融合词位字向量的军事领域命名实体识别
2019-09-23车金立唐力伟邓士杰苏续军
车金立,唐力伟,邓士杰,苏续军
(陆军工程大学石家庄校区 火炮工程系,河北 石家庄 050003)
随着信息时代的不断发展,数据已逐渐成为一种资源甚至生产要素。与此同时,在现代军事活动中也会产生海量的电子文本,例如有大量文本记录了火炮射击过程中的射击体制、射击模式等[1],如何处理并有效利用这些数据对于指导军事活动具有重要意义。而准确识别军事领域文本中的命名实体是对其进行深层次分析的基础性工作。
命名实体识别(named entity recognition, NER)在通用领域中主要是指识别文本中的人名、地名、机构名、时间、货币等具有特定意义的实体[2]。目前,命名实体识别的主要方法包括基于规则的方法、基于统计机器学习的方法和基于深度神经网络的方法三大类。
命名实体识别研究的初期主要是基于规则的方法,如文献[3-4]都是通过人工构建的规则来完成命名实体识别。这类方法需要较强的领域知识及语言学知识来制定有效的规则,领域迁移性较差,且人工消耗较大,仅适用于简单任务。因此,之后命名实体识别研究的重心逐渐转移到基于统计机器学习的方法上。在将NER任务视作序列标注任务后,学者们首先将最大熵(maximum entropy, ME)[5]、隐马尔科夫(hidden Markov model, HMM)[6]、条件随机场(conditional random fields, CRF)[7]等模型用于英文的命名实体识别,并取得了一定的效果。之后面向中文的命名实体识别也开展了一系列研究,邱泉清等[8]在对特征模板进行设计后,使用CRF模型对微博数据完成了命名实体识别,且取得了较好的效果。然而这些方法的缺陷也显而易见,模型性能的好坏严重依赖于人工设计特征的数量,但特征的增多,会导致模型训练时间过长且容易过拟合,领域泛化性较差。
近年来,深度神经网络依靠其可从原始数据中自动提取深层次抽象特征的优势,避免了复杂的人工特征设计,使其在图像处理、机器翻译等领域取得了显著成效[9-13]。与此同时,在NER任务中,深度学习也显示出了其特有的优势[14]。
而在军事领域,有关研究相对较少,军事命名实体识别任务面临实体名称语法结构较为复杂,且名称较长等问题。为了解决这些难题,笔者基于深度神经网络提出一种融合词位字向量的军事领域命名实体识别方法,该方法首先将单个汉字在分词结果中的词位信息加入到由大规模语料预训练的字向量中,然后将得到的组合特征向量作为输入,由改进得到的双向门限循环单元条件随机场(BI-GRU-CRF)网络进行训练,最后完成对军事领域命名实体的识别。实验结果表明,该方法较基于CRF的方法及使用基本字向量的深度神经网络模型有较好的识别效果。
1 基于BI-GRU-CRF模型的军事领域命名实体识别
