基于并行独立成分分析方法研究精神分裂症的影像遗传学特征
2019-09-25谢忠翔武杰
谢忠翔,武杰
上海理工大学 医疗器械与食品学院(上海, 200093)
0 引言
精神分裂症作为一种基因遗传疾病,其临床表现往往症状各异,涉及感知觉、 思维、 情感和行为等多方面的障碍以及精神活动的不协调。有关精神分裂症研究的结果表明[1-2],受干扰的工作记忆和相关的前额皮质激活可能是两种受基因影响的疾病易感指标。然而,人们对这些功能障碍的遗传决定因素知之甚少,大多数遗传研究关注的只是特定的基因或感兴趣的单核苷酸多态性(SNP)。传统的对精神分裂症的研究大多是在单一模态(功能磁共振成像、 结构磁功能成像等)下进行的,每一种成像方式都只提供了有限的大脑信息,这样采集到信息就不够全面,无法利用不同模态的交叉信息来得出更有效的结论。
近年来,影像遗传学已经逐渐成为研究脑功能与基因相关性的一个有力和敏感的方法[1]。影像遗传学方法[3-5],通过观察和量化在遗传背景下的脑激活模式,综合神经影像和遗传学来研究两者的不同优势,用脑影像结果整合基因型信息能帮助识别脑功能水平上的候选基因的功能。影像遗传学方法在精神分裂症的研究中尤为重要。
在本文中,我们使用一种并行独立成分分析(Parallel ICA,PICA)方法,同时分析精神分裂症患者和健康者(对照组)的fMRI图像和遗传信息,提取隐藏的交叉信息,从而揭示遗传因素对大脑功能的影响[6]。这种方法涉及到三个需解决的问题[7-9]:(1)找到与精神分裂症相关的脑功能区; (2)识别与精神分裂症相关的SNP; (3)找出与精神分裂症相关的SNP和脑功能区域之间的相关性。
1 理论与方法
1.1 独立成分分析理论介绍
独立成分分析(Independent Component Analysis, ICA)是一种统计和计算技术[8],用于恢复隐藏的独立因素或随机变量。ICA的优点是它能够在不需要预先了解这些因素的特性的情况下,揭示各种因素。ICA已经应用于fMRI数据的分析,以发现在某些脑区大脑的独立成分。同样,ICA也是一种合理的方法,可以用来发现存储在基因中的未知但重要的信息。
X=A·S;Z=W·X;
IfW=A-1, themZ=S
(1)
式(1)为基本ICA模型,它定义了所观察数据的生成模型,观察到的变量被假定为一些未知潜在变量的线性混合,混合系统也未知。潜在变量被假定为非高斯分布和相互独立[9],它们被称为观测数据的独立成分。式(1)中,X是一个观测矩阵,可以由诸如fMRI图像或SNP等组成。S包含独立的成分,如大脑激活图等。A是一个线性混合矩阵,将源与受干扰的测量数据联系起来,W是一个解混矩阵。如果W等于A的逆,那么Z(估计的成分矩阵)等于S(源矩阵)。因此,ICA的本质是找到W,使Z尽可能接近包含在S中的真正独立成分。
