基于互信息和半监督学习的入侵检测研究
2019-10-22石凯
石凯
(西南交通大学信息科学与技术学院,成都611756)
0 引言
随着计算机网络的日益普及和计算机服务的快速发展,其背后暴露的安全问题也更加突出。为了解决网络安全的问题,提出了能针对网络攻击而主动采取反应措施的入侵检测系统(Intrusion Detection System,IDS)[1]。IDS 能监视并分析主机和网络,一旦发现异常情况,将马上采取相应的措施并提供防护[2]。为了减少基于异常情况的IDS 的漏报率和误报率,相关研究人员利用机器学习技术在大量的数据中提取特征和分类灵活快速的优势,对未知攻击数据集归类。然而,现今研究仍然有以下问题:
(1)当目标网络遭受攻击时,大量的底层网络数据包所包含的特征重要性不同,所以需要准确的对特征定性,并且剔除不重要或者可能降低检测性能的特征。
(2)现今基于机器学习的未知攻击检测都需要大量的已有标记的数据进行训练。在遭受攻击时,大量的未知攻击数据将产生,人工标注将降低检测效率。
针对上述问题,本文提出一种基于相关性、冗余度和半监督学习的入侵检测方案。主要贡献有3 个方面:
(1)针对准确定性不同的特征,区分不同特征的重要性,使用改进的过滤算法,引入相关性、冗余度来确定不同特征对系统检测性能的影响程度,从而减少多余特征的干扰,达到定量选取重要特征、加快检测速度的目的;同时,使用相关性、冗余度也[3]可以定量的区分不同流量特征对于攻击分类的重要程度。
(2)针对缺乏已标记数据的问题。为了很好地利用已有标记的数据,并且更好的得到未标记数据的标记,采用新型的CPLE 半监督学习利用数据特征相似性标记未标记的数据,从而得到大量可以参与训练的已标记数据,达到增加检测准确率的目的。
(3)NSL-KDD[4]数据集是KDD99 数据集的改进,解决了KDD99 很多潜在的问题,是网络入侵检测的标准数据。本方案在NSL-DD 上进行对比实验,验证了本方案的有效性。
1 基于机器学习的入侵检测
机器学习在海量数据的处理上有着天然的优势,所以在入侵检测信息分析阶段可以很流畅的引入机器学习的方法。Duan Xindong 等[5],提出了在云计算环境中设计一种新的非法用户入侵行为检测模型。利用主成分分析选择非法用户入侵行为的特征,并采用最小二乘支持向量机对入侵行为特征进行分类和检测,采用粒子群优化算法确定最小二乘支持向量机的参数。Du Shao-Bo 等[6],针对入侵检测算法的独立冗余属性导致入侵检测算法检测速度慢,检测率低的问题,提出了一种基于邻域距离的入侵特征选择方法。
在大数据时代,依靠人工专家标注的数据仍然太少,较少的有效数据将极大的降低检测系统的效率。在对攻击数据特征进行筛选时,有效快速地选取特征十分重要,如果没有很好地特征选择,将减少接下来分类的准确率,所以如何在减少特征维数时速度更快、更准确变得尤为重要。
因此,本文提出一种基于最大相关最小冗余和半监督学习的入侵检测方案,在更快速地降低网络攻击特征维数的同时,选取检测更准确的特征,去除干扰检测的特征,同时,自动化的标记以降低标注成本,尽可能多地保留分类信息以更准确的检测未知攻击。
2 我们的方案
为了提升检测系统的效率,筛选出妨碍检测的特征,本方案首先采用改进的最大相关最小冗余的方法,对数据集的特征进行选择。之后为了应对未知攻击检测以及训练数据集的规模较小的挑战,采用半监督学习的方法利用少量标注的数据生成大量的训练数据集进行训练。
2.1 基于MR-MD的特征选择方法
本文引入了一种基于距离函数的方法来度量每个特征的独立性。距离越远,独立性越高。MRMD 的主要关注点是搜索一种特征排序度量,它包含两个方面:一是特征子集与目标类之间的相关性,二是特征子集的冗余度。在本文中,Pearson 相关系数[6]被用来衡量相关性,利用三种距离函数来计算冗余度。
为了便于理解,我们将作如下规定。D 表示数据集,N 表示数据集D 数据的数量,M 表示数据集有M个特征。在F={ fi,i=1,2,3…,M }中,F 表示特征集合,其中fi代表各种不同的特征,c 表示分类目标,我们的目标是找到m 个特征(F 的特征子集),能够使得尽可能多的数据符合分类目标c。
(1)最大相关性
对目标类条件进行分类的最大贡献通常意味着最小的分类错误,最小误差通常需要分类目标y 与F 的子空间有最大相关性,这要求我们选择的特征子空间是与分类目标y 具有最高相关性的特征集。Pearson 相关系数可以测量正相关和负相关,因此选择Pearson 相关系数作为特征与目标类c 之间的相关度量。给定两个向量和,Pearson 相关系数的计算为:
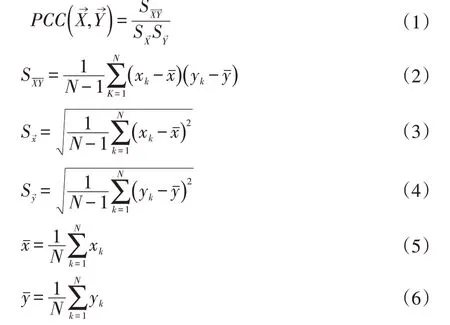
xk、yk分别是向量和的第k 个元素,向量X→和都是数据集D 中所有例子的属于一个特征或者分类目标的值所组成的向量。最大相关则定义为:

(2)最大距离
使用最大距离来测量两个特征向量之间的相似度。为了综合考虑各种维度的距离,选择了欧氏距离,余弦相似度和Tanimoto 系数。计算方式分别为:

每个特征根据以下公式,我们可以得到第i 个特征的欧氏距离,余弦相似度和Tanimoto 系数:


根据公式(12-14)可得到平均距离。

(3)本方案第一个模块特征选择
组合上述两个约束的标准称为“最大相关、最大距离”(MRMD)。假设我们选择了具有m-1 个特征的子特征集。接下来的任务是从剩余特征集中选择第m 个特征。该算法选择最优特征的条件为:

即选择相关性与距离之和的最大值为下一个选择的特征。以上两小节组成了入侵检测方案的第一个模块,特征选择模块。
2.2 基于CPLE的半监督学习
本小节将介绍最初的基于CPLE 的方案[7]。
半监督学习是监督和无监督组合的一种学习方法,并试图通过合并标记和无标记的数据提供改进的分类。训练集表示为表示xi是d维向量,表示为每个样本的标记值。生成模型的对数可能性损失函数L 定义为:

Nk表示分类标签为k 的样本数量,且表示为所有样本数量。Θ 表示分类器的参数集,最大似然估计通常用于优化监督学习中的损失函数。最佳参数表示为:

半监督学习中的参数通过使用来估计标记和未标记的样品。未标记的样品表示为ui表示未标记样本的特征,vi表示未观察的响应变量,M 是未标记样本数量。半监督分类器通过最大化可能性来优化的参数:


对于给定的q,相对改进半监督的对比似然CL 相对于受监督的参数估计θ可以表示为:
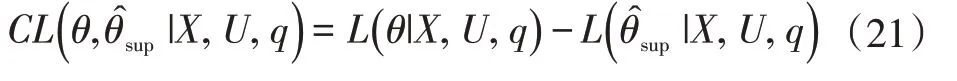
LOOG[8]提出q 的“悲观”选择,估计未知的软标签q 以达到之后优化的目的,即选择q,能使CL 最小化,因此,CPL 目标函数变为:

为了确保判别可能性的悲观最小化,引入一个新的函数,表示如下:

其中g( x;θ)=p( f=1 ]x,θ)表示后验概率预测分类器,y'是基于后验证的未标记的样本预测的硬标签,公式(23)可以通过以下步骤优化。
(1)初始化一个分类器C0,并且生成软标签q0
(2)对第i 次迭代(i=1,2,3,…,N):
①计算未标记数据硬标签,计算公式为:

(3)迭代了N 次时,以CN为最终分类器。对于之后无标签的样本,使用分类器CN进行标签预测或者分类。
2.3 本方案第二个模块CPLE半监督模块
本方案第二个模块将接着利用第一个模块选择的特征,已经剔除不需要的特征及相关特征的数据。图1为CPLE 半监督模块模型。
在图1 中,第一步,将已经过特征选择的数据分裂为训练集和测试集。第二步,使用在第一步中准备的可接受数据集构建监督分类器。使用来自接受和拒绝数据集的样本训练模型。第三步,将第二步中得出的分类规则是适用于测试集。第四步,重复以上步骤50次评估模型性能。

