基于ARM 的声控LCD 屏设计
2019-10-22袁良祺魏晓马牧燕
袁良祺,魏晓,马牧燕
(北京信息科技大学仪器科学与光电工程系,北京100192)
0 引言
纵观人类社会的发展至今,古老的信息传递方式发生了巨大的变革,由飞鸽传书到邮政,再到信号传递等过程,说明信息交流不断在进化。现在,声音控制技术逐渐成熟,有很多产品已经投入到各个应用中。
语音识别技术是一种让机器通过识别和理解过程把人类的语音信号转变为相应的文本或命令的技术,属于多维模式识别和智能计算机接口的范畴。其研究目标是让机器“听懂”人类口述的语言,这是人类自计算机诞生以来梦寐以求的想法[1]。随着计算机技术和信息媒体的飞速发展,人们越来越迫切需要摆脱信息的输入方式桎梏而以多种多样的输入方式为基础。语音输入作为一种易于上手、自然的、人性化、简洁的、快速的输入方式越来越在当今时代拥有其独特的地位。并可根据操作者的需要进行有目的性的语音控制,从而在LCD 屏上显示出来。同时也为人们带来生活中的小乐趣,更适宜老人和儿童。
1 声控LCD屏的总体设计
如图1 所示,系统采用ARM 嵌入式平台为整个系统的总控制器,ARM 是一种高级精简指令级机器。ARM 微处理器是目前应用领域非常广的处理器,到目前为止,ARM 微处理器及技术的应用几乎已经遍及工业控制、消费类电子产品、通信系统、网络系统、无线系统等各类产品市场,深入到各个领域[2],ARM 技术正在逐步渗透人们生活各个方面。另外,选择与开发板配套的ATK-4.3’TFT LCD 液晶屏模块,以及外接市面上常用的语音识别模块LD3320。
在实际使用之前先对语音识别模块预先存储需要识别语言的语句,事先在计算机等介质上向SD 卡中存储要显示的文字、图片等内容在实际操作中,使用者通过正常的语音向系统发出指令,语音识别系统进行转化语音输入,转化为相应的数字信号并与预先存储的语音信号匹配上,然后通过ARM 平台的电路传输与程序语言控制,通过ARM 平台读取图片并且显示在LCD屏幕上,从而实现声控LCD 屏幕显示的功能。
1.1 输入部分
输入分为三个部分,第一部分为写入语音指令,需要使用者提前在程序里面添加50 个语言识别的拼音及编号如表1 所示;第二部分为存储图片,存储的图片是第一部分所设定语言相对应的图片。图片的格式为jpg 或gif;第三部分为使用语言输入,非特定使用者在实际使用时,在适当的距离内说出第一部分所添加的语音指令,只能是普通话。
1.2 语音信号识别与调用部分
通过使用者所发出的指令,语音识别模块进行解码,转化为字符串,字符串与设定好的语音指令进行匹配。最佳匹配结果输送到ARM 平台。ARM 平台调取SD 卡中最佳图片与结果匹配。
1.3 显示部分
调用部分给出来的指令显示在LCD 屏幕上,反应时间大约1~2 秒,显示的内容为语音输入指令相关图像,图片以行扫的形式显示在LDC 屏幕上。

图1 硬件系统总体框图
2 硬件系统设计
此系统的语音模块部分使用串口与STM32F407通信的,使用串口1 所以使用的是PA9 和PA10 两个引脚,语音模块的RXD 管脚接PA9,模块的TXD 管脚接PA10。
2.1 ARM平台的选用
声控LCD 系统采用STM 公司提供的高性能、高兼容、易开发、低功耗、低工作电压的STM32 系列的32位ARM 微控制器STM32F407,其拥有先进的Cortex-M4 内核、更多的存储空间、极致的运行速度以及更高级的外设[3]。
2.2 声控模块的选用
LD3320 的主要特点是:非特定人语音识别技术;不需要用户进行录音训练。可动态编辑的识别关键词语列表;只需要把识别的关键词语以字符串的形式传送进芯片,即可在下次识别中生效且用户可自由编辑50条关键词语。用户可根据场景需要,随时编辑更新这50 条关键词语内容[4]。使用普通话就可以进行LCD 的声音控制,这大大提高了使用者的便利性并方便了这款产品的普及。
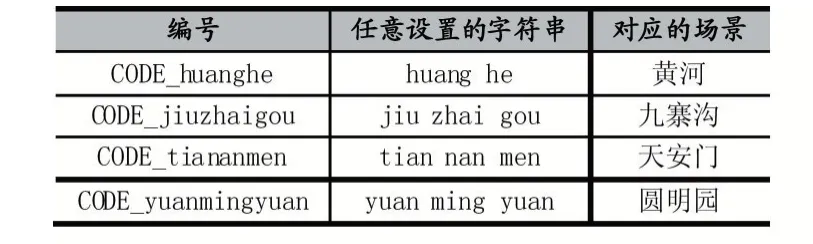
表1 任意设置的识别风景图表示示例
基于LD3320 的语音识别系统,使用者可以根据场景或各种需求,从而更改50 个输入的关键词及编号和相对应的图片来补足容量问题。首先使用者下达指令至声控模块,再由声控模块进行频谱分析,将人的语言转化为数字化信号,得到系统所能识别的参数。然后声控模块再提取信号中的特征参数,再将参数输送给语音识别器,语音识别器通过特征参数调取SD 卡中的关键词,寻找最匹配的关键词。如图2 所示,虚线内为LD3320 内部语音识别原理框图。