对于ICA,有许多基于不同独立标准的算法,其中,信息极大化原则[10](Infomax)算法通过最大化的熵函数来寻找W矩阵。
1.2 并行独立成分分析理论
独立成分分析通常用于处理单个数据类型,揭示数据集中嵌入的因素,而不需要事先知道这些因素的特性。并行独立成分分析(Parallel Independent Component Analysis,PICA)可以同时容纳两种数据类型,能够揭示每种数据类型的独立成分,并评估这些成分之间的相关性。
PICA需要同时解决三个问题,其中两项涉及到两种数据类型的成分之间的独立性最大化,第三项是确定两数据类型独立成分之间的相关性。PICA方法是基于Infomax算法的,它利用互熵的最大化来最大限度地实现成分间的独立性[11],而对于不同数据类型的成分之间的相关性,则是通过增加一个相关性平方最大化的约束项来确定的。例如,在本研究中,我们试图找到一种数据类型的列向量与另一数据类型的列向量之间的相关性,正如图1所示。
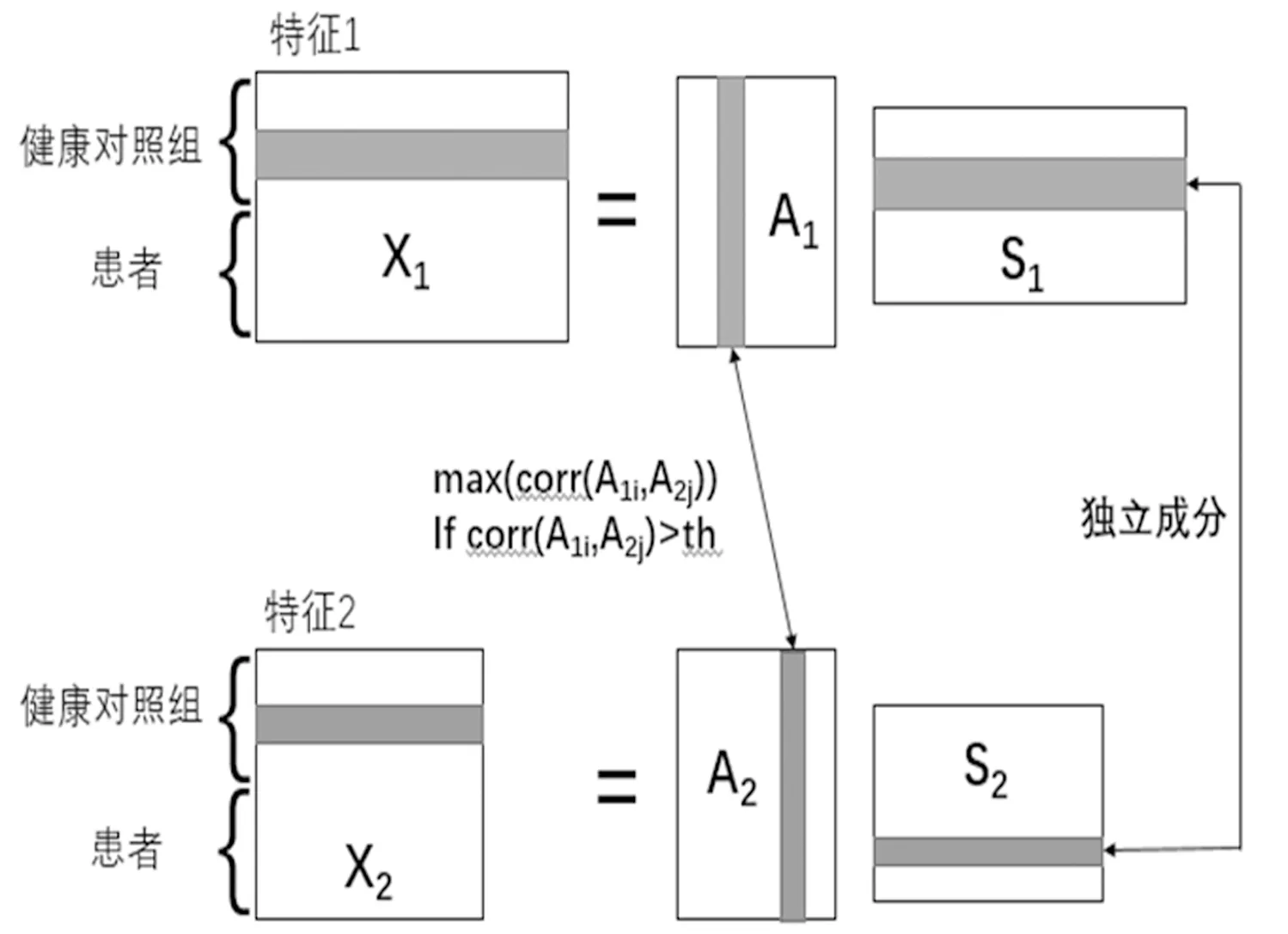
图1 PICA理论框架Fig.1 Theoretical framework of PICA
为了便于说明,我们设定每个数据类型中只有一个成分受到约束。
(2)
其中,Corr为相关函数,Cov是协方差函数,Std是标准偏差函数,i和j是分量的指数。
约束项是两种数据类型之间的桥梁,它是PICA的本质[6],不同于两个完全独立的ICA优化,约束的适当优化在收敛和避免过拟合中起着关键的作用。我们采用以下两种策略来进行约束优化: (1)动态强制连接; (2)自适应学习速率。
对于动态强制连接[7-8],我们允许PICA约束在优化过程中变化。在一个相关性大于0.3的经验假设下,在每一步迭代中选择相关性满足条件的任意一对独立成分(一个独立成分在每一步迭代中只能选择一次),并通过约束来强调相关性。因此,根据它们的并行性质,受约束的关联可以在不断的迭代中变化,这种灵活性允许约束在算法收敛时动态地优化。
我们采用的第二种策略是自适应学习速率,不断改变代价函数中三项的学习速率。自适应改变学习速率的原因有两方面: (1)这三个项具有不同的特征,所以它们会以不同的速率收敛。然而,它们也会相互影响,如果其中一个项占据主导地位,那么学习将是次优的。为了弥补这一点,我们为每一个项分配一个学习速率并同步更新它们。(2)通过自适应地调整关联项的学习速率,以减轻过拟合。
最后的最大化代价函数显示在式(3)中。
max{H(Y1)+H(Y2)+Corr(A1,A2)2}
(2)