图1 N-CPLE半监督模型
3 实验及结果分析
3.1 实验环境
采用最新的NSL-KDD 数据集,实验环境为Intel i7 6700K,编译环境为Pycharm。该方案对数据集进行归一化处理,采用max-min 标准化法,将数据值映射到[0,1],计算方法为:

其中xcriterion是某个特征数据值标准化处理后的数据,xinitial是某个特征标准化前的原始样本值,xmin是某个特征原始样本中最小值,xmax是某个特征原始样本中最大值。
3.2 实验结果分析
分别将基于MRMD,信息增益,相关系数的特征选择方案利用SMO、贝叶斯,随机树分类器,在选择8、20、30 个特征和使用完整特征的情况下,对分类准确率进行比较。实验结果如图2、图3、图4 所示。

图2 基于SMO分类器在各特征数下准确率

图3 基于贝叶斯分类器在各特征数下准确率

图4 基于随机树分类器在各特征数下准确率
图2 、3、4 分别表示在各种分类器下的分类准确率比较,在较低特征数时,基于相关系数的方式无法取得有效的效果。基于信息增益的方式,虽然各种特征数都有较好的分类准确率,但是分类准确率较MRMD 的方式更低,所以验证了本方案对少量特征地选择的有效性。
分别将基于MRMD、信息增益、相关系数的特征选择方案利用SMO、贝叶斯、随机树分类器,在选择8、20、30 个特征的情况下运行时间如表1 所示。

表1 各种分类器下不同特征数运行时间
在表1 中,运行时间单位为秒(s),可以看到特征数越多,运行时间越长的特点,所以在选择少量特征时,可以达到检测的高效率,提高检测速度的目的。
本方案1000 次在有标记样本和无标记样本比分别为:1:1、1:3、1:5、1:7、1:10、1:20、1:100、1:1000 得到的准确率如图5 所示。

图5 N-CPLE各比例准确率
由上图所示,本方案并没有随着样本比值的减少准确率一直下降,而是呈现一定波动,在1:1 和1:10 取得最大值。说明了本方案的有效性。并且我们将在1:10 的数据比值下进行特征选择,得到的结果如图6所示。
为了同时比较各特征数对准确率和运行时间造成的影响,取运行时间的1/10 在图上表示(例如全特征运行时间为1302.4s,但是表示为130.24(十秒)。随着特征数减少,运行时间持续减少,这是因为参与判断的特征数量得到有效减少,从而增加了检测速度。但是随着特征减少,准确率先增大后减少,并且在特征数为35的时候达到高于全特征数的准确率,所以验证了本方案的有效性,在减少特征数从而增大检测速率的同时,对检测准确率也有一定提高。
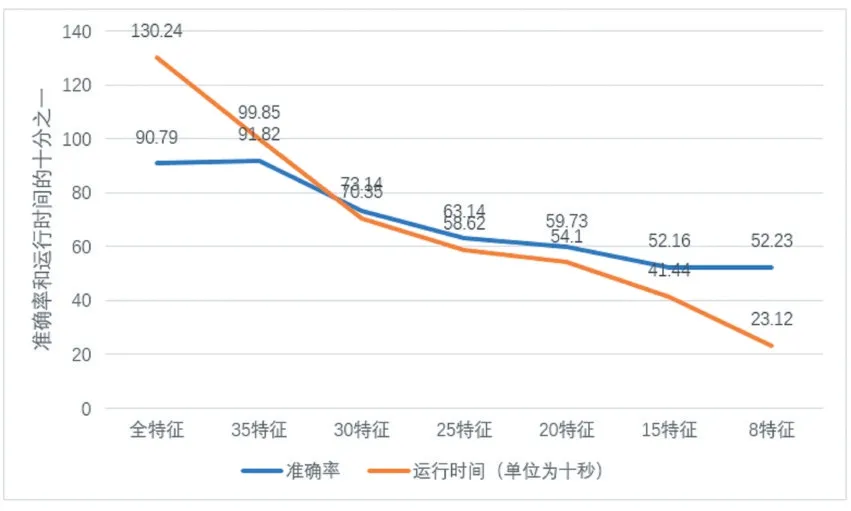
图6 各特征数准确率和运行时间
4 结语
本文提出了一种基于相关性冗余度和半监督学习的入侵检测方案,针对准确选择网络流量特征并且定性、定量分析以及缺少可靠标记流量数据而导致检测率较低的问题,采用MRMD 特征选择算法筛选重要特征,并改进CPLE 半监督方法,达到对未知攻击的检测。通过实验对比,验证了本方案的有效性,并且分析了不同规模数据集合和特征的选择对检测的影响以及检测效率的影响。
