基于卷积门控循环单元网络的储层参数预测方法
2019-10-08李谋杰王浩懿
宋 辉 ,陈 伟 ,3,李谋杰 ,3,王浩懿
(1.油气资源与勘探技术教育部重点实验室长江大学,湖北武汉430100;2.长江大学地球物理与石油资源学院,
湖北武汉430100;3.非常规油气湖北省协同创新中心长江大学,湖北武汉430100;4.太原理工大学材料科学与工程学院,山西太原030024)
储层参数通常由测井资料确定,传统的测井资料解释基于储层均质性假设建立测井解释方程,难以摆脱线性方程的束缚。随着非常规油气成为目前勘探开发的主体,储层预测的目标介质发生了很大变化,具有明显的非均质、各向异性特征[1],常规测井储层预测技术难以满足勘探领域的要求。如今发展的机器学习技术可以很好地解决测井解释中的非线性映射问题[2]。
用于储层预测的机器学习算法主要有支持向量机[3-8]、随机森林[9]、极端梯度提升[10]和人工神经网络[11-16]等。深度学习是机器学习的一个分支,其概念源于对人工神经网络的研究。相对于传统的浅层学习,深度学习通过构建具有很多隐层的机器模型结构,实现复杂函数逼近和逐层特征变换,从而提升预测或分类的准确性。目前深度学习已广泛应用于计算机视觉、自然语言处理、语音识别等领域。
深度学习包括很多流行的模型,如卷积神经网络(CNN)和循环神经网络(RNN)。段友祥等借鉴CNN在图像处理上的应用,在卷积模型中将测井参数调整为二维数据,更好地提取了储层特征[17]。林年添等将CNN应用于地震储层预测,取得较好的预测结果[18-19]。无论是CNN,还是全连接神经网络(DNN),其前提假设均为:前一个输入和后一个输入是完全没有关系的。但是,某些任务需要能够更好地处理序列的信息,即有些场景输入的数据与后面输入的数据是有关系的,或者说后面的数据跟前面的数据是有关联的。而长短期记忆网络(LSTM)与门控循环单元网络(GRU)能够考虑历史输入对当前输入的影响,因此非常适合处理序列数据。张东晓等将LSTM应用于测井曲线生成,该方法准确性高且成本低[20]。安鹏等将其应用于孔隙度与泥质含量预测,取得了比DNN更优的结果[21]。
以上研究结果表明,基于深度学习的储层预测比传统方法有更好的预测结果。储层预测实质上属于序列预测问题,因此在测井数据提取特征中,既要考虑不同特征参数之间空间上的联系,还要考虑测井参数随深度的变化。为此,提出将CNN与GRU相结合,选取对孔隙度较为敏感的声波、密度、补偿中子、自然伽马4种测井参数作为模型输入,从而进行孔隙度预测。同时为证明该模型对于孔隙度预测的有效性,利用CNN-GRU模型对某井区A井未知深度的孔隙度进行预测,并与CNN和GRU模型预测的结果进行比较,证实CNN-GRU模型的有效性。
1 深度学习理论
