机器阅读理解中观点型问题的求解策略研究
2019-10-22段利国高建颖李爱萍
段利国,高建颖,李爱萍
(太原理工大学 信息与计算机学院, 山西 太原 030024)
0 引言
机器阅读理解的发展能够极大促进自然语言处理领域的进步[1],目前可应用于智能搜索、智能问答、智能客服、智能音箱、语音控制等场景,具有较大的学术意义和实用价值。
阅读理解任务从答案角度划分,大致可分为完形填空型[2]、选择型[3]和片段抽取型[4]等形式。目前以CNN&Dailymail数据集为代表的完形填空型阅读理解和以SQuAD为代表的片段抽取型阅读理解任务研究已相当成熟,并取得较好效果,但针对选择型阅读理解任务还有待进一步研究。因此本文以选择型阅读理解为任务,选用AIchallager 2018(1)https: //challenger.ai/competition/oqmrc2018中提供的观点型问题数据集,目标是为了让机器能够正确理解文本语义并给出相关问题的正确答案[5]。但求解该观点型问题面临以下挑战:
(1) 该数据集是从搜索日志中随机选取,并由机器初判后人工筛选生成,以自然语言形式表示,主要包括一些较为复杂的、需要综合考虑文章中每个句子的语义才能得到正确答案的问题,数据规模较大且难度较大。
(2) 求解该问题要求机器必须具备理解自然语言和推理线索的能力,涉及自然语言处理中信息检索、文本匹配、文本理解、语义推理等多方面的技术[6],因此对于模型构建和技术选择具有很大的挑战性。
由于深度学习在大规模数据集上的显著效果,目前已广泛应用于机器阅读理解方面,因此针对以上问题,本文结合深度学习对观点型问题阅读理解求解策略进行了一些探索性研究,主要贡献如下:
