基于深度学习的高分遥感影像乡镇建筑物识别方法
2019-10-11王利忠张宏海
王利忠,张宏海,仲 波,牛 铁
1.中国科学院计算机网络信息中心,北京 100190
2.中国科学院大学,北京 100049
3.中国科学院遥感与数字地球研究所,北京 100094
引言
近年来,随着科技的发展,人们可以越来越方便地获得高分辨率卫星图像,并将其应用到导航、城市环境、农业检测、防灾等领域,为我们的生活带来更多便利和保障。随着高分辨率光学卫星的增多,不同层次、不同角度、多时段的观测为我们带来了极为丰富的数据集,这些数据集分辨率高,覆盖范围大,采集时间较短,成本相对较低,且受气象条件影响较小,使得基于此的研究和应用成为当前的热点之一。
我国有面积广泛的乡镇地区,对于乡镇建筑物的识别,可以有效地分析出乡镇的密集程度和用地分配,从而为国家的农村发展规划及相关政策制定提供参考。特别是在当前扶贫攻坚阶段,这些信息在指导乡镇发展有很大的作用。
乡镇建筑的卫星图像相较于城市建筑在特征上有很大不同,乡镇的建筑物较为低矮,种类较多,目标大小不一,小目标占多数,容易受到高大物体的遮挡,也容易受到田垄、树木、道路等的干扰。
传统的目标识别主要是利用图像的一些底层特征,包括颜色特征、纹理特征、几何形状特征等。颜色特征是利用不同目标颜色上的不同来处理,如用颜色直方图[1]来描述颜色分布,颜色矩[2]来统计颜色分量等等。但是不同目标可能含有相同颜色,相同目标在不同阶段又可能有不同颜色,仅仅凭借颜色来进行识别,成功率并不理想。纹理特征描述的是图像的局部灰度分布情况,在此基础上有灰度共生矩阵[3]、Haar 特征[4]、HOG[5]等方法来进行处理。几何特征则主要利用不同目标的轮廓、边缘、面积等来进行识别。高分辨率遥感卫星图像分辨率高,提供的信息较为丰富,容易受到阴影影响,使用传统方法效果并不理想。
另一种重要的研究方法是采用机器学习的方法来提取图像特征,如 PCA、LDA 以及能适用于非线性结构的 SVM 等,但这些方法应用场景单一,很难做大规模推广。此外还有基于样本问题的张量流形学习方法。张量流形学习直接处理张量形式的数据并保持数据的空间特征,但目前在目标识别中的成果较少。
近年来,深度学习在多个领域都取得了非常好的表现,如图像分类、目标识别、语音识别、文本检测等。在计算机视觉方面,1998年Letun[6]等人提出了卷积神经网络,其中体现的局部感知、参数共享等思想为后来深度学习的发展带来的极大的启发。2012年,深度神经网络 Alexnet[7]在ImageNet 竞赛中一鸣惊人。此后深度学习在计算机视觉领域的发展越来越迅速。2013年,纽约大学提出 OverFeat[8]模型,这是最早将深度学习应用于目标检测的模型之一。之后,加州伯克利的科学家提出了 R-CNN[9]模型,在物体识别挑战中获得 50% 的效果提升。该方法的主要思想是:利用候选区域方法 (论文中采用 Selective Search 方法) 提取可能的物体,然后使用CNN从每一个区域提取特征,最后使用 SVM 分类每一个区域。