CNN与RNN是深度学习的2种特性不同的模型。CNN具有参数共享、稀疏连接的特性,因此擅长提取数据的空间特征。RNN具有记忆的特性,能以很高的效率处理序列数据任务。在某些情况下,一个任务的完成需要多种模型共同发挥作用,CNN与RNN有时也结合使用[22]。但RNN存在着梯度消失的问题,难以记忆长距离的信息。门控算法是RNN应对梯度消失的重要方法,而GRU是门控算法的代表。因此,本次基于CNN与GRU进行孔隙度预测。
1.1 卷积神经网络
CNN是一种特殊的网络结构,在计算机视觉领域广泛应用。CNN包含卷积层与池化层2种特殊的提取结构。卷积层能够提取前一层的特征并得到特征图,由于每个特征图的神经元能够共享权重参数,减少了网络各层的连接,同时也降低了过拟合的风险;池化层也称为下采样,可以看作一种特殊的卷积过程,主要用于特征降维、压缩数据以及减少参数的数量。
卷积是CNN中非常重要的操作,不同维度的卷积可以解决不同的问题。用一维卷积处理测井资料,提取的是测井参数在邻近时间步长上的变化;用二维卷积处理测井资料,可以用于提取不同测井参数之间的关系。研究使用二维卷积提取不同测井参数之间的关系,其处理步骤包括:①借用图像识别的处理,将测井资料表征为时间步长×特征参数的矩阵。②用二维卷积提取特征。选用的特征参数包括声波、密度、补偿中子和自然伽马,其原理如图1所示,卷积核长度为1×4,点乘表1中每一行的值,从上到下依次进行,如果输入的时间步长为5,则5×4个数据经过这一层卷积后被压缩为5个数据,如果需要保持原来尺寸,则需要通过填充0操作。
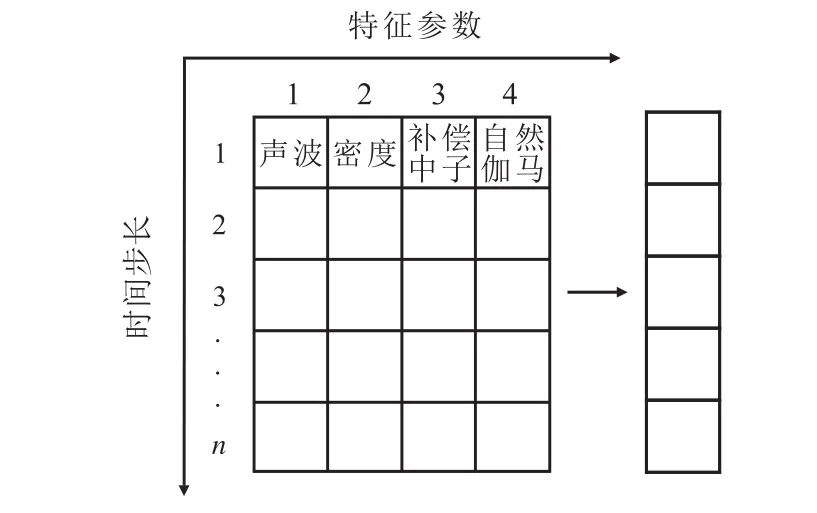
图1 二维卷积提取测井数据不同特征参数示意Fig.1 Schematic of different characteristic parameters extraction of logging data by twodimensional convolution
1.2 门控循环单元网络
RNN是当前深度学习热潮中最重要的技术之一。一个典型的RNN结构包括输入层、隐藏层和输出层。由图2可知,RNN的特殊之处在于隐藏层为循环体结构,也就是说RNN每一时刻都在执行同样的操作,只不过是输入数据不同而已。该结构使得RNN当前时刻的计算会结合历史的输入信息,有助于处理序列相关的任务。但RNN只能记忆短期的历史输入信息,无法有效解决长期记忆的问题。
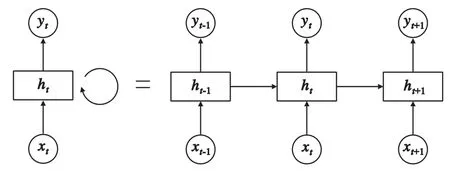
图2 RNN模型Fig.2 Schematic of RNN model
为克服长期记忆问题,提出LSTM[23]。LSTM的核心思想在于细胞状态和各种门结构。细胞状态携带网络不同时刻的记忆信息,而输入门、遗忘门和输出门能够控制细胞状态遗忘或记忆某些信息。GRU是LSTM的一种非常流行的变体,在很多任务中能够达到与LSTM相当的表现,同时具有更简洁的模型结构,减少模型训练的参数,增强模型防止过拟合的能力,并且提高模型的收敛速度。GRU对LSTM做了2个大的改动:①将单元状态与输出合并为隐藏状态,依靠隐藏状态来传输信息。②将输入门、遗忘门和输出门更改为更新门和重置门。