(1) 获取文章和问题的综合语义时,在拼接、双线性、点乘和差集[7]4种常用注意力的基础上,融合Query2Context和Context2Query[8]两个方向的注意力,强化文章和问题的关键信息,弱化无关信息。
(2) 加入多层注意力转移的推理机制,使注意力不断聚焦,从而更准确地抽取文章和问题的综合语义,提高求解答案的准确率。
(3) 不同方式的文本表示通常对语义理解有不同的影响,因此实验对比了基于词语序列和句子序列进行输入表示文章对求解效果的影响。
1 相关研究
随着语料库的丰富和深度学习的发展,机器阅读理解已由传统人工参与的基于句法、语法分析的方法转向基于神经网络的端到端深度学习。在阅读理解深度学习模型方面,虽然存在结构差异,但大多本质都是基于“Attention Reader(AR)”和“Impatient Reader(IR)”两个基础模型的变体[9],并采用注意力获取文章和问题综合语义[10]。
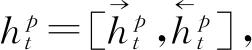

上述基于“IR”的二维匹配变体,虽利用不同于“AR”的问题表示方式引入更多细节信息,但均是用点积函数得到相似矩阵的基础上,以不同的方式进行注意力计算,并没有像基于“AR”的一维匹配变体采用其他函数进行注意力的计算,也没有像“AR”的变体引入深层推理结构。针对以上不足,本文模型在二维匹配的过程中加入基于拼接、双线性、点乘和差集4种函数的注意力来计算文章和问题的注意力权重分布,并引入多层注意力转移推理机制实现注意力的不断聚焦,从而获得更加准确的文章和问题的综合语义。
2 任务描述
