基于U-net模型的航拍图像去绳带方法
2019-10-14洪汉玉孙建国郑新波
洪汉玉,孙建国,栾 琳,王 硕,郑新波
(1.武汉工程大学 湖北省视频图像与高清投影工程技术研究中心,湖北 武汉 4300732.深圳光启高等理工研究院,广东 深圳 518000)
引言
光启云端号是一个特种充满氦气的纤维囊体,主要工作范围在4 000 m~5 000 m高的空域,通过飞艇下面的吊舱做监控和航拍服务,吊舱使用最新计算机技术实现多种功能模块灵活搭载,通过“一根缆”(光电复合缆)系留于地面锚泊系统,最后接入大数据中心。在实际航拍中,所获得的图像会包含绳带信息,而这种非均匀结构的绳带不仅不利于场景分析,也不利于进行有效目标的检测,因此,必须使用图像信息处理技术消除绳带干扰,复原图像中实际场景,为进一步分析图像提供数据支撑。光启云端号如图1所示。

图1 光启云端号Fig. 1 Kuang-chi Cloud
图像中绳带去除主要包含绳带图像的检测和绳带图像的修复两部分,其中最关键的是绳带图像的检测。绳带图像的检测可以抽象为线检测或者条带检测,目前对线检测采用的方法大致有两类:一类是基于Hough变换及其改进算法[1-3]的线检测,该方法对噪声不敏感,鲁棒性好,对遮挡问题易处理,但是在实际情况中存在极大的局限性,如计算量大、准确率低且不能检测弯曲部分等;另一类是基于对比度特征的线检测方法,其基本原理是利用绳带像素与绳带周围像素区域存在的对比度关系来提取特征[4-5],该方法可以检测条状特征的物体,但是在实际中该方法的检测结果容易出现断裂、误检等问题。因此,前面的2个检测方法在图像中绳带的检测难以适用。图像中绳带的修复主要采用FMM算法[6],该算法速度较快且对噪声不敏感,在实际测试中能得到了很好的效果。
随着机器学习理论的发展,深度学习在人脸识别、无人驾驶[7]等领域发挥着越来越重要的作用。基于深度学习的相关问题属于图像分割问题,其代表是FCN[8]及其改进网络SegNet[9]。但是针对图像中具体的内容检测如条带检测的文献较少,现有的网络存在难以训练、数据需求大、训练时间长等缺点,已有方法难以解决实际航拍图像中背景复杂、绳带弯曲等问题。目前,Ronneberger等人提出的U-net[10]在少量样本数据和医学图像中的目标分割[11]上有着广泛的应用,该网络是一个基于FCN思想设计的网络模型,只有卷积层,没有全连接层,可以有效地检测图像中的目标。将其应用于图像中绳带的检测分割中,发现存在绳带数据过少,像素比例分布严重不均匀,模型不能收敛等问题。
为此,本文提出一种基于U-net的绳带检测改进模型,只需要较少的训练数据和较短的训练时间,模型就能够收敛,得到的检测结果通过改进的OTSU[12]做一个精细分割后,采用FMM修复算法能够有效地去除图像中的绳带。
1 基于U-net的绳带检测方法
在云端号拍摄的图像中背景有很多条状的物体,这些物体给绳带检测带来很大的干扰,基于多层卷积网络的算法能够很好学习到绳带和背景信息的特征,这些特征经过卷积的层层计算会越来越复杂,通过这些提取到的特征能够用来区分这些非目标物体和目标物体,从而检测出图像中的绳带。本文方法的流程如图2所示。

