基于深度学习的肺结节识别
2019-10-11高智勇万昕
高智勇,万昕
(中南民族大学 生物医学工程学院,武汉 430074)
在雾霾、PM2.5等各种现代污染物的影响下,全世界的肺癌患者数量激增[1],肺癌作为常见的和致死率非常高的癌症之一,其病灶体称为肺结节,是早期病征的标志之一,若能及时识别出肺结节,即可早期检测肺癌,颇受研究者关注[2].目前较多医疗系统采用人工识别肺结节,但体积很小和特殊部位的肺结节在检查结果图上与血管较为相似,仅凭经验对其进行诊断,易出现漏诊或误诊[3].一个病例可能有一百多张CT切片图,数据量庞大.因此,对肺结节的检查尤其需要提高诊断准确率,而自动高效的识别肺结节显得尤为重要.
临床上多层螺旋CT是检测肺结节最有效的方法之一[4],但人工阅片约有26%的结节被遗漏[5].肺结节识别的准确度对诊断有较大的影响,因而研究者致力于学习更有效的识别方法.结合深度学习的肺结节识别是研究热点之一.中科院联合南佛罗里达大学的学者使用多层卷积神经网络(Multi-scale Convolution Neural Network),从原始图像的结节斑块中提取特征,将不同尺度输入获得的特征结合起来,获得了86.84%的识别准确率[6].MONKAM P等[7]使用35000多个样本,提高交叉训练的复杂度,达到了88.28%的准确度.上海交通大学的孟以爽等[8]通过预处理方法,分割出肺结节感兴趣区域,叠加一个序列中同一区域相邻的三层,用22000张伪彩色样本块训练网络105次,获得了95%的准确度[8].然而,这些研究复杂的预处理方法使系统缺乏应用的灵活性,如何用较少层的网络结构,建立针对少量样本数据进行肺结节识别的模型是一个关键问题,本文对此展开了研究.
1 本文方法
1.1 问题与分析
迁移学习是将已经训练好的模型参数迁移到新的模型中,帮助新模型训练的方法.肺结节的识别可用的标准样本数较少,故本文采用迁移学习法来训练模型,提高学习效率.
针对肺结节识别,可通过调整网络结构,增加方法的实用性.本文提出三分支型结构的DAG3模型,在不同分支使用C-B-R层的组合代替C-R-C-R-P层的组合加快训练过程.整体深度相似的条件下,DAG3较直线型网络结构DConv(6)具有更强的学习能力.实验对比了多种模型迁移训练得到的结果,优化自主设计的网络结构,较大程度提高了准确率(网络结构见图1).
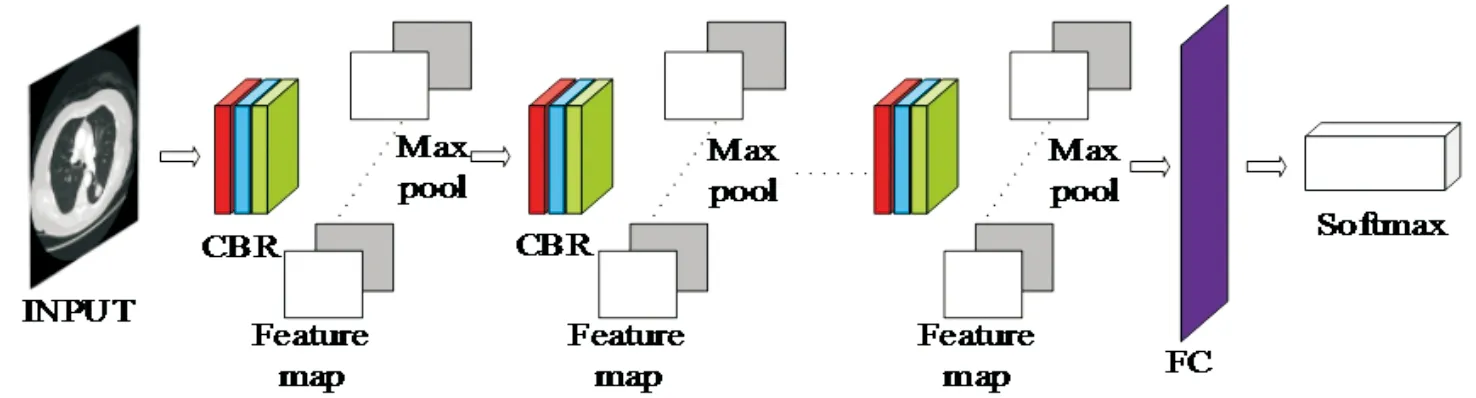
图1 DAG3网络结构
1.2 网络结构设计
由于个体差异,不同个体的肺部CT图像特征差别较大.通常实验仅针对图像中的肺实质部分,在神经网络训练前,进行预处理,自动或人工提取出肺实质,减少肺部轮廓对识别结果的影响.为更好地利用深度学习网络的强大性能优势,减少识别流程的复杂性,实验中未对原始图像进行预处理,保留更多原始信息,令识别过程更加智能化.
实验数据集均为299×299的图片,训练过程直接采用原始数据作为输入.网络卷积层全部采用3*3大小的卷积核,卷积结果保持原始输入尺寸,其输入输出计算公式如下:
(1)
式(1)中:W2为输入数据的长;H2为输入数据的宽;K为输入数据的深度;W2为输出数据的长;H2为输出数据的宽;D2为输出数据的深度;卷积核的大小为F,步长为S,填充为P.
