基于一维卷积混合神经网络的文本情感分类
2019-09-04陈郑淏冯翱何嘉
陈郑淏 冯翱 何嘉


摘 要:针对情感分类中传统二维卷积模型对特征语义信息的损耗以及时序特征表达能力匮乏的问题,提出了一种基于一维卷积神经网络(CNN)和循环神经网络(RNN)的混合模型。首先,使用一维卷积替换二维卷积以保留更丰富的局部语义特征;再由池化层降维后进入循环神经网络层,整合特征之间的时序关系;最后,经过softmax层实现情感分类。在多个标准英文数据集上的实验结果表明,所提模型在SST和MR数据集上的分类准确率与传统统计方法和端到端深度学习方法相比有1至3个百分点的提升,而对网络各组成部分的分析验证了一维卷积和循环神经网络的引入有助于提升分类准确率。
关键词:情感分类;卷积神经网络;循环神经网络;词向量;深度学习
Abstract:Traditional 2D convolutional models suffer from loss of semantic information and lack of sequential feature expression ability in sentiment classification. Aiming at these problems, a hybrid model based on 1D Convolutional Neural Network (CNN) and Recurrent Neural Network (RNN) was proposed. Firstly, 2D convolution was replaced by 1D convolution to retain richer local semantic features. Then, a pooling layer was used to reduce data dimension and the output was put into the recurrent neural network layer to extract sequential information between the features. Finally, softmax layer was used to realize the sentiment classification. The experimental results on multiple standard English datasets show that the proposed model has 1-3 percentage points improvement in classification accuracy compared with traditional statistical method and end-to-end deep learning method. Analysis of each component of network verifies the value of introduction of 1D convolution and recurrent neural network for better classification accuracy.
Key words: sentiment classification; Convolutional Neural Network (CNN); Recurrent Neural Network (RNN); word embedding中文關键词为词矢量,此处是否应该为word vector?请明确。回复:词向量是word embedding的常用翻译,可不做修改; deep learning
0 引言
随着互联网和社交媒体的蓬勃发展,网络用户不再局限于浏览信息,更多的人开始表达自己的观点,分享知识并创作内容。互联网中出现了大量用户产生的信息,例如对热点新闻事件的讨论、对特定商品的评价、对电影的评分等,这些评论信息都包含了各种复杂的情感色彩或情感倾向,如赞同、否定和喜怒哀乐等,企业、机构或个人希望整合这些带有主观色彩的评论,来解析和跟踪大众舆论对于某一对象或某一事件的看法。对主观评论的分析在业界被广泛应用于股票价格预测、产品分析、商品推荐等领域,在政府部门常常被应用于舆情监测、民意调研、异常检测等方面。
由于网络上这类评论信息激增,仅靠人工难以在海量的非结构文本数据中收集和挖掘出有价值的情感信息,因此需要设计情感分析算法,利用计算机来帮助用户快速、有效地获取对于某一对象的情感倾向,这就是情感分析(Sentiment Analysis)的主要任务[1-2]。本文研究的是语句级情感分析,即通过算法判断给定句子的情感倾向,对应于机器学习领域的文本分类问题。
