DEA模型在地区对外贸易量分析上的应用分析
2019-09-10李慧慧
李慧慧











摘要:本文提出用于多决策单元(Multiple Decision Unite,MDU)数据包络分析(l)ata Envclope Analysis,DEA)的一次性模型。假设论域中有多个决策单元,其具体按年度划分的有多个输入向量和输出向量。本文提出的一次性模型可以通过一次建模求解出所有DMU在各个年度中的DEA效率。相对于传统的DEA模型需要针对每个决策单元和每个年度的单独建立模型,本文方法具有高集成度和高效率的特点。本文利用MLCap建模语言对提出的一次性模型进行表达,并作为案例将其应用于地区对外贸易量的分析上。算例表明,本文提出的方法在相关研究中具有一定的参考价值。
数据包络分析(Data Envelopment Analysis),简称DEA,是数理经济学、运筹学、管理科学三者交叉研究的一个领域,曾被广为研究和使用,目前可以看作是一个成熟的方法。DEA是一种数理方法,用于评价那些能够用数字表达的多组织(也称多决策单元,MDU),且每个对象有多输入、多输出的绩效评价。DEA方法在多组织(多输入、多输出)的评价上具有绝对优势。目前,DEA方法在多个领域的评价分析方面都得到了广泛的应用[2-4]。在近30年的研究中,DEA方法发展出了多种类型的数学模型,其中线性模型更容易实现大规模求解,多篇文献[6-7]在DEA研究上也采取线性模型。本文主要针对DEA中C2R对偶输入模型(即以最小的投入实现指定量的产出)的整数规划模型改进展开研究。
具体的DEA适用的问题可以被简单表述为:假设有m个组织(编号:k=l,…,m),每个组织有r项投入(编号:i=l,…,r).s项产出(编号:j=l,…,s),需要对每个组织的投入/产出效率作出相对评价。方法要求所有的投入和产出都能够被量化表达,且隐含了对S项产出来说,其值越大越正向影响该组织的效率评价;且对r项投入来说,其值越小则越正向影响该组织的效率。
经典的DEA模型要求针对某个特定组织k分析其DEA效率ek.,将第k(k=l,…,m)个组织的输入和输出分别表示为X和y,则模型可以被表达为以下线性规划模型:
