基于信息熵和小波滤波的清音检测方法
2019-10-15赵霞
赵 霞
(西安航空学院 能源与建筑学院,西安 710077)
0 引 言
语音的端点检测、音节划分、声韵分割、浊清判决等对语音信号的后续处理,如消噪、语音识别都有重要应用。目前最常用的几种方法有:能量、倒谱、频谱特征、谱熵[1]、过零率、自相关函数,以及它们的组合形式,如能零积[2]。在低噪环境下,很多方法都能够检测出语音端点和清音、浊音;部分方法,如能量法能够很好地区分清音浊音或者浊音和背景噪声。然而,清音作为绝大部分汉语词语的起点,其检测不仅有一定难度,而且是否准确对语音识别性能影响颇大[3]。
从产生原理上讲,浊音是通过声门调制、声道影响和口腔辐射冲击序列发出的一组能量并且具有一定规律性的语音;而清音则更像白噪声,气流的摩擦、爆破却没有声带的震动。因此,将清音和白噪声相互分离,还是比较困难的,特别是清音淹没在白噪声中时。
有些“稳健性”的端点检测方法实际上是通过消噪,清除掉语音中的噪声[1-2],然后对信号进行端点检测的方法实际上改变了原信号,很可能会对清音部分产生比较大的伤害。有的学者使用基于子带能量比[4-5]的方法或者信息熵[6]对清音进行了检测。但是这几种方法在白噪声下不能很好地检测出清音来,大量的白噪声被误认为是清音,甚至有些浊音也被误检为清音。
本文通过仿真试验发现,在不考虑浊音的情况下,信息熵能够比较好地区分白噪声和清音,即使是在清音被白噪声淹没的情况下仍然能够分辨出来,但由于清音和白噪声的高频特征,使得它们的信息熵变化比较大,也比较快,检测时容易将连续清音分割成几段清音。所以为了可靠地检测出连续的清音,必须对语音的信息熵序列进行平滑地处理。本文选择小波滤波方法对信号进行处理,仿真及结果显示,这种方法能够很好地从白噪声及色噪声中检测出清音来,并且具有很好的稳健性,在10 dB及以上条件下,完全可以检测出噪声中的清音来。
