基于STM32的步进电机多轴速度控制方法研究与实现
2019-09-25于乃功
于乃功
(1.北京工业大学 信息学部,北京 100124; 2.计算智能与智能系统北京重点实验室,北京 100124; 3.数字社区教育部工程研究中心,北京 100124)
0 引言
随着自动化设备和机器人需求的稳步增长,作为它们的关键驱动部件步进电机或伺服电机配套的驱动器及脉冲控制器需求也相应增加,而常用的脉冲控制器一般情况下依靠PLC即可实现,但其在机器人控制中无法灵活使用,所以很有必要开发一款基于STM32的实时定时脉冲发生器。并且STM32F103芯片也有结构简单[1],成本低廉,占用空间小等诸多优点。
电机起步速度过快时会发生堵转,具体原因是因为由静止状态到动态,如果速度过高的话,会引起各轴之间产生冲击,超程,失步等现象[2],而停止时因为工件在快速运行状态,若突停的话,因机械惯性较大,严重的话会引起机械损伤,或定位不准现象为了使执行机构能平稳定位,就要求电机在开机速度达到给定进给速度的过程中有一个加减速过程,使其能平滑过渡,避免电机速度突变给其带来损伤。
大多数运动控制系统都采用两种加减速控制算法:梯形加减速算法,S形加减速算法。因梯形加减速方案[2]便于计算,实现方式简单,系统响应快,已能满足一般多轴加减速控制场合应用需求所以在多轴脉冲控制器中获得广泛应用,本文主要采用梯形加减速方法实现。
STM32F103在发送多路脉冲方面,如果选择用多个定时器来发送,那么在速度非常高的时候就会导致发送的脉冲不准确。这是因为STM32F103芯片是单核单线程的,无法同时处理多个中断,利用多个定时器来发送多路脉冲经常就会发生同一时间触发多个中断的情况。因此本文克服了常规采用多路定时器方案只能实现中低速下(50 kHz以下)多路脉冲发生方法,采用只使用一个定时器发送主轴脉冲,从轴脉冲通过插补算法跟随主轴的方法实现多路高速脉冲发送。
1 基于脉冲定时器的电机加减速脉冲产生算法
1.1 脉冲定时器工作原理分析
定时器采用向上计数模式,从零开始累加到设定值后溢出,设定值由自己设置并存放在ARR(自动重装载寄存器)中[3]。当达到设定值时进入中断,每次进入定时中断后,将单片机某一I/O口翻转,即可产生脉冲,通过改变定时中断的时间即ARR值,就可以控制输出脉冲的频率。为了防止ARR寄存器中的值超过16位导致溢出,利用TIMx_PSC(预分频寄存器),预分频器可以将计数器的时钟频率按1到65536之间的任意值分频。它是基于一个(在TIMx_PSC寄存器中的)16位寄存器控制的16位计数器。这个控制寄存器带有缓冲器,它能够在工作时被改变。新的预分频器参数在下一次更新事件到来时被采用。
当预分频器的参数从1变到2时,计数器的时序图如图1所示。
1.2 插补原理分析
插补法常见的有:逐点比较插补法,比值积分法和数字积分插补法。

图1 计数器的时序图
当预分频器的参数从1变到4时,数器的时序图如图2所示。
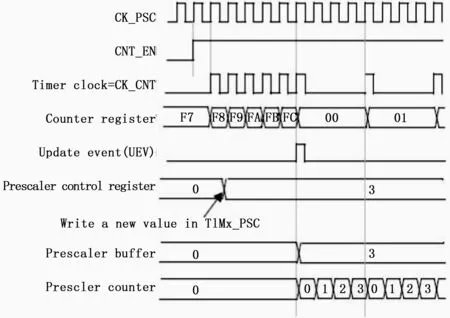
图2 计数器的时序图