深度学习逐渐成为一种性能优异的主流机器学习方法,它通过学习数据的多层特征表示,在很多领域取得优于传统方法的结果。近年来,随着深度学习在图像处理、机器翻译等领域的成功,深度学习也被用于文本情感分类任务中。卷积神经网络(Convolutional Neural Network, CNN)是一种常见的多层神经网络,由于能够有效地捕获时间和空间结构的相关性,被广泛应用于计算机视觉和自然语言处理等领域。在文本情感分类任务中,CNN逐渐取代传统基于文本统计信息的机器学习方法,成为主流模型之一。
目前,基于CNN的文本情感分类方法大多是利用文本局部的最大语义特征进行情感极性判别[3]。Kim[4]提出的CNN模型是较为经典的一种,它通过二维卷积获取文本N-grams特征,再经过最大池化层筛选出最显著的语义特征,使用全连接层组合多个特征来判断情感倾向。然而,对输入文本使用二维卷积会压缩特征图(Feature Map)的维度,损失大量原始文本中的语义信息。从语言学的角度理解,该模型仅从文本中挖掘出包含情感的关键词或词组,对关键词或词组赋予不同的权重来判断情感倾向,并未考虑文本的语序结构。
针对上述CNN模型的缺陷,本文提出了一种基于一维卷积神经网络和循环神经网络(Recurrent Neural Network,RNN)的混合模型。首先,使用一维卷积替换二维卷积来提取文本特征,在获取文本N-grams特征的过程中保持特征维度不变,将语义信息的损失降到最低。其次,通过RNN获取高层特征之间的时序关系,理解文本的全局语义。相比文献[4]的CNN模型,该混合模型具有更强的特征提取能力,且提取到的特征维度更高,种类更丰富。实验结果表明,该模型在多个标准数据集上的情感分类性能相比传统统计方法和主流端到端深度学习模型均有明显的提升。本文还在该模型的基础上,对不同网络层的特征提取模式进行改进,对比多种网络结构的效果,验证了一维卷积在文本情感分类任务上的有效性。
1 相关工作
1.1 传统情感分类方法
传统的情感分类方法主要分为基于情感词典和基于机器学习的方法[5]。
1.1.1 基于情感词典的分类方法
该方法主要通过构建情感词典以及一系列的规则来判断文本的情感极性。Kim等[6]使用已有的情感词典,根据词语的情感得分加和的方法来判断文本的情感极性。Turney[7]利用点互信息方法扩展正面和负面的种子词汇,使用形容词种子集作为语句中词的评分,根据多个固定的句式结构来判断语句情感倾向。Hu等[8]通过词汇语义网WordNet的同义词、反义词关系,得到形容词情感词典,并根据该词典与一些简单规则判断语句的情感极性。这类方法严重依赖情感词典的质量,并且词典的维护需要耗费大量的人力物力,随着新词的不断涌现,己经不能满足应用需求。
1.1.2 基于机器学习的分类方法
该方法首先从文本中筛选出一组具有统计意义的特征,然后使用机器学习算法构建分类模型判断文本的情感极性。Pang等[9]最早使用机器学习方法对电影评论进行情感极性判别,对比了朴素贝叶斯(Nave Bayes, NB)、最大熵(Maximum Entropy, ME)和支持向量机(Support Vector Machine, SVM)这三种机器学习算法在情感分类中的效果。Mohammad等[10]在Pang等[9]的方法基础上,加入通过情感词典构建的特征,取得了更高的分类准确度。Kim等[11]引入词汇、位置和评价词作为特征,使用SVM作为分类模型进行情感极性判别。这类方法对不同的数据集选取不同的人工特征,模型泛化能力差,而且特征大多来自于文本的个别词汇统计数据,无法体现词语间的关系以及上下文信息[12]。
1.2 基于深度学习的情感分类方法
在文本表示方面,Bengio等[13]最早提出用神经网络学习语言模型,训练得到词在同一个向量空间上的表示,与one-hot表示方式相比维数大幅度降低。由于该模型参数较多,训练效率低下,Mikolov等[14]在此基础上使用层次化Softmax进行优化,提出了Word2vec框架,使训练时间大幅度缩短的同时,学习得到的词向量在一定程度上可体现深层的语法和语义特征。
随着Word2vec[14]和GloVe[15]等词的分布式表示方法的出现,词向量表示维度大幅度降低,且包含更多明确的语义信息,这使深度学习方法逐渐成为情感分类任务的主流方法。深度學习相比传统算法,具有更强的语义表达能力,在不需要人工进行特征选择的情况下取得了较好的性能。