GRU模型隐藏层结构包含更新门激活向量(zt)、重置门激活向量(rt)、候选状态向量(h͂t)、隐藏状态向量(ht)及上一时刻的隐藏状态向量(ht-1)(图3)。
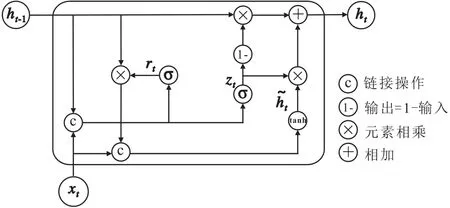
图3 GRU模型隐藏层结构Fig.3 Hidden layer structure of GRU model
更新门同时决定着丢弃旧信息的内容和添加新信息的内容,其表达式为:
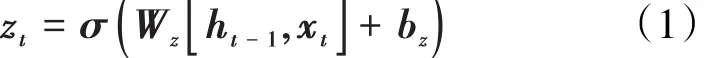
重置门决定着忘记历史信息的程度,其表达式为:
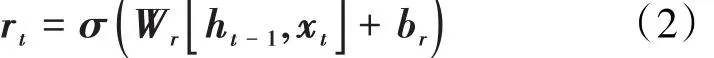
候选状态主要是包含当前时刻输入的信息,相当于记忆了当前时刻的状态,其表达式为:
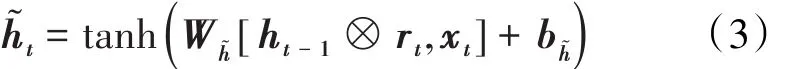
隐藏状态决定当前时刻需要输出的信息,其表达式为:
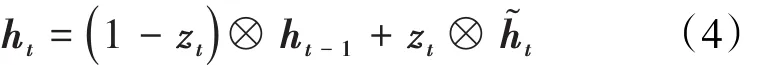
2 模型构建
CNN与GRU模型是深度学习非常流行的算法,具有不同的特性。CNN模型具有局部感知的特性,而GRU模型具有长期记忆的功能,更适合解决时序问题。为此,将CNN与GRU相结合,设计CNNGRU模型进行孔隙度预测,该模型具有表达数据时空特征的能力,模型预测框架如图4所示。在数据输送到网络模型之前,首先需要对数据进行预处理,即划分数据集与数据归一化,然后将预处理后的数据输送到网络模型中进行训练及测试。另外,CNN-GRU模型隐藏层由单层CNN与GRU构成。在CNN层设置8个1×4的卷积核,在GRU层设置4个神经单元。同时,考虑到如果时间步长太短,模型可以利用的信息太少会影响预测精度,而时间步长太长,则会增加模型计算的负担,因此,在本次实验中,将时间步长设置为6。选择TensorFlow框架来实现模型,TensorFlow具备高质量的元框架,如Keras,Keras作为TensorFlow的高级应用程序编程接口,封装了很多TensorFlow的代码,使得代码模块化,非常简便,但缺少灵活性。因此,本次模型建模部分主要由Keras完成,其余部分由TensorFlow完成,充分利用两者的优势。
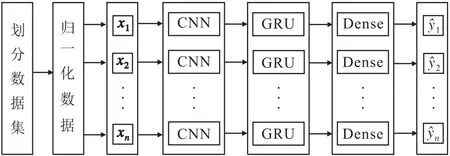
图4 CNN-GRU模型预测框架Fig.4 Prediction framework of CNN-GRU model
为避免模型出现过拟合现象,提高模型的泛化能力,在损失函数中加入L2正则化项。最终将模型损失函数定义为:
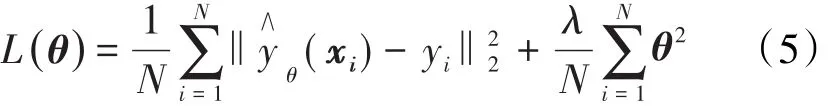