1 (谱)熵与离散小波变换
语音信号x(n)被加性白噪声w(n)污染后的信号可表示为
zi(n)=xi(n)+wi(n)
(1)
式中:n=1,2,…,N;i为帧号。
1.1 信息熵和谱熵计算
信息熵的计算公式为[7]
(2)
式中,k=1,2,…,M;M为帧长。
谱熵的计算方法为:对信号先进行傅里叶变换,然后进行功率谱密度计算,最后根据功率谱密度计算熵值,就可以得到谱熵结果:
(3)
式中:Zi(k)为第i帧信号的M点FFT;M为FFT变换的长度,本文取值和帧长相等;pi(k)为第i帧信号的功率谱;*表示卷积计算;conj表示共轭。
1.2 离散小波变换和小波滤波
对于任意信号f(t),其连续小波变换为[8]
FCWT(a,τ)=〈f(t),φa,τ(t)〉=
(4)
式中:a,τ分别为尺度因子(或者尺度参数)和时间因子(或者位移参数);φ为小波函数;*表示共轭。
对连续小波变换,把尺度因子和时间因子离散化:
其中,a0,Ts分别是用来决定尺度因子和时间因子的离散化程度的参数,得到离散小波变换为
(5)
离散小波变换的结果表明,相当于使用了一对正交镜像滤波器(QMF)对信号进行高通滤波(相应于小波函数和细节空间)和低通滤波(相应于尺度函数和尺度空间),对应的正交镜像滤波器分别为g(p)和h(p)(p为滤波器级数)[9],然后再进行一次2倍下采样,得到的小波系数(以3层分解为例)记为cA3、cD3、cD2、cD1分别是3层近似系数、3层细节系数、2层细节系数和1层细节系数。