基于深度学习的分类方法是一种多层表示学习方法。该方法可以利用深层神经网络,从低层的文本表示中自动学习高层的文本语义特征。基于深度学习的方法主要包含如下几种。
1.2.1 基于递归神经网络
Socher等[16-17]提出了多个递归神经网络(Recursive Neural Network)模型,将文本的句法结构加入到神经网络模型中。Qian等[18]提出两种基于短语词性标签的递归网络模型:标签引导递归神经网络(Tag-Guided Recursive Neural Network, TG-RNN)和标签嵌入递归神经网络(Tag Embedded Recursive Neural Network, TE-RNN),前者根据词性标签选择一个用于子节点词嵌入的合成函数,后者学习词性标签的词嵌入,并与子节点的词嵌入结合。Tai等[19]将长短期记忆(Long Short-Term Memory, LSTM)网络改造为树状结构,相比线性的LSTM结构效果有明显提升。
1.2.2 基于循环神经网络
Irsoy等[20]利用循环神经网络获取文本序列特征,对比了不同层数RNN对性能的影响;Liu等[21]提出了3种可用于多种数据集共同训练的RNN模型,将分布相似的数据集同时作为输入,提高了模型的泛化能力;Qian等[22]在LSTM的基础上对情感词添加了正则化,不同类型情感词的出现会调整当前时刻情感表示的概率分布。
1.2.3 基于卷积神经网络
Kim[4]使用CNN捕获文本的局部语义特征,结合静态或微调的词向量实现句子级情感分类;Kalchbrenner等[23]使用一维CNN获取文本的N-grams特征,尽可能保留了原文本的语义信息,再经过动态K-Max池化筛选出最显著的k个特征;Zhou等[24]提出了一种结合CNN和RNN的混合模型,利用CNN提取文本的N-grams特征,RNN整合文本的全局信息。
2 模型介绍
2.1 词嵌入向量和N-grams特征
自然语言处理任务中大多数深度学习模型都需要词向量作为神经网络的输入特征[25]。词嵌入(Word Embedding)是一种用于语言建模和特征学习的技术,它将词汇表中的单词转换成连续的实数向量。例如,单词“cat”在一个5维词嵌入模型中可表示为向量(0.15,0.23,0.41,0.63,0.45)。该技术能将高维稀疏的向量空间(例如one-hot向量空间,只有一个维度的值取1,其他全取0)转换为低维稠密的向量空间。词向量可编码一定的语言学规则和模式,包含语义特征。
词嵌入向量仅仅涵盖了词级别(word level)的特征表示,无法表达固定短语和词组的语义,对文本的表示能力不足。在传统统计模型中,N-grams特征常被用于解决此类问题。神经网络模型中的卷积操作也能达到类似的效果,用于提升文本的语义表达能力。例如,“I get up early”这句话通过大小为2的卷积核处理后会得到Bigram特征:“I get”“get up”“up early”,其中“get up”为固定的短语搭配,经过反向传播后该特征能分配到更高的权重。
2.2 长短期记忆网络
由于原始的循环神经网络存在严重的梯度消失或梯度爆炸问题,对于较长距离的特征处理能力弱,网络的处理单元出现了若干的变体,其中长短期记忆(Long Short-Term Memory, LSTM)网络[26]已被广泛应用于自然语言处理领域。简单地说,在LSTM中,隐含状态ht和存储单元ct是它们前一时刻的状态ct-1、ht-1和当前时刻输入向量xt的函数,其表达式如下:
隐含状态ht∈Rd是隐含层t时刻的向量表示,同时也编码该时刻之前的上下文信息。
在单向LSTM中,每个位置ht的隐藏状态只保留了前向的上下文信息,而没有考虑反向的上下文信息。双向长短期记忆(Bi-directional Long Short-Term Memory, BiLSTM)网络[27]利用两个并行通道(前向和后向)和两个LSTM的隐藏状态级联作为每个位置的表示。前向和后向LSTM分别表述如下:
其中,g(LSTM)与式(1)中的相同,但分别使用不同的参数,在每个位置t,隐含状态表示为ht=[t,t],它是前向LSTM和后向LSTM隐含状态的联结。以这种方式,可以同时考虑到向前和向后上下文信息,从而更有效地从文本中提取特征。
2.3 基于卷积神经网络的文本情感分类
卷积神经网络是一种多层神经网络,由卷积层、池化层、全连接层等组成。由于能够提取空间或时间结构的局部相关性,CNN在计算机视觉、语音识别和自然语言处理等方面都取得了优异的表现。对于句子建模,CNN通过卷积核在句子不同位置提取N-grams特征,并通过池化操作学习短、长程的上下文关系。其中,Kim[4]提出了经典的基于卷积神经网络的文本情感分析算法,本文采用其中的CNN-non-static作为对照算法(后文简称为Kim-CNN),其结构如图1所示。