本文选择AIchallager2018中观点型问题语料进行解答研究,该语料中问题对应的文章段落相对较短,但却具有隐藏性,比较注重机器对文本的整体理解概括和推理,且问题来自真实世界,任务困难,对于促进阅读理解发展研究更具有代表性和挑战性。语料本身对每个问题都提供了候选答案,所以作为选择题来处理,题型涉及Yes-No观点型(候选答案为A|非A|不确定)和Entity-Fact观点型(候选答案为A|B|不确定)[16]。而选择题答案预测是机器根据所提供的文章及相关问题,通过理解后在候选答案集中选出正确答案的过程。语料示例如表1所示。

表1 观点型问题题目示例
一般选择类阅读理解任务数据集可形式化描述为文章、问题和候选答案三元组
通常语料中文章、问题长度不一,直接输入不便于模型统一处理,所以在进行深度模型构建之前,先对数据进行处理。通过语料分析,文章长度固定为m,然后按照文章原始顺序抽取前m个词作为有效信息,其他信息舍弃,如果不足m个词则进行padding操作,之后作为模型输入。同理,将问题长度固定为n作为输入。
3 模型构建
本节针对观点型问题答案求解构建了一个多阶段的分层处理模型,接下来将对各层进行详细描述。
3.1 模型整体架构
模型整体架构如图1所示(见下页),Document、Query、Alternatives分别基于词语序列进行输入表示。本模型共包括以下5层。
(1) 词嵌入层: 使用Word2Vec[20]将文章、问题及候选答案集中的每个词映射到向量空间,形成初始化词向量。
(2) 上下文信息编码层: 将Document和Query的初始化词嵌入层向量输入Bi-GRU,利用词语的上下文重新定义词嵌入。之后将3个候选答案初始化词向量序列A1、A2、A3分别和问题最后隐含状态编码拼接同时输入到Bi-GRU,得到融合问题信息的三个候选答案的语义表示Q_A1、Q_A2、Q_A3。
