务的时间;
(8)Tij为机器人Ri完成任务Zj所花费的时间,即
(5)
(9)αi表示机器人Ri的空闲率,则
(6)
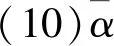
(7)
(11)Di表示机器人Ri完成所有任务的行走距离;
(12)决策变量Yi表示是否调度机器人Ri来完成任务,则
(8)
(13)Cr为机器人行走单位距离所花费的成本,Cf为单位时间每台机器人的空闲成本,Cp为每台机器人的固定成本即购买成本,C为n个机器人完成m个任务所花费的总成本;
(14)决策变量Xij表示机器人Ri是否完成任务Zj,则
(9)
2 模型构建与求解
2.1 不考虑距离变化的任务分配双层规划模型
双层规划模型具有主从递阶结构,最早由Bracken和McGill[12]提出。其上层问题的决策变量制约下层问题的最优结果,下层问题的决策变量影响上层问题的最优结果[13]。双层规划具有层次性、冲突性、独立性、优先性、自主性、制约性等特点,其研究的系统是分层的,上层决策者首先进行决策,下层决策者需要对其决策结果做出反应并且具有一定的自主决策权,上层决策者需要根据下层的反应再次进行决策[14]。双层优化能很好地描述分层系统优化问题,该方法多用于解决设施选址、生产计划以及应急物资运输等问题。如Yegane等[15]针对配送中心选址问题建立双层规划模型,提出了自适应双层蚁群算法进行求解,实现了利润最大化。Calvete等[16]对生产分配问题进行研究,考虑了不同决策者分别控制生产与分配问题,以成本最小为目标建立双层规划模型,利用蚁群算法进行求解,解决了生产分配问题。Camacho-Vallejo等[17]针对应急物资运输问题建立双层规划模型,对运输成本进行优化,解决了灾难后国际救援分配的决策问题。