其中:xi:i+h-1∈Rkh表示从输入文本第i个词(第i列)开始邻接的h个词向量拼接而成的矩阵;b∈R表示偏置; f使用非线性激活函数ReLU(Rectified Linear Unit请补充ReLU的英文全称);ci表示卷积核在文本第i个位置的特征值。
卷积核wc作用于句子中每一个可能的窗口{x1:h,x2:h+1,…,xn-h+1:n},获得特征图:
3)池化层。池化操作可改变句子的长度,其主要目标是获取特征图中最重要的特征,即最大的特征值=max{c},然后将得到的所有最大特征值拼接,生成文本的高层特征向量v=[1,2,…,m],其中m为卷积核数量。
4)Softmax层。以特征向量v作为输入,使用Softmax分类,输出当前文本在各个类别上的概率:
其中:y∈Rs;ws为权重;bs为偏置,s为类别数目。预测出概率后,使用交叉熵形式的损失函数并反向传播,进行权值更新和词向量微调(fine tuning),多次迭代后,取最优的模型参数。
目前,基于CNN的情感分类方法大多使用二维卷积结构,但通过这种方式获得的N-grams特征,相比输入文本的词向量,特征维度降低,特征包含的语法和语义信息较少。Kim-CNN模型可以理解为使用二维卷积从文本中捕获对应情感标签下语义特征最显著的“关键词”,通过全连接对多个“关键词”加权求和,判断情感类别。然而,使用二维卷积会压缩获取N-grams特征的维度,损耗特征的大量语义信息,无法实现多层神经网络来提取高层次的语义特征,而且CNN只能获取文本的局部特征,对时序信息和全局特征不能有效地识别与表示。
2.4 基于一维卷积的混合网络模型
由于Kim-CNN模型存在二维卷积损失特征语义信息以及CNN无法有效地识别和表达时序信息的问题,本文在该算法的基础上进行改进,在网络结构中加入一维卷积结构和BiLSTM,提出了一种应用于文本情感分类的神经网络结构:1D-CLSTM。具体改变为:将卷积层的二维卷积操作替换成词向量每个维度上的一维卷积操作,并在池化层和Softmax层之间增加一个循环神经网络层,其结构如图2所示。
从图2可以看出,该网络自底向上由5层结构组成,分别如下。
1)输入层。从文本D查找词wi,得到对应的词向量xi∈Rk,k为词向量的维度。在文本开始和末尾分别添加全0的Padding,以保证卷积后句子长度不变。
2)一维卷积层。词向量每一维(每一行)分别使用不同的一维卷积。一组一维卷积核表示为wc∈Rhk,可生成一个特征图c,h为滑动窗口大小。经过卷积,文本第i个词的第j维得到的特征值为:
其中,wcj∈Rh表示词向量第j维上的一维卷積核。
3)池化层。池化操作的目标是选取文本各个位置最重要的特征,对于每一个特征图c,第i列的最大特征值i=max{ci},经过池化层得到其中一个特征向量v=[1,2,…,L]。其中,ci∈Rk,L为文本长度。
4)循环神经网络层。经过池化层得到矩阵V=[v1,v2,…,vN],将其按列展开为[α1,α2,…,αL],N表示特征向量v的数量。向量αt作为BiLSTM网络t时刻的输入,由式(2)和式(3)分别求得t时刻前向和后向的隐藏状态t和t,输出为:
5)Softmax层。用Softmax作为分类器,输出当前文本在各个情感类别下的概率。
本文选用一维卷积替换二维卷积有两点考虑:其一,通过一维卷积得到的特征图可以保持与输入文本相同的维度,将语义信息的损失降到最小;其二,词向量可以认为是神经网络训练语言模型的副产物[28],词向量各维的值可以看作隐含层各个神经元的输出,词向量的各个维度之间相互独立,卷积应该分别进行,而不是将它们简单地进行加权求和。
卷积操作虽然可以将相邻词或特征的语义进行组合,但无法有效地识别和表示时序信息。为解决这一问题,本文采用BiLSTM将一维卷积提取出的N-grams特征按时间顺序整合,挖掘特征之间的时序关系以及全局语义信息。
如上分析,本文提出的1D-CLSTM模型相对Kim-CNN模型来说,较好地避免了在二维卷积中损失语义信息,无法识别和表达时序信息等问题,第3章将用实验结果验证它在情感判别领域的应用效果。
3 实验及结果分析
为了检验1D-CLSTM模型的性能以及证明一维卷积在情感分类任务上的优越性,将其与近年来一些经典的文本情感分类算法进行实验对比。在基本模型之外,还对一些其他的变体进行实验,以分析各种网络结构对于分类效果的影响。
3.1 情感分类数据集