受文献[15-16]的启发,笔者将命名实体识别任务抽象为序列标注任务,即由标注模型对输入的文字序列进行输出标签序列的预测,为每个字打上“IOBES”标签集中对应的标签,进而标记出文中的命名实体。笔者在文献[16]提出的双向长短时记忆(bidirectional long short-term memory, BI-LSTM)标注模型的基础上进行了改进,将LSTM单元替换为结构相对简单且更易于训练的门限循环单元(GRU),并在输出层加入CRF层,利用预测标签间的前后关系对整个标签序列进行预测,构成双向门限循环单元条件随机场(BI-GRU-CRF)模型。
1.1 传统RNN网络
循环神经网络(recurrent neural network, RNN)的基本结构如图1所示,通常包括输入层、隐藏层、 softmax层及输出层。与卷积神经网络不同,RNN在隐藏层节点间加入了相互连接,将隐藏层的前一状态加入到隐藏层当前状态的计算中,充分利用了历史信息。
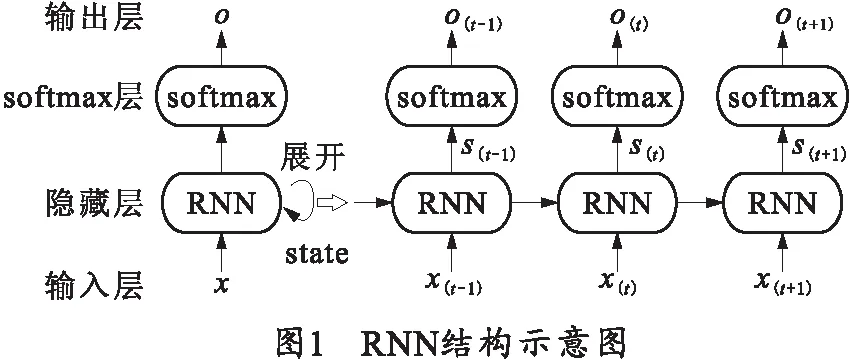
图1中x(t)为输入,在命名实体识别中代表t时刻的输入字向量。s(t)则为RNN节点t时刻输出的隐藏状态,其计算依赖于前一时刻的隐藏状态s(t-1)与当前时刻的输入x(t):
s(t)=tanh(W*x(t)+U*s(t-1)+B),
(1)
式中:W为连接输入层到隐藏层的权值矩阵;U为前一时刻隐藏层到当前时刻隐藏层的权值矩阵;B为偏置参数矩阵;tanh为激活函数。
o(t)为输出,在命名实体识别中表示t时刻输出的标签概率,其计算依赖于当前时刻节点的状态:
o(t)=softmax(V*s(t)),
(2)
式中:V为连接隐藏层到输出层的权值矩阵;softmax则作为分类函数。另外,为了减少参数数量,RNN网络在训练中的参数是共享的,即上文中的W,U,B,V权值矩阵在每一时刻的计算中相同。
1.2 GRU单元
理论上,RNN网络可以利用隐藏层状态s(t)来捕获前面所有的输入信息,然而现实却并非如此完美。相关研究[17-18]表明,传统的RNN网络在处理长距离信息时,隐藏层节点只是简单的使用tanh函数,使得训练易于陷入梯度消失或梯度爆炸的问题当中。
因此为解决上述问题,LSTM[19]和GRU[20]单元先后被提出,用于替换传统RNN网络中的tanh函数层。GRU是一种改进模型,相对LSTM更加简洁和高效,它只具有重置门和更新门两个门结构。文献[21]验证了GRU模型在许多问题中比LSTM模型更易于训练,且能够取得与LSTM相当的结果。GRU单元的内部结构如图2所示。
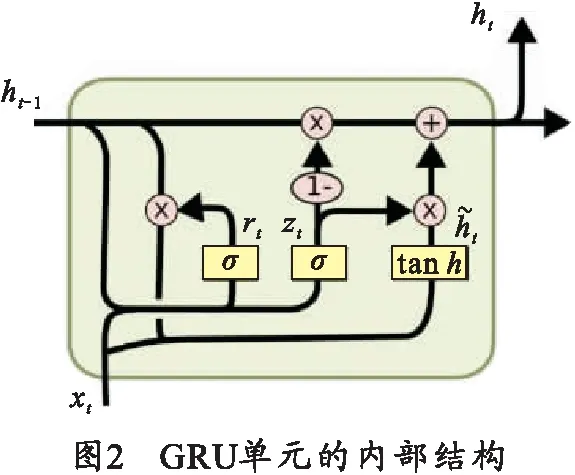
图2可表示为

(3)

zt=σ(Wzxt+Uzht-1+bz) ,
(4)
而当前时刻隐藏节点的候选值计算为
(5)
式中;xt为输入;σ为sigmoid函数;φ为tanh函数;⊙则表示逐元素(element-wise)相乘;rt表示重置门,其计算公式为
rt=σ(Wrxt+Urht-1+br).
