SCE 大数据平台接入的研究与实现
2019-10-11韩伊梦王小宁肖海力迟学斌
韩伊梦,王小宁,肖海力,迟学斌
1.中国科学院计算机网络信息中心,北京 100190
2.中国科学院大学,北京 100190
引言
SCE 是中国科学院计算机网络信息中心牵头建设、自主研发的科学计算中间件。其聚合了“天河一号”、“天河二号”、“神威·蓝光”和“神威·太湖之光”等超级计算机资源,构建了超级计算环境。SCE 屏蔽了底层不同超级计算机之间的差异性,提供了统一的入口与命令行为用户提供服务。
SCE 目前提供的资源[1]主要是超算中心、高校与研究所的超级计算机资源。硬件资源方面,目前已经接入无锡中心、天津中心、济南中心、深圳中心、长沙中心、广州中心等国家超级计算中心,和清华大学、西安交通大学、中国科学技术大学、北京应用物理与计算数学研究所、山东大学、香港大学、中国科学院深圳先进技术研究院、华中科技大学、甘肃省计算中心、上海交通大学、吉林省计算中心等高校与研究所的计算资源。软件资源方面,SCE 提供了AutoDock、Blast、CP2K、CPMD、cuda_compiler、DL_POLY、DOCK、EspressoMD、GAMESS 等个开源的基因对比、分子模拟、量子化学等科学计算软件和编译器,AMBER、Abinit、CASTEP、CHARMM、Discovery Studio、Gaussian、sw_compiler、swmpi和VASP 等分子模拟、量子化学或编译器类商业软件,以及 ABACUS、ARCpilot-ATALAS、inter_match_Inx和 PHDEMO 等自研软件。
自 Google 公司提出 GFS、MapReduce 和BigTable“三驾马车”这三项技术后,Apache 基金会基于其的基础之上,推出了大数据平台 Hadoop。目前,在学术界与工业界,大数据与云计算技术应用广泛,许多热门人工智能与深度学习系统都是基于大数据平台进行部署与运行的。近年来,随着 SCE 用户对于海量数据处理与大数据计算需求的日益提升,SCE 提供大数据平台满足用户的需求亟待解决。
1 背景
1.1 SCE 介绍
SCE 自上而下可以分为三层结构[2],分别是应用层、服务层与资源层。
应用层可以分为客户端 Client 和 API (Application Interface) 接口。客户端主要负责与用户的交互,为用户提供了作业提交、查询作业、节点查询、等一系列命令行操作;API 为用户提供了可调用的接口,让开发者级用户可以使用接口编写自己的代码。
服务层连接用户与底层资源的一层,是 SCE 提供服务的重要组件。可以分为中央服务器 CS (Center Server) 和前端服务器 FS (Front Server)。中央服务器负责 SCE 的调度、管理、信息汇总等功能,是 SCE的核心部分。前端服务器是的中央服务器与底层资源的中间层次,实现了屏蔽底层资源异构性和汇报资源信息的功能。