本文在多个标准英文数据集上测试了上述模型,数据集的统计信息如表1所示。SST-1和SST-2[16]分别为五分类和二分类的影评情感分类数据集,来自Stanford Sentiment Treebank。MR是二分类的影评数据集,目标是判断评论的情感为正面还是负面。IMDB由100000条二分类的影评数据组成,每一条影评包含多个句子,属于文档级的情感分类数据集[29]。
由于IMDB数据集没有明确的训练集、验证集划分,采用10折交叉验证(10-fold cross-validation),将训练集随机分成10组,每次使用训练数据的90%训练模型参数,剩下10%作为验证集,验证模型优劣,选取验证结果最优的模型参数,用于计算测试集上的情感分类准确度。MR数据集使用81%作为训练集,9%作为验证集,10%作为测试集。SST-1和SST-2数据集有固定的验证集划分,因此每轮实验随机初始化参数,重复训练10次,取这10次实验结果的平均值作为最终的情感分类准确度。
3.2 参数设置
实验使用GloVe预训练的词嵌入向量作为初始的输入[3],维度为300。对于一维卷积层,采用1、2、3这三种尺寸的卷积核,每种尺寸的卷积核数量均设置为4,确保卷积网络从不同维度不同位置提取多种文本特征。循环神经网络层使用BiLSTM,记忆单元的维度为150,词向量和BiLSTM后均设置0.5的dropout。训练批次大小(batch size)为50,学习率为5E-4,进行反向传播的参数增加0.001的L2正则约束,选择Adam作为优化器(optimizer),训练阶段最大迭代次数(epoch)为100。输入的词向量会根据反向传播微调,在1000个批次(batch)内验证集上的准确度没有提升会提前停止训练(early stop),设置梯度截断(gradient clipping)为3。
3.3 结果对比
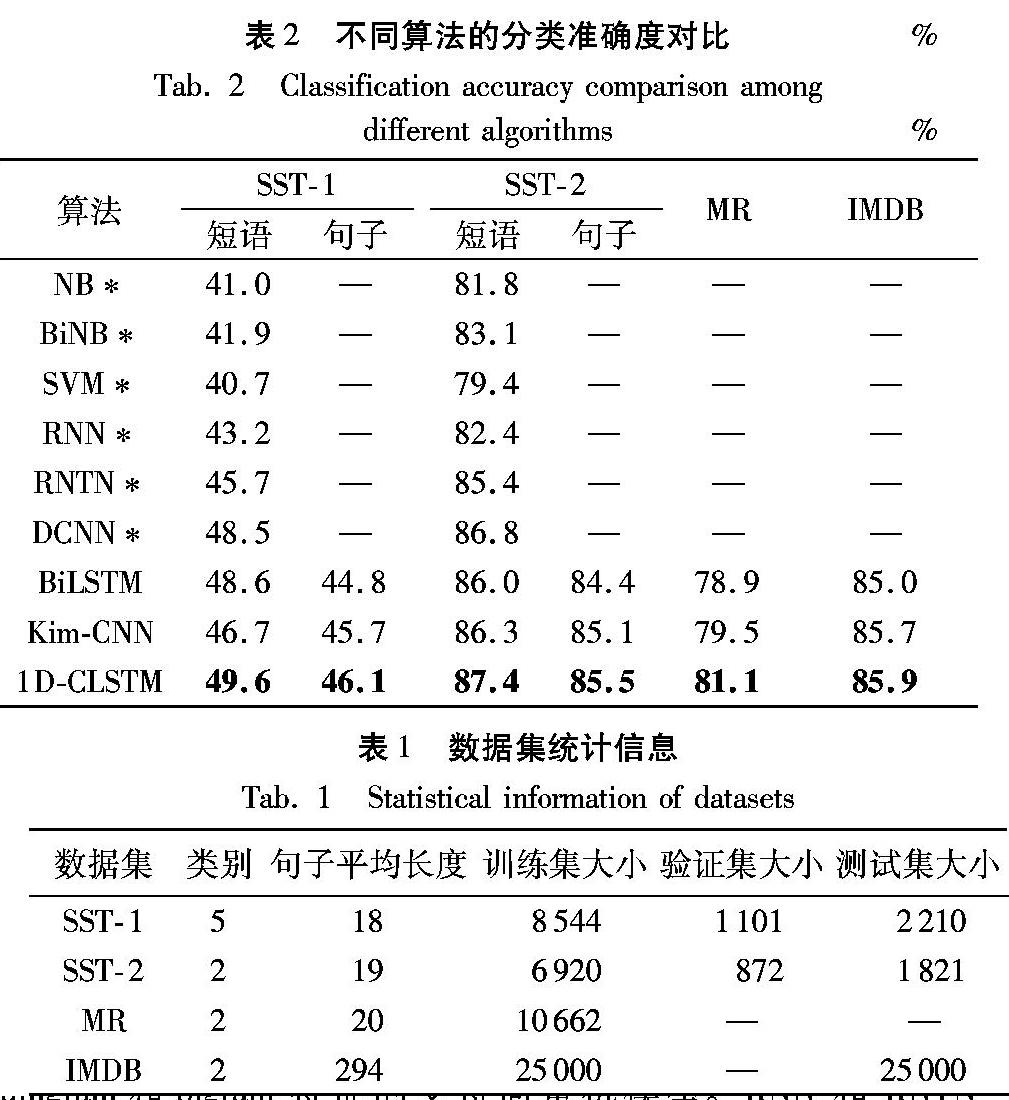
为测试模型性能,本文将1D-CLSTM模型与主流的情感分类模型进行对比。实验采用分类准确度(Accuracy)作为情感分类算法的评价指标,结果以百分比为单位。实验结果如表2所示。
其中,SST-1和SST-2数据集下的短语和句子分别代表训练时使用短语级或句子级的标注数据,而验证和测试阶段均使用句子级的标注数据[16]。前5个模型的结果引用自Socher[16]。NB和BiNB均为朴素贝叶斯模型,前者仅使用unigram特征,后者同时使用unigram和bigram。SVM是使用unigram和bigram特征的支持向量机模型。RNN和RNTN(Recursive Neural Tensor Network)均是基于文本句法解析树的递归神经网络模型。DCNN(Dynamic Convolutional Neural Network)[23]同样采用一维卷积,但经过动态k-max池化后文本长度会减小,仅保留了最显著的k个N-grams特征。BiLSTM是以词向量为输入的双向长短期记忆网络,去掉了1D-CLSTM中的一维卷积层,其余参数设置相同。Kim-CNN[4]是根据原论文的参数设置和开源代码复现,将词向量由Word2vec换作GloVe,由于文献[4]对于数据集划分、参数选择和优化的细节没有说明,导致复现结果相比原文略差。文献[4]汇报了SST-1短语、SST-2短语和MR的结果,分别为48.0%、87.2%和81.5%此处的三个数字后面,是否应该加个百分号?即48.0%、87.2%和81.5%,请明确。
从表2可以看出,基于深度学习的情感分类方法性能明显优于传统机器学习方法,1D-CLSTM在各个数据集上的结果均优于其他模型。对比BiLSTM,1D-CLSTM增加了一维卷积,使得各数据集的结果均有明显提升。这表明,经过一维卷积提取的N-grams特征,相比初始词向量,包含了更有价值的语义信息,适合后续的池化和循环神经网络处理。对比Kim-CNN的重现模型,用一维卷积替换二维卷积并增加BiLSTM后,在各數据集上的结果都有一定的提升,最高达到2.9%。
为了进一步验证一维卷积相对于二维卷积的优势,本文在1D-CLSTM的基础上修改了部分结构,提出了两种变体:1D-2D-CNN与1D-2D-CLSTM,并通过实验对比了改进前和改进后分类准确度的变化。
其中,1D-2D-CNN是在Kim-CNN的基础上,输入层和卷积层之间增加一个一维卷积层,其他参数与Kim-CNN一致。1D-2D-CLSTM是在1D-2D-CNN的基础上,在池化层前添加一个BiLSTM网络。