本文的插补方法主要采用数字积分法,数字积分法就是把给定的形成数据存储到有限长度的寄存器里进行微分累加,通过判断寄存溢出产生脉冲作为进给输出脉冲。数字积分的插补方法(DDA)具有逻辑强的特点,可以实现复杂曲线的插补运算,适用于多轴联动控制;只要输入几个初始数据,就能计算出执行机构所需要的运行轨迹数据,从而加工出直线、圆弧或由直线和圆弧组成的更复杂的轮廓曲线。在进行插补时选择位置值大的作为长轴,这样长轴就能均匀输出进给脉冲,其余轴就能根据与长轴的关系输出进给脉冲。另外在进行直线插补运算控制时,插补运算的输出脉冲比较均匀。
1.3 电机加减速控制脉冲产生算法
步进电机的转速和步进电机驱动器接收的脉冲频率成正比,如果控制器发出的脉冲频率越高则步进电机的转速越快[4]。利用这个特点通过设定发出脉冲的频率控制步进电机的转速是一种行之有效的方法。通过更改定时器ARR的值即可控制输出脉冲的速度[5]。
(1)
脉冲加减速采用常用的梯形加减速方式,参数为初始速度v0,最终速度vmax,加速度acctime,脉冲总数L。当这些参数确定后可以确定一个脉冲序列及速度序列(定时器ARR值),以1 ms为一个单位来改变定时器的装载值,来改变其频率。程序中将每毫秒应输出的脉冲数和该毫秒内定时器的自动装载值都放在查找表中。定时器工作时按照顺序首先按照最初的装载值定时中断,当输出完对应装载值设定的脉冲后,更新装载值。如此复,直到整个加减速过程完成。
计时器初始化参数有如下公式:
(2)
那么:
(3)
定时器装载值:
(4)
因为定时器的频率应该是脉冲频率的两倍,所以实际的定时器装载值为:
(5)
1.4 多路脉冲差补算法
确定最高速脉冲为主轴,其他路为从轴[5]。每次中断开始计算其他从轴是否发送脉冲。主轴速度与从轴速度为已知量,主轴速度由Vmain表示,从轴速度用Vsub表示。计算方法如下:
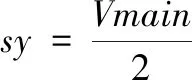
(6)
st=Vmain-Vsub
(7)
如果sy≥st那么发送脉冲,并且:
sy=sy-st
(8)
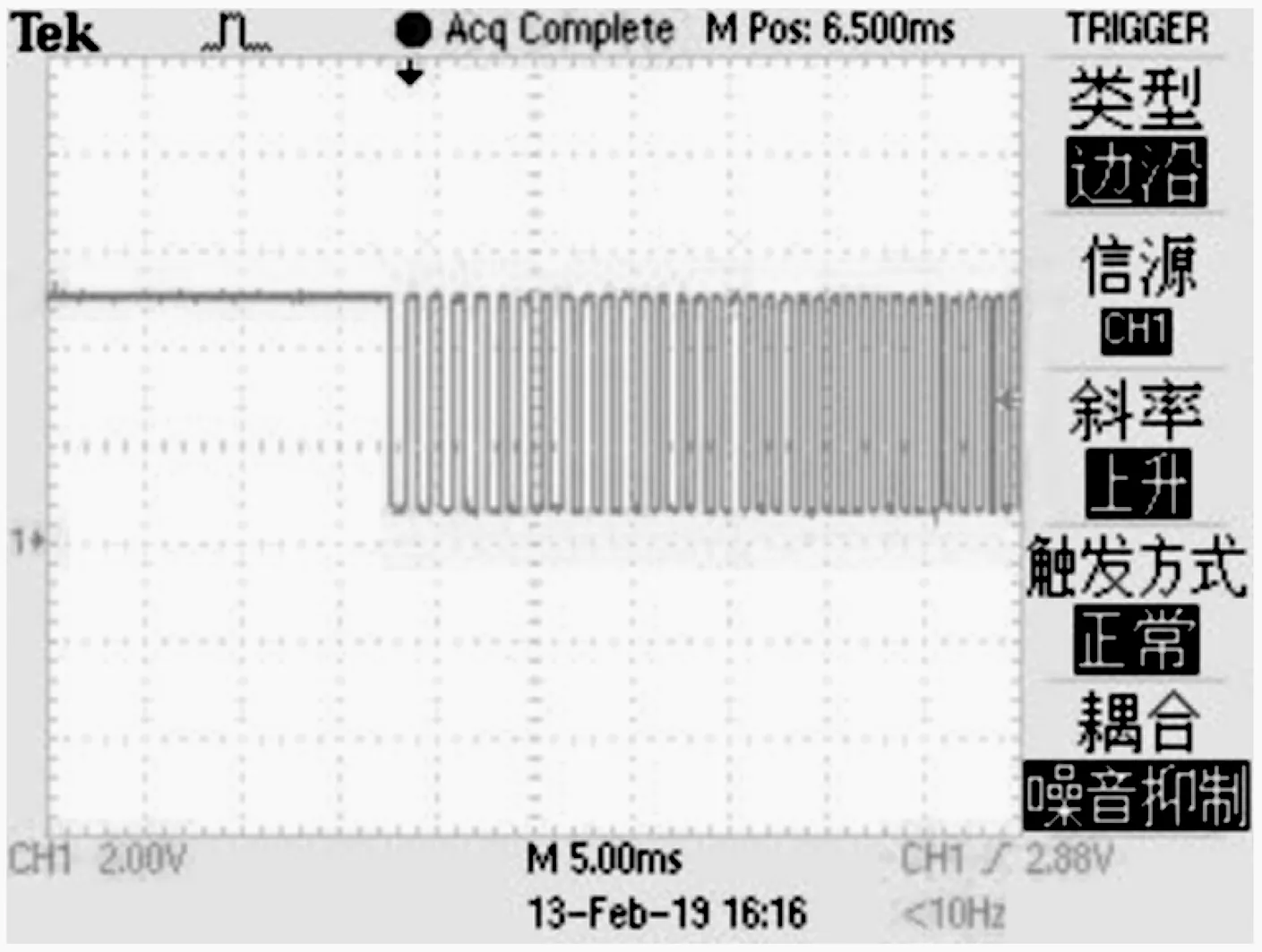
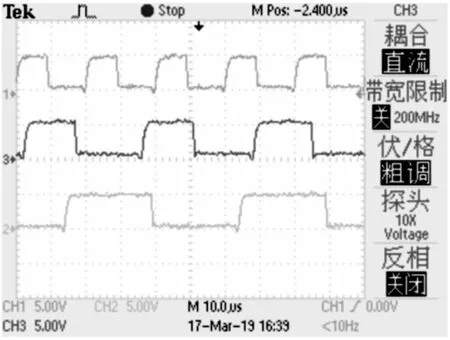
如果sy sy=sy+Vsub (9) 如此往复循环就可以得到从轴脉冲。 步进电机单轴速度与位置控制程序流程图如图3所示。首先,设置步进电机的初始转速v0,最高转速vmax, 加速时间acctime,总脉冲数L。然后,计算出加速段截止脉冲数S1,匀速段截止脉冲数S2。根据不同区间的位置S使用不同的赋值方式[6]。接着利用上述给定条件,计算出每毫秒发送的脉冲数与截止至该毫秒的总脉冲数 (每毫秒发送的脉冲数实际上是只有加速阶段的速度值并且是经过1.3节算法计算出的定时器装载值),并设置两个数组分别装载所有计算结果。