资源层就是各中心、高校与研究院的高性能计算机资源 HPC。用户作业将被提交到服务层,再根据用户预先指定的机型、核数下分给不同的计算节点。目前 SCE 的底层资源都是高性能计算集群,支持的作业管理系统有 LSF、Torque PBS、PBSPro、SLURM、SW 等适用于高性能计算集群的作业管理系统。
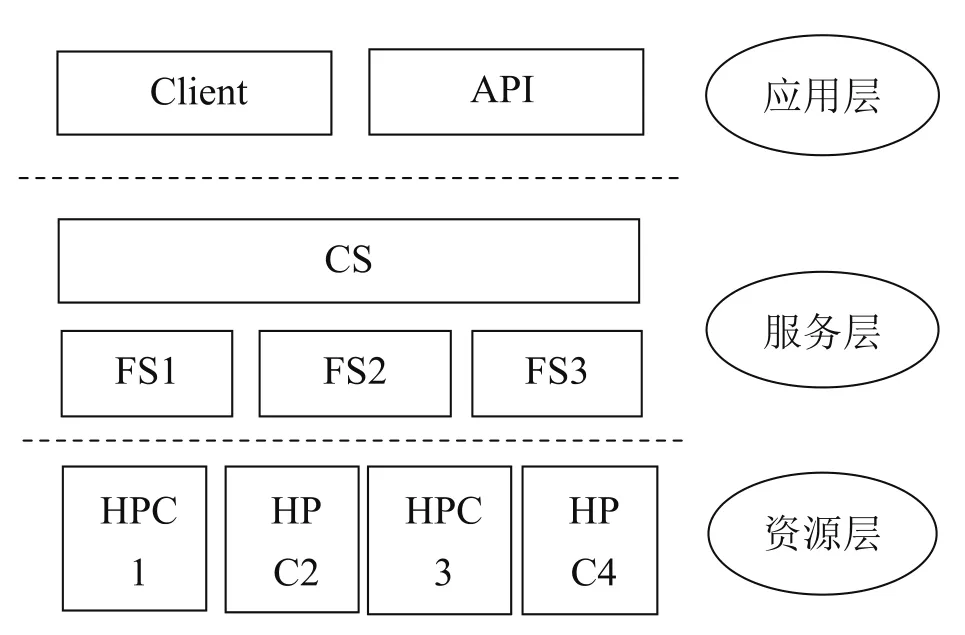
图1 SCE分层结构图Fig.1 Hierarchical Structure of SCE
1.2 YARN 介绍
1.2.1 YARN 简介
YARN (Yet Another Resource Negotiator)[3]资源管理器是第二代 Hadoop 的资源管理器。第一代 Hadoop 的架构为客户端、jobtracker、tasktracker与 HDFS 四个实体。而新一代 Hadoop 框架中,将 jobtracker 职能进行拆分为资源管理器 (resource manager,RM) 和结点管理器 (node manager,NM),将 MapReduce 与 YARN 分开。这种抽象独立的架构改善了系统集群规模扩展性瓶颈,同时使得 YARN资源管理器能够支撑多种计算引擎,包括 Hadoop MapReduce 和 Spark 等。
以下是 YARN 的几个重要模块的介绍:
(1) 资源管理器:YARN 负责分配集群计算资源的模块,是 YARN 的中心模块。它接收来自结点管理器的汇报,启动各应用程序的 master,并将资源分配给应用。
(2) 结点管理器:YARN 的结点管理模块,负责启动和管理集群机器上的容器。
(3) 应用程序 master (application master,AM):YARN 每起一个应用,都会为应用启动一个 master,其负责向资源管理器申请资源,并请求结点管理器启动容器,告知容器执行的任务。
(4) 容器 (container):YARN 中所有的应用都是在容器之上运行的,这其中也包括应用的 master。
1.2.1 YARN 的工作流程
在安装了 Hadoop 并配置完成的集群中,YARN就可以正常使用。
用户在YARN 上运行一个应用程序需要先提交,提交之后,在YARN 中会分为两大阶段来运行:1,启动应用程序 master。2,在master 监控下运行应用程序。主要有以下几步:
(1) 用户向 YARN 提交应用程序;
(2) 资源管理器为应用程序分配一个容器,向结点管理器发送启动程序与程序 master 的请求,启动master;