网络基本结构采用Conv-BN-Relu的组合,BN层有防止梯度弥散的功能,同时也能加快训练过程.Relu层增加了网络各层之间的非线性关系,Relu令一部分神经元的输出为0,使网络具有稀疏性,减弱参数间的依赖性,防止过拟合的发生.其激活函数表达式如下:
(2)
实验设计了具有6层卷积深度的DConv(6)网络结构,网络整体结构为直线型类VGG结构,每个Conv-BN-Relu组合单元后的降采样采用Maxpool,能减小卷积层参数误差造成估计均值的偏移对特征提取造成的误差[9],其整体结构如图2.
为了保证其学习能力的同时,降低DConv(6)直线型类结构的深度,本文对其进行改进,采用类Inception的结构,增加DAG3结构的网络宽度(结构如图1所示).临床上通常根据肺结节的密度不同将其分为3类:实性结节、部分实性结节和磨玻璃密度结节,根据图像中直径大小的差别,分为高危、中危和低危三类.实验所用数据未将正样本进行详细分类,为让网络能更准确地识别临床常见的三类结节,同时避免参数过多,硬件资源耗费过大,DAG3网络模型采用了三分支结构.分支结构前使用5*5和3*3的卷积核对原始数据进行学习,三个分支结构均采用3*3 的卷积核拓展网络宽度.分支叠加后的降采样采用Avgpool, 能减小邻域大小受限造成的估计值方差增大对特征提取造成的误差[10].研究表明,类Inception的分支型网络结构增加了网络的宽度,能在减少参数的同时,增强网络学习能力[11].实验对Inception结构做出调整,以适应本实验数据特点.每个Conv-BN-Relu组合单元后的降采样均采用2*2的Maxpool.
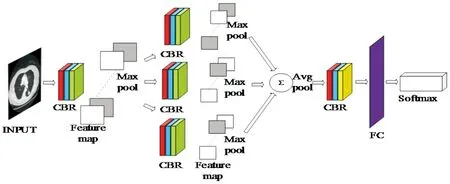
图2 DConv(6)网络结构
2 结果与分析
迁移学习所用到的预训练模型均在ImageNet数据库上完成了预训练,ImageNet是目前世界上图像识别最大的数据库,由美国斯坦福大学建立.其中有超过1400万的图像数据被手动注释,至少一百万个图像中包含有边界框,拥有2万多个类别.模型的参数由Matlab扩展包提供.实验采用LIDC-IDRI数据集的数据,包含805张包含肺结节正样本图像,795张不包含肺结节的负样本图像,直接使用原始数据进行训练.训练过程可视化处理,5个Epoch内Loss的变化在在±0.01范围时训练均被认为已收敛[12].训练使用具有动量的随机梯度下降法SGDM(Stochastic Gradient Descent with Momentum),以减少收敛过程中的震荡.SGDM的参数更新公式如下:
θl+1=θl-αE(θl)+γ(θl-θl-1),
(3)
式(3)中:θ为参数向量;l为迭代次数;α为学习率;E(θ)为loss函数;γ为动量.
直接型结构的Dconv(6)网络共有30层,分支型DAG3网络共有39层.迁移学习的预训练使用了5个模型,Alexnet共有25层,VGG16共有41层,Googlenet共有144层,Inceptionv3共有316层,Resnet101共有347层.训练学习率为0.0001,动量为0.9,批大小为100.由于部分预训练网络层数较深,实验中依据迁移训练过程中的微调(Fine-Tune)原理,对实际参与训练的层数进行调整,具体使用层数见表1.

表1 不同网络识别结果
由表1可知:(1)对直接型网络Dconv(6)改进后,分支结构的DAG3模型获得了更高的准确率;(2)与预训练模型相比,DAG3模型使用较少的层数获得了较高的准确率,增强了方法的适用性;(3)Resnet101模型使用了残差块,具有很强的学习能力,但结构复杂,层数很深,训练要消耗大量硬件资源,耗时较久.DAG3模型仅有39层,与使用了268层网络参与训练的Resnet101模型的识别准确率仅相差1.04%.针对本实验所用的小样本,DAG3模型实现了使用更少的层数和参数,达到较高的识别准确率的目标.
本实验结果与其他实验对比如表2所示.实验数据集包含1600个样本,不到其他方法样本数量的1/10,识别率较高.而孟以爽等使用的方法首先采用预处理方法,将分割出的肺结节块作为训练数据,预处理过程复杂,人为因素等随机影响使系统鲁棒性较差.在样本数量较小,没有对输入图像进行预处理的条件下,DAG3模型对肺结节识别达到了较高的准确率.

表2 本文方法与其他方法对比
3 结语
本文针对肺部CT图像的病灶肺结节识别问题,在样本数量较小情况下,引入迁移训练方法,提高了学习效率.同时结合网络结构特征,采用分支网络结构,减少网络层数和参数,节约硬件资源,缩短训练时间.在LIDC-IDRI数据集上进行的实验结果表明:运用迁移训练能在新问题上取得较好的结果,实现了对肺结节的高准确率识别.与其他方法相比,在未进行图像预处理的情况下,本方法在降低网络结构的同时,获得了较好的识别效果.若加入鲁棒性较好的预处理过程,设计更有效的网络结构,预期会取得更高的识别准确率,有待更深入的研究.