其中,U是评估的独立源,W是解混矩阵。为了满足校正准则,我们通过使用自然梯度的最大化来实现W矩阵的校正。其中i和j表示在每个最大化迭代中选择的约束成分,这两个指标可以根据最大化过程而变化。因此,该算法能够适应不断更新的成分。在最大化函数式(3)中,这三个项有不同的特点。为了使两个熵同样最大化,我们只需将前两项与两种学习速率同时进行最大化,利用自然梯度最大化; 第三项采用最陡下降法进行优化,并且通过在选定的两个成分上每一次迭代来计算步长。最终,该算法确定了: (1)最优W矩阵; (2)两类数据的独立成分; (3)两类数据独立成分之间的相关性。
1.3 研究对象
在这项研究中,从63名受试者中收集了fMRI和SNP两种类型的数据,其中包括20名精神分裂症患者和43名健康对照组。患者年龄在39岁至54岁之间,健康对照组的年龄从21岁到83岁不等。在43例健康对照中,有21名女性和22名男性参与者,3名女性和17名男性精神分裂症患者。在纳入研究之前,对所有受试者进行了筛选,以美国DSM-IV精神分裂症诊断标准来诊断[12]。
功能磁共振成像扫描通过使用梯度回波平面成像获得,使用以下参数: 重复时间=1.50 s、 回波时间=27 ms,视野=24 cm, 采集矩阵=64×64, 翻转角度=70°,体素的大小=3.75×3.75×4 mm3,层厚=4 mm,间隙=1 mm,一共采集29层。
1.4 PICA算法流程
对影像和基因数据运用PICA方法进行处理,PICA算法的过程如下:
(1) 分别对fMRI和SNP数据进行分析,并分别用指定的学习速率进行初始化;
(2) 如果有必要的话,两个W矩阵需根据它们各自的熵项来更新;
(3) 对两类数据各自的W矩阵优化停止标准进行评估。如果两个寻优过程都满足标准,那么整个PICA过程就停止了。如果只有一个过程满足该标准,那么该模态的迭代就停止,相应的W矩阵也就完成了;
(4) 依据最高的相关性,选出与每个fMRI成分相关的SNP成分;
(5) 如果需要的话,两个W矩阵都根据相关项来更新。之后,返回步骤(2)。
为了避免因过拟合导致的错误发现,我们运用留一检测法(Leave-one-out Evaluation)来测试结果的精确度。由于本论文实验中所涉及的受试者只有63名,因此,在同一参数设置下,我们使用PICA进行63次测试,每次62人(包括一个不同的受试者)。最后,对63次测试的一致性进行评估。
2 结果
2.1 独立成分显示
对于63个受试者处理后的fMRI数据的独立成分数量为5个,SNP数据的独立成分数量为7个。
我们对两类数据处理得到的独立成分进行统计学显著性检验,找出其中与精神分裂症相关的独立成分,排除不相关成分。

表1 fMRI和SNP成分的P值Tab.1 The P-value of fMRI and SNP component
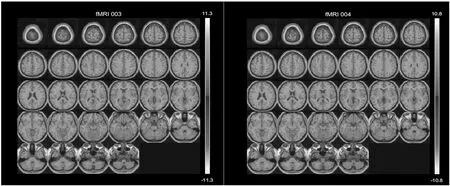