(3) 匹配层: 通过C2Q+Q2C+(Concat(拼接)+Bilinear(双线性)+Dot(点乘)+Minus(差集))Attention多种注意力的融合得包含问题信息的文章表示VDQ_1。
(4) 推理融合层: 将VD和VDQ_i(i为叠加推理的层数)输入到匹配层,输出为篇章和问题的综合语义VDQ_i+1。
(5) 输出层: 将推理融合层的输出结果VDQ_n和3个融合问题信息的候选答案Q_A1、Q_A2、Q_A3进行相似度匹配,选择相似度最高的一个作为答案。
3.2 词嵌入层
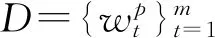

图1 模型整体架构图
3.3 上下文信息编码层
3.3.1 Gated Recurrent Unit
在上一层所获得词嵌入的基础上,本文使用Gated Recurrent Unit(GRU)[12]来获取文章和问题中词语及其所在上下文的语义信息。GRU模型公式如式(1)~(4)所示。
其中,xt表示t时刻的输入,rt和zt是控制门,ht是输出的隐含状态。
3.3.2 上下文编码表示
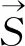

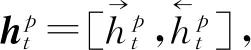
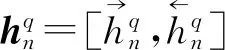
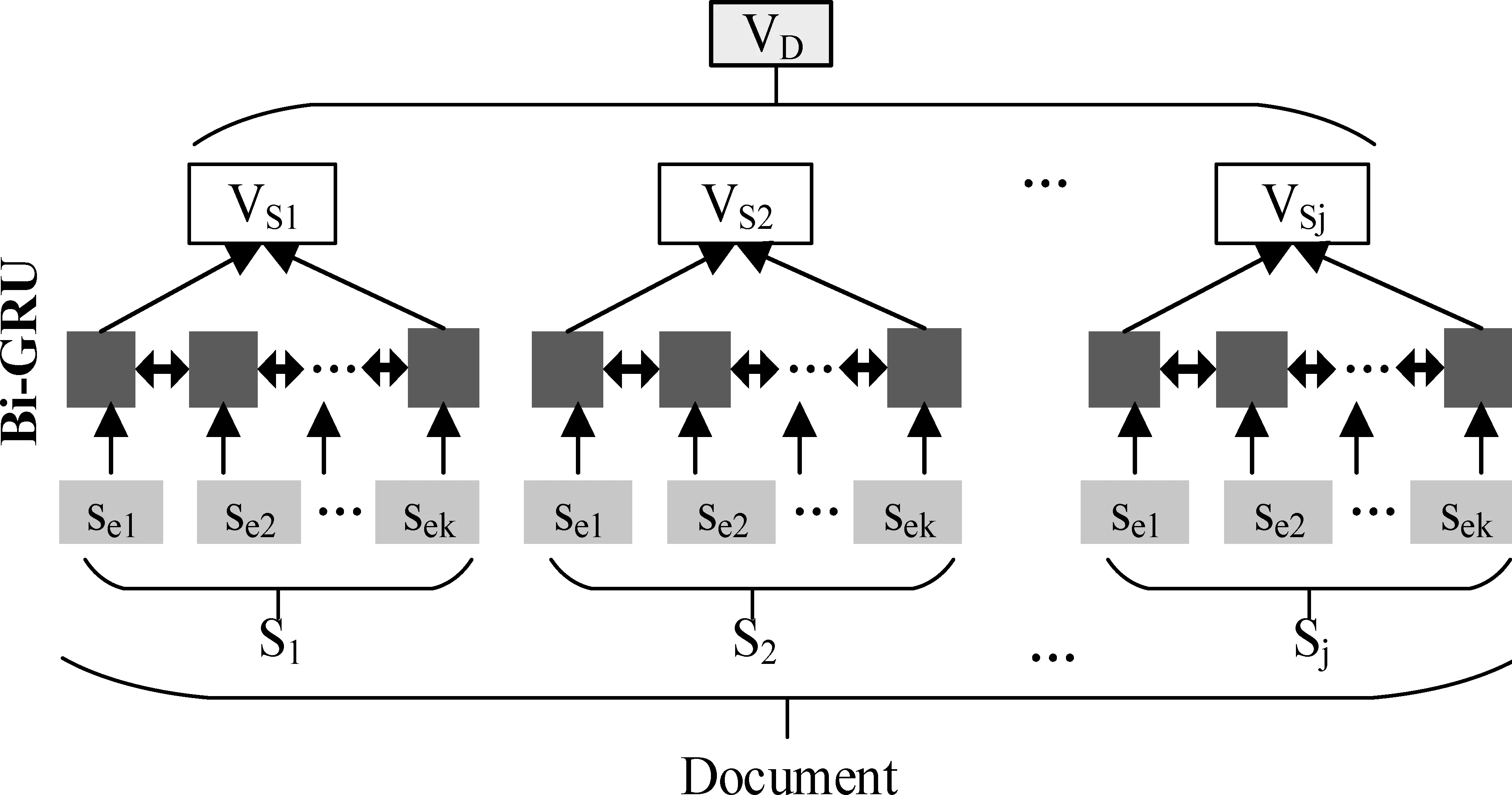
图2 基于句子序列的Document表示