(3) 应用程序 master 在资源管理器上以轮询的方式,通过某 RPC(Remote Procedure Call) 协议向资源管理器申领资源。同时也担任监控它们的运行状态的职责;
(4) 申请到资源后与结点管理器通信,启动任务;(5) 结点管理器为任务设置好运行环境(将作业配置、jar 文件、缓存文件等进行本地化),启动任务;
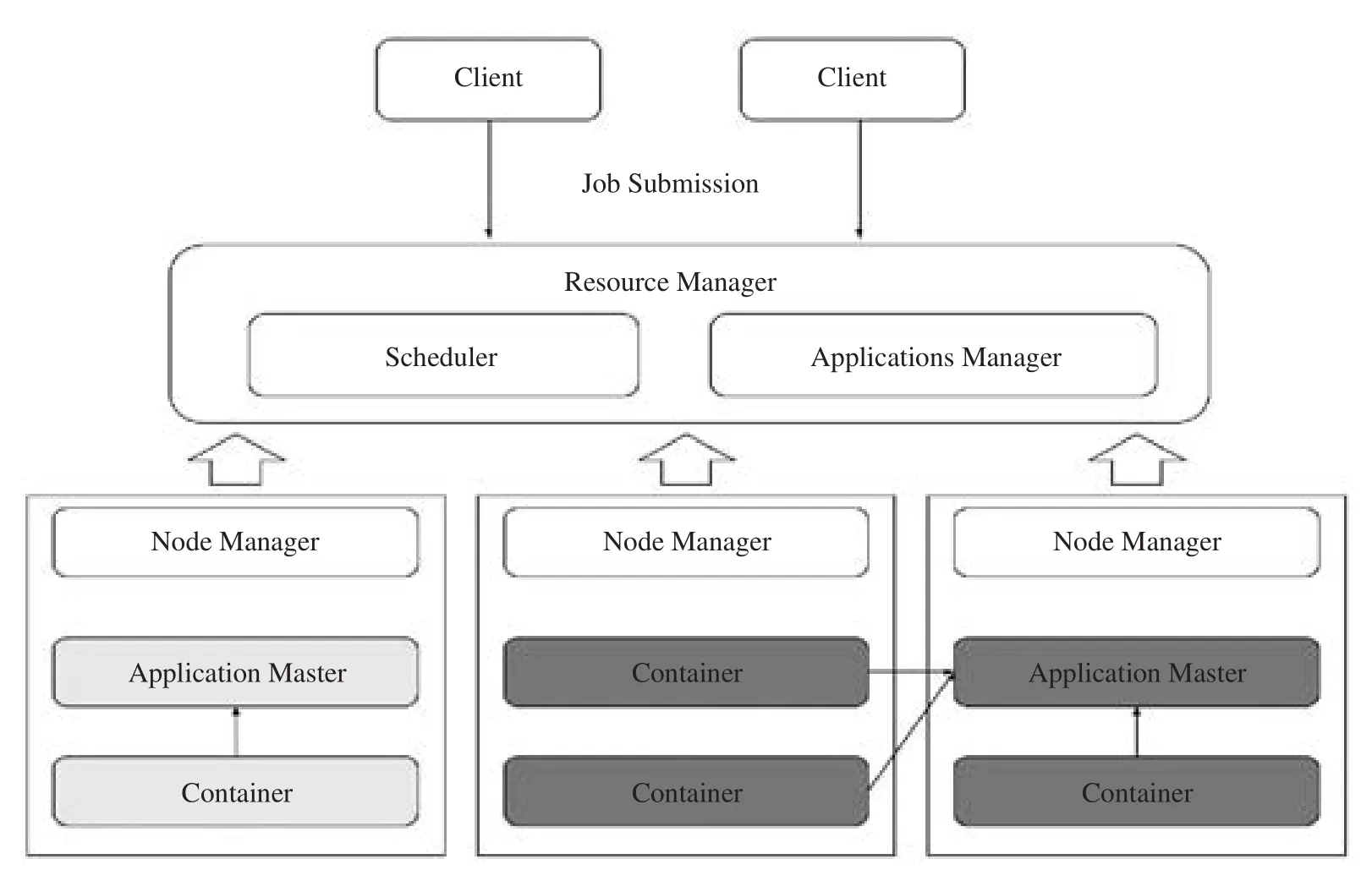
图2 YARN 结构图Fig.2 Structure of YARN
(6) 各任务通过某 RPC 协议与 master 进行通信,汇报状态与进度。当任务运行失败时可以重新启动;
(7) 程序运行完成后,master 与容器清理自身工作状态,master 向资源管理器注销并关闭自己。
以上是理想情况下的用户任务运行流程,在实际情况下会产生代码、进程、机器等各方面的故障,而hadoop 可以对此进行很好的处理。
1.2.2 YARN 程序编写
开发者开发一个 Y A R N 的应用程序需要实现三个部分:客户端 (client)、应用程序master (application master) 和容器程序 (container application)。大部分运行在YARN 上的程序都提供了应用程序 master 和客户端的丰富的库,并且提供了容器程序的基础框架,所以我们基本上只需要做配置和编写容器程序就可以。
2 设计与实现
2.1 SCE 的服务层次的重新划分
云计算是指将系统硬件、研发平台、应用等计算机资源通过互联网提供给用户的服务模式。其主要包括三个云服务交付模型[4]:(1) 基础设施即服务(IaaS),提供基本计算资源,例如 Amazon EC2;(2)平台即服务 (PaaS),能够向上层用户提供应用程序开发和部署平台,例如 Google App Engine (GAE);(3)软件即服务 (SaaS),将软件应用程序作为在线服务,例如 Salesforce CRM。

图3 SCE提供的服务类型Fig.3 Types of Service Provided by SCE
借鉴云计算领域的划分方式,目前 SCE 为用户提供的服务同样可以这样分类:其为用户提供各地的超级计算机集群作为计算资源,可以看作是基础设施即服务 IaaS;在超算上部署各类科学计算软件提供给用户使用,则是软件即服务 SaaS。本文想要使得SCE 可以接入大数据平台,拓展 SCE 的服务层次,使得 SCE 可以提供平台即服务 PaaS。
2.2 大数据资源管理器与传统高性能计算机管理系统异同
想要将 YARN 框架接入适用于传统超算管理系统的超算环境 SCE,就必须考虑到大数据资源管理器与传统超算管理系统的差别,下面就以 SLURM 为例,比较 YARN 与 SLURM 的异同之处。