由于“货到人”拣选系统中的机器人调度与任务分配之间的决策存在着上述层次关系,所以本节借鉴庆艳华等[18]利用此方法研究选址问题的模型,考虑了机器人调度与机器人任务分配问题,建立双层规划模型,以机器人完成所有任务的总成本为目标函数,机器人调度为决策变量,建立上层模型;考虑机器人在完成任务过程中处于空闲状态时所花费的成本,以机器人的平均空闲率为目标函数,任务分配为决策变量,建立下层模型。上层的机器人调度结果制约下层的机器人平均空闲率,下层的任务分配结果影响上层的总成本,上下层结果共同决定了机器人的配置决策。
上层模型:
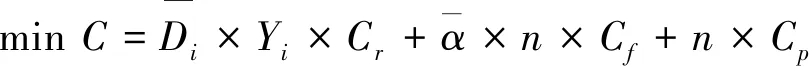
(10)
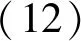
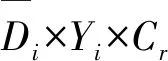
下层模型:
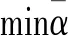
(13)
s.t.Xij∈{0,1},i=1,2,3,…,n;j=1,2,3,…,m
(14)
(15)
(16)
下层模型中,Xij为决策变量,表示机器人Ri是否完成任务Zj,αi表示在单批订单完成的时间内,机器人Ri的空闲率,式中将机器人完成一个任务所行走的距离分为三个部分。式(15)表示一个任务只允许由一个机器人完成,式(16)表示被调度的机器人至少完成一个任务。
2.2 考虑距离变化的任务分配鲁棒双层规划模型
在现实的优化问题中,一些数据往往是具有不确定性的,传统的不确定优化方法通常采用先验知识和不确定数据的分布假设解决不确定性问题,但数据发生变化时,最优解也会变化。鲁棒优化是针对传统的不确定优化方法的不足而提出的一种更有效的不确定优化方法,对不确定数据的分布没有规定,其关键在于构建不确定参数的集合,可用于解决最坏情况下的最优绩效[19,20]。当参数在集合范围内发生变化时,最优解不发生变化,使得优化的模型具有一定的鲁棒性,对参数的变化不敏感,最优解具有一定的稳健性[21]。