3.4 匹配层
在上一层获得文章和问题的上下文词序列之后,本层采用(Q2C和C2Q)双向注意力与(Concat、Bilinear、Dot、Minus)4种常用注意力分别得到问题与文章各部分的相关性,然后将结果进行融合得到文章和问题的综合语义表示,即VDQ_1=F(VD,VQ),该表达式表示VD和VQ通过匹配层的输出结果。计算步骤如下: Step1和Step2为计算双向注意力Q2C和C2Q的过程,模型如图3所示。
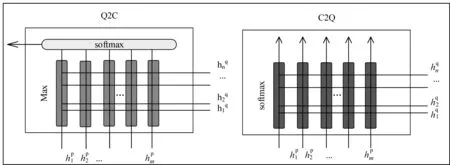
图3 注意力Q2C和C2Q的模型结构
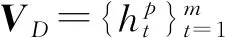
M=(VD)T·VQ
(12)

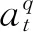
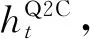
Step3采用基于四种函数Concat、Bilinear、Dot、Minus的attention分别确定文章中第t个单词对问题中每个词的注意力,如式(17)~式(20)所示。
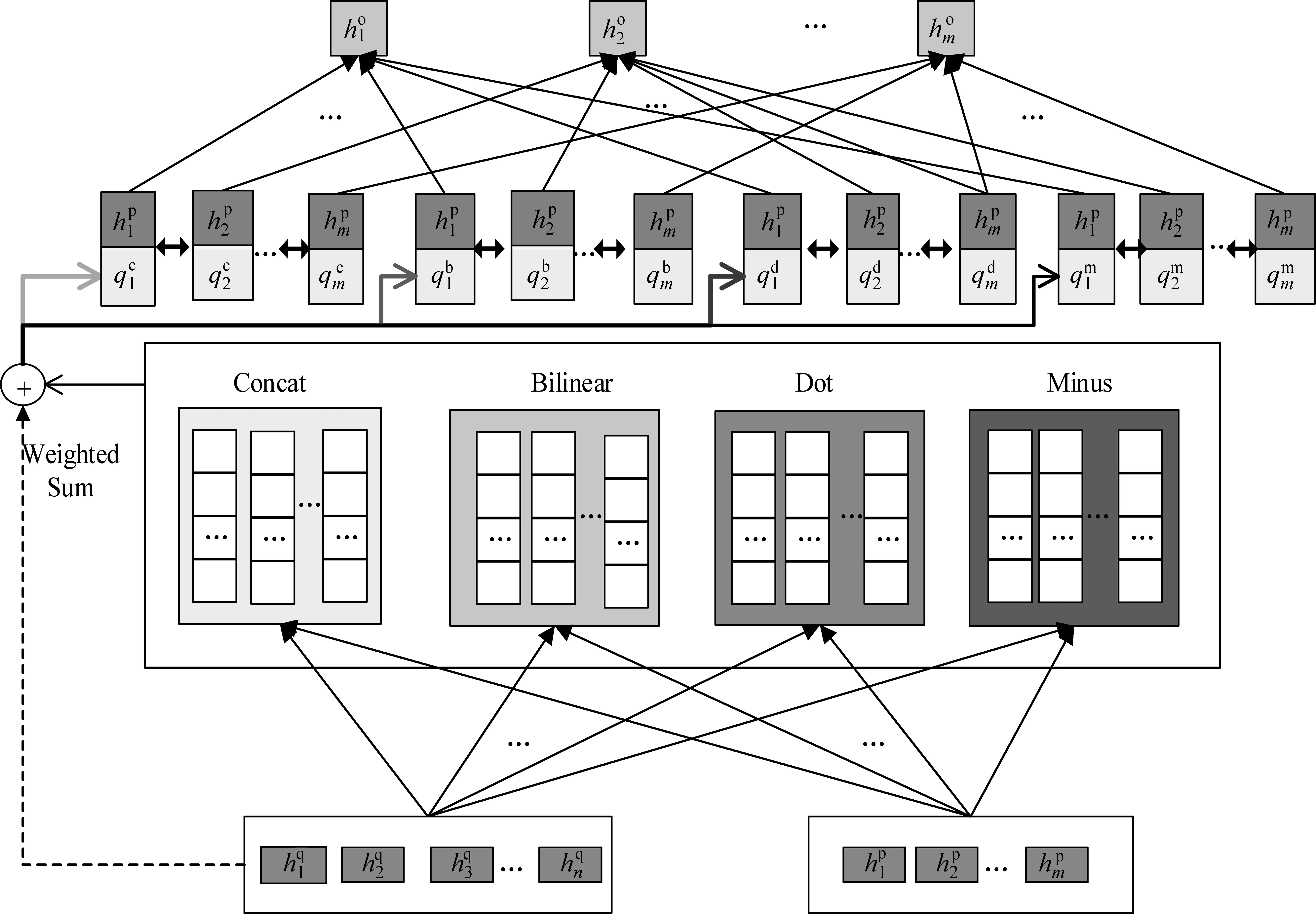
图4 Concat+Bilinear+Dot+Minus整合模型

3.5 推理融合层

(27)
则VDQ_1={hβt|t∈(1,m)}。
多层推理融合层在得到VDQ_i之后,将D和VDQ_i输入到3.4节匹配层进行多层注意力的转移,最终得到文章关于问题的高层语义表示VDQ_n=F(VD,VDQ_i)。
3.6 输出层