SLURM[5]是一个用于大型集群的集群资源管理系统,广泛应用于超算集群管理,例如“天河一号”、“天河二号”等都使用 SLURM 进行高性能计算机群的调度。
在YARN 中有着节点、队列、应用、任务、资源调度等重要概念,而在SLURM 中也有一些类似的概念,同时还有资源预约等特殊概念。下面将二者之间一些基础概念进行简要的介绍和对比,阐述二者之间的不同。
· 节点
资源分配的最小单位,一般为一台可分配计算任务的机器。提交的任务就是在节点上计算的。
与 YARN 中的节点概念类似,是指计算节点。节点的状态与 YARN 的节点状态有所不同。SLURM 中节点状态可以分为空闲 (IDLE)、已分配(ALLOCATED)、故障 (DOWN)、不再分配 (DRAIN)、无响应 (NO_RESPOND)、退出中 (COMPLETING)、未知 (UNKNOWN) 七种。
· 队列
是 YARN 对于节点资源的一种组织方式,在YARN 不同的资源调度方式下有着不同的创建与组织方式。队列可以限制资源数、用户访问权限等。各队列间的资源是独立占有的。
类似于 YARN 中队列的概念,是对集群中节点资源的逻辑上的分配。分区可以被设置的属性有用户访问权限、作业可分配资源数限制、分区优先级等。在SLURM 中,节点可以属于多个分区,而非独占式。用户提交作业时需要指定分区,未指定分区的作业将被提交到默认分区中。(在YARN 中,节点是队列独占,容量调度下用户无需指定队列,调度器自动根据资源量来为用户作业分配队列,这种方式称之为弹性队列 (queue elasticity);在公平调度下,当用户提交作业后,放在以提交作业用户名命名的队列下,如果队列不存在,将会新建一个该命名队列。新队列按照配置规则分配资源,不同队列内部可以是 FIFO、公平调度或者 DRF (Dominant Resource Fairness)[8]的调度策略。)
SLURM 的分区有 UP 与 DOWN 两种状态。YARN 中的队列状态有 RUNNING 和 STOPPED两种。
在SLURM 中,对于分区的信息是可以通过scontrol –a show partition 获取的,并且获得的是直观的节点个数、cpu核数等信息,而在YARN 中队列信息会以百分比形式给出,并不是明确的。YARN 中队列的静态配置信息,不能通过命令行查询。
· 应用
即 application,是用户的一次程序提交以及后续的资源分配与及计算过程的合称。用户将写好的YARN 程序提交到资源管理器上后,就以应用为单位生成 AM 并进行后续的资源分配与计算。