不久之后,R-CNN 的改进版本 Fast R-CNN 提出,它仍然使用 Selective Search 方法提取候选区域,但与R-CNN 不同,它在完整的图片上使用 CNN,然后使用集中了特征映射的兴趣区域以及前向传播网络进行分类和回归,这个方法使训练速度大大提高,但是对候选区域算法的依赖成为它继续发展的瓶颈。紧接着,RCNN 的第三代 Faster-RCNN[10]被提出,它试图取消对 Selective Search 的依赖,并实现了完全的端到端的训练。之后,何凯明等研究人员在原有的 Faster R-CNN 模型上添加一个分支,使用现有的检测方法对目标进行并行预测,称为 Mask RNN[11],它既容易实现和训练,也可以方便地应用到其他领域。
基于深度学习在目标识别领域的优势和前面提到的建筑物识别的问题,本文采用基于深度学习的方法进行乡镇建筑物目标识别,采用在TensorFlow 平台上搭建的Faster-RCNN模型进行训练和测试。
1 方法
本文设计的基于深度学习的乡镇建筑物识别的方法是建立在Faster-RCNN 模型的基础上。Faster-RCNN 神经网络是在RCNN、Fast-RCNN 神经网络的基础上优化而来,它实现了快速、精确的图像目标检测,其基本结构如图1所示。
1.1 卷积神经网络
卷积神经网络是由卷积层、池化层、全连接层等结构组合而成的具有深度结构的神经网络,它采用共享参数和局部感受野的思想,在保证神经网络学习能力的基础上极大地减少参数规模,在计算机视觉、自然语言处理等领域迅速发展,并取得了良好的表现。
Faster-RCNN 的结构中采用卷积神经网络来提取图像特征,生成输入图像对应的特征图并作为后续网络结构的输入。模型采用的卷积神经网络是 VGG16模型,它的输入是 224*224*3 的图片,经过 13 个卷积 +ReLU 层,5 个最大池化层,3 个全连接层,最后得到 51*39*256 维特征。卷积神经网络得到的图像特征后续用来选取 proposal,而它此时的坐标依然可以映射回原图。
每个卷积层都是利用前面的网络信息来进行处理,从而得到图片的更深层次的特征,一般学习图像的边缘、纹理、复杂形状等特征,最终的卷积特征图空间维度上比原图大大缩减,也便于后面的网络结构对其进行分类或回归。
1.2 区域推荐网络 (Region Proposal Networks)
在Faster-RCNN 模型训练时,图像在经过前面的卷积神经网络多个卷积层、池化层、激活函数(ReLU) 和全连接层之后,得到输入图像对应的特征图。然后使用 RPN(Region Proposal Networks) 来生成检测框。在RPN 中,使用 9 种大小和尺寸固定的候选框 (称为 Anchor) 在特征图左右上下移动,最终对每一张图片都生成约 20000 个左右的 anchor。接下来 RPN 就从这 20000 个候选框选择 256 个进行分类和回归。具体来讲,首先对每个标记框 (训练之前人工标记),选择和它重合度最高的候选框作为正样本。