图2 LD3320内部语音识别原理框图
2.3 LCD屏幕的选用
出于选用时的便利原则,选用与STM32F4 配套的一种TFT-LCD 模块,其自带驱动板块,可以直接方便地与STM32F4 进行安装连接,操作容易简单。而且此ATK-4.3’TFT LCD 电容触摸屏具有高分辨率、自带驱动、速度超快、接口简单等优点.
2.4 SD卡的选用
SD 卡拥有存储速度快,方便随身携带,安全保密性强的优点,目前已经逐渐替代CF 卡成为数码相机的主要存储介质。SD 卡在使用时需要高速读写功能,同时也为了使用者以及使用环境的不同设置了两种访问接口:SD 访问模式SPI 访问模式,SD 卡接口定义及引脚功能如表2 所示。
3 软件系统设计
软件系统设计实现对各个模块的驱动和控制以及系统联调,完成系统整体功能。STM32F4 的编程操作环境为C 语言环境。软件系统设计主要包括两部分:语音识别模块驱动程序和STM32F4 的匹配调用程序。

表2 SD 卡接口定义及引脚功能
3.1 语音识别模块驱动程序
在语音模块驱动程序的设计中,采用了中断方式的工作模式,其工作流程分为四个步骤依次是:通用初始化和语音识别初始化;将语音信息写入待识别列表;与事先存储好的任意设置的识别风景图词语识别;响应中断,如图3 所示。

图3 语音识别程序化流程图
(1)通用初始化和语音识别初始化。在初始化程序里,主要完成软复位、模式设定、时钟频率设定、FIFO设定[5]。
(2)将语音信息写入待识别列表。待识别列表的每个识别语句对应一个特定的编号如“1”、“2”、“3”等,为了利于接下来的编译使用“CODE_huanghe”(黄河的语句编号)这样的识别语句编号。LD3320 芯片最多支持5O 个识别语句,每个识别条语句是普通话的汉语拼音(小写),且拼音单词之间应用一个空格间隔。本文中采取的语句识别条部分如表1 所示。
(3)开始识别的步骤:设置数个相关需要的寄存器,即可开始语音语句的识别。ADC 通道即为麦克风咪头的语音输入通道,ADC 增益(灵敏度调节)也就是麦克风可识别的音量大小,可设定值OOH~7FH,建议设置值为40H~6FH[5]。
(4)响应中断阶段为当麦克风时,无论是否识别出匹配的结果,都产生一个中断信号,中断程序根据寄存器里的值进行字符段匹配,产生数个结果,选择其中最好的结果进行输出显示。
3.2 STM32F4的匹配调用程序
STM32F4 的匹配调用程序通过对预先存储在SD卡中的BMP、JPG 或者GIF 等格式的图片进行解码、读取,然后与语音模块传送过来的语音信息进行匹配,然后在TFT LCD 屏上轮换显示出来。该设计的总体流程图如图4 所示。
在SD 卡的读取环节采用较多的文件系统是FAT12/FAT16/FAT32 等。另外,SD 卡在进行读写操作的时候,需要首先对SD 卡进行初始化。在进行语音控制之前,应将图片存储在SD 卡中,在本系统图片使用的格式分为两大类JPEG 格式和GIF 格式,理论上只需对这两种格式进行解码操作即可,由于本文的重心在于语音控制LCD 屏显示图片,所以对于读取和解码不进行过多的赘述[7]。

