基于半监督深度生成对抗网络的图像识别方法
2019-09-12向德华2宁2肖红光
曾 琦, 向德华2,李 宁2,肖红光
(1.长沙理工大学 计算机与通信工程学院,湖南 长沙 410114;2.湖南省计量检测研究院,湖南 长沙 410014)
Ian J.Goodfellow在2014年首次提出生成对抗网络(Generative Adversarial Networks,GAN)[1]的概念。GAN包括生成器(generator)与判别器(discriminator)两个组成部分,生成器与判别器之间是一种博弈对抗的关系,判别器的目标是正确区分真实样本与生成的伪样本,而生成器的目标则是输出的伪样本能够使判别器做出误判。两者经过博弈对抗之后达到纳什均衡[2],生成拟合真实数据的样本。GAN目前应用十分广泛,如图像识别、图像超分辨率[3]、灰度图像上色[4]、通信加密[5]、图像合成[6]、根据文字生成图片[7]等领域。在图像识别领域,基于GAN的方法[8]虽然拥有很高的识别率,但与传统有监督学习方法如卷积神经网络一样需要使用大量有标签样本进行训练。在面对某些情况时这个问题影响了图像识别效果,例如在进行医学图像分析时,虽然能够采集大量样本,但是需要富有经验的医生进行样本标注,不仅费时费力而且浪费了无标签样本中的有效信息。针对这个问题,本文结合半监督生成对抗网络[9](Semi-Supervised Generative Adversarial Networks,SSGAN)与深度卷积生成对抗网络[10](Deep Convolutional Generative Adversarial Networks,DCGAN)建立半监督深度生成对抗网络模型(Semi Supervised Deep Convolutional Generative Adversarial Networks,SS-DCGAN)。SS-DCGAN使用有标签样本和无标签样本进行训练,并且使用深度卷积网络作为生成器与分类器。训练后抽取模型的分类器部分用于图像识别,实验结果表明,该方法仅使用少量有标签样本即可达到与其他图像识别方法同水平的识别率,解决了有标签样本数量较少的情况时识别效果不佳的问题。
1 生成对抗网络原理
生成对抗网络模型由生成器和判别器两个部分组成,生成器根据随机噪声生成伪样本,判别器判断输入数据真伪。生成器和判别器是能够实现生成样本和判别真伪的映射函数模型,如多层感知器。生成对抗网络的模型流程图如图1所示。
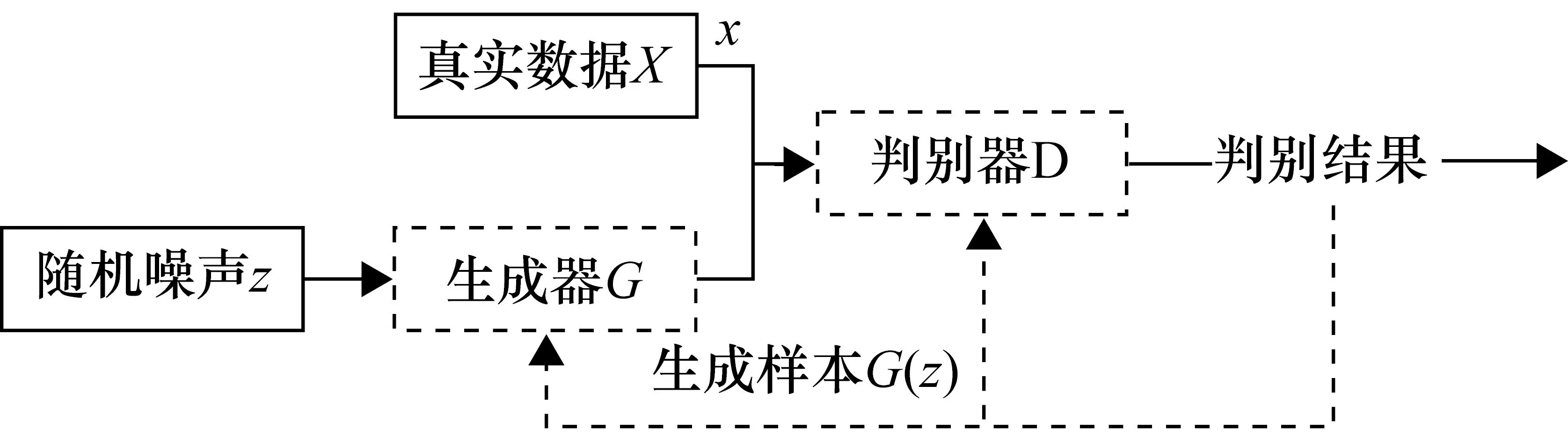
图1 GAN流程图
在生成器和判别器的博弈对抗中,生成器根据随机噪声z生成拟合真实数据Pdata的伪样本G(z),G(z)和真实数据x一起输入判别器,判别器输出判别结果D(x)和D(G(z)),即输入数据判别为“真”的概率。判别器得到判别结果后最小化实际输出和期望输出的交叉熵,而生成器通过判别器反馈最大化伪样本判别为“真”的概率D(G(z)),此时生成器与判别器完成了一次优化更新。但为了使生成器和判别器维持同水平博弈对抗,避免判别器过快达到最优解使模型无法收敛,生成器与判别器的优化更新频率并非同步的,生成器更新几次之后判别器才更新一次。经过博弈对抗生成器与判别器达到纳什均衡,此时D(G(z))=0.5,生成的样本拟合真实数据分布。
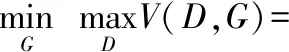
Ez~Pz(z)[log(1-D(G(z)))]
(1)
2 半监督生成对抗网络