对于剩下的候选框,再选择和任意标记框重合度超过 0.7 的候选框作为正样本。然后随机选取和标记框重合度小于 0.3 的候选框为负样本 (其中正样本总数不超过 128,正负样本总数为 256)。计算分类损失和回归损失。RPN 在自身训练的同时还会给后面的RoIHead 模块提供感兴趣区域 (RoI),并利用回归得到的位置参数修正 RoI 的位置,最终选出 2000 个左右的 RoI。在RPN 之后是 RoIHead,它在RPN 给出的约 2000 个的 RoI 上继续进行分类和位置参数的回归。在Faster-RCNN 模型的测试阶段,网络对所有的RoI 计算概率,并利用位置参数调整其位置,最终生成对图片的目标的位置预测和概率。
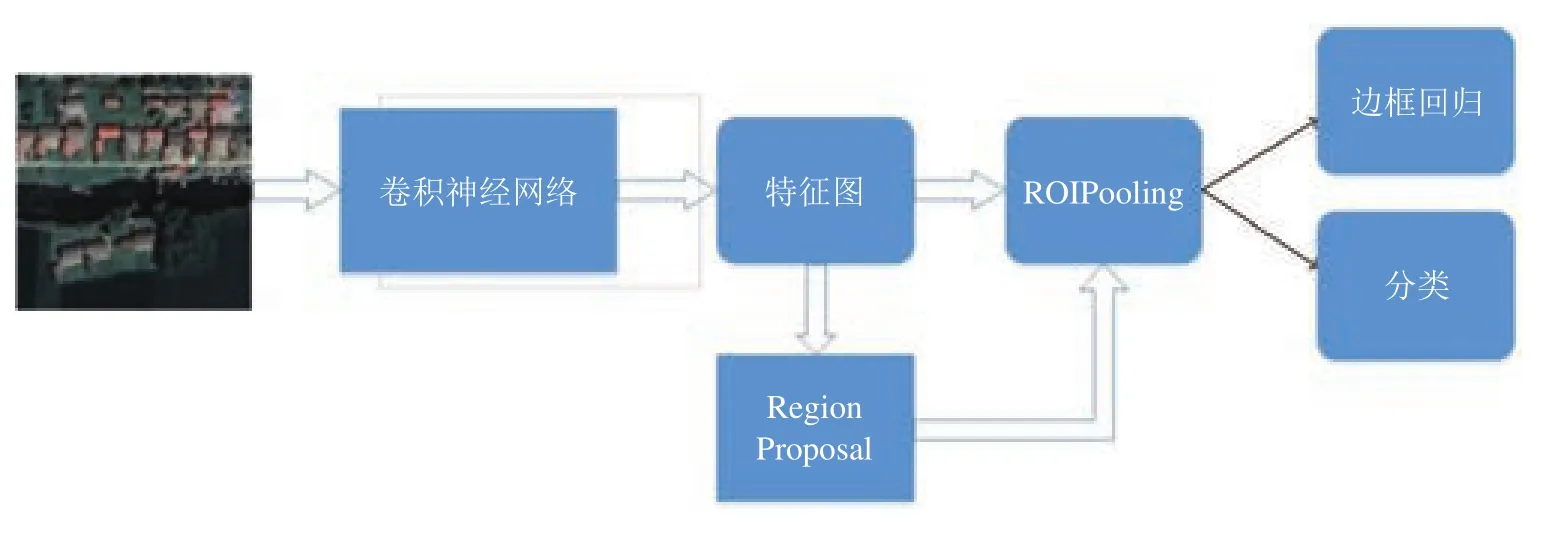
图1 Faster-RCNN 神经网络Fig.1 Faster-RCNN neural networks
2 数据集
2.1 数据集简介
本文所使用的数据集是截取自 Google 地图上河南某地区乡镇卫星图,该数据集中的图像都是高分辨率的 RGB 图像,大小均为 256*256,分辨率为 18级,即 0.6 米分辨率。
2.2 数据集过滤
从谷歌地图下载的地区整体图片大约有 40000 多张,其中有大量的无目标图片,如图2所示。
在生成数据集之前需要先进行初步过滤,过滤步骤如图3所示。
本文中使用 opencv 中轮廓检测的方法,提取图片中的轮廓并识别其中的矩形轮廓,并根据矩形轮廓的面积和个数进行过滤。当然,这只是初步过滤,阈值不宜设置地太严格。在上面的流程过滤完后再进行人工辅助过滤,但这时数据量已经大大减少。在最后的数据集中,我们总共有 1730 张图片,我们选取其中 1000 张图片作为训练集,其余的 730 张图作为测试集。由于模型的输入是 224*224*3 大小的图像,我们将得到的数据集等比例缩放到 224*224*3。
2.3 数据集特征分析
从高分辨率卫星图像中识别建筑物一直是科研工作者研究的热点之一,因为识别的结果在人口预测、发展规划、导航、防灾等方面都有重要的应用价值。本文主要从以下方面来解决乡镇建筑物识别的问题。

图2 无目标图片Fig.2 No target picture
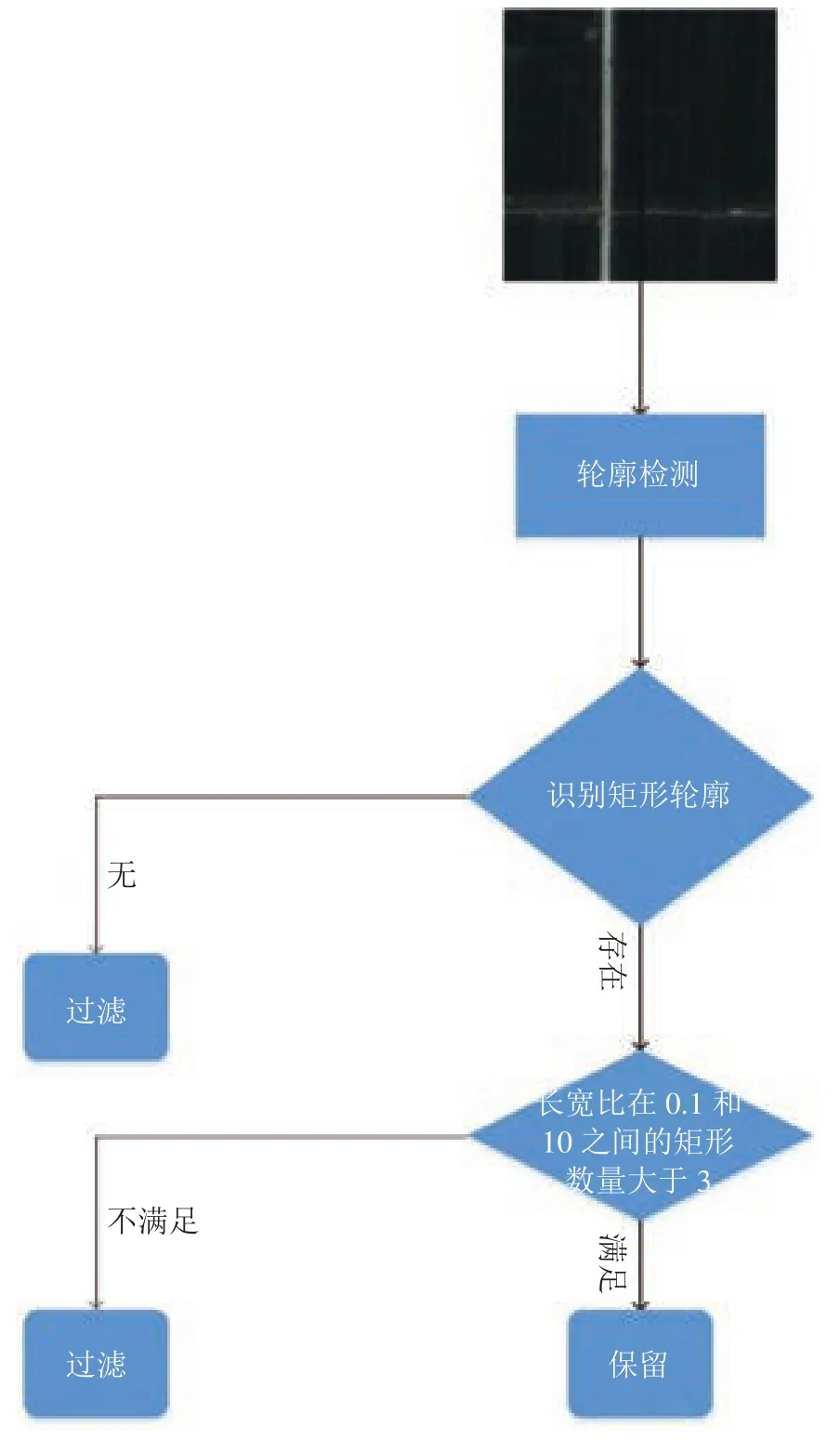
图3 数据集过滤流程图Fig.3 Data set filtering flowchart
首先,乡镇建筑物有不同的种类。乡镇建筑物在大小和外形方面各有不同,而且也有因为卫星拍摄时间的不同导致的建筑物阴影上的差异。在大小方面,乡镇建筑物中既有面积较小以户为单位出现的住宅,也有面积中大型的工厂房。在阴影方面,阴影是建筑物目标一个很重要的特征,而卫星拍摄时间的不同会造成建筑物阴影上的差异。在正午拍摄的图像目标阴影较小,而在早晨或者傍晚拍摄的图像目标阴影较大。本文中我们针对建筑物的以上特征,做了具体的分类探索,首先我们尝试将建筑物以功能为单位 (如乡镇住宅就以户为单位标注) 划分为一类,背景分为一类。