在重构时,使用QMF滤波器g(p)′和h(p)′对小波系数cA3、cD3、cD2、cD1的信号进行滤波,再进行一次2倍采样。
本文选定了小波基后,对应的正交镜像滤波器记为g(p,waveletbasis)和h(p,waveletbasis);同时,重构正交滤波器记为g(p,waveletbasis)′和h(p,waveletbasis)′。
2 清音检测方法
2.1 谱熵与浊音检测
如图1所示,当使用16位量化,采样率为11.025 kHz的语音,其内容为英文“passage thirty-six”,信噪比为10.720 9 dB,分帧方法为:帧长256,帧移128,矩形窗。计算得到的谱熵显示,谱熵基本上不会受到清音或白噪声的影响,是一种很好的浊音检测方法。
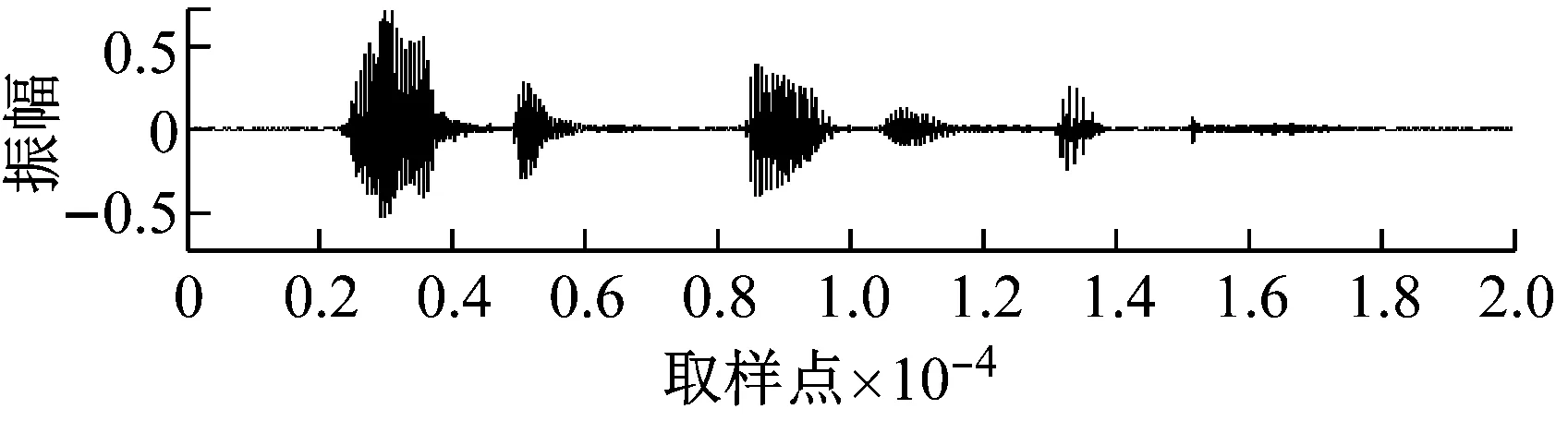
(a) 无噪信号

(b) 染噪信号
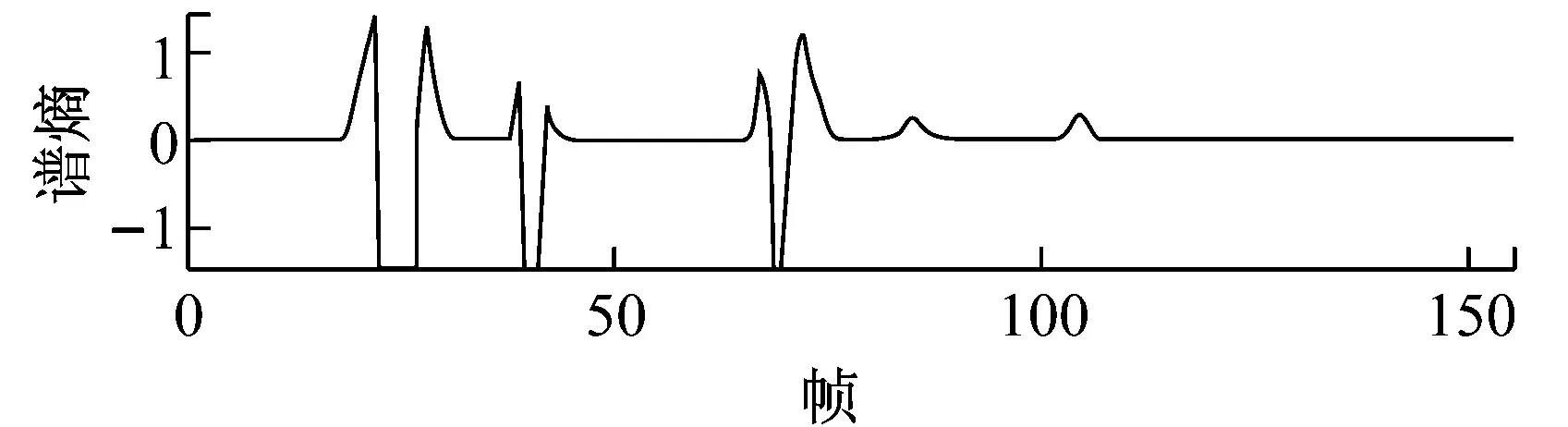
(c) 染噪信号的谱熵
图1 染噪信号的谱熵
浊音的检测方法如下:
(1) 按照式(3)计算每帧信号的谱熵值,组成谱熵序列。
(2) 选择门限。选择2个门限Thmax,Thmin,它们分别是某些非浊音段的谱熵最大值和最小值,可以根据语音信号前面和后面预留的无声段进行选择。只有连续大于Thmax或者连续小于Thmin的谱熵对应帧,才能被认为是浊音。一般情况下,浊音的谱熵在开始时比较明显,因此,为了提高浊音开始点检测的准确性,进一步消除噪声的影响,对两个选定的门限进行如下调整:
Thsmax=1.5Thmax
(6)
Thsmin=0.5Thmin
(7)
如果检测到连续3帧信号的谱熵值都大于调整后的Thsmax,或者小于调整后的Thsmin,就认为浊音开始。另外还需要注意的是,在噪声很低情况下,根据信号噪声得到的门限Thmax非常小,不能正确识别出浊音来,因此,需要对它设定一个下限,通过多次试验测定显示,该下限设定为0.003能够很好地满足要求,并使得检测无论是在高背景噪声还是低背景噪声下,都能够有效地检测出浊音来。
(3) 对浊音结束进行相应判断。浊音虽然在开始时特征比较明显,但是在结尾部分其特征却是缓慢下降的,特别在尾音,甚至和噪声或者清音的谱熵相当。因此,为了检测到更精确的浊音结束点,需要对浊音的结束条件加强约束。这里使用的约束方法是:使用调整前的门限Thmax和Thmin。结果表明,使用不同门限对浊音开始和结束进行判断时,得到的检测效果有一定进步。如果检测到连续3帧信号谱熵都小于Thmax,并且大于Thmin,认为浊音结束。
对于检测后确定为浊音的信号部分,将其全部置零,然后使用该信号进行清音检测。
2.2 熵与清音检测
根据分析,熵函数对清音和白噪声有一定的分辨能力,如图2(a)、(b)所示,在时域信号中,当清音和白噪声无法辨认情况下,使用信息熵仍然能够在一定程度上区分出清音来。为了能够更好地检测和提高分辨能力,在检测清音时,使用的帧长为128,帧移为64。清音检测方法如下:
(1) 根据式(2)对分帧后的各帧信号计算其信息熵序列(见图2(b))。