接着每毫秒都先进行判断,首先判断总脉冲值是否小于S1,如果小于则说明目前为加速阶段,将数组中的每毫秒发送脉冲数按正序赋值给定时器,如果不再满足小于S1的条件,则开始循环判断是否小于S2,如过小于则说明目前在匀速段,将数组中每毫秒发送的脉冲数中最大值赋给定时器,如果不再满足小于S2的条件,则开始循环判断是否小于L,如果小于说明目前为减速阶段,将数组中的每毫秒发送脉冲数按倒序赋值给定时器,如果不再满足小于L的条件,说明脉冲已全部发送完毕。采用先计算再用数组存储的方法是为了使输出脉冲具有连续性与准确性,并能够减少CPU占用。 图3 单轴脉冲加减速流程图 在输入完设定值后,如果无法在总脉冲为L时完成一次完整的从v0加速到vmax再减速回v0时,说明vmax设置值过大。而实际的发送情况是加速到发送脉冲总数为1/2L就立刻开始减速,实际最大速度应为v1,所得速度函数应为三角形而非梯形。考虑到此情况,当按梯形加减速求出的S1>1/2L时,则不使用设置的vmax为最大速度而利用1/2L、v0、acctime求出实际最大速度v1替换掉梯形加减速情况的vmax,1/2L替换掉S1,取消掉匀速段部分S2的判断与赋值,即可实现准确的三角形加减速。 实际代码: (1)主程序配置代码如下: ifndef _DRIVE_H_ define _DRIVE_H_ include "sys.h" define PULSEARRAY_SIZE 500 extern u16 psc; struct PULSE { u16 pulsearray[PULSEARRAY_SIZE]; //存放每毫秒要发送的脉冲数,脉冲频率 u32 pulse_num; //定时器中对发送脉冲计数 int pulsearray_index; //中间变量,用于定时器值累加 u16 state_status; //运行状态标志 u16 state1; //S1分割点 u16 state2; //S2分割点 u16 state3; //L结束 u16 time_up; //加速时间acctime u16 time_stable; //平稳运行时间 u32 pulse_num_stable; //平稳运行时的脉冲总数 u16 v0; //初始速度 u16 vmax; //最终速度 float acc; //加速度 u32 pulse_totalnum; //脉冲总数 }; extern struct PULSE pulse_x; extern struct PULSE pulse_y; extern struct PULSE pulse_z; extern struct PULSE pulse_a; extern struct PULSE pulse_b; extern struct PULSE pulse_c; u8 Init_Pulsetable(u16 v0,u16 vmax,u16 acc,u32 pulse_totalnum,struct PULSE *pulse);//声明使用的速度计算函数 endif /* __DRIVE_H__ */ (2)主程序代码如下: u8 Init_Pulsetable(u16 v0,u16 vmax,u16 acc_time,u32 pulse_totalnum,struct PULSE *pulse) { u16 