目前鲁棒优化方法被应用到各个领域,如Bertsimas等[22]研究了呼叫中心人员配置问题,考虑了呼叫中心顾客到达的不确定性,建立人员配置的鲁棒优化模型,实现了人员的合理配置并降低了系统的成本。Leung等[23]对多站点生产计划问题进行研究,考虑了生产过程中各个站点的需求、劳动成本等不确定因素,以成本最小为优化目标,利用鲁棒优化方法解决了不确定环境下的多站点生产计划问题。Akbari[24]等对供应链网络进行优化,利用鲁棒优化方法解决了生产过程中的不确定因素,降低了运输与库存成本。
Soyster[25]提出了鲁棒优化理论,用来解决具有不确定性的线性优化问题。之后Ben-Tal、Nemirovski[26~28]深入研究了鲁棒优化理论,但提出的鲁棒优化方法增加了求解的复杂度。Bertsimas等[29]提出的鲁棒优化理论可以解决线性问题与离散型问题,其最终的鲁棒对等式仍为线性优化问题,便于求解且控制了优化解的保守程度。因此,本文利用了Bertsimas的鲁棒离散优化理论将不确定问题进行转换。
Bertsimas将不确定性组合优化问题进行如下转换:
mincTx
(17)
s.t.x∈X
(18)
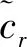
上述模型不能直接求解,需要进行鲁棒对等转换,因此引入鲁棒控制参数Γ0表示不确定参数的个数,Γ0通常取整数,因此,组合优化问题的鲁棒模型为:
(20)
假定d1≥d2≥…≥dn,令dn+1=0,Bertsimas将式(19) 转化为对n+1个标称问题进行求解,其目标函数为:
(22)
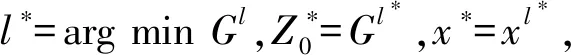