答案预测时,通过内积方式计算出推理融合层获得的文章关于问题的高层语义VDQ_n与包含问题信息的候选答案语义Q_Ak的相似度,选择相似度最高的一个作为答案,如式(30)所示。
Answer=Argmax(Q_Ak·VDQ_n)(k=1,2,3)
(30)
4 实验结果及分析
4.1 数据集
实验数据集选用AIchallager2018提供的观点型问题数据集,其样本数共29万,包括训练集25万、验证集3万和测试集1万。语料对于每个问题都提供了候选答案,因此作为选择题来处理,涉及Yes-No观点型和Entity-Fact观点型[17]。训练集和验证集中每条数据都由文章、问题、候选答案集以及答案组成。测试集中没有答案。在整个实验中,没有使用任何外部数据。本文后续和其他系统进行实验对比,并将准确率作为评价指标。
4.2 模型参数设置
本文词向量采用Word2Vec进行预训练,维度d=300。对于未登录词,采用零向量表示。根据表2统计,文章中几乎99.8%的数据长度都未超度500,同时为了考虑数据输入的稀疏度问题,最终将文章长度m设置成500。通过统计,问题长度小于30的有249 999,因此问题长度n设置为30。Bi-GRU隐含层的维度设置为150。训练过程中,模型采用Adamax[21]作为优化器,学习率设置为0.1。误差采用批处理,batch-size设置为30。为避免过拟合,dropout设置为0.2。推理层数设置为4。共训练10轮(epoch),每一轮之后在验证集上测试性能,最终选择在验证集上效果最好的作为模型。
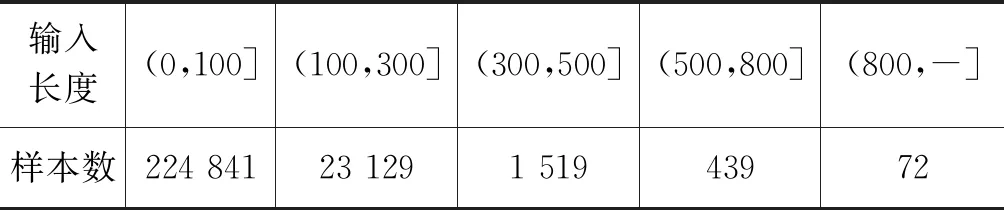
表2 25万训练集中文章长度分布统计
4.3 实验结果及分析