(6)
式(4)~(6)中的Wz、Uz、bz、Wh、Uh、bh、Wr、Ur、br都是用于训练的权重矩阵。通过重置门和更新门两个门结构, GRU单元就具备了学习长距离信息的能力,改善了传统RNN网络结构训练时所带来的梯度消失或爆炸的难题。
1.3 双向 GRU网络
在处理中文的命名实体识别任务时,不仅需要文字序列左边的前文信息,同时也需要文字序列右边的后文信息。然而,单向的GRU网络只包含一层正向的隐藏层,仅能够利用输入序列的前文信息,并不能很好地处理两个方向的序列信息。因此,为了能够同时利用输入序列的前文信息和后文信息,笔者将采用双向GRU(BI-GRU)网络[22]作为模型的一部分来处理中文命名实体识别任务,BI-GRU网络的基本结构如图3所示。
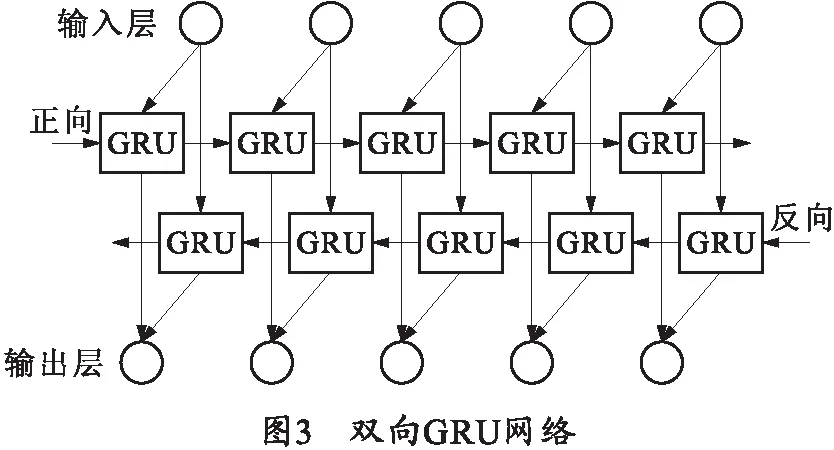
从图3中可以看出,双向GRU网络包含正向和反向两个隐藏层,并同时将这两个隐藏层都连接到了输出层。因此,在将文字序列输入到双向GRU网络中时,隐藏层可同时按照正向和反向两个方向处理序列信息,在输出层得到两个方向的联合信息。
1.4 BI-GRU-CRF模型
1.4.1 CRF模型
作为序列标注任务,命名体识别在预测最终的标签序列时,标签间的前后关系也十分重要,因此需要根据整条标记路径的分值情况来判断最终的标注结果。而CRF作为序列预测的一种概率模型,可以联合考虑相邻标签间的相关性而得到全局最优的标签序列作为结果,实现对整个标签序列进行预测,其结构如图4所示。

1.4.2 BI-GRU-CRF模型
BI-GRU-CRF模型就是将双向GRU网络与CRF层进行结合,在双向GRU网络的隐藏层后加入CRF层,其基本结构如图5所示。
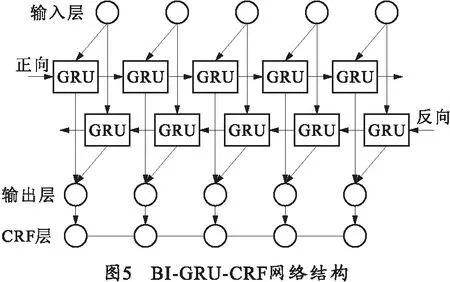
该模型可以有效利用双向GRU网络获取输入文本序列中的前后文信息作为特征,并通过CRF层对整个标签序列进行预测,实现对文本序列的最优标注。
在该网络模型中,对于给定的输入文本序列x={x1,x2,…,xn},以及待预测的标签序列y={y1,y2,…,yn},可定义
(7)
式中:p∈Rn×k为双向GRU层输出的概率矩阵;n为输入文本序列中汉字的个数;k为输出标签的种类,即pi,j表示第i个字被标记为第j个标签的概率;A为状态转移矩阵;Ai,j代表从第i个标签转移到第j个标签的概率,则标签序列为y的条件概率为