(2) 使用小波滤波方法对熵进行平滑和连续性处理。如图2(b)所示,虽然清音有明显的信息熵尖峰存在,但是由于选择的门限不一定是最优的,同时随机的白噪声有可能在某个短暂的时刻超过门限,并且即便是清音,由于它和白噪声的相似性,也有可能出现连续清音中低于熵值门限的情况,这些都会使连续的清音被分割成许多不连续的部分。同时也会增加个别白噪声信息熵尖峰影响检测结果的可能性。因此,在这里采用小波滤波对信号的信息熵序列进行平滑处理。
通过仿真试验,发现使用db2小波对信息熵序列进行了2层分解,然后,使用haar小波和小波系数cA2进行重构,能更好地获得平滑作用,如图2(c)所示。每个正交小波基都对应了一组正交镜像滤波器,本文使用db2进行小波分解,并用haar小波进行重构,相当于使用了g(p,db2)和h(p,db2)对输入信号进行高通和低通滤波,并用g(p,haar)′和h(p,haar)′对上述采样后的小波系数进行高通和低通滤波。选择haar小波,主要是因为它的形状类似矩形,用在重构中,能使重构后的信号有一定的类似矩形结构(见图2(c)),从而保证了平滑效果,称为块化效应。
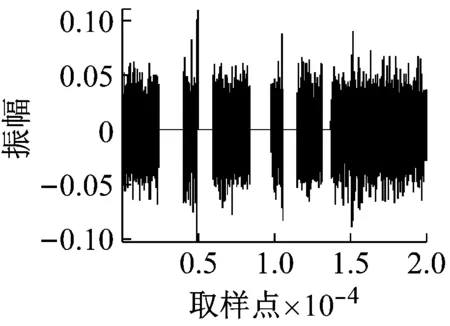
(a) 去除噪声后的染噪信号

(b) 剩余染噪信号的熵

(c) db2分解haar重构
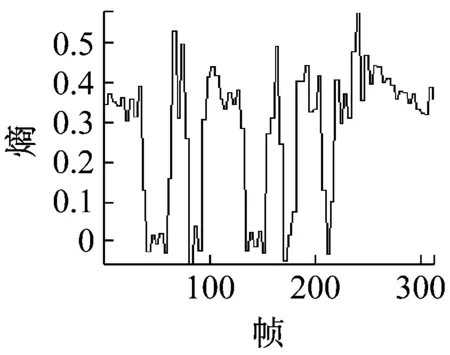
(d) dmey分解haar重构
图2 去除浊音后的染噪信号的信息熵