本文实验分为两大类。
第一类: 与其他模型作对比实验,其他模型选择官方提供的基线系统MWAN[7],以及前沿方法BIDAF[8]和AOA[18],如表3所示,在验证集和测试集上本文的模型明显优于其他模型,并在测试集上超过基线系统10.28%,达到了78.48%的准确率。
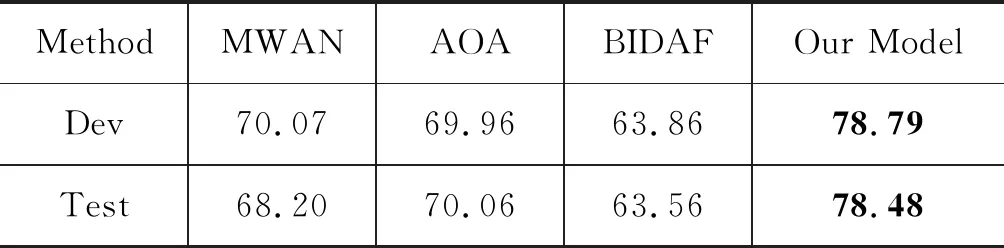
表3 不同模型准确率对比(%)
第二类: 自对比实验。
(1) 为了确定本文所提出的多层注意力转移机制的有效性,在测试集上作了如表4所示的对比实验,从表4中可知本文模型在加入多层推理层之后,不论文章以何种序列进行输入表示,每增加一层推理层,准确率都会明显上升,在层数4时准确率达最高,比不添加推理层时基于句子的文章输入表示高出7.84%,由此可看出多层推理机制的加入可以让注意力不断进行聚焦,从而可以抽取到更加准确的语义信息。
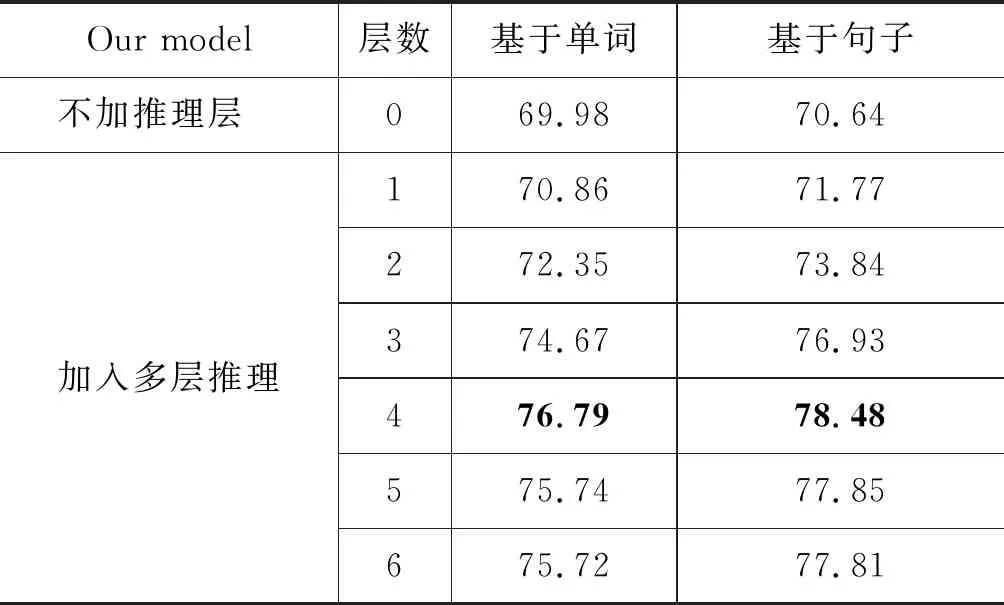
表4 文章基于单词和句子两种表示下加入不同注意力转移推理层数实验对比结果(%)
(2) 通常在阅读理解中文章都是以词语序列进行表示,而对于句子序列表示的结果却未曾探知。为了探索文章以这两种方式进行输入表示时对获取文章和问题综合语义信息的影响,本文在添加推理层的同时作了对比实验,在图5对比图中可以直观看出无论是否添加多层推理层,文章基于句子序列进行输入表示的准确率始终高于基于单词序列进行输入表示的结果。
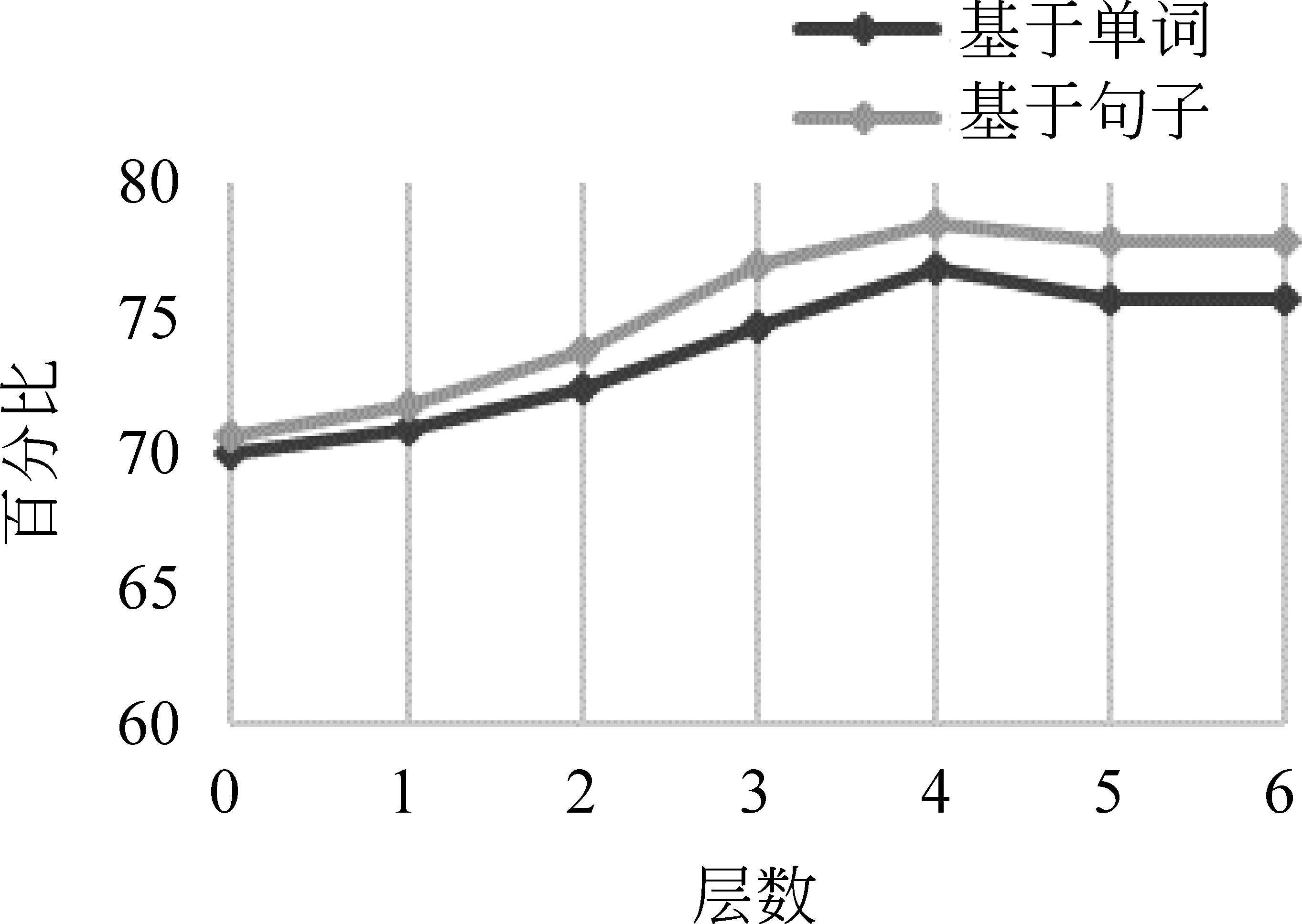
图5 推理机制层数对比图