模型使用RMSProp优化器来更新网络参数,以最小化损失函数,其表达式更新为:
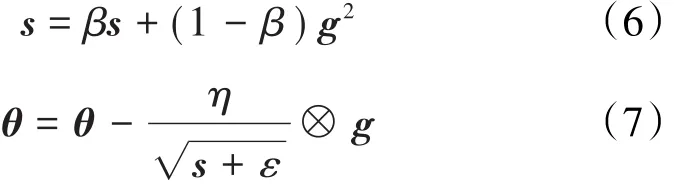
学习率是深度学习中一个非常重要的超参数。学习率太大,网络无法收敛到全局最小值,而是在全局最小值附近“徘徊”;学习率太小,网络收敛需要极长的时间。因此,调整好学习率是训练出好模型的关键要素之一。设置变学习率训练方法为:
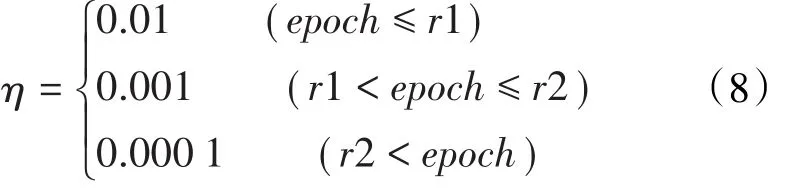
(8)式中,r1与r2将训练阶段分为训练前期、训练中期和训练后期。(8)式表明训练前期使用较大的学习率以加速网络收敛,然后以较小的学习率过渡到训练后期,最后设置更小的学习率,以保证训练的稳定性。
3 实例与分析
为证明所设计模型的有效性,利用某井区的A井数据进行验证。在A井中选择井深为6 650~6 813 m的1 080组测井数据作为训练集,井深为6 813~6 868 m的360组测井数据作为测试集。训练集是为了训练网络参数,而测试集则用来测验模型的性能。为加速训练及提高模型预测的精度,对数据进行归一化处理,归一化公式为:
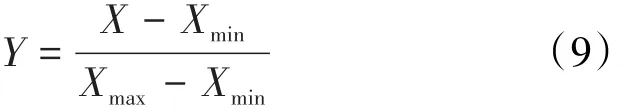
经过多次实验,将CNN-GRU模型中r1,r2分别设置为50,200;将CNN模型中r1,r2分别设置为100,400;将GRU模型中r1,r2分别设置为100,500。为检验3种模型的预测效果,将训练好的模型分别在测试集上进行测试。
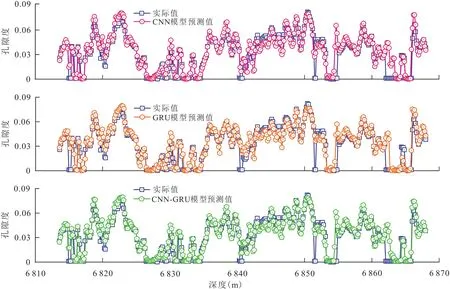
图5 3种深度学习模型孔隙度预测结果Fig.5 Porosity prediction results based on three different deep learning models
从图5可以看出,3种深度学习模型均实现了很好的预测结果,证明深度学习能有效地提取测井数据之间的非线性化特征,为储层预测提供了一种有效的新技术。为评价3种模型性能,采用均方差和相关系数(R)作为评价标准(表1)。从表1可知,CNN-GRU模型对均方差和相关系数的预测结果比单一的GRU模型和CNN模型更优,这说明充分利用数据的时空特征可以取得更好的预测效果,证明CNN-GRU模型的有效性。
从CNN-GRU模型在测试集上的交会结果(图6)可以看出,CNN-GRU模型预测的孔隙度与实际孔隙度具有较高的相关性,其相关系数达0.911 8。
为证明所设置变学习率训练方法的有效性,将设置的学习率与固定学习率0.01,0.001和0.000 1分别迭代1 000次。由图7可知,当学习率为0.01时,训练前期网络收敛快,训练后期网络难以收敛;当学习率为0.000 1时,网络收敛缓慢。因此,以固定学习率训练网络模型存在着收敛震荡或收敛很慢的问题。这证明所提出的学习率设置方式,既可在训练前期加速网络收敛,又可在训练后期使网络平稳收敛到一个较小的值。由不同学习率对模型预测结果的影响(图8)可知,所提出的变学习率训练方法能够得到更好的预测精度。