图2 本文检测方法流程图Fig 2 Flow chart of detection method of this paper
1.1 U-net模型
1.1.1 网络结构
基于深度学习的算法往往需要大量的隐藏层来提取更加抽象的特征,可以用来检测更多类别的物体,但是在实际情况中,我们只需要检测一个类别,并且这个任务可以归于实例分割,所以原始网络模型的参数会有很大冗余,而参数过于复杂会给模型收敛带来困难。理论上已经证明,通过去掉那些不重要的参数,可以使模型具有更好的泛化能力[13],并且只需要更少的训练数据就可以提高训练和检测速度。如图3所示,在U-net的基础上每层卷积核的数量做了适当调整(见图3),输入一个480×272×3 pixel的图像,输出一个单通道的绳带检测结果,模型结构前半部分与VGG相似,所有的卷积都是3×3卷积+ReLU+批量归一化的组合形式,解码器部分均采用最大池化,编码器部分均没有池化层。由于数据的多样性太少会增加过拟合风险,为了抑制过拟合,同时加快收敛速度,所以模型在同层的卷积中都加入一个Batch Normalization层[14]。最终的模型结构的网络层次和深度都是通过多次实验后确定的,具体网络结构如图3所示。

图3 U-net模型结构图Fig .3 U-net model structure
1.1.2 深度可分离卷积
实验中发现模型中的参数存在很大冗余,所以本文把大部分的传统卷积全部换成深度可分离卷积[15],该卷积的计算过程为
(1)
式中:S为输出特征图;H为卷积核;I为输入特征图;i,j为特征图像素位置;k,l为输出特征图分辨率;m为通道数。
深度可分离卷积包含depth-wise和point-wise,depth-wise中每个特征图只用一个卷积核提取特征,point-wise则是传统的1×1卷积,用来组合各个通道的特征图。深度可分离卷积与传统的卷积操作的参数量比例定义如下:
(2)
式中:K为depth-wise的卷积核的大小;N为point-wise的卷积核数量;M为输入特征图的数量;G为point-wise卷积的分组数。由(2)式可知,输出特征图数量越多,深度可分离卷积参数数量压缩率越大,通过这种方式提高卷积参数的利用率,从而大幅减小工程的存储开销。
1.1.3 引入双线性插值的反卷积
在恢复分辨率时一般采用上采样运算。上采样是一般采样的逆运算,即像素根据步长重复,这个方法在实际中会使每层恢复分辨率后的特征图会很粗糙,最后的绳带位置可能会有略微的偏移。因此,本文采用双线性插值的反卷积来恢复解码部分的分辨率。双线性插值的反卷积在像素之中增加了过渡值,预测的绳带像素的概率值更加平滑和鲁棒,使解码器部分的特征图更加合理,双线性插值的反卷积的操作如图4所示。
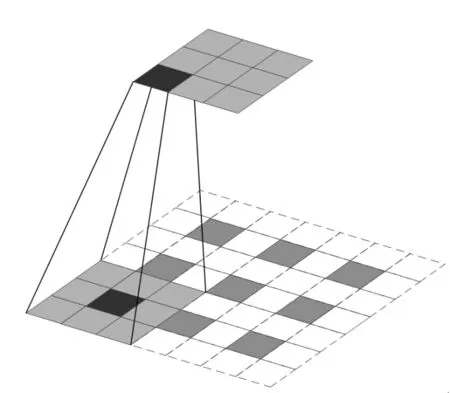
图4 反卷积操作Fig. 4 Deconvolution operation
1.1.4 损失函数
本文模型最后一层使用Sigmoid计算每个像素点的值,Sigmoid公式为
(3)
式中:z表示输入的像素值;sigmoid(z)为输出的预测绳带像素的概率值。
实验中发现图像中绳带的数量较少,且绳带像素在整个图像中的比例非常小,此类任务属于小目标的图像分割,这种非均匀的样本会给模型收敛带来困难,当图像中所有的像素都被识别成背景,准确率依然较高并且损失也较低。因此,绳带像素的重要程度大于非绳带像素,一种比较容易的解决方案是,处理这种类别不平衡的方式就是根据类别的重要程度加上不同的比例权重。基于经验本文定义的损失函数为