在机器人完成任务的过程中,如果多个任务同时聚集在一定的区域内,会使得多个机器人之间的行走路径发生冲突,为了减少机器人之间发生碰撞或减少机器人的等待时间,调度系统会调度机器人行走其他路径完成任务,无论机器人选择等待还是改变路径,都会影响任务的完成时间,进而影响机器人完成任务的效率,因此考虑了机器人在完成任务过程中由于调度、避障、路径规划等导致的行走距离不确定因素,将机器人等待的时间与路径的改变转换为行走距离的增加,由此可见,机器人完成任务的实际行走距离不一定是机器人完成任务的曼哈顿距离,所以采用区间值的形式表示机器人完成任务的实际行走距离。
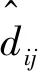
引入参数J,J表示受不确定距离影响的路段集合,|J|表示受不确定距离影响的路段的个数,|J|∈「0,|W|⎤。
引入参数Γ,Γ∈「0,|J|⎤,用来控制不确定距离的保守度,这里令Γ取整数,当Γ=0时,不考虑距离偏差的影响,此时任务分配模型与2.1节中模型一致,对不确定距离最敏感;随着Γ值的增大,增加了鲁棒性,模型对不确定距离的敏感程度会下降;当Γ=|W|时,所有路段的距离均为不确定距离,这时模型对不确定距离最不敏感,其任务分配结果最保守。
机器人任务分配鲁棒双层规划模型:
上层模型:
(23)
(25)
下层模型:
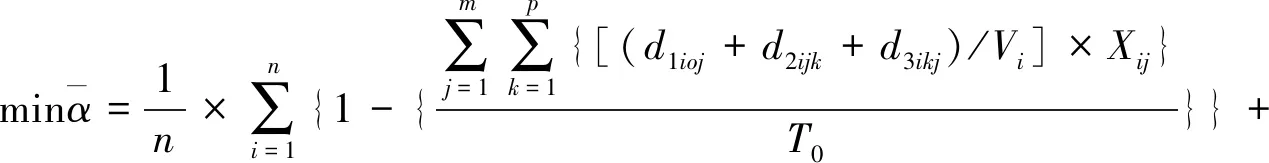
(26)
s.t.Xij∈{0,1},i=1,2,3,…,n,j=1,2,3,…,m
(27)
(28)
(29)
式(26)考虑了机器人在完成任务时不确定距离的偏差,表示在不确定距离偏差最大的情况下进行任务分配,进而使得机器人的平均空闲率最小。目标函数中含有max项,不能直接求解,本文利用鲁棒离散转换规则,将下层模型的目标函数进行如下转换:
下层模型:
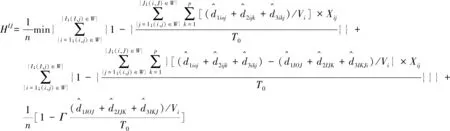
(30)
由此可得机器人任务分配鲁棒双层规划模型:
上层模型:
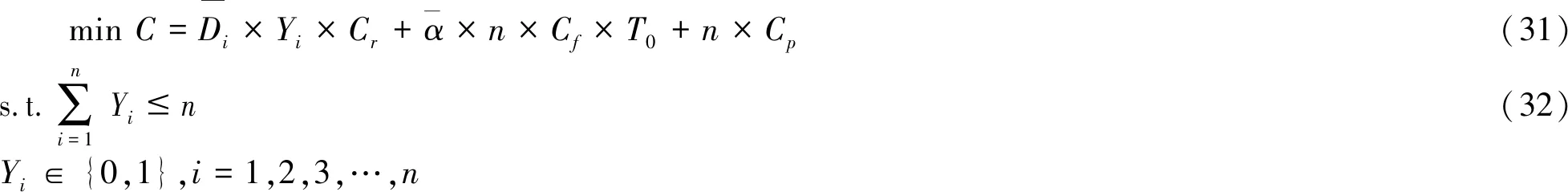
(33)
下层模型:
(34)
(35)