但是,当观察到3(c)中的某些比较明显的清音部分,如3(b)中第40帧左右位置的一个尖峰在平滑后消失了。经过仿真试验发现,如果使用dmey小波对信息熵进行分解,并使用haar小波进行重构,能使清音部分的信息熵值更多地保留下来,重构效果如图2(d)所示。同时发现,虽然单单使用dmey小波可以更好地检测出被忽略的清音,但是又会因为其平滑效果不如db2好,而造成许多连续清音的断裂。因此,选择同时使用这两种小波基来进行小波分解和重构,之后将检测到的清音段进行叠加。结果显示,这种操作既可以避免清音断裂情况的出现,又能够很好地检测出一些轻微的被淹没的清音来。
平滑处理后,根据信号各帧的信息熵水平,选择合适的门限,再对清音帧进行判断。因为清音和白噪声非常相似,为了提高检测精度,除了缩短帧长及帧移以外,在选择门限时,也应当避免选择非清音帧对应的最大熵值,而应该在可以接受的条件下,选择比较小且能比较好地区分清音和白噪声的门限。本文具体的处理方法为:计算信号前后部分帧的熵值,从中选择次大的作为门限,如果连续2帧信号大于该门限,就认为清音开始,若连续2帧信号的信息熵小于该门限,就认为清音结束。
2.3 清音检测结果
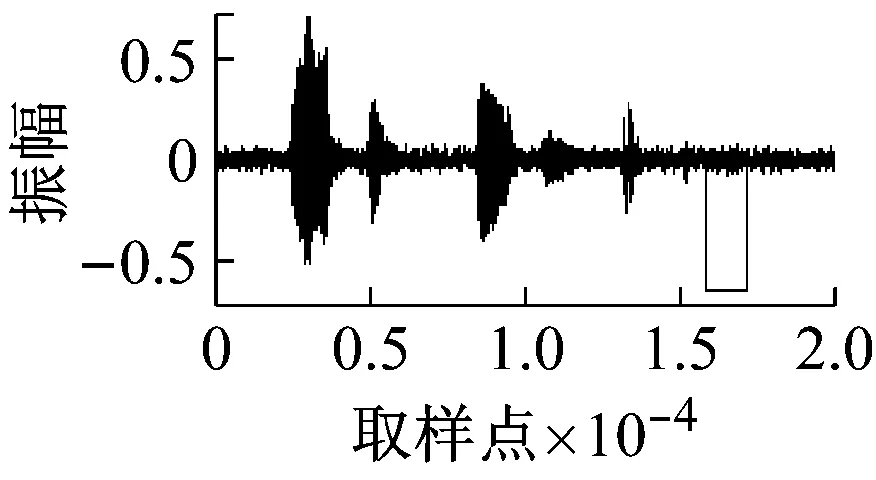
在浊音检测及清音检测完成后,需要对结果进行一些调整,因为将浊音部分置零和分帧都会使得清音和浊音的边界产生模糊,可能会使某些已被检测为浊音的部分又被检测为清音,因此,在出现这种情况时,应当认为这些重叠部分是浊音,而将清音检测的开始点后移到浊音结束的下一个位置,或者将清音检测的结束点前移到浊音开始的上一个位置。最终的检测结果如图3所示。