图2 fMRI的No.3、No.4独立成分Fig.2 No.3 and No.4 Independent components of fMRI
根据表1中fMRI和SNP成分的P值,我们找到了与精神分裂症相关的No.3 fMRI成分、 No.4 fMRI成分以及No.6 SNP成分(该SNP成分显示在图3中)。
结合脑AAL模型,我们可以从图2中发现: 与精神分裂症相关的脑功能区有: 楔前叶、 舌回、 楔叶、 枕颞内侧回、 顶上小叶、 中央后回、 枕下回、 额上回、 额内侧回、 颞上回。
2.2 内外表型的相关性
在与精神分裂症相关的fMRI成分和SNP成分中,其中一个fMRI成分和一个SNP成分之间的相关性最高,相关系数为0.375 4。为了便于直观显示,在这两个相关联的fMRI成分和SNP成分中,只显示fMRI中高激活区域和重要的SNPs。
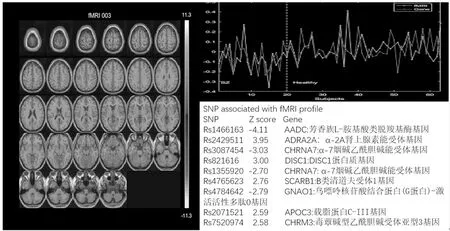
图3 与SNP相关的fMRI脑区Fig.3 Brain regions of fMRI associated with SNP
图3显示了来自20个精神分裂症患者和43个健康对照者的fMRI数据和367个SNPs的PICA处理分析的结果。左边的图表示提取出的相关联的fMRI成分,红色和蓝色分别代表正激活和负激活,数值表示脑功能区被激活的程度大小。右上角的图表示所有受试者的No.3 fMRI成分和SNP成分的混合系数。右下角表示其中提取出的相关联的SNP成分的具体信息。
该fMRI成分最大的部分位于楔前叶,第2个区域是舌回,第3个区域是楔叶。相关SNP成分主要在以下编码基因中: 芳香族L-胺基酸类脱羧基酶基因(AADC),α-2A肾上腺素能受体基因(ADRA2A),α-7烟碱乙酰胆碱能受体基因(CHRNA7), DISC1,SCARB1,GNAO1,APOC3,CHRM3。
为了避免因过拟合导致的错误发现,我们用留一检测法来检测结果的精确度,对63次测试的一致性进行评估。如图4显示,在63次的评估数据中,这些fMRI和SNP成分之间的相关性是0.37±0.07。
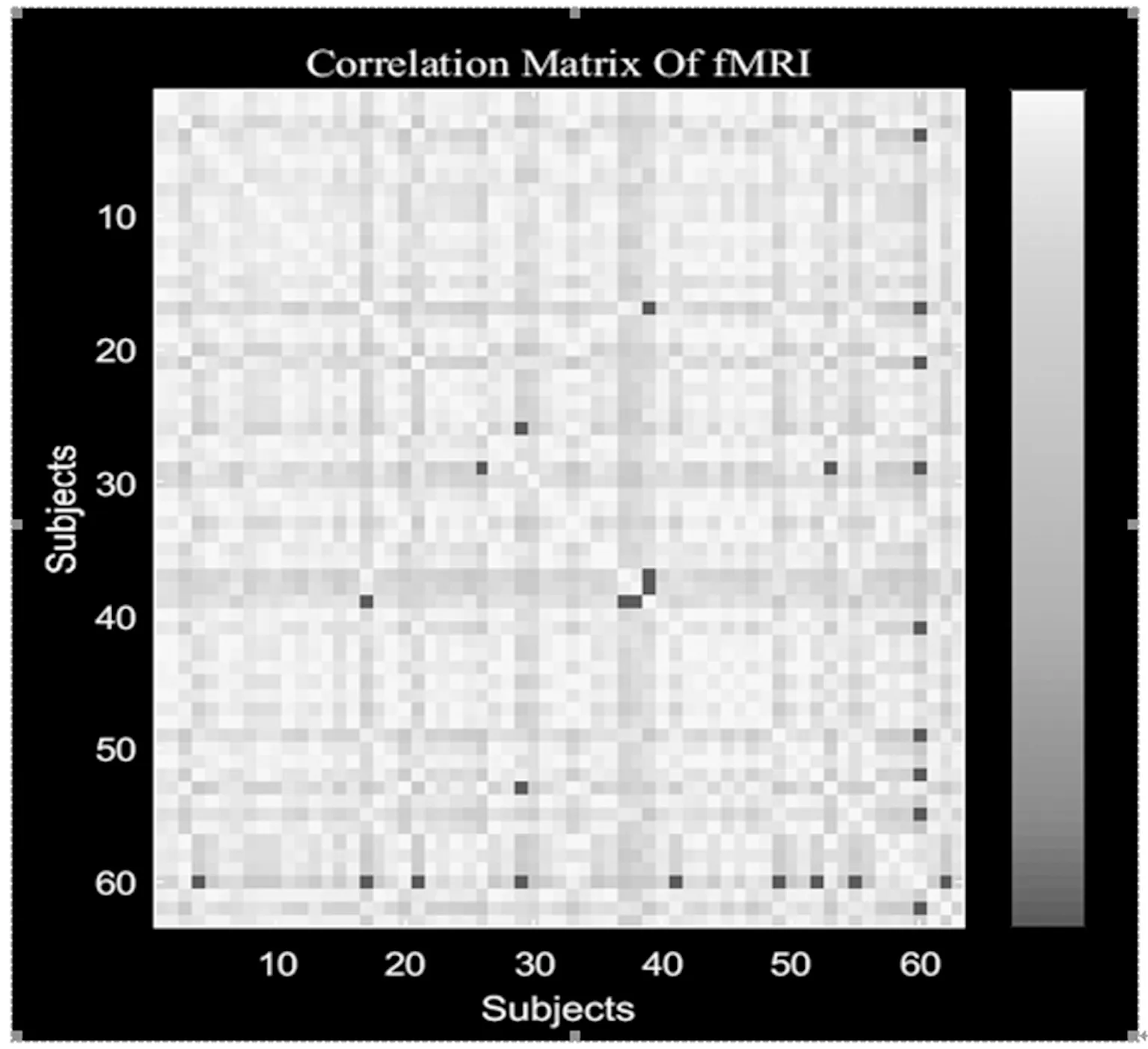
图4 相关性矩阵Fig.4 Correlation matrix
3 总结
我们使用了一种分析影像遗传学的方法,以研究脑功能区与基因之间的相关性。该方法可以评估基因遗传对外表型的影响,如与精神障碍有关的脑功能。