从表3可以看出,在SST-1数据集中,额外的一维卷积层为Kim-CNN模型带来了1至2个百分点的提升。相比原始输入的词向量,经过一维卷积的特征包含了更多额外的语义信息,说明一维卷积在提取N-grams特征方面具有一定的优势,但是IMDB数据集上增加一维卷积反而让准确度有所下降,可能原因是该数据集属于文档级的情感分类,输入文本的平均长度为294,仅使用卷积神经网络无法表征足够的全局语义信息。
从表4可以看出,将最大池化层改为BiLSTM后,1D-2D-CLSTM模型相比1D-2D-CNN分类准确度有1个百分点左右的提升。这表明使用LSTM的循环神经网络相对简单的池化操作具有更强的表达力,能够提取和表达更复杂的语法和语义特征,适合情感分类任务。
1D-2D-CLSTM模型和1D-CLSTM模型的差别在,将池化层换成了二维卷积层,通过卷积来实现特征降维。从表4可以看到,1D-2D-CLSTM模型仍有微弱的提升。这说明,在情感分类任务上,二维卷积层或许是比池化层更好的降维特征提取方式,当然其代价是更大的网络参数和更高的训练成本。
4 结语
本文针对文本情感分类任务提出了一种基于一维卷积和循环神经网络的混合网络模型。该模型使用一维卷积替代二维卷积提取N-grams特征,通过BiLSTM挖掘特征之间的时序关系,解决了Kim-CNN模型中卷积损失特征语义以及无法表示时序信息的问题。实验结果表明,该模型的情感分类性能相比同类主流算法有明显的提升,并通过进一步的对比实验验证了引入一维卷积和循环神经网络对分类性能的正面影响。
从现有实验结果来看,在词嵌入向量的基础上使用卷积和循环神经网络进行情感分类,对于最终分类性能的提升是有一定限度的,其中尤其是原始词嵌入向量的质量对于最终模型的分类效果有很大影响。传统词嵌入向量是在较大的无标注文本集中通过计算各个关键词共同出现的统计指标得到的[14-15],Kim-CNN[4]的实验已经证明这些原始向量并不适合情感分析任务,一个重要证据是具有相似统计关系的反义词会被表达为类似的嵌入向量,因此,最近的一些研究工作尝试在另一个有监督场景下训练上下文相关的嵌入向量[30],或者借用卷积神经网络逐层特征提取的思路来设计一个多层LSTM网络以表达语言不同粒度的特征[31],将这些额外的关键词表达与原始词嵌入向量结合带来了显著提升的分类精度。
在计算机视觉领域使用迁移学习的方法可以最大限度地利用大规模数据集上预训练的模型参数,使得在一个相似场景下进行学习的效率大幅度提高,但是对于自然语言处理来说,大多数场景下除了词嵌入向量可以重用以外,都需要从头开始训练,这对于训练效率和最终效果都造成了较大影响。Howard等[32]提出了一个ULMFiT(Universal Language Model Fine-Tuning)模型,建立了自然语言处理领域中迁移学习的完整应用框架。Radford等[33]则将迁移学习过程建立在一个深层的Transformer网络[34]上,使用该框架预训练的模型通常在3次迭代左右就可以完成细调。同样基于Transformer网络,BERT[35]设计了一个填空(Cloze)任务,同时利用前向和后向的上下文,比之前的单向语言模型或者相互独立的双向LSTM都有明显优势,该模型在11个不同的公开任务中,都在之前最好的结果基础上明显提高。
未来的工作将会集中在以下几个方面:首先是基于对现有词嵌入向量及其在情感分析任务中的表达能力分析,尝试运用其他包含更丰富语义信息的特征表达方式;其次是进一步比较卷积神经网络、循环神经网络及Transformer网络等不同的网络结构在该场景不同任务中的性能,选择适当的网络结构进行组合和优化;最后是充分利用以BERT为代表的预训练模型,使用其网络结构和预训练参数,结合其他网络模型,该模型即使在不进行原始参数细调的前提下也能取得接近最优的效果。
参考文献 (References)
[1] 周立柱,贺宇凯,王建勇.情感分析研究综述[J].计算机应用,2008,28(11):2725-2728.(ZHOU L Z, HE Y K, WANG J Y. Survey on research of sentiment analysis [J]. Journal of Computer Applications, 2008,28(11): 2725-2728.)
[2] 趙妍妍,秦兵,刘挺.文本情感分析[J].软件学报,2010,21(8):1834-1848.(ZHAO Y Y, QIN B, LIU T. Sentiment analysis [J]. Journal of Software, 2010, 21(8): 1834-1848.)