类似于 YARN 中应用的概念。是指用户提交资源申请后的资源分配,一次资源分配就是对应一个作业,申请到的资源是不可跨分区的。SLURM中作业状态有 PD (PENDING)、R (RUNNING)、S(SUSPENDED)、CD (COMPLETED)、F (FAILED)、CA (CANCELLED)、TO (TIMEOUT)、NF (NODE_FAILED) 八种。YARN 中作业状态有 NEW、NEW_SAVING、SUBMITTED、ACCEPTED、RUNNING、FINISHED、FAILED、KILLED 八种。
· 任务
即 task,YARN 程序中分配到不同节点的任务。是计算的最小单位。
类似于 YARN 中任务的概念,是指作业在srun命令下的一次加载,可并发执行。但是如果用户不通过 SLURM 加载计算任务,将不会有作业步产生。在YARN 中,任务始终运行于节点 NM 所生成的container 中,受到 AM 的管理。
· 资源调度
YARN 中对用户资源请求有着多种不同的分配方式,常见的有先进先出 (FIFO(first in first out))、容量调度 (capacity scheduler[6]) 和公平调度 (fair scheduler[7])。
· 资源预约
资源预约,是 SLURM 中一种用户对于资源的一种提前的请求,由资源需求数、访问限制与使用起止时间组成。当用户的资源预约生效后,就可以使用预约资源来运行自己的作业。在YARN 中并不支持这种对于资源提前申请的预约方式。

表1 YARN 与 SLURM 对比Table 1 YARN vs.SLURM
2.3 接口程序实现
由上一节的总结可以得知,YARN 与 SLURM之间既有相同之处,也有许多的不同之处。将一个YARN 平台接入到 SCE 中,并提供与原有 SCE 支持的集群管理系统相类似的服务,需要在服务层的前端服务器FS上插入编写的接口程序,实现在不改变原有 SCE 命令行[9]输入输出的情况下,接入 YARN平台。
· 作业提交
输入:bsub generic jarfile mainclass /input /output
输出:成功会返回 success,并给出作业的 gid 与ujid。
原接口是将所有的参数如指定队列、请求资源数等在命令行输入,由接口程序组成提交指令。而一个编写好的 YARN 程序,会将自己的内存、cpu 需求、优先级与队列信息写在程序的 Client 部分中。所以提交指令仅需由 YARN 程序包、mainclass,input 文件路径、output 文件路径组装起来即可。
YARN 的程序提交后,会一直占用终端直到作业运算结束。这会导致不能及时返回作业ID影响作业信息提取。因此使用 nohup 指令让其后台执行,并且在sleep 五秒后,截获屏幕输出,获取所需信息。
· 作业终止
输入:bkill all/ujid
输出:cancel job [ujid]success!