(3) 为了测试本文模型所使用的每个注意力的有效性,模型在加入4层注意力转移推理层的基础上,先在验证集和测试集上对比了只使用单个注意力时的效果,如图6所示。可以直观看出,无论使用任何单一的注意力,模型性能都急剧下降,同时可知这五种注意力中只使用Dot attention时的效果最好,但是测试集上本文模型比单一使用Dot attention却要高出3.22%。之后对比只抽掉其中一个注意力之后的效果,由图6可知,去除其中任意一个注意力时,准确率都会有所下降,从而更加证明了本文模型的有效性。
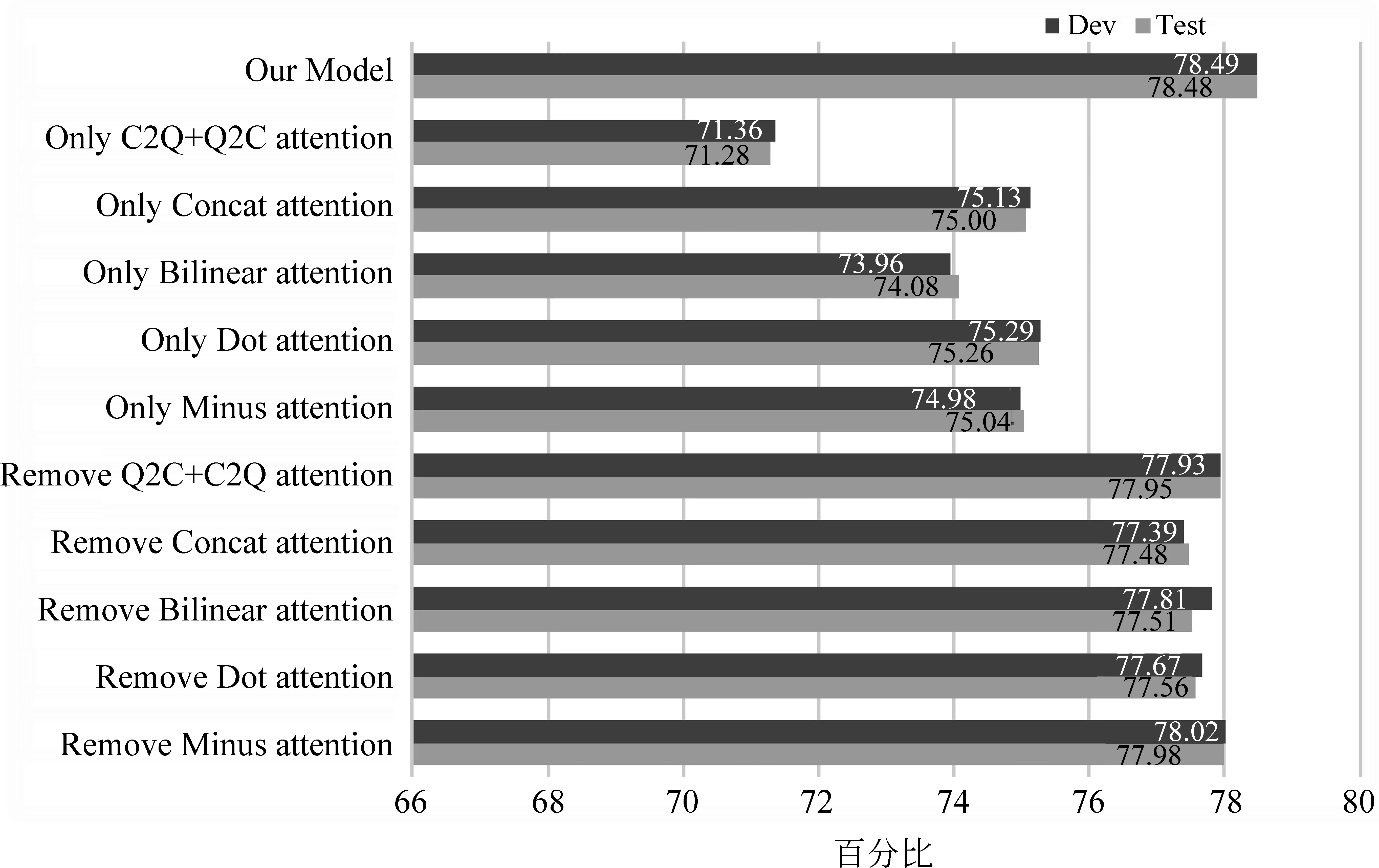
图6 模型消融实验结果对比
5 结论
本文针对阅读理解观点型问题求解提出一个多阶段的分层处理模型,主要贡献点如下:
首先,针对文章和问题综合语义信息的获取问题,本文提出一种将常用注意力拼接、双线性、点乘和差集加上双向注意力Query2Context和Context2Query的多注意力融合算法。实验表明该算法可以有效强化文章与问题相关的重要信息,弱化无关信息。
其次,为了获取更加准确的文章和问题的综合语义信息,本文提出在多种注意力融合的基础上添加多轮迭代的多层注意力转移推理机制。实验表明该机制可以使注意力不断聚焦,从而大幅提升阅读理解性能。
最后,为了探索基于句子序列和基于词语序列的文章向量表示效果,本文将两者进行了对比实验,实验表明句子序列表示效果能提升求解性能。
虽然本文模型在阅读理解观点型数据集上取得较好结果,但在抽取文章和问题综合语义信息上仍有欠缺。另外,对于文章以词语序列和句子序列进行输入表示时影响准确率的原因仍有待探索,并且今后将进一步优化模型并设计新的神经网络来提高模型抽取文章和问题综合语义信息的能力和推理答案的性能。