图3(a)是染噪信号,图3(b)是检测到的浊音和清音内容。上面的方框内是浊音部分,下面的方框内是清音部分。在该语音中,“passage thirty-six”一共有5个浊音,分别是// /ei/ /з:/ /i/ /i/,已经被全部检测出来,清音共有7个,分别是/p/ /s/ /d/ /θ/ /t/ /s/ /ks/,除了“six”中s的发音被检测为两段外,其他部分都被检测出来了。而这些清音中的大部分是淹没在白噪声中的,如图3(a)所示。

(a) 染噪语音
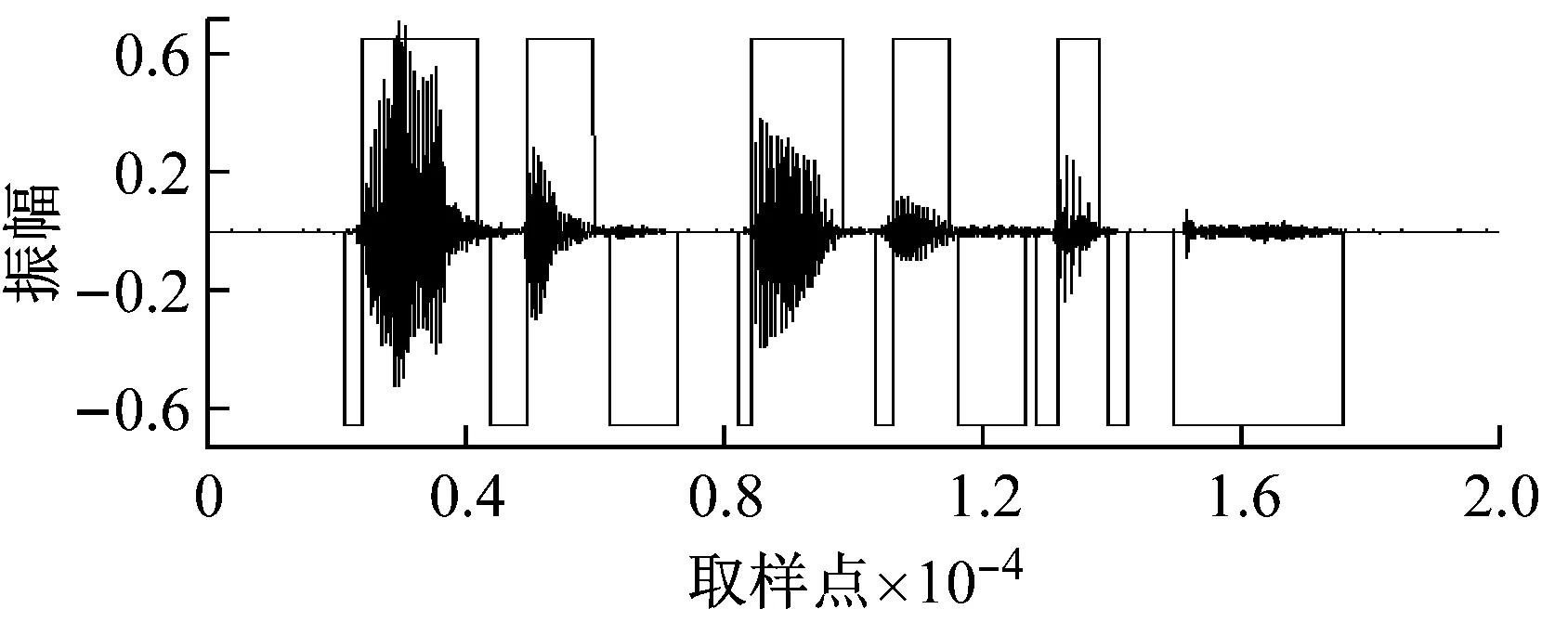
(b) 清音检测结果
图3 染噪信号清音检测结果
3 试验仿真
使用内容为“passage thirty-six”的语音,在不同信噪比下进行清音检测,检测结果如图4所示,噪声类型为白噪声。其中图(f)为无噪声条件下浊音、清音的检测结果,(a)~(e)分别为5、10、15、20、25 dB下的检测结果。图中显示,本文提出的方法,在10 dB及以上信噪比条件下,取得的检测结果很好,特别是10 dB条件下,而此时的清音基本上已经被白噪声所掩盖。

(a)

(b)
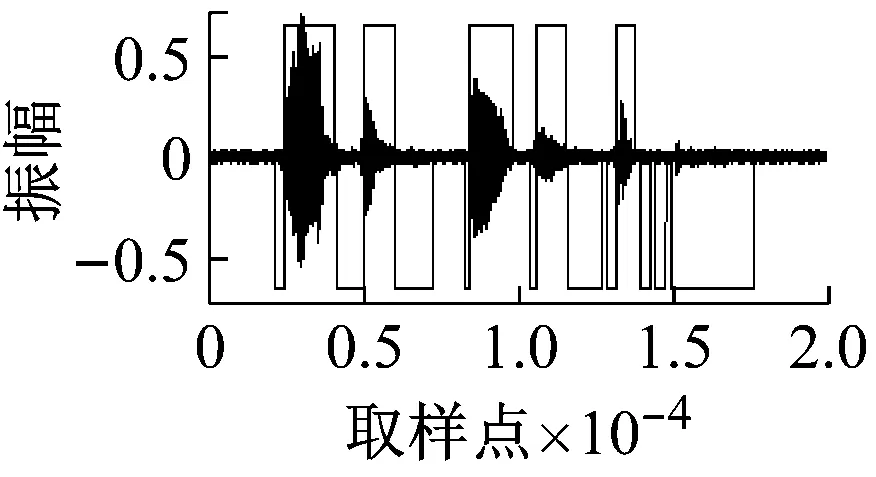
(c)

(d)
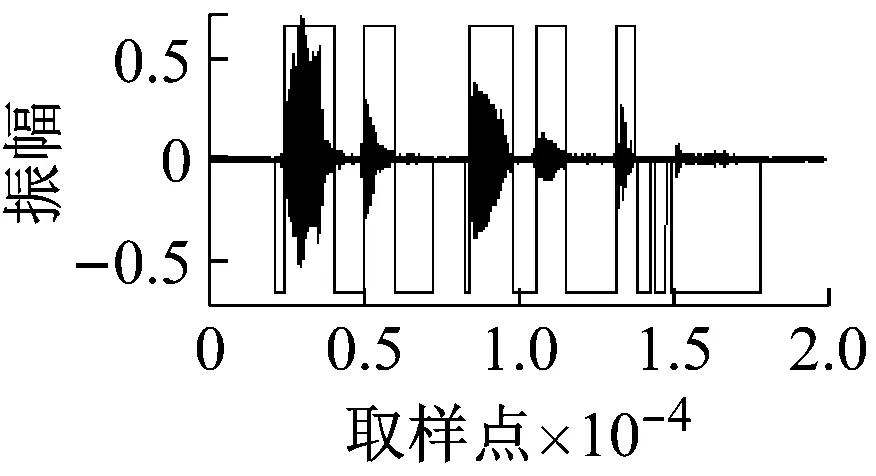
(e)
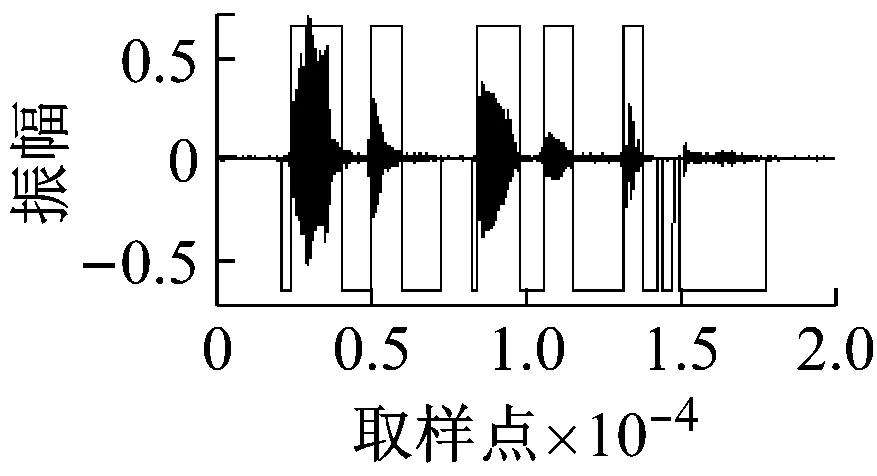
(f)
图4 不同信噪比下的检测结果(本文方法+白噪声)
随机在马路上采集一段实际噪声,然后加入到上述纯语音中,分别使用本文中方法和基于子带的方法[5]进行清音检测,得到的结果如图5和图6所示。信噪比顺序与图4中的相同。

(a)

(b)

(c)
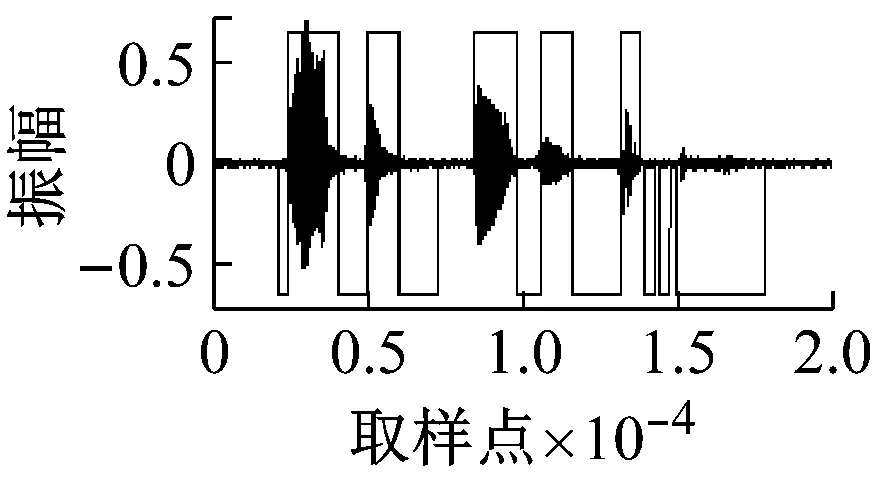