式(1)中的ak是DEA方法引入的决策变量,其含义可以被理解为对组织K’输入所做的凸组合拆分。求解上式即得到组织K’的DEA效率ek.。若ek.=l,则说组织K’是DEA有效的,或者可以不严格地说组织后,的相对效率是l00%。若ek,<1,则说组织K’非DEA有效,或者可以不严格地说组织K’的相对效率仅有ek ,XlOO%。
采用式(1)进行分析时,必须对重复m次,即对K’=1,..,,m的每种情况都单独建模并求解。假设需要评价多年度的相对绩效,即当Xki和Yki是分年度给出的若干组数据,则需要更多的模型和求解次数。针对这个问题,本文提出一种可以一次建模并求解出所有DMU在各个年度中DEA效率的方法,并作为案例将其运用于地区对外贸易量的分析上。该方法相比与传统的模型(1)具有集成度好和效率高的特点。
在其后本文将在第1节中定义多年度多组织的DEA问题,并给出对该问题的一次性模型;在第2节中介绍本文模型基于Leap语言的机器表达方式;第3节给出算例求解和分析;第4节给出本文的结论。
1 问题及模型
1.1 经典DEA问题的一次性求解模型
模型(1)是经典DEA问题常用模型。其缺点是需要对每个组织后’=1,…,m都单独建立模型并求解,总计建模和求解m次。本文提出使用以下模型完成对经典DEA问题的一次性求解:
式(2)中的变量是DEA方法中的决策变量,其含义可以被理解为对组织k’输入所做的凸组合拆分。求解模型(2)将一次得到所有组织的DEA效率值ek.(尼’=1,...,m),即有以下简单定理。
定理1:求解模型(2)将一次得到所有组织的DEA效率值ek,(K’=1,…,m),其结果与多次求解模型(l)所得到的效率值ek,一致。
证明:因模型(2)中每个ek.(K’=1,…,m)所承受的约束互不干扰且等同于模型(1),并且其总体目标是ek.(K’=1,…,m)之和最小,因此模型(2)的ek.(K’=1,¨.,m)最优值与模型(1)的ek.(K’=1,…,m)最优值一致。
1.2 多时间段DEA问题的一次性求解模型
经典的DEA问题只涉及单时间阶段数据,即所有DMU的数据都是一个时间阶段发生的,问题的要求也是评价该时间阶段的相对效率。