s.t.Xij∈{0,1},i=1,2,3,…,n;j=1,2,3,…,m
(36)
(37)
(38)
2.3 模型求解
遗传算法是模拟生物自然选择与遗传进化过程的一种优化算法,该算法是在初始种群中根据适应度函数选择较优的个体,通过对染色体进行交叉变异等操作,按照优胜劣汰的原则更新种群,最终得到适应度值最高的染色体[30]。遗传算法具有并行性、高效性与自适应等特点,便于求解组合优化问题[31]。鉴于多机器人调度与任务分配问题为NP-hard问题,当任务的数量增加时,精确算法所需求解时间增加,遗传算法在求解该类问题时,绩效表现良好。因此利用双层遗传算法与迭代相结合进行模型求解。
模型的求解具体计算步骤如下:
Step1确定机器人调度的最小数量。
Step2确定所调度的机器人的序号,采用机器人序号对调度问题进行编码产生初始种群,计算这些机器人到所有任务的平均距离。
Step3在上层确定机器人调度数量及调度结果的基础上,利用遗传算法对下层模型进行求解。首先设置控制参数;采用所调度的机器人序号对任务分配情况进行编码来产生初始种群,即每条染色体中的元素值都是所调度机器人的序号,代表该序号的机器人完成该位置的任务,并保证所调度机器人的序号在染色体中至少出现一次;计算种群中每个个体的适应度值,适应度值为机器人完成所有任务所行走的总距离的倒数,即机器人完成所有任务所行走的总距离越小,该个体的适应度值越大;选择一定数量的优良个体进入下一代种群作为父代;按照交叉概率选择两个父代个体,并使染色体的随机一段基因进行交叉从而生成新的个体; 按照变异概率对选择个体进行变异,变异时只可以将染色体的某个基因变异成所调度的某个机器人的序号;如果达到了设置的最大迭代次数,则停止迭代并输出机器人完成所有任务所行走的最短距离、任务的分配结果以及机器人的平均空闲率,否则继续计算。