(1-w(x))·(1-p(x))·logq(x))
(4)
式中:X表示整幅图像的像素;x为X中一个像素值;w(x)为绳带像素的权重;q(x)为sigmoid在x处预测的像素值;p(x)为标记图在x处的实际像素值; Loss表示预测结果与标记图之间的距离。w(x)表示为
(5)
式中:x为计算时的像素,当x属于绳带位置时该点的损失的权值为w。(5)式表示绳带像素与非绳带像素的权重比例为w∶1,当w为1时,则退化成原始的交叉熵。
1.2 训练绳带数据的准备
目前还没有相关开源复杂背景的绳带图像数据可供下载,本文训练数据主要为两部分:一部分来自于云端号上直接拍摄的图像数据,可以直接训练;另一部分是人工采集的其他相关数据,采用拍摄的部分校园电线图像数据,通过Photoshop软件标记绳带。每对训练的数据如图5所示。

图5 训练的绳带数据Fig.5 Training rope dataset
本文的原始数据总共有375对图像,每对图像包含一张绳带图像和对应的绳带标记图,其中训练集300对,测试集75对。使用TensorFlow的内置数据增强工具,抖动参数设置为0.05,随机裁剪参数设置为0.2,增强的数据都是在训练时在线生成的,最终的训练绳带数据总共有2 400对。
1.3 绳带检测训练方法
本文训练时采用Adam的优化函数,前10个epoch的学习率始终设置为0.001,后10个epoch的学习率为0.0003,所有的卷积核采用He[16]的均匀分布初始化,batch size设置为8,每个epoch迭代300次,由于硬件条件的限制,最终在训练的时候,输入图像的尺寸会缩放到480×272×3 pixel,最后输出480×272×1 pixel检测后的绳带灰度图。
原始的U-net网络收敛不稳定,模型存在一定概率不能收敛,测试10次中有5次不能收敛或者收敛效果不好,本文提出的模型在10个epoch后能达到很好的效果,后面的提升很小,在经过20个epoch后模型基本已经收敛、趋于稳定。本文的模型在最终测试时用了10个epoch,mAP(MeanAveragePrecision)达到98.56%,mIoU(Mean Intersection over Union,均交并比)达到62.8%,实验中发现当 取10时能达到最好的效果。
1.4 图像中绳带的检测
前面在训练的时候为了提高运行速度,对输入的图像进行了缩小,所以检测的时候也需要缩小,同理输出后的图像需要放大到原来大小。经过前面卷积的层层计算,最后得到一个0~1的绳带像素预测概率矩阵,通过乘以255可以得到一个0~255的灰度图。此时的结果中会有很多灰度较小的像素形成水雾现象,为了转化成二值掩码图,采用OTSU做一个精细分割来剔除灰度值较小的像素,以便后面的图像修复过程更准确。
2 去绳带修复方法
图像中绳带的去除属于图像修复,通过前面的算法可以检测出绳带的像素位置,此时需要根据检测出来的结果去除图像中绳带。图像修复算法目前主要分为基于样本块的算法和基于偏微分方程(PDE)的算法[17]两大类,两大类算法的前提都是要预先知道待修复区域的位置。基于样本块的算法适用于修复较大的区域,但是存在速度慢、线性结构易产生模糊等缺点;基于PDE的算法可以克服速度慢、线性模糊等缺点,但是只适用于较小的区域修复。因此本文采用的基于偏微分方程的FMM算法,如图6(a)所示,先处理待修复区域边缘上的像素点,点q周围的像素为I,修复区域为Ω,修复边界为∂Ω,如图6(b)所示,点p到点q的梯度为▽I,为点Iq(p)搭配点p的一阶近似值。关系如下:
Iq(p)=Iq+▽Iq(p-q)
(3)