(8)
式中,Yx为所有可能的标签序列的集合,在训练中,则使用其似然函数:
(9)
通过式(10)可在预测时得到整体概率最大的一组标签序列:
(10)
2 词位字向量
2.1 字向量
将文本序列输入到标注模型的第一步是要将每个汉字转换为固定维度的实数向量,并将全部汉字与对应的向量储存到查找层的字典D中。通过这个字典D,文本序列在经过查找层后,就可以转换为对应的向量序列,可用于标注模型的训练。
目前,最为常用的是基于深度神经网络的字向量表示方法,该方法可通过多层的隐层网络对字的特征进行深层次的抽象,将每个汉字表示成一个低维的实数向量。这种方法不仅可以有效避免数据稀疏的问题,还可以较好地表示汉字之间的语义关系。文献[15]中处理多种自然语言处理任务时使用的就是一种基于深度神经网络语言模型的向量化表示方法,其主要思想是使用一个字的周围字来决定当前字的语义,从而将语义相近的字表示成向量空间中夹角较小的向量。文献[23]中提出了两种向量化表示方法,一种是使用周围字来预测当前字的连续词袋(continuous bag-of-words, CBOW)模型;另一种则正好相反,是使用当前字来预测周围字的连续skip-gram模型。对比3种语言模型,skip-gram 模型在解决数据稀疏问题时具有更好的效果,因此笔者将使用skip-gram模型在大规模语料上训练字向量。该模型在训练中的优化目标则是最大化训练语料的对数似然函数:
(11)
式中:k表示输入汉字时的窗口大小;xi+j及xj则表示训练语料中的汉字;概率p(xi+j|xj)可由公式(12)计算得到
(12)
式中:vxO及vxI表示对应汉字xO及xI的初始向量值;vx′则是输出向量值。
2.2 词位字向量
在军事领域的命名实体识别中,军事实体名称语法结构较为复杂,且名称较长,导致实体边界难以划分,识别性能有待提高。另外,中文里一字多音多义的现象繁多,单独使用字向量极易造成语义混淆。因此,笔者将每个字在军事词语中的词位信息融合到字向量中,形成词位字向量,用于模型训练,缓解了汉字在词语中位置不同导致语义不同的问题。
词位字向量包括两个部分:第1部分是使用skip-gram模型基于大规模中文维基百科语料与爬虫获取的军事领域语料联合无监督训练得到的字向量,维度为d;第2部分是基于军事领域语料分词结果采用独热编码得到的词位向量。由于字在词中的位置只有词的开头字符、词的末尾字符、词的中间字符及单独构成词的字符4种,所以维度为4,并不会造成数据稀疏的问题。然后将字向量与词位向量用首尾相接的方式进行拼接得到词位字向量,使用该向量作为输入,由笔者提出的BI-GRU-CRF模型进行训练,具体训练流程如图6所示。