Step4将Step 2得到的计算结果与Step 3得到的机器人平均空闲率带入上层模型,求出机器人完成所有任务所花费的总成本。直到最小成本不再发生变化,找到调度该数量机器人下的最小总成本,并得到了任务的调度结果与任务分配结果。
Step5将机器人的调度数量增加一个,返回Step 1。
Step6机器人的调度数量等于系统中机器人的最大数量,停止计算,输出历史最优成本作为最终结果。
模型的求解流程如图2所示:
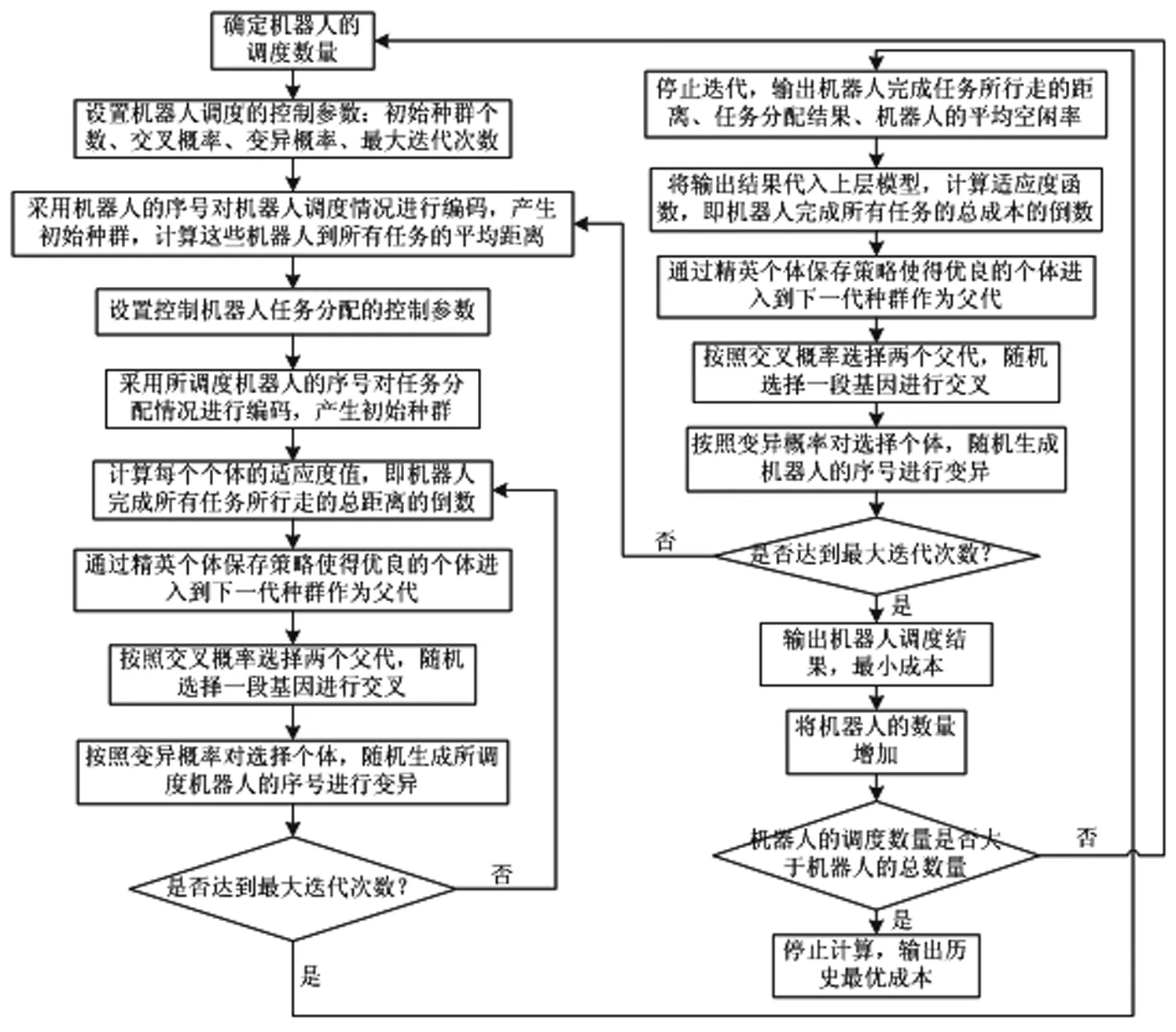
图2 双层遗传算法求解流程图
3 实例仿真与分析
3.1 实例描述
仿真环境设定为一个某50m×50m 的仓库,如图3所示。机器人的速度为1米/秒,按照每台机器人的折旧费用为2万/年计算得出,每台机器人在单位时间内的空闲成本为0.0006元/秒,按照每台机器人的功率为100w/小时,电费为0.86元/千瓦时计算得出,其行走单位距离所花费的成本为0.00083元/米,每台机器人的固定成本为7万元,机器人的最大数量为8个,模拟单批订单,其任务数量为30个,拣选台的位置为(20,10),随机指定机器人的初始位置如表1所示,任务所在的货架位置如表2所示。

表1 机器人坐标
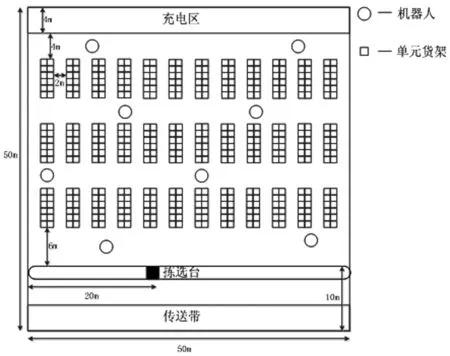
图3 仿真仓库布局
3.2 双层规划模型的机器人任务分配仿真结果与分析
首先,对双层规划模型的机器人任务分配问题进行仿真,遗传算法参数中,初始种群个数为700个,最大迭代次数设为100次,交叉概率与变异概率分别为0.9和0.8。调度3~8个机器人来完成所有任务,由于机器人数量较少,所以本节将上层模型采用遍历方式进行仿真,由于机器人的固定成本相同,因此以下仿真结果只包括机器人的运行成本以及空闲成本。仿真结果如图4所示。
通过图4可以得出调度不同数量的机器人,其最小成本不同,当调度6个机器人时,机器人完成所有任务所花费的总成本最小,此时,得到的不同调度结果对应的成本如图5所示,图4中调度7个或8个机器人时所花费的成本高于调用6个机器人的成本,是由于随着机器人调度的数量增加,机器人的平均空闲率增大,所花费的成本增加。