这种情况下的识别效果并不尽如人意。之后我们尝试以屋顶为单位将建筑物划分为一类,背景为一类。这种情况下建筑物的识别受到树木、田垄、道路等的干扰较大。最后我们根据建筑物大小和阴影将建筑物分为四类:阴影小的乡镇住宅以户为单位标注为house 类,阴影较小的独立出现的大型工厂房以屋顶为单位标注为 big 类,非正午时分拍摄阴影较大的乡镇住宅以户为单位标注为 shadow 类,非正午时分拍摄阴影较大的大型工厂房标注为 big_shadow 类,其余为背景。在这种分类策略下,模型的目标识别取得了较好的效果。
另一方面,高清卫星图像由于分辨率较高,所以在建筑物识别中容易受到其他物体的干扰。在乡镇建筑物的识别过程中,最容易受到树木、田垄、道路等的影响。树木特别是高大树木,阴影较大,这和 shadow 类建筑物的特征相似。田垄和道路 (特别是道路拐角处) 具有较为规整的轮廓,也较为容易产生干扰。本文在标记建筑物时尽量多地将其特征包含其中,例如以户为单位进行标注可以借助建筑整体建构来使其与干扰物体区别开来,还有尽可能地将建筑物产生的阴影包括其中,这些措施进一步降低非目标物体的干扰。
2.4 数据标注
按照特征分析所述将图像分为4类:house、big、shadow、big_shadow,如下图1所示:图4 (a) 中的建筑物主要是阴影较小的以户为单位的住宅,图4 (b)中的建筑物主要是阴影较小的独立的大型工厂房,图4 (c) 中的建筑物主要是阴影较大的以户为单位的住宅,图4 (d) 中的建筑物则有阴影较大的独立工厂房。而很多情况下是同一张图片中有不止一个类,分类时按照阴影和功能 (住宅和工厂房) 各自标注。
数据集标注分类按照前面所述进行,图像标记完成以后,每一张图片的标记信息都是用一个 xml 文件保存,本文采用正则表达式匹配的方法将其整理到一个文件 (gt.txt) 中,其中每一行的格式如下:
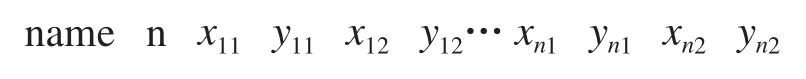
其中 name 是图片的名字 (不带后缀),n 代表该图片中标记框的数量,后面的参数表示图片中所有标记框的位置 (四个坐标代表一个标记框)。
在图像标记过程中,容易出现目标不完整的情况,也就是识别目标的一部分出现在一张图像的边缘位置。在标记过程中视不完整目标的面积而定,如果目标有超过 50% 在图片中,就将其标记,否则就不对其进行标记。这样也避免了同一目标在不同图像中的重复识别。
2.4 数据增强
在深度学习网络的训练中,需要大量的人工标记数据。为了解决这个问题,需要进行数据增强,常用的方法包括裁剪、翻转、颜色亮度变化等。本文在网络训练中使用水平翻转使训练集数量扩充一倍,达到2000 张。

图4 建筑物图像分类Fig.4 Building image classification
3 实验研究及分析
3.1 实验
实验采用深度学习框架 TensorFlow 实现,实验是在基于 CentOS 操作系统、12G 内存的 NVIDIA显卡的服务器环境运行。设置迭代 20000 次。通过TensorFlow-GPU 框架进行相关操作实现,并在服务器上多次运行。