半监督生成对抗网络(SSGAN)是2016年OpenAI提出的一种GAN改进模型。原始GAN训练时使用无标签样本,生成没有类别信息的样本,与之相比SSGAN使用有标签样本和无标签样本共同训练并生成带有类别信息的样本[9],也因此需要将GAN的判断器替换为多分类器。
SSGAN模型的流程图如图2所示。随机噪声z通过生成器生成的伪样本G(z)与k类有标签样本xl和无标签样本xu输入分类器,输出k+1维分类结果。前k维输出代表对应类置信度,第k+1维代表判定为“伪”的置信度。
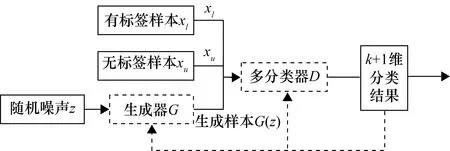
图2 SSGAN流程图
3 深度卷积生成对抗网络
深度卷积生成对抗网络(DCGAN)由Alec Radford在2015年提出。DCGAN引入深度卷积网络作为GAN的生成器和判别器,利用其强大的特征提取能力提升了GAN模型的表现[11]。
DCGAN与GAN比较做出了以下改变[10]:
① 分别用步幅卷积(Strided Convolutions)和微步幅卷积(Fractional-Strided Convolutions)替换了判别器和生成器中的池化层。
② 在生成器和判别器上使用了批量归一化(Batchnorm)。批量归一化可以解决初始化差的问题并在进行最小化交叉熵时将梯度传播到每一层,
③ 除了输出层使用Tanh(双曲正切函数)激活函数,生成器所有层都使用ReLU(Rectified Linear Unit)激活函数。判别器所有层都使用Leaky ReLU(Leaky Rectified Linear Unit)激活函数。
4 基于半监督深度生成对抗网络的图像识别
结合SSGAN模型和DCGAN模型的特点,建立半监督深度生成对抗网络模型(SS-DCGAN)。SS-DCGAN引入深度卷积网络作为生成器和分类器,与其他有监督学习算法只使用有标签样本不同,SS-DCGAN训练时还使用无标签样本。
图3为无标签样本在分类中的作用。其中黑白色点代表有标签样本而灰色点代表无标签样本,虚线代表分类面。如果在训练时只考虑有标签样本则会得到垂直的分类面,而考虑无标签样本之后分类器可以通过样本整体分布得到更为准确的分类面。
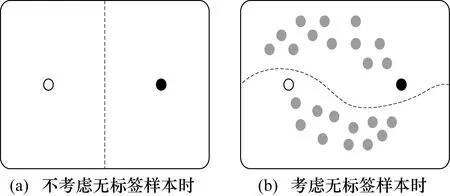
图3 无标签样本在分类中的作用
在进行训练时,无标签样本虽然没有类别信息,但是无标签样本的分布有助于学习数据的整体分布,帮助分类器更加准确分类。根据真实数据的整体分布,模型利用深度卷积网络强大的特征提取能力生成拟合真实数据分布的伪样本,这些样本和真实数据共同输入并训练分类器,增加了训练样本个数。经过足够多样本训练后,分类器拥有很高的识别率。抽取训练好的模型中分类器部分优化调整后即得到用于图像分类的网络结构。
4.1 SS-DCGAN模型结构
SS-DCGAN引入7层和9层的深度卷积网络作为生成器和分类器。
SS-DCGAN的生成器模型如图4所示。生成器是一个7层的转置卷积网络,包括2层全连接层和5层转置卷积层。100+k维随机噪声z首先通过2层全连接层进行维度转换,其中k为类别数,然后经过5层转置卷积层进行反卷积转换,最后输出一个m×n×p的张量,即生成的图像样本。其中m×n代表图像分辨率,p代表图像通道数。
分类器的模型如图5所示。分类器为一个9层的卷积网络,包括2层全连接层和7层卷积层。m×n×p的图像样本首先经过7层卷积层进行特征提取,然后利用2层全连接层对卷积层提取的特征信息进行整合,最后输出k+1维分类结果。前k维输出为对应类的置信度,第k+1维为判定为“伪”的置信度。