封装 yarn application -kill
· 获取作业信息
输入:bjobs
输出:给出当前用户历史作业的 ujid、stat、exec_host、queue、ncore、jon_name、submit、update等信息。
封装 yarn applicaton –list –appStates ALL 指令,将所获得的作业信息格式化后,存入数据库让用户可以查询。向集群定时发送该指令以更新数据库。
· 格式化作业状态
Y A R N 作业的作业状态一共由 N E W、NEW_SAVING、SUBMITTED、ACCEPTED、RUNNING、FINISHED、FAILED和KILLED 八种。将其与 SCE 的 PEND、RUN、DONE、EXIT、DELAY、QERROR 六种状态分别对应,对作业状态进行格式化处理。其中,NEW、NEW_SAVING、SUBMITTED、ACCEPTED 对应 PEND,RUNNING对应RUN,FINISHED 对应 DONE、FAILED和KILLED 对应 EXIT,DELAY 无对应信息。若无法获取到作业状态或者作业状态不属于以上八种,则返回QERROR。
· 获取静态队列信息
YARN 的静态队列状态,即队列的配置信息,是无法通过命令行获取的。YARN 队列的配置信息在队列配置方法不同的时候,写在不同的文件中。当队列配置方法为 capacity scheduler 时,写在$HADOOP_HOME/etc/capacity-schedulelr.xml 中,队列配置方法为 fair scheduler 时,显式定义的队列是写在$HADOOP_HOME/etc/fair-scheduler.xml 中。需要对配置文件进行解析获取相关信息。
YARN 的队列配置与传统超算队列配置略有不同,并没有最大最小资源数这个概念,而是队列占用容量、最大可用容量、最少容量这些概念,并且是用百分比表示的。我们暂时用去掉 % 的数字来代替 SCE 所需要得到的信息。而队列为 capacity scheduler 配置方式时,仅子队列可提交任务,因此只有子队列的配置信息是需要的,仅提取子队列信息并格式化即可。
· 获取动态队列信息
输入:bqueues
输出:grid、hpc、queue、walltime、maxcpus、mincpus、njobs、pend 与 run。
使用 yarn queue -status
4 实验结果
我们选择在一台虚拟机上安装在fs层添加过测试代码的完整 SCE 软件,让单虚拟机同时扮演 Client、FS、CS 三种角色,并连接上在阿里云服务器上搭建的单机 Hadoop 平台和一个四台机器的 Hadoop 集群,作为我们的实验环境,进行代码可行性测试。结果如下:

表2 阿里云软件环境Table 2 Aliyun Software Environment

表3 阿里云硬件环境Table 3 Aliyun Hardware Environment

表4 虚拟机软件环境Table 4 Virtual Machine Software Environment

表5 虚拟机硬件环境Table 5 Virtual Machine Hardware Environment
· 测试环境
· 测试结果
· 提交作业:
我们以向集群提交一个 wordcount 作业为例。预先将需要进行 wordcount 计算的文件上传至集群的hdfs 上,再在本地虚拟机的 sce 客户端,通过 bsub指令将代码 jar 包、输入路径、输出路径等提交至集群,等待计算结果。

· 查询作业信息:
我们向集群提交了多个作业,在本地 sce 客户端通过 bjobs 指令查询作业信息。

· 获取静态/动态队列状态:
以 capacity scheduler 队列配置为例,在Hadoop平台上配置了多个队列。在本地 sce 客户端通过bqueues指令进行获取队列信息。

· 终止作业:
运行一个长作业,中途发送指令终止它。
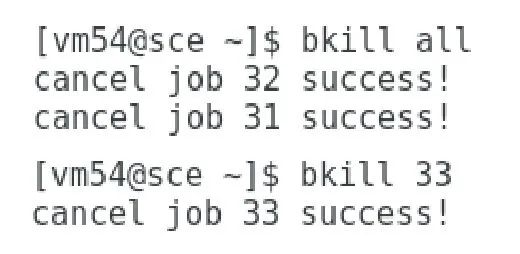
由测试结果可以看出,所编写的接口程序可以将YARN 平台接入并且正常的对其进行提交作业、终止作业、查询信息等基本操作。
3 结语
目前,基于 SCE 的大数据平台 YARN 接口尚未正式投入大范围的使用。不过,在小范围的单机与集群测试中,接口程序良好的实现了提交作业、终止作业、查询作业、查询队列信息的功能。
本文介绍了传统超算集群管理系统与大数据资源管理器的区别,并以 SLURM 和 YARN 为例进行对比,详细说明了他们的区别。基于这些不同点,编写了新的应用于 YARN 的服务层接口程序,在屏蔽了差异性的同时,实现了大数据资源管理器 YARN 的接入。