图6 FMM方法的原理图Fig. 6 Schematic diagram of FMM method
将q点周围的值通过加权求和,最后归一化值I(p)为
(4)
依次类推,层层向内推进,直到修复完所有的像素点。
3 实验与结果分析
本文采用前面的图像检测和修复算法,对绳带图像进行了大量实验,验证算法的可靠性和正确性。在Ubuntu18.04 64位原生操作系统平台上,用到的硬件环境为Intel I7-7700k、GTX1080、32G内存,使用Tensorflow深度学习框架和OpenCV为主要工具。实验2和实验3均是在w取10时的结果。
实验1,改进交叉熵实验对比。本次实验是权重对训练时的准确率对比实验(其中都是选取收敛了的情况),当w=1时损失函数为原始的交叉熵,此时能检测一般直的绳带,但是模型收敛不稳定,存在一定几率不能收敛,w=10时检测的效果最好,同时模型也基本都能收敛,当w大于10时,收敛的效果开始变得较差,有较多的模型背景被识别为绳带,这种情况给后续OTSU的精确分割带来极大的困难。增加绳带像素的损失函数权重,能更好地检测出绳带像素,但是当手动设置的权重太大时会导致模型收敛的效果变差,实验中发现当w=10时能达到最好的效果。

图7 损失函数取不同权重时的结果Fig .7 Partial results of loss function when taking different weights
实验2,图像绳带检测的实验对比。基于随机Hough变换、对比度特征的线检测模型和U-net以及本文算法的实验结果对比如图8、图9和图10所示,图片下面小图均为部分细节放大9倍结果。对于图8(b)、图9(b)和图10(b),Hough变换很难检测出有用的信息,有大量背景信息被误检,同时弯曲打结等绳带几乎检测不到;对于图8(c)、图9(c)和图10(c),基于对比度特征的线检测算法很难克服复杂背景、绳带弯曲的困难,漏检问题很严重;对于图8(d)、图9(d)和图10(d),SegNet能很好地检测到绳带,但是在分割的边缘部分存在很大的误差;对于图8(e)、图9(f)、图10(e)和图10(f),U-net网络和本文的方法能达到很好的效果,一般的弯曲绳带信息都能被检测出来;如图8(e)和图8(f),本文提出的模型在部分细节上比U-net表现出更出色的结果;而图9(e)、图9(f)、图10(e)和图10(f),由于绳带被背景覆盖,所以绳带会出现少量漏检,大部分情况下在绳带宽度不确定时本文的模型表现出更高的准确率,在打结部分和细绳带部分检测的准确率更高。


图8 多根绳带时检测结果对比Fig. 8 Comparison of test results when multiple ropes


图9 绳带打结时检测结果对比Fig. 9 Comparison of test results when rope is knotted

图10 复杂背景时检测结果对比Fig. 10 Comparison of test results in complex background
原始U-net存在不能收敛的情况或者收敛的速度很慢,本文的模型收敛的更快,同时解决了模型收敛不稳定的问题。最终模型的性能对比如表1所示。

表1 算法性能对比
实验3,图像去绳带的修复算法。如图11(a)和图11(b)所示,在多根绳带场景的实验中,4根被检测到的绳带都被很好地去除了;如图11(c)和图11(d),在弯曲打结绳带场景的实验中,宽度不一的绳带以及弯曲打结细节部分也被去除了;如图11(e)和图11(f),在复杂背景场景的实验中,同样出色地去除了图像中绳带,所有图片下面小图为部分细节放大9倍的结果。
4 结论
本文提出一种基于改进U-net的图像绳带检测模型。通过加入深度可分离卷积来压缩模型参数,同时优化了网络的结构,引入BN层减少过拟合,引入双线性插值的反卷积提高分割精度,提出带权重的交叉熵函数和采用的He初始化提高了收敛的稳定性。从最终的实验结果可以看出,U-net和本文的方法优于传统方法,但是本文模型的训练和测试结果比U-net算法速度更快,同时解决了U-net收敛不稳定的问题,在部分场景优于原始的U-net,特别是在部分打结和弯曲的绳带上,最终取得了很好的结果,mIOU达到62.8%,进一步证明本文算法的正确性。采用基于FMM的图像修复算法,利用检测到的绳带位置,得到了非常好的图像去绳带效果,这一结果为在云端号上拍摄高质量图像提供了技术支持。

图11 去绳带实验结果图Fig. 11 Experimental results of rope removal test
致谢:本文的实验数据由深圳光启科技有限公司提供,写作过程中黄正华老师对论文的研究方向做出了指导性的意见和推荐,提出了许多有益的改善性意见,在此致谢。