i = 0; u32 pulse_num_temp = 0; //先判断速度是否满足要求 if(v0 < 1)v0 = 1; if(vmax > 100) vmax = 100; pulse->v0 = v0; pulse->vmax = vmax; pulse->time_up = acc_time; pulse->pulse_totalnum = pulse_totalnum; pulse->state_status = 1; pulse->acc = (float)(vmax-v0) / acc_time*1.0; if(pulse->time_up*2+2 > PULSEARRAY_SIZE) return 0; pulse_num_temp = (v0 + v0 + pulse->acc * (pulse->time_up-1)) * pulse->time_up; if(pulse_num_temp < pulse->pulse_totalnum) { //梯形加减速 for(i = 0;i < pulse->time_up-1;i++) { pulse->pulsearray[2*i] = v0 + pulse->acc * i; pulse->pulsearray[2*i+1] = 36000 / pulse->pulsearray[2*i] / (psc+1)-1; }//将每毫秒计算出的自动重装载值存入数组 pulse->pulsearray[2*pulse->time_up-2] = pulse->vmax; pulse->pulsearray[2*pulse->time_up-1] = 36000 / pulse->pulsearray[2*pulse->time_up-2] / psc / 2;//将实际算出的脉冲总数存入数组 pulse_num_temp = (v0 + v0 + pulse->acc * (pulse->time_up-2)) * (pulse->time_up-1); pulse_num_temp += pulse->vmax * 2; pulse->pulse_num_stable = pulse->pulse_totalnum-pulse_num_temp; pulse->time_stable = pulse->pulse_num_stable / vmax; pulse->state1 = pulse->time_up; } else { //三角形加减速 pulse->time_up = (sqrt(4*v0*v0+4*pulse->acc*pulse_totalnum)-2*v0)/(2*pulse->acc); pulse_num_temp = (v0 + v0 + pulse->acc * pulse->time_up) * (pulse->time_up + 1); pulse->pulse_num_stable = pulse->pulse_totalnum-pulse_num_temp; for(i = 