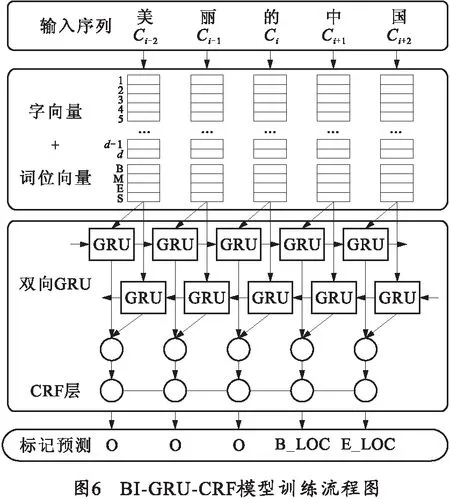
该模型通过查找操作将输入的文本序列映射为词位字向量序列,在训练中引入了每个字在军事词语中的词位特征。因此在军事领域的实体识别中,该模型可以利用词位字向量中蕴含的语言规律和语义知识来辅助军事实体的识别,以提升实体识别的性能。
3 命名实体识别实验
3.1 实验数据
由于目前还没有比较权威的军事领域语料库,因此笔者将采用网络爬虫技术收集中文百科网站中军事领域的相关文本作为实验语料,并对收集的文本进行特殊符号的处理、分词、人工标注等预处理,总共获得网络军事语料534 376字,并取其中80%作为训练语料,剩余20%作为测试语料。另外,笔者在爬取数据时考虑到网络百科页面具有一定的结构性,因此制定了一系列爬虫规则来预先获取一部分实体,降低了标注实体的成本。
针对军事领域主要定义了人名、军用地名、军事机构名、军职军衔、军事装备名、军用物资名、军事设施名7类实体,并采用“IOBES”标记方案对语料中的实体进行标记,具体标记方式如表1所示。
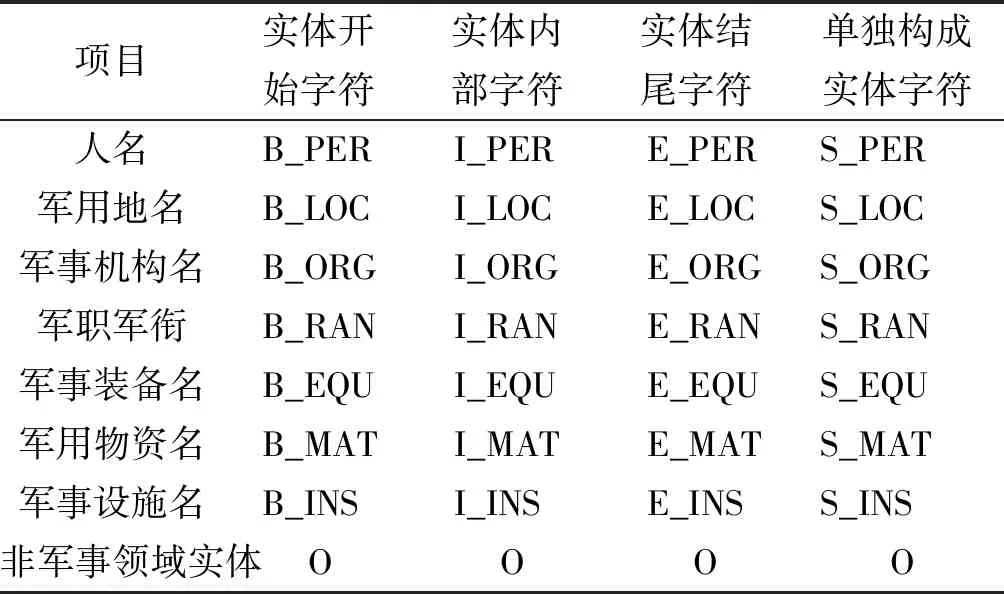
表1 军事领域实体标记方案
3.2 实验设置
为验证文中所提出的军事领域命名实体识别方法的性能,共设置了5个实验。
实验1:运用军事知识及语言规律等构建特征模板,并基于特征模板使用训练语料训练条件随机场模型,然后使用该模型在测试语料上进行命名实体识别,该实验标记为CRF.
实验2:使用由大规模语料无监督训练得到的字向量构造查找层字典D,然后使用训练语料训练BI-LSTM模型,并用该模型在测试语料上进行命名实体识别,该实验标记为BI-LSTM+CHAR.
实验3:使用由2.2节所提出的词位字向量构造查找层字典D,然后使用训练语料训练BI-LSTM模型,并用该模型在测试语料上进行命名实体识别,该实验标记为BI-LSTM+POSI.
实验4:使用由大规模语料无监督训练得到的字向量构造查找层字典D,然后使用训练语料训练所提出的BI-GRU-CRF模型,并用该模型在测试语料上进行命名实体识别,该实验标记为BI-GRU-CRF+CHAR.