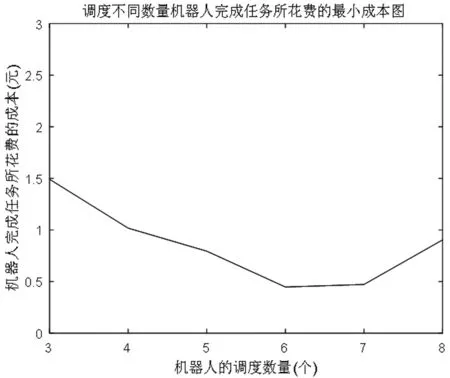
图4 调度不同数量机器人完成任务所花费的最小成本
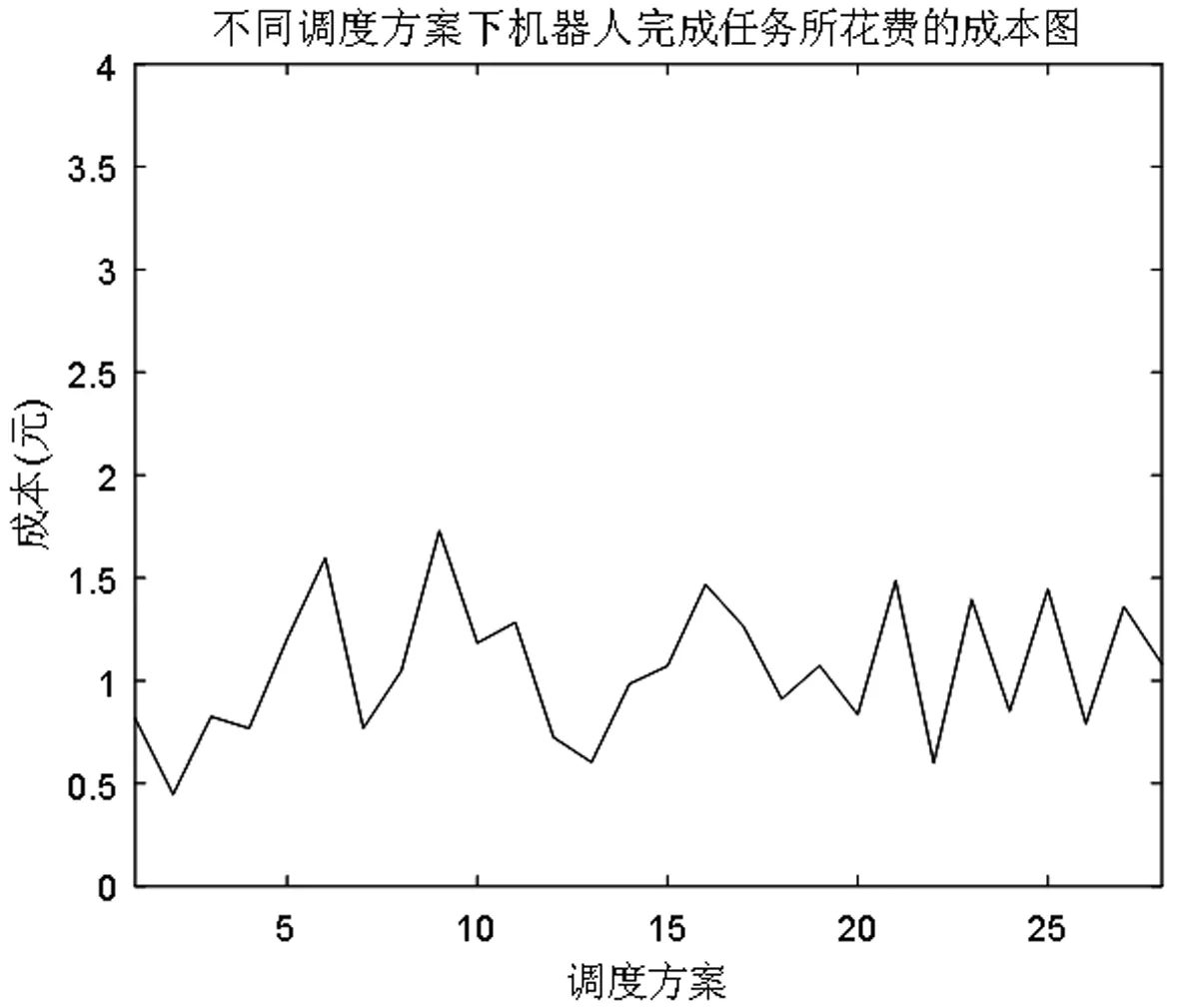
图5 不同调度方案下机器人完成任务所花费的成本
图5表示调度6个机器人时,不同调度方案下机器人完成任务所花费的成本,其中横坐标表示调度方案共28种,纵坐标表示成本。仿真结果显示调用第1、2、3、4、5、7个机器完成任务时,所花费的成本最小,此时机器人行走的总距离如图6所示。
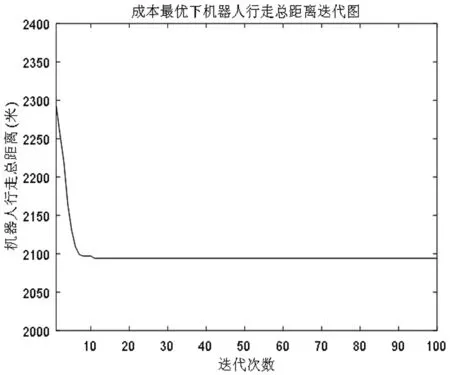
图6 成本最优下机器人行走总距离
因此,双层规划模型的机器人任务分配问题得到的机器人配置、调度以及任务分配结果如表3所示。

表2 任务坐标

表3 双层规划模型的机器人配置、调度以及任务分配结果
表中任务分配结果的第一个数字代表调度的机器人序号,后面数字则代表该机器人所完成的任务序号。
3.3 鲁棒双层规划模型的机器人任务分配仿真结果与分析
将不确定距离分为三段,在本仿真实例中,机器人完成任务可能行走的距离共1200段,Γ表示不确定距离的个数,当Γ=0时,所有距离不变,与原来模型计算结果一致,这里分别取Γ=0,40,80,120,160,200,300,表4为机器人配置、调度及任务分配结果,图7为对应的成本。
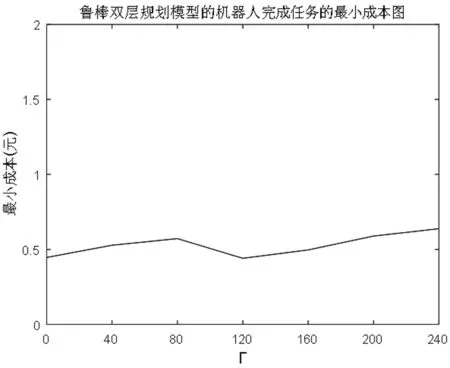
图7 鲁棒双层规划模型的机器人完成任务的最小成本
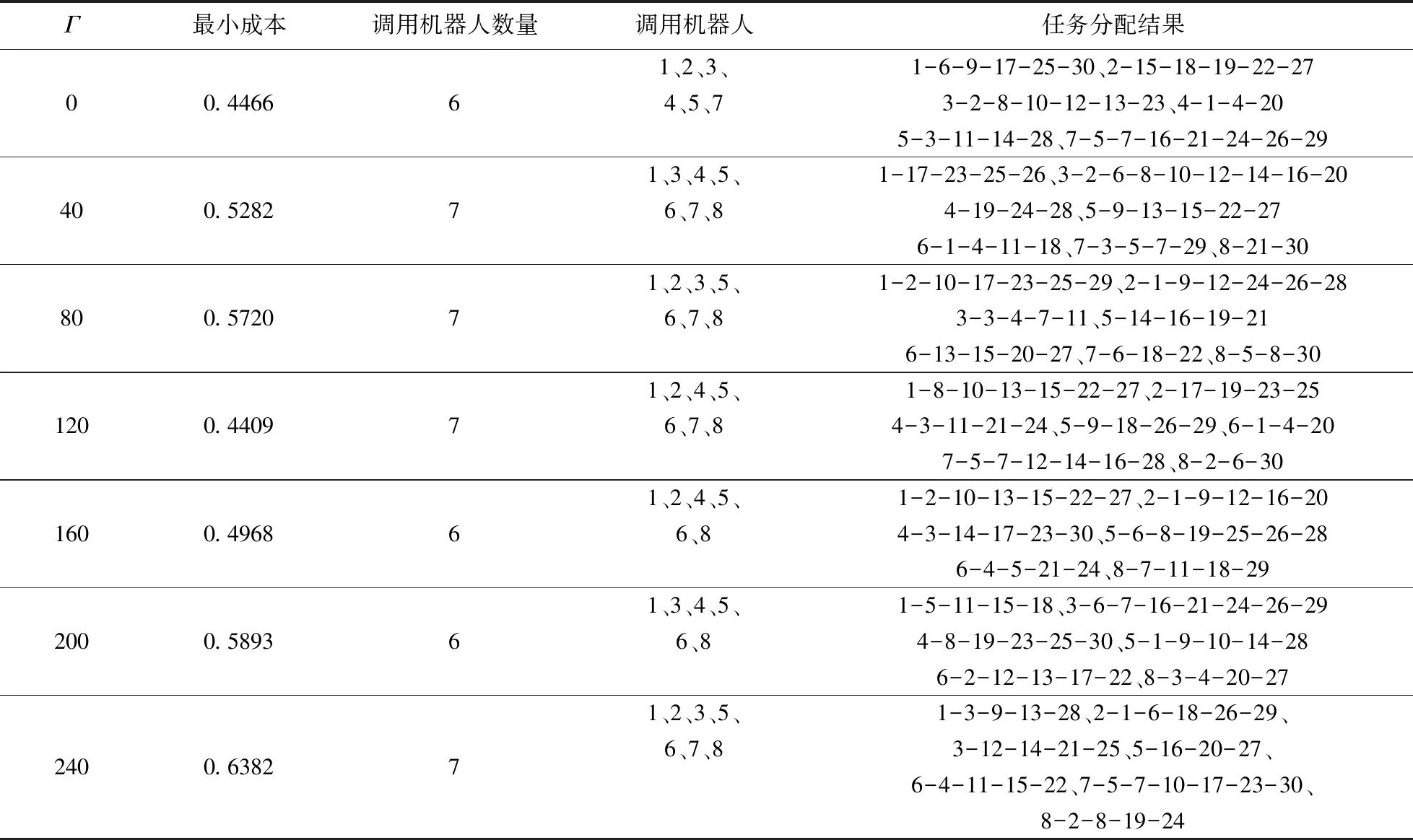
表4 鲁棒双层规划模型的机器人的配置、调度以及任务分配结果
从表中看出,发生变化的距离个数不同,机器人完成所有任务所花费的成本不同、其数量配置、调度方案、以及任务的分配结果也会发生变化。