图4 STM32F4的匹配调用程序流程图
4 系统整体功能说明
本文进行基于ARM 的声控LCD 屏的设计并完成系统的搭建,实现语音控制LCD 屏的功能,使用者通过语音输入的方式与之前所存储的语音指令(拼音)相匹配,最佳的匹配结果传送给LCD 屏并显示。例如想要显示“目录”这张图片,首先需要在LD3320 程序里添加“mulu”形式的拼音指令,然后在SD 卡里存储一张“目录”的图片(“目录.jpg”),然后再由使用者发出语音指令“目录”经过LD3320 语音识别模块匹配到最佳图片,显示在LCD 屏上。由于单片机需要对图片进行解码,所以根据图片大小不同,反应时间大概是2 秒左右,图片的显示是行扫模式。
5 系统性能的测试
进行硬件系统和软件系统安装调试,完成声控LCD 屏制作,实物如图5 所示。

图5 声控LCD屏实物图
对于此系统进行性能的测量环节,随机的邀请三名非特定人,一名女性两名男性,三名非特定人说话声音拥有不一样的频率,声调自己音色。每个人分别选择不相同两组词语,每组五个,在安静环境和嘈杂环境(手机模拟雨声)下与语音识别麦克风距离1m 分别进行语音识别测试,测试结果如表3 所示。
分析表格数据可知,在安静环境下语音模块对于非特定人群的语音辨识度准确率约为91%,在嘈杂环境下,语音模块对于非特定人群的语音辨识度准确率约为81.7%。可怜嘈杂环境对语音模块的影响较小,平均十张图片可以标识八张,在嘈杂环境中也有一定的工作能力。综上,语音模块准确率高,稳定性强,实时性高,反应速度快,嘈杂环境影响小,抗干扰能力强。

表3 语音识别模块准确性能测试效果
6 系统结构功能的问题及改进
在本系统中存在的问题主要在以下两个方面:识别准确度不高,识别稳定性不强,具体改进系统功能的方案如下:
首先,在程序的编写时可以增加错误语句来减小非需要语音的误判。在语言的识别中,有时会出现误识别,即说出语音相近的词汇而匹配上关键词语的情况,这是进行语言识别中可能会存在的垃圾词汇(垃圾词汇是指具有与关键词语相似但不是需要的词语,例如“黄河”的垃圾词语有“黄山”、“混合”等)。这种垃圾词汇在程序的编写中可以进行人为设定,如设置“黄山”、“混合”为不需要识别的语句,在系统听到此词语时不予反应,但是由于硬件系统的设定,这种垃圾词汇的编写与关键词语的编写最多只能设定50 条语句。
其次,在程序的编写时可以设置ADC 增益(灵敏度调节)来减小噪声的影响。这个设置的灵敏度值越大代表MIC 音量越大,语音识别对声音越敏感,但是对周围噪声以及垃圾词汇;灵敏度值越小则代表MIC 音量越小,需要更加近距离的语音才能启动识别功能,好处是对周遭环境或者垃圾词汇的干扰反应较小。本文中设定值为40H,也可以根据场景的需要以及使用人的需求所决定。
最后,在程序的编写时可以增加口令模式来增强抗干扰能力和安全性。在某个特定的场景或者需求下,比如嘈杂的车间,当需要用声控识别系统时,嘈杂的环境可能给系统带来很大的影响,所以需要增加口令模式,给予系统更高的识别精度和抗干扰能力。
7 结语
本文设计了一款基于ARM 平台、采用STM32 单片机为核心以达到实现语音控制LCD 屏用来显示图片。在信息化发展变化快的年代,声音控制系统将会更频繁出现在大家的世界里面,无论是教学、医护、研究等各个领域都会有很好的发展空间。加载的语音控制模块可以针对不同的人群、适用于不同的场合,并且可以根据自己的需要多次使用。采用的TFTLCD 液晶触摸屏具有高分辨率、饱和度强、对比度高、反应快等特点。该系统的硬件设计较为简单,主要使用软件编程来实现想要的功能,此系统价格适中、功能强劲、普遍性强可以进一步开展进行商业化模式思考和进行商业开发可能性的探索,且在保值方面也尤为突出,磨损老化等问题对于该系统影响很少,极大程度上为社会材料节约能源。在以后人类的生活中,声控系统将会更大的发挥它的可能性。