本实验中,我们对63个受试者的fMRI数据和SNP数据进行了处理,用PICA方法提取出了两类数据的独立成分,并通过统计学方法筛选出其中与精神分裂症相关的成分,同时找到相关性最大的fMRI成分和SNP成分。该fMRI成分主要包括楔前叶、 舌回、 楔叶这三个脑区,其中楔前叶与许多高水平的认知功能有关,如情景记忆,自我相关的信息处理,以及意识的各个方面; 舌回有两大功能,一为视觉加工,二为单词加工; 楔叶则是在记忆检索中起到很重要的作用[13-14]。相关的SNPs主要位于的基因包括芳香族L-胺基酸类脱羧基酶基因(AADC)、 α-2A肾上腺素能受体基因(ADRA2A)、 α-7烟碱乙酰胆碱能受体基因(CHRNA7)、 DISC1、 SCARB1、 GNAO1、 APOC3和CHRM3。其中,CHRNA7和DISC1则是著名的精神分裂症易感基因[14]; AADC基因上的单核苷酸多态性已被证实与神经精神障碍有关[15]; 由ADRA2A基因编码的α-2A肾上腺素能受体主要调节由交感神经和肾上腺素能神经元释放的神经递质,在中枢神经系统功能调解中起着重要的作用,在以往的研究中也被发现与精神分裂症相关[16-17]; 对精神分裂症的候选基因的分子遗传分析显示: CHRNA7基因位于一个被认为与精神分裂症遗传传播有关的染色体位置[18]; DISC1与神经异常有关,如妄想、 长期工作记忆缺失、 海马和前额区域灰质体积的减少等,而这些异常也是精神分裂症的症状[19]; GNAO1基因的突变已被证明可引起癫痫性脑病[20]。
本研究的结果表明了特定区域脑功能与所选基因之间的相关性,为预测和诊断精神分裂症提供了一个更精确的方法。采用检测到的精神分裂症生物学指标对处于高危状态(有精神分裂症家史)的青少年人群进行筛查,可以对将来可能患精神分裂症的青少年进行预测并进行早期干预(心理干预或药物干预),将有助于改善预后。
4 讨论
综上所述,我们使用了一种可以同时处理两类高维数据的方法,能够找到与精神分裂症相关的独立成分以及这些成分之间的相关性。
作为一种多模态数据处理方法,PICA方法除了能够处理fMRI和Gene数据类型,提取出fMRI和Gene的独立成分,找到基因与脑功能区的相关性,还能够处理sMRI和EEG数据类型,比如: 用PICA方法处理sMRI和Gene数据类型,找到基因与脑功能结构之间的关联; 或者用PICA方法处理fMRI和EEG数据类型,找出脑功能区域与心电图之间的联系等等。同样,PICA方法所适用的范围也不仅仅局限于研究精神分裂症的影像遗传学特征,还能够用来研究阿尔茨海默病、 抑郁症等。
在我们研究了fMRI和遗传成分的特征后,与精神分裂症相关的变化和已知的这种疾病的功能障碍是一致的。例如,顶叶(楔前叶、 顶叶上回)和额叶上皮层的异常通常发生在精神分裂症的异常部位。此外,如前所述,CHRNA7、 DISC1被认为是精神分裂症易感性和大脑功能结构改变的候选基因。然而,为了证实这些基因与特定大脑区域的功能以及它们与精神分裂症的相关性之间的联系,同样的方法需要应用于更大范围的受试者群体。