本文讨论的问题是一个多时间阶段的DEA问题:有m个组织(编号:k-l,…,m),每个組织有NI项投入(编号t一1,…,NI)、NO项产出(编号:r一1,-NO),已知各个组织在n个年度的投入数据Xtk(t=1,…,NI,k=l,…,m,i=l,…,n)和产出数据Yrkj(r=1,…,NO,k=l,…,m,j=l,…,n),请相对评价各个年度每个组织的投入/产出效率。
显然多时间段的DEA问题可以分别针对不同年度多次使用模型(l)或模型(2)完成求解,但是这种方法较为繁琐。本文提出使用以下模型一次求出各个组织在不同年度的DEA效率值:
一次求解模型(3)与多次求解模型(2)将得到相同的效率值,
其原因在于ek.i(k’=1,…,m,i=l,…,,n)在模型(3)的目标和约束中都是可分解的,且模型(3)所表达的约束与模型(2)所表达的约束一致。
定理2:求解模型(3)将一次得到所有组织在各个年度的DEA效率值ek.i(k’=1,…,m,i=l,…,,z),其结果与多次分别求解模型(l)或模型(2)所得到的效率值ek,,一致。
证明:观察模型(3)中的任意ek,,,其在目标和约束中均与其他ek。f.(k”≠k’,f’≠i)无关,且任意ek.f所承担的约束均与模型(2)中的相同,因此上述定理成立。
1.3 一次性求解模型的求解效率问题
注意到模型(3)将比模型(2)和(1)引入更多地变量和约束。一般,具有更多约束和变量的模型在求解时会更困难些。但是对现代数学规划求解器来说,对大规模模型都会进行模型分解预处理。对这种处理器来说,模型(3)是一个非常容易处理的可分解模型,因此其求解效率基本等同于多次重复求解模型(1)。
2 模型的MLeap表达
为获得模型(3)的解,需要首先通过一种建模语言将其表达给机器,而后使用求解器得到所需要的结果。本文采用MLeap建模语言实现这一过程。MLeap语言是本文作者所设计的一种数学规划模型的描述型建模语言。MLeap语言具有很强的描述性(与过程性相对,即不需要任何模型展开和求解过程,只需将模型描述出来即可),基本上只需将数学模型写成文本形式即可,具体如图1所示。
和约束段(subject to)的表达方式基本与传统整数规划的建模语言相同。不同的是,MLeap建模语言新增了标识符声明(where),该部分需要明确表明模型中出现的标识符是变量或者常量,并且声明其数据类型以及范围。Data部分是MLeap建模语言中的数据表达部分,主要用来对已经声明的常量进行赋值操作方便计算。MLeap表达中的“一”符号表示换行符,用于连接上一行与下一行的文本内容。