[3] ZHANG Y, WALLACE B. A sensitivity analysis of (and practitioners guide to) convolutional neural networks for sentence classification[EB/OL]. (2016-04-06)[2018-06-07]. https://arxiv.org/abs/1510.03820.
[4] KIM Y. Convolutional neural networks for sentence classification [EB/OL]. (2014-09-03)[2018-06-01]. https://arxiv.org/abs/1408.5882.
[5] ZHANG L, WANG S, LIU B. Deep learning for sentiment analysis: a survey[J]. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery, 2018, 8(4): e1253.
[6] KIM S-M, HOVY E. Extracting opinions, opinion holders, and topics expressed in online news media text[C]// Proceedings of the 2006 Workshop on Sentiment and Subjectivity in Text. Stroudsburg, PA: Association for Computational Linguistics, 2006: 1-8.
[7] TURNEY P D. Thumbs up or thumbs down?: semantic orientation applied to unsupervised classification of reviews[C]// Proceedings of the 40th Annual Meeting on Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2002: 417-424.
[8] HU M, LIU B. Mining and summarizing customer reviews[C]// Proceedings of the Tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2004: 168-177.
[9] PANG B, LEE L, VAITHYANATHAN S. Thumbs up?: sentiment classification using machine learning techniques[C]// Proceedings of the ACL-02 Conference on Empirical Methods in Natural Language Processing-Volume 10. Stroudsburg, PA: Association for Computational Linguistics, 2002: 79-86.
[10] MOHAMMAD S M, KIRITCHENKO S, ZHU X. NRC-Canada: building the state-of-the-art in sentiment analysis of tweets[EB/OL]. (2013-08-28)[2018-07-02]. https://arxiv.org/abs/1308.6242.
[11] KIM S-M, HOVY E. Automatic identification of pro and con reasons in online reviews[C]// Proceedings of the 2006 COLING/ACL on Main Conference Poster Sessions. Stroudsburg, PA: Association for Computational Linguistics, 2006: 483-490.
[12] MEDHAT W, HASSAN A, KORASHY H. Sentiment analysis algorithms and applications: a survey [J]. Ain Shams Engineering Journal, 2014, 5(4): 1093-1113.