图4 SS-DCGAN生成器结构

图5 SS-DCGAN分类器结构
4.2 SS-DCGAN模型训练
SS-DCGAN使用部分有标签样本和较多的无标签样本共同进行训练,训练的过程实质上为生成器与分类器之间的博弈对抗。在生成器和分类器的博弈对抗中,分类器最小化实际输出和期望输出的交叉熵,而生成器通过判别器反馈最大化伪样本判别为“真”的概率D(G(z)),此时生成器与判别器完成一次优化。经过多轮反馈和更新后,生成器和分类器达到纳什均衡,此时生成的伪样本拟合真实数据分布,分类器识别率最高。抽取训练后模型的分类器部分经过优化调整即得到用于图像识别的网络结构。
模型的损失函数如式(2)[9]所示,由两部分组成,前两项对应真实数据的损失函数,后半部分对应生成样本的损失函数。使用Adam(Adaptive Moment Estim-Ation)优化器最小化损失函数,对生成器和分类器进行优化更新。
L=-Ex,y~Pdata(x,y)[logPmodel(y|x)]-
Ex,y~Pdata(x,y)[1-logPmodel(y=K+1|x)]-
Ex~G[logPmodel(y=K+1|x)]
(2)
4.3 基于SS-DCGAN的图像识别
将训练之后得到的SS-DCGAN模型用于图像识别。如图6所示,将训练好的SS-DCGAN中的分类器部分抽取出来,因为第k+1维输出是判定为“伪”的置信度,所以忽略第k+1维中间输出后将剩余部分输出连接Softmax层,最终得到k维输出,对应输入图像在k个分类上的置信度。

图6 SS-DCGAN图像分类结构
5 实验结果与分析
在MNIST和CIFAR-10两个公开数据集上进行了图像识别实验。实验环境为 Intel®CoreTMi7-7700k CPU@ 4.2 GHz处理器,16 GB运行内存,Nvidia GeForce GTX 1080 GPU,TensorFlow框架。
5.1 MNIST实验
MNIST数据集是目前应用最广泛的手写字符数据集,包含70000张0~9的灰度图像。其中60000张为训练样本,10000张为测试样本。在使用图像样本进行训练之前要进行归一化处理将图像数据限制在一定的范围,这样能在训练时收敛得更快。而对于标签数据进行独热编码方便计算交叉熵。
训练时,为了保持分类器和生成器的对抗平衡性,避免分类器过早达到最优解使模型无法收敛,将分类器和生成器的更新频率之比设置为1∶3。对于有标签样本数量设置4个不同的值,对比使用不同有标签样本数时图像识别的准确率。为了保证准确性,通过随机抽样同时构建10个样本集进行实验,实验结果取平均值。
5.1.1 MNIST生成样本
SS-DCGAN模型在训练MNIST样本时选择Adam优化器,学习率设置为0.0001,动量为0.5,批处理量为32。
图7为SS-DCGAN在MNIST数据集上分类器损失函数随训练次数增加而变化的情况。

图7 MNIST上d_loss变化趋势
图8为SS-DCGAN在MNIST数据上生成器损失函数随训练次数增加而变化的情况。

图8 MNIST上g_loss变化趋势
从图7和图8中可以看出生成器的损失函数总体上呈上升趋势,而分类器的损失函数呈下降趋势。在训练初期两者曲线较为平滑,随着训练次数的增加,生成器和分类器对抗引起损失函数曲线大幅振荡。
图9为生成样本随训练迭代次数增加而产生的变化。可以看到在训练初期生成的样本为模糊的灰度图像,不具备手写数字特征。经过15次迭代后图像上有了较为明显的特征,而在第25次迭代后得到了拟合真实数据分布的手写数字图像。