(d)
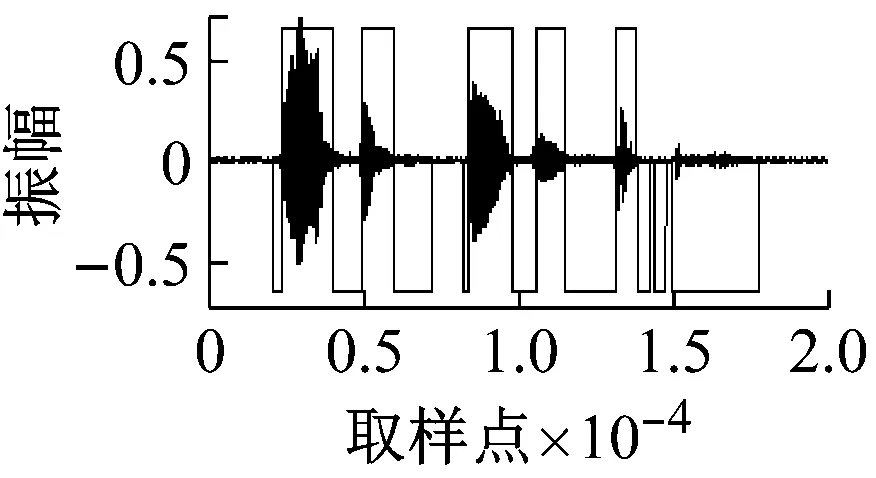
(e)
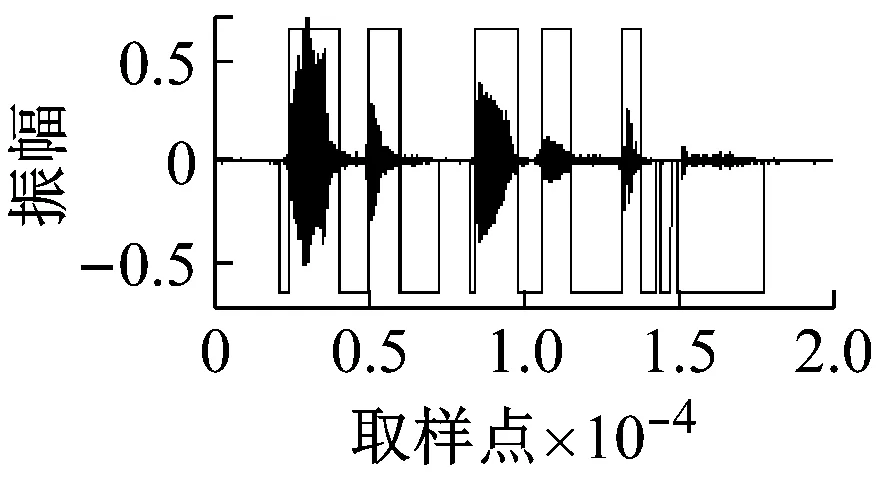
(f)
图5 不同信噪比下的检测结果(本文方法+实际噪声)
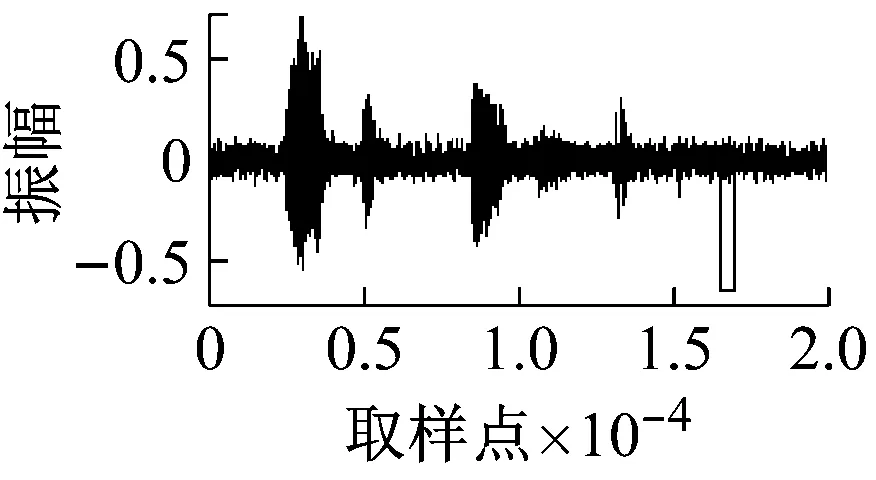
(a)
(b)

(c)

(d)

(e)
(f)
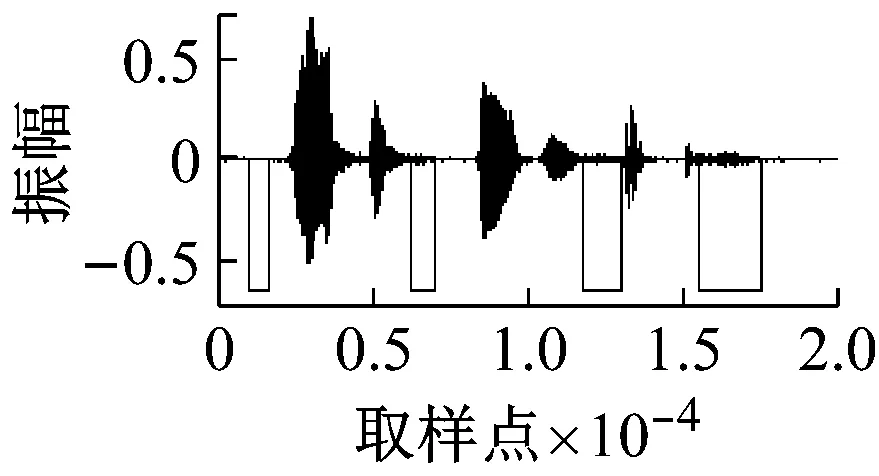
图6 不同信噪比下的检测结果(子带方法+实际噪声)
通过对比可以明显得到,本文的方法能够检测出更多清音来,并且其鲁棒性也明显优于基于子带的方法。
4 结 语
在语音信号的端点检测及声韵分割等技术中,困难主要在于清音的有效检测。使用本文的方法,能够将所有的浊音和几乎全部的清音很好地识别出来,即使在清音完全掩盖在噪声中时(包括白噪声和实际噪声),本文的方法仍然可以很好地检测到清音。
浊音、清音、无声段的检测对于语音增强、语音识别都有重要的意义。以语音增强为例,通过对各种典型语音使用小波收缩法进行消噪[10]时,在小波基的选择上,对浊音段使用dmey小波,对无声段使用haar小波能够取得更好的效果。同时,其他消噪参数,如阈值算法等的选择,也需要分辨语音是否是清音[4-6],然后再进行处理。
本文中,判决门限,包括浊音判决和清音判决,对于结果而言都是非常重要的。本文使用的门限估算方法为全部语音信号前后的无音帧的(谱)熵最大值与最小值的加权处理。因此,该方法要求语音前后要有一定的无声段用来估计门限,若能与自适应方法相结合使用,会取得更好的效果。