3.2 评价指标
为了定量评价该方法的性能,本文采用的评价标准是准确率 (Accuracy)[12],用来评价模型对建筑物目标的识别能力。分类结果混淆矩阵,见表1。
TP (真正例) 是将正类预测为正类的数量;TN (真负例) 是将负类预测为负类的数量;FP (假正例) 是将负类预测为正类的数量;FN (假负例) 是将正类预测为负类的数量。对应到本实验中,预测结果只有正类,即所有的建筑物目标 (建筑物目标在训练模型时分类,在统计预测结果时不分类)。记图片中实际的建筑物目标数量为 N,TP 表示预测类别为建筑物 (四种中任意一种) 且在实际中也是建筑物的预测框数量,FP 表示预测类别为建筑物 (同上) 但实际中不是建筑物的预测框。准确率的计算公式分别如下:

3.3 识别结果
最终的训练结果得到的测试准确率可达到93.06%,其中的一些图像的识别效果如图5 所展示。从识别效果来看,本文的方法在建筑物识别任务中达到了较好的准确率,能够有效地将不同类型的乡镇建筑物提取出来,且有效地避免了非目标物体 (如树木、道路) 等的干扰。

表1 分类结果混淆矩阵Table 1 Classification result confusion matrix
3.4 实验对比
为了验证本文方法的性能,我们还做了两组对比实验:第一组实验中采用传统图形学的方法,先将图像进行形态学开闭运算和前景提取将图像前景和背景分开,然后用分水岭算法将建筑物区域从原图像中分割出来,再用轮廓检测的方法将建筑物轮廓提取出来。第二组实验选用的方法也是基于深度学习,其模型用的同样是本文中 Faster-RCNN 模型,只是在数据集标记时采取的策略与本文中所述策略不同,而是将建筑物按屋顶进行标记,统一标记为一类building,其余的为背景。这三个实验的准确率如表2所示:

图5 模型识别效果Fig.5 Model recoghition effect

表2 三个实验的准确率Table 2 Accuracy of three experiments
从结果上来看,基于深度学习的建筑物提取方法的准确率明显比传统方法高很多。另一方面,本文在基于数据集特征分析的基础上提出的多分类标注策略也比统一将目标标注为一类的标记策略能更有效地提取到建筑物目标。
4 结论
本文的基于深度学习的乡镇建筑物识别方法,采用多分类的标注方式,通过使用深度学习框架TensorFlow-GPU 搭建 Faster-RCNN 网络模型,并在自己构建的数据集上进行有监督学习,从而预测出建筑物目标范围。最终实验结果表明本方法取得了较好的准确率,能够有效地识别不同种类的乡镇建筑物目标,同时可以有效地克服由阴影、树木、田垄、道路等带来的干扰。
本文的方法仍存在一些不足,实验过程中发现分割建筑物时,有部分建筑物的轮廓提取不完整,也仍然有部分纹理特征类似建筑物的道路、田垄等非目标物体造成的干扰,这些问题可作为今后研究的重点。