由于模型(3)中的已知常量Xtki和yrkj的赋值矩阵较大,不方便表述,故图1中Data部分对常量Xtki和yrkj的赋值过程未给出。
3 算例求解与结果分析
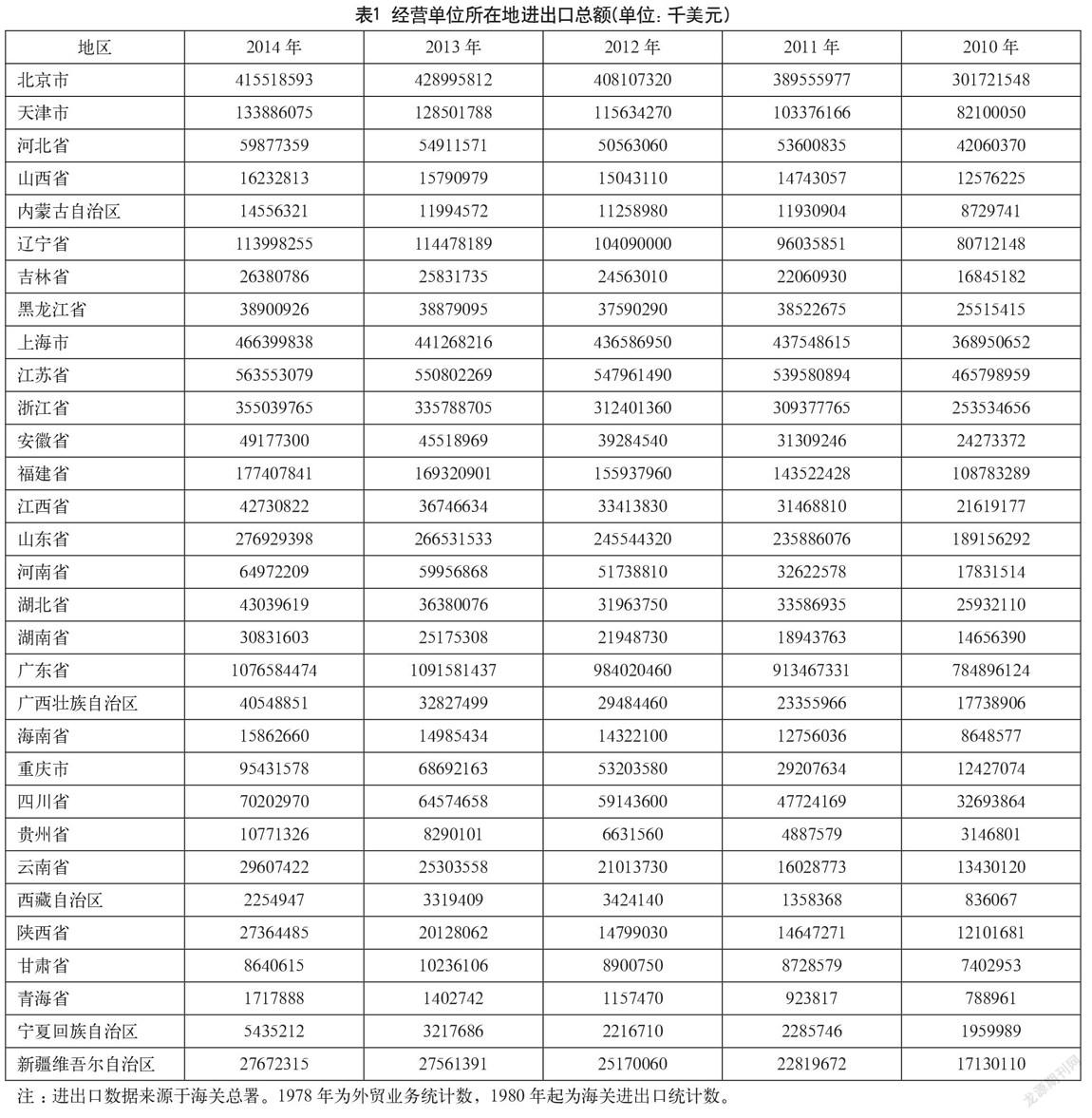
为验证模型的有效性,本文采用国家统计局从2010—2014年分省年度数据带入模型中进行计算验证。主要研究各省的各指标对该省的进出口总额(千美元)的相对效率。经过初步的判定,确定影响各省进出口总额的指标有:消费价格指数、消费零售总额、地区生产总值、可支配收入、固定资产投资、城镇单位就业人员、高等学校数与地级以上城市数。
具体计算中,将确定影响各省进出口总额的8个指标作为模型(3)的输入Xtki,将进出口总额作为模型输出Yrkj。各省各年度进出口总额入的具体数据如表1所示。
由于本文篇幅有限,输入8个指标的各年度数据不能一一展示。但本文的所有数据来源都来自干中华人民共和国国家统计局的官方网站的地区统计数据,可查阅到文中引用指标的具体相关数据。
3.1 算例求解与结果分析
经过MLeap对模型(3)的展开,总变量数为4960个,总约束数为1550个。由于模型展开的变量数较多,采用MLeap内部求解器求解时间成本较高,故调用Cplex12 63版本求解器求解,求解时间小于1秒得出结果。
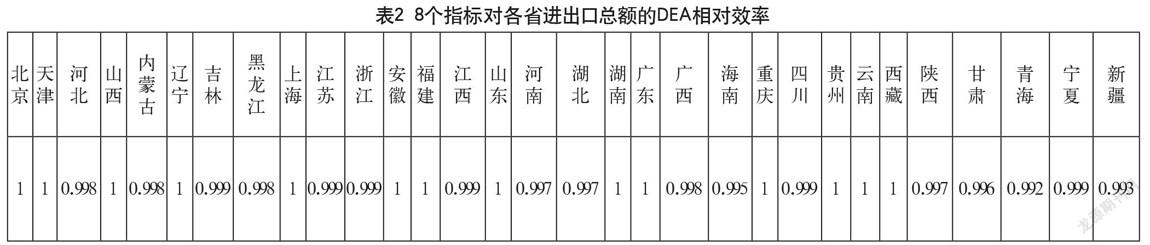
表2是经过近似取值后的结果。对表2的结果数据分析发现,各省的DEA相对效率都为1,意味着各省从2010 2014年期间我们选中的8个指标相对进出口总额的投入/产出效率达到了近似最优的分配。但对输入8个指标中各指标对输出的影响还需要继续探究。
为对输入8个指标中各指标影响力的继续探究,产生猜测:在各省DEA输入数据中,其中某一项或者某几项指标相对输出指标的DEA效率极大(DEA效率接近于1)。在众多指标中的显著性很强,从而导致一次求解结果的各省DEA效率接近于1。
3.2 逐次剔除指标求解结果及分析
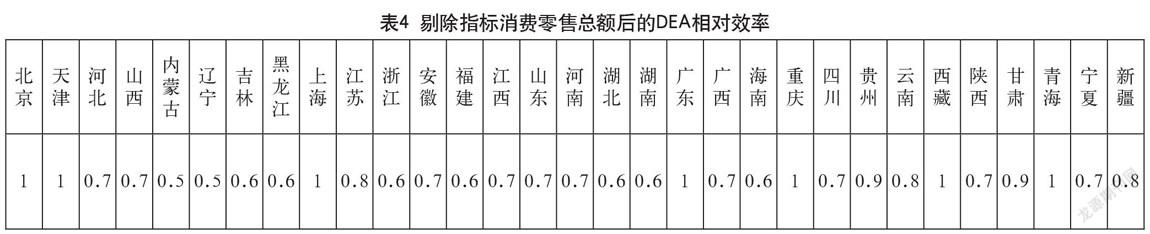