[13] BENGIO Y, DUCHARME R, VINCENT P, et al. A neural probabilistic language model[J]. Journal of Machine Learning Research, 2003, 3: 1137-1155.
[14] MIKOLOV T, SUTSKEVER I, CHEN K, et al. Distributed representations of words and phrases and their compositionality[C]// NIPS13: Proceedings of the 26th International Conference on Neural Information Processing Systems. North Miami Beach, FL: Curran Associates Inc., 2013: 3111-3119.
[15] PENNINGTON J, SOCHER R, MANNING C. GloVe: global vectors for word representation[C]// Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2014: 1532-1543.
[16] SOCHER R, PERELYGIN A, WU J, et al. Recursive deep models for semantic compositionality over a sentiment treebank[C]// Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2013: 1631-1642.
[17] SOCHER R, PENNINGTON J, HUANG E H, et al. Semi-supervised recursive autoencoders for predicting sentiment distributions[C]// Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2011: 151-161.
[18] QIAN Q, TIAN B, HUANG M, et al. Learning tag embeddings and tag-specific composition functions in recursive neural network[C]// Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2015: 1365-1374.
[19] TAI K S, SOCHER R, MANNING C D. Improved semantic representations from tree-structured long short-term memory networks[EB/OL]. (2015-05-30)[2018-08-10]. https://arxiv.org/abs/1503.00075.
[20] IRSOY O, CARDIE C. Opinion mining with deep recurrent neural networks[C]// Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computational Linguistics, 2014: 720-728.
[21] LIU P, QIU X, HUANG X. Recurrent neural network for text classification with multi-task learning[EB/OL]. (2016-05-17)[2018-08-01]. https://arxiv.org/abs/1605.05101.
[22] QIAN Q, HUANG M, LEI J, et al. Linguistically regularized LSTMs for sentiment classification [EB/OL]. (2017-04-25)[2018-08-15]. https://arxiv.org/abs/1611.03949.
[23] KALCHBRENNER N, GREFENSTETTE E, BLUNSOM P. A convolutional neural network for modelling sentences [EB/OL]. (2014-04-08)[2018-07-16]. https://arxiv.org/abs/1404.2188.
[24] ZHOU C, SUN C, LIU Z, et al. A C-LSTM neural network for text classification[EB/OL]. (2015-11-30)[2018-08-22]. https://arxiv.org/abs/1511.08630.
[25] COLLOBERT R, WESTON J, BOTTOU L, et al. Natural lan-guage processing (almost) from scratch[J]. Journal of Machine Learning Research, 2011, 12: 2493-2537.
[26] HOCHREITER S, SCHMIDHUBER J. Long short-term memory[J]. Neural Computation, 1997, 9(8): 1735-1780.
[27] GRAVES A, JAITLY N, MOHAMED A. Hybrid speech recognition with deep bidirectional LSTM[C]// Proceedings of the 2013 IEEE Workshop on Automatic Speech Recognition and Understanding. Piscataway, NJ: IEEE, 2013: 273-278.
[28] MIKOLOV T, CHEN K, CORRADO G, et al. Efficient estimation of word representations in vector space[EB/OL]. (2013-09-07)[2018-09-02]. https://arxiv.org/abs/1301.3781.
[29] LIU B. Sentiment Analysis and Opinion Mining[M]. San Rafael, CA: Morgan and Claypool Publishers, 2012: 1-167.
[30] McCANN B, BRADBURY J, XIONG C, et al. Learned in translation: contextualized word vectors[C]// NIPS 2017: Proceedings of the 31st Annual Conference on Neural Information Processing Systems. North Miami Beach, FL: Curran Associates Inc., 2017: 6297-6308.
[31] PETERS M E, NEUMANN M, IYYER M et al. Deep contextualized word representations[EB/OL]. (2018-03-22)[2018-10-21]. https://arxiv.org/abs/1802.05365.
[32] HOWARD J, RUDER S. Universal language model fine-tuning for text classification[C]// Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2018: 328-339.
[33] RADFORD A, NARASIMHAN K, SALIMANS T, et al. Improving language understanding by generative pre-training[EB/OL]. (2018-06-11)[2018-10-22]. https://blog.openai.com/language-unsupervised/.
[34] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]// NIPS 2017: Proceedings of the 31st Annual Conference on Neural Information Processing Systems. North Miami Beach, FL: Curran Associates Inc., 2017: 5998-6008.
[35] DEVLIN J, CHANG M-W, LEE K, et al. BERT: pre-training of deep bidirectional transformers for language understanding[EB/OL]. (2018-10-11)[2018-11-13]. https://arxiv.org/abs/1810.04805.