图9 MNIST生成样本
5.1.2 MNIST分类结果
表1为MNIST上SS-DCGAN模型使用20、50、100、200个有标签样本的识别率与其他方法使用60000个样本进行训练的识别率对比[8,12-14]。模型训练共耗时4 h 27 min,图像识别速率为13张/s。

表1 MNIST上各方法识别率对比
在使用200个有标签样本训练时,本文方法的识别率已经超过Linear Classifier[14]、KNN[12](K-NearestNeighbor)、ADGM[13](Auxiliary Deep Generative Model)、DCNN[8](Deep Convolutional Neural Networks),略低于C-DCGAN[8](Conditional Deep Convolutional Generative Adversarial Networks)。
C-DCGAN训练时需要60000个样本,与之相比,SS-DCGAN虽然识别率略低,但训练时仅使用200个有标签样本,其余样本为无标签样本即可达到与C-DCGAN同水平的识别率,可以节约大量用于样本标注的人力与时间。实验结果表明,SS-DCGAN解决了有标签样本数量较少时识别效果不佳的问题。
5.2 CIFAR-10实验
CIFAR-10数据集是由 Alex Krizhevsky,Vinod Nair和Geoffrey Hinton收集的10分类数据集,包含60000张32×32彩色图像,其中50000张为训练样本,10000张为测试样本。使用数据前需要进行归一化处理将图像数据等比例限制在一定范围内。标签数据需要进行独热编码。使用图3结构作为生成器,图4作为分类器组成SS-DCGAN模型,考虑到CIFAR-10数据集样本的特点,分类器和生成器更新频率之比设置为1∶4。训练时有标签样本数量设置4个不同的值,对比不同有标签样本数时图像识别的准确率。为了保证准确性,通过随机抽样同时构建10个样本集进行实验,实验结果取平均值。
5.2.1 CIFAR-10生成样本
SS-DCGAN模型在训练CIFAR-10样本时选择Adam优化器,学习率设置为0.0002,动量为0.5,批处理量为32。
图10和图11分别表示分类器和生成器损失函数随训练次数变化。
从图10和图11中可以看出生成器和分类器损失函数前期相对平滑,随着训练次数增加生成器损失函数呈上升趋势而分类器损失函数呈下降趋势并且两者都表现出大幅振荡。
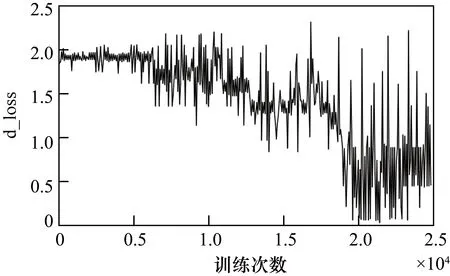
图10 CIFAR-10上d_loss变化趋势

图11 CIFAR-10上g_loss变化趋势
图12为生成样本随训练迭代次数增加而产生的变化。在训练初期生成的样本为模糊的彩色条纹,在第100次迭代后图像上有了较为明显的特征,而在第300次迭代后得到了拟合真实数据分布的图像样本。

图12 CIFAR-10生成样本
5.2.2 CIFAR-10分类结果
表2为CIFAR-10上SS-DCGAN模型使用1000、2000、4000、8000个有标签样本训练的识别率与1L K-means(1 Layer K-means)、3L K-means(3 Layer K-means)、Cudaconvnet、C-DCGAN((Conditional Deep Convolutional Generative Adversarial Networks))、VI K-means(View Invariant K-means)五种方法[8,15-16]使用50000个样本进行训练的识别率对比。模型训练共耗时5 h 43 min,图像识别速率为9张/s。
由表2可知,在使用4000个有标签样本训练时,SS-DCGAN的识别率已经超过其他图像识别方法。实验结果表明,该方法有效解决了有标签样本数量较少的情况时识别效果不佳的问题。
6 结束语
结合半监督生成对抗网络模型和深度卷积生成对抗网络模型提出半监督深度生成对抗网络模型(SS-DCGAN)并抽取分类器部分用于图像识别。SS-DCGAN模型使用有标签样本和无标签样本进行训练,根据真实数据的整体分布,模型利用深度卷积网络强大的特征提取能力生成拟合真实数据分布的伪样本,这些伪样本和真实数据共同输入并训练分类器,提升了识别率。将SS-DCGAN模型用于图像识别,并在MNIST和CIFAR-10两个公开数据集上进行了实验。实验结果表明,SS-DCGAN模型仅用少量有标签样本即达到了很高的识别率,有效解决了有标签样本数量较少的情况时识别效果不佳的问题。