针对3 1节中的猜测,本次求解策略采用分批次求解,即每次剔除一项指标以进行检验。其指标的剔除顺序为:消费价格指数、消费零售总额、地区生产总值、可支配收入、固定资产投资、城镇
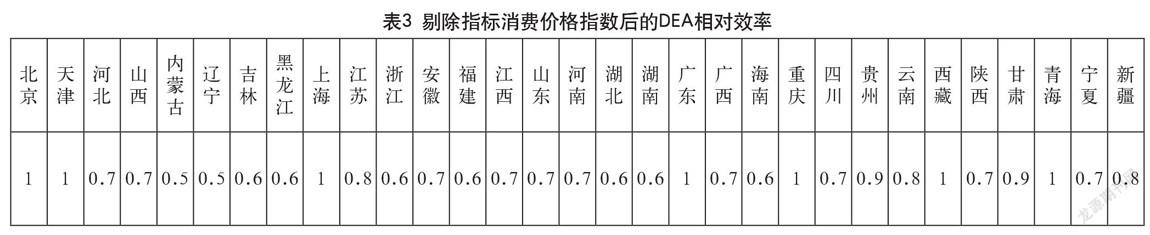
单位就业人员和高等学校数。再次调用Cplex12 .63对模型分批次进行求解,每次求解都能迅速得到结果(小于1秒),求解结果如表3-表9所示。
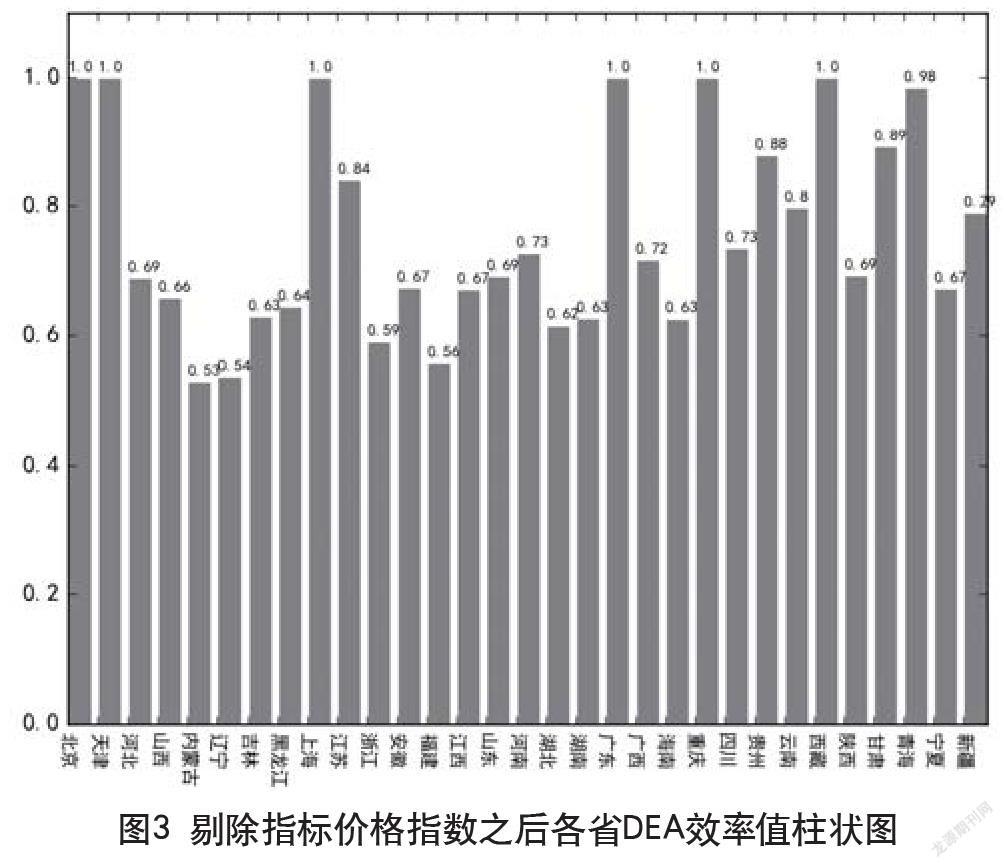
经过批次计算与对各批次结果对比分析,发现在剔除指标价格指数后各省的DEA效率值波动最大。由此可以判定在众多的输入指标中,消费价格指数对进出口总额的显著性最强。而在剔除价格指数之后,显著性较强的指标依次为:可支配收入、城镇单位就业人员、高等学校数。具体如图2、图3所示。
通过以上指标显著性的分析,基本可以得出结论:对一个地区进出口贸易总额起到显著影响的是该地区的消费价格指数和总体居民购买力的强弱。
对求得结果按照城市整理分析,发现各指標下的相对DEA效率最高(剔除各指标阶段下DEA效率值仍为1)的地区基本为发达城市或省份,分别为:北京、上海、天津、重庆、广东。该结果即意味着对于上述发达城市或地区,消费价格指数、消费零售总额等输入判别指标相对于输出的判定指标(进出口贸易总量)来说,其输入中的各项指标的资源分配已经达到了相对最优状态。
由于本文篇幅有限,与上述结果相关的图,文中未全部给出。其中北京市具体如图4所示。
4 结语
本文给出了多时间段DEA问题的一次性求解模型,该模型可以一次建模求解出所有DMU在各个年度中的DEA效率。相对于传统的DEA模型需要针对每个决策单元和每个年度的单独建立模型,本文方法具有集成度更好和效率高的特点。
本文采用MLeap建模语言对数学模型给予机器表达,最后调用外部求解器对其进行求解。其中算例求解的数据来自于国家统计局的官方网站的地区统计数据。算例对消费价格指数、消费零售总额等8个指标相对于进出口总额的DEA效率值进行了计算,并采用逐次剔除指标求解的方式判定出了输入各指标的显著性影响。最后得出了一定有意义的结论,其在地区对外贸易量分析上有一定的指导意义。