在本仿真实例中,完成30个任务需要行走90段距离,为了验证鲁棒双层规划模型的有效性,使机器人的行走距离在指定范围内随机发生变化,取,表示从1段距离发生变化直到30段距离发生变化,两个模型的仿真结果如图8所示。
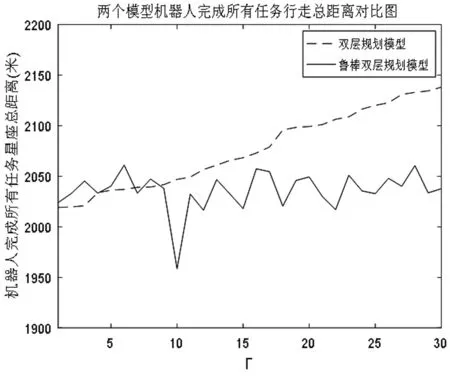
图8 两个模型下机器人完成所有任务行走总距离
图8中横坐标为不确定距离段的个数,纵坐标为机器人完成所有任务行走的总距离,虚线为双层规划模型的机器人完成所有任务行走的总距离,实线为鲁棒双层规划模型的机器人完成所有任务行走的总距离。随着不确定距离数量的增加,使用双层规划模型得到的机器人完成所有任务行走的总距离明显多于使用鲁棒双层规划模型得到的机器人完成所有任务行走的总距离并且呈上升趋势,而鲁棒双层规划模型的曲线波动范围较小,相对稳定;图中开始部分,鲁棒双层规划模型的优势不明显,对不确定距离比较敏感,随着不确定距离数量的增加,降低了模型对不确定距离的敏感程度,其行走距离比较稳定,意味着此时的分配结果比较保守,但增加了解的鲁棒性。
4 结论
在“货到人”拣选系统中,提高作业效率的关键取决于如何调度机器人并进行任务分配,进而影响着整个系统的运行效率与成本,本文考虑了机器人在完成任务过程中由于调度、避障、路径规划等导致的行走距离不确定因素,建立了基于行走距离不确定性的鲁棒双层规划模型,以机器人完成任务成本最小作为上层模型目标函数,以机器人平均空闲率最小为下层目标函数,通过双层遗传算法对模型进行求解,解决了机器人的调度问题,并同时实现了机器人的任务分配。通过算例研究,验证了鲁棒双层规划模型的有效性,得到鲁棒双层规划模型的机器人调度结果与任务分配结果使得机器人完成所有任务的总成本对不确定距离因素不敏感,也就意味着这种情况下的分配结果最为保守,在一定程度上提高了系统的运行效率,降低了系统的运作成本。