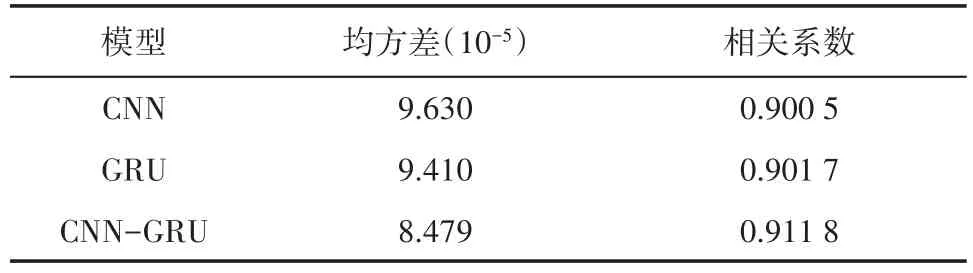
表1 3种深度学习模型预测结果评价Table1 Evaluation of prediction results based on three different deep learning models
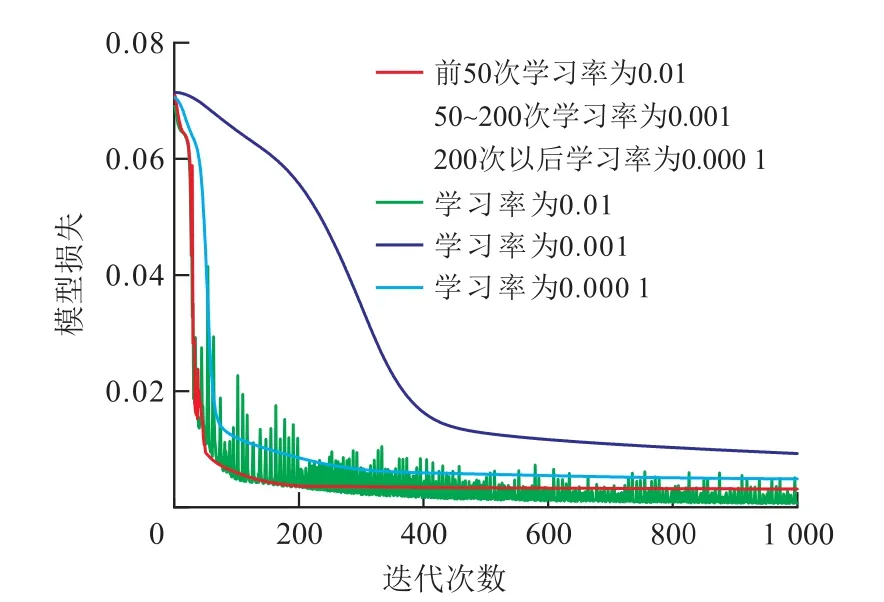
图7 不同学习率对模型收敛的影响Fig.7 Effect of different learning rates on model convergence
4 结束语
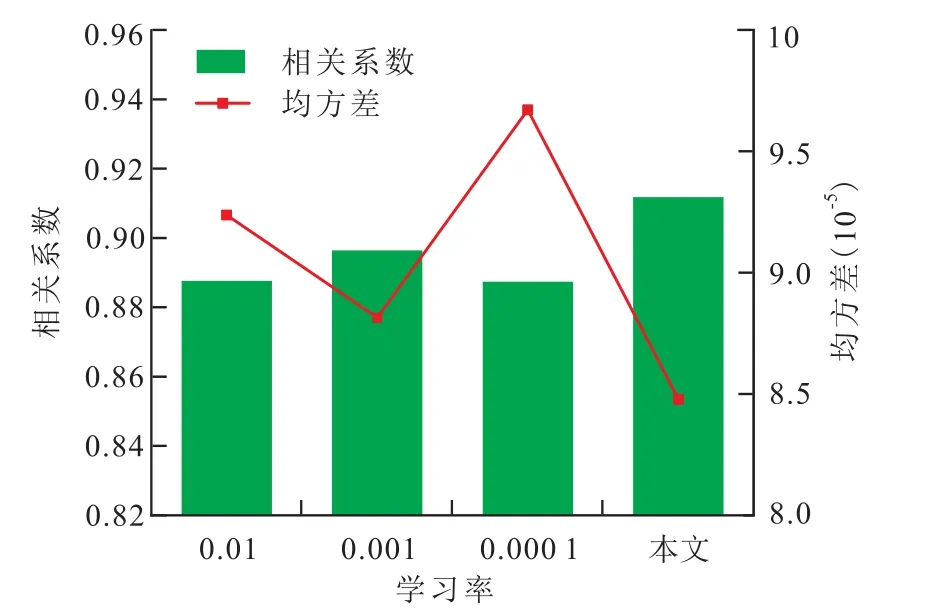
图8 不同学习率对模型预测结果的影响Fig.8 Effect of different learning rates on model prediction results
随着勘探领域的变化,储层介质由均质地层转向非均质地层,传统的储层预测方法难以估计出非均质地层的孔隙度。深度学习是机器学习的一个分支,已被广泛应用于各个领域。CNN与GRU是2种特性不同的深度学习模型,CNN模型适合提取不同测井参数之间的非线性关系,GRU模型适合提取测井参数在时间维度上的变化,2种模型均取得了不错的储层参数预测结果。本次结合2种模型的优势,设计了CNN-GRU模型。该模型能够充分提取测井数据的时空特征,预测精度优于单一的模型。调整好学习率是训练出好模型的关键要素之一,所提出的变学习率训练方法,既可以加速网络收敛,又可以提高模型的预测精度。
符号解释
n——时间步长;xt——t时刻的输入;yt——t时刻的输出;ht——t时刻的隐藏状态向量;rt——重置门激活向量;σ——Sigmoid函数;zt——更新门激活向量;h͂t——t时刻的候选状态向量;tanh——tanh函数;Wz——更新门权重矩阵;bz——更新门偏置值;Wr——重置门权重矩阵;br——重置门偏置值;Wh͂——候选状态的权重矩阵;bh͂——候选状态的偏置值;xn——第n个输入值;y∧n——第n个输出值;L(θ)——模型损失函数;θ——模型中的权重矩阵与偏置值;N——样本数量;i——样本序号,i=1,2,3,…θ(xi)——输入值为xi时的预测值;xi——输入值;yi——实际值;λ——正则化系数,取值为10-5;s——累积平方梯度;β——动量系数;g——梯度;η——学习率;ε——用于维持数值稳定的常数,取值为10-8;epoch——迭代次数;r1——训练前期与训练中期的界限值;r2——训练中期与训练后期的界限值;Y——测井数据归一化后的值;X——测井数据。