实验5:使用由2.2节所提出的词位字向量构造查找层字典D,然后使用训练语料训练所提出的BI-GRU-CRF模型,并用该模型在测试语料上进行命名实体识别,该实验标记为BI-GRU-CRF+POSI.
在训练深度神经网络模型时的超参数设置如表2所示。另外,笔者在模型训练中还用到了防止训练过拟合的Dropout技巧、缓和梯度消失或梯度爆炸的梯度裁剪技巧以及改进GRU单元输出门的ReLU激活函数以提高模型的训练效果。

表2 超参数数值
3.3 实验结果分析
为了便于评估模型的识别性能,将采用SIGHAN规定的标准评估指标:准确率P,召回率R及F1值来对模型进行评估。其相应的计算公式如下:
(13)
(14)
(15)
在上述实验设置下的5个实验结果如表3所示。其中,表中所给出的准确率P、召回率R及F1值都是模型对各类命名实体识别效果的平均值。
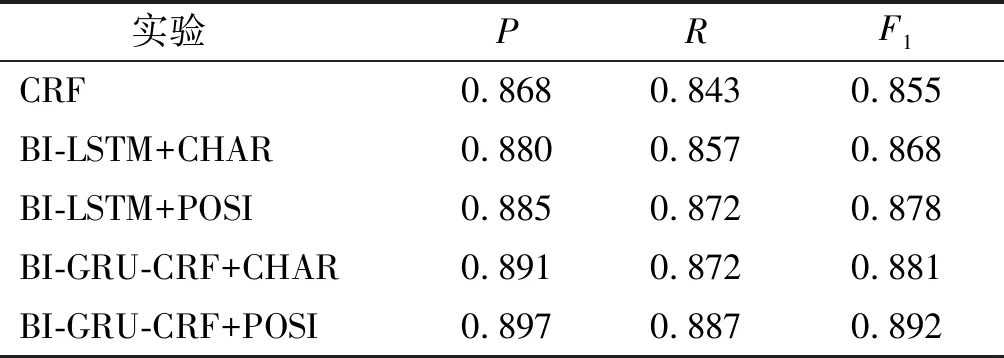
表3 不同模型对军事领域命名实体识别性能对比
对比分析表3中的实验结果可知,笔者所提出的BI-GRU-CRF模型以及词位字向量的方法对于提升军事领域命名实体识别的性能均有一定的效果,且可以有效避免人工构建特征集。结合使用BI-GRU-CRF模型与词位字向量的方法可以达到最好的效果,并且对军事领域实体的识别效果接近于通用领域。具体而言,对比实验4与实验5(或实验2与实验3)可知,使用笔者提出的词位字向量较基本字向量可以提升模型的识别性能,主要原因是词位字向量将字在军事词语中的词位信息引入到模型训练中,使模型学习到了一定的军事领域语言规律,可以更好地识别出语料中的复合词实体,提升了模型性能。对比实验2与实验4(或实验3与实验5)可知,使用笔者提出的BI-GRU-CRF模型可以更加有效地识别出军事领域实体,主要原因是该模型通过结合CRF层可以根据整条标记路径的分值情况来判断最终的标注结果,提升了模型的识别效果。
4 结束语
针对军事领域命名实体识别准确率不高的问题,笔者根据其语言特点,提出了一种融合词位字向量的命名实体识别方法。该方法利用词位字向量将字在军事词语中的词位信息引入到BI-GRU-CRF模型中进行训练,有效增加了输入向量的特征,并利用BI-GRU-CRF模型可较好完成序列标注任务的优势,高效完成了军事领域命名实体识别的任务。笔者在爬取的网络百科军事语料上对文中定义的人名、军用地名、军事机构名、军职军衔、军事装备名、军用物资名、军事设施名7类实体进行了命名实体识别,通过与其他命名实体识别模型以及基于基本字向量的方法进行对比,表明笔者所提出的方法可以较好地解决军事领域命名实体识别的问题。下一步将对如何进一步融合领域特征提高命名实体识别效果进行研究。