0;i <= pulse->time_up;i++) { pulse->pulsearray[2*i] = v0 + pulse->acc * i; //将实际算出的脉冲总数存入数组 pulse->pulsearray[2*i+1] = 36000 / pulse->pulsearray[2*i] / (psc+1)-1; //将每毫秒计算出的自动重装载值存入数组 } pulse->state1 = pulse->time_up+1; } return 1; } 多路脉冲发送流程图如图4所示。由于STM32F103性能不够强大,不能够同时使用多个定时器同时发送多路高速脉冲,所以选择最高速脉冲为主轴[9],用定时器来控制,其余各路作为从轴用插补算法来控制发送速度,从而避免使用多个定时器。流程是先判断是否发送,然后进入中断,通过比较找出最高速的一路脉冲作为主轴,其余路脉冲为从轴,然后通过差补算法算出从轴在此次中断时是否发送脉冲。如此不断重复即可实现单个定时器实现多路不同速度脉冲的发送。实际上,在主函数中也需要先判断一次最高速脉冲,然后才能确定主轴与中断触发条件。实现从轴发送与不发送脉冲的方法是不断改变一个设定好的全局变量标志位,目标从轴的标志位为1时从轴发送,为0时不进行发送,在主函数里则通过判断这些标志位来判断是否发送,这样是因为中断函数里不能出现循环语句导致的。 将按照要求实现的程序烧录进STM32F103开发板中,输入初始速度,最大速度,加速时间acctime,总步长L。然后开始发送脉冲并用示波器测量波形,得到3个阶段的波形如图5、图6和图7所示。可以发现由控制I/O口发送脉冲的方法更加精准且更易于计数。在实际自动化生产与机器人运用中,精确的速度控制往往能够成为是否可应用化的关键标准,所以开发以一款基于STM32F103由控制I/O口发送脉冲的方法是十分必要的。 图4 多路脉冲发送流程图 图5 脉冲发送加速段 图6 脉冲发送匀速段 图7 脉冲发送减速段 在原有程序基础上加入多路脉冲插补算法重新烧录进STM32F103开发板中,设定主轴脉冲最高速度为50 kHz,其余两路分别为30 kHz与20 kHz。得到的三路脉冲波形图如图8所示,图9为由3个定时器发送三路脉冲的方案,通过对比可以看出由差补算法得到的速度比为精确的5:3:2, 而利用3个定时器发送的方式主轴实际速度为30 kHz,无法达到50 kHz且速度不稳定,这是由于STM32F103本身性能不够的原因导致的,所以使用插补算法发送多路脉冲是十分有必要的。 图8 利用差补算法方案的多路脉冲 图9 利用多个定时器发送多路脉冲 本文中设计的基于STM32F103的控制多轴梯形加减速脉冲发送方法具有精度高,硬件结构简单,适应性强等特点[10],可降低运动控制器的成本。该方法已经应用于工业自动化控制领域,证明了该方法的可行性与实用性。2 步进电机速度与位置控制的实现
2.1 梯形加减速情况

2.2 三角形加减速情况
3 多路脉冲发送实现
4 测试与实验结果分析
4.1 单路加减速脉冲实现



4.2 多路脉冲发送实现

5 结束语
