基于介电频谱灵武长枣维生素C含量预测方法的研究
2019-09-04李冬冬贾柳君单启梅何嘉琳张海红
李冬冬 贾柳君 邓 鸿 单启梅 何嘉琳 张海红
(宁夏大学农学院 银川750021)
灵武长枣(Zizphus jujube Mill cv.Lingwu changzao)为鼠李科枣属植物,是宁夏特色优势果品,其果实色艳、肉质脆实、酸甜适口,富含糖、酸、维生素C、粗纤维及矿物元素等多种营养元素,其中尤以VC 含量最为丰富,素有“VC 之王”的美誉[1]。常将VC 含量作为评价灵武长枣品质的首选指标。
果品VC 含量的常用检测方法为2,6-二氯靛酚滴定法等[2],该法虽然检测精度高,但在样品前处理、快速测定、检测成本消耗等方面存在固有缺陷,检测后的样品,因组织遭到严重破坏而无食用和销售价值。寻找一种快速、便捷、高效的VC 含量检测方法对指导长枣生产,商品化推广具有重要意义。
无损检测技术[3]是近年来国内外最新发展的一种新型的品质检测技术,具有操作方便、原理简单、适应性强和非破坏等优点,受到国内外学者的广泛关注。近年来,众多学者利用高光谱、近红外技术检测樱桃、蜜桔、柑橘、鲜枣[4-7]等果品的VC含量,并取得较好的研究成果。介电无损检测技术也被部分学者应用于苹果[8-13]、猕猴桃[14]、火柿[15]、梨[16]、灵武长枣[17]、哈密瓜[18]等果品可溶性固形物、可滴定酸、含水率等品质指标的研究与分析,而利用介电特性检测灵武长枣VC 含量的研究鲜见报道。
本文拟基于介电特性的灵武长枣VC 检测的可行性,分析1 kHz~1 MHz 下长枣的介电频谱(相对介电常数ε' 和介电损耗因子ε")。利用连续投影算法 (Successive Projection Aalgorithm,SPA)、无信息变量消除法(Uninformative Variables Elimination,UVE)、竞争性自适应重加权算法(Competitive Adaptive Reweighted Sampling,CARS) 和遗传算法(Genetic Algorithm,GA)提取介电频谱的有效信息;采用偏最小二乘 (Partial Least Squares,PLS) 和最小二乘支持向量机(Least square support vector machine,LSSVM)法分别建立长枣VC 含量的预测模型,通过比较各模型的预测精度和稳定性,确定基于介电频谱检测灵武长枣VC 含量的最佳方法,优选基于介电频谱长枣VC 含量的预测模型。
1 材料与方法
1.1 材料
供试灵武长枣采摘于宁夏回族自治区灵武市永宁长枣生产基地。挑选果形完好,平均单果重约(15±2)g,纵径(4.2±0.5)cm,横径(2.5±0.5)cm,大小均匀、成熟度在九成熟和十成熟之间 (九成熟:绿色面积占长枣总面积的1/3 以下;十成熟:全红果),无虫害损伤的枣果100 个,常温(20±3)℃条件下擦净、贮藏、备用。
1.2 仪器及处理软件
LCR 测试仪(HIOKI-3532-50 型),日本日置电机株式会社;Matlab R2014a (Math Works),美国;Unscrambler X 10.3(CAMO),挪威。
1.3 试验方法
1.3.1 电学参数的测量 根据枣果尺寸选择面积为4.5 cm×3.1 cm 的铝制平行板电极。测试前首先对LCR 测试仪预热1 h,并依次进行开路、短路校正,选择测量电参数损耗系数D、并联等效电容Cp。将枣果平放在两极板间,调整极板距离,使极板与枣果刚好接触且对枣果不造成挤压为宜。在频率1 kHz~1 MHz 范围测量103,103.05,103.1,……,105.95,106Hz 时55 个点的枣果电参数D 和Cp值,测量数据以Microsoft Excel 2013 表格自动生成,以等效电容法推算枣果相对介电常数ε′和介电损耗因子ε″[19-20]。
1.3.2 维生素C 的测定 长枣VC 含量测定采用2,6-二氯靛酚法[21]。样本总量为100 个,测定周期为10 d,每天从总样中随机选取10 个样本测定。为避免偶然性误差,各样本均测3 次,取平均值作为最终测定结果。
1.4 数据分析及处理
1.4.1 特征频率的提取
1) 连续投影算法(Successive Projection Aalgorithm,SPA) SPA[22-23]是一种前向循环的变量选择方法,选定一个初始频点,然后在每次迭代时加入新的频点,直到达到指定的频点数,该法目的是解决信息重叠,选择最小冗余信息量的频点组合,解决共线性问题。
2) 无信息变量消除法 (Uninformative Variables Elimination,UVE) UVE 是基于偏最小二乘回归系数选择变量的一种方法[24-25],它把与自变量矩阵变量数目相同的随机变量矩阵(即噪声)加入频谱矩阵中,通过交叉验证在原始变量中逐一剔除无关变量,进而得到新的回归系数矩阵,最终达到降维的目的。
3) 竞争性自适应重加权算法(Competitive Adaptive Reweighted Sampling,CARS) 该 法 是一种基于蒙特卡罗采样 (Monte Carlo Sampling,MCS)法对模型取样的新型变量选择理论[26]。通过指数衰减函数及自适应重加权采样技术(Adaptive Reweighted Sampling,ARS) 计算并比较每次产生的新变量子集的RMSECV 值,将该值最小的变量子集作为最优变量子集。
4) 遗传算法(Genetic Algorithm,GA) GA[27]使用选择、交叉和变异三类遗传算子把复杂的现象用繁殖机制结合简单的编码技术来表现,通过随机搜索算法得出复杂问题相对较好的解;从初始群体到根据变异、选择和交叉等算子的作用而不断迭代来优胜劣汰,通过这样的搜索过程来不断逼近最优解。
1.4.2 模型建立
1) 偏最小二乘(partial least squares,PLS)PLS 是一种经典的线性拟合方法,它通过最小化偏差平方和实现对曲线的拟合[28]。
2) 最小二乘支持向量机(Least square support vector machine,LSSVM) LSSVM 是由Suyken 等[29]提出的用于解决模式分类和函数估计问题的支持向量机,它采用最小二乘线性系统作为损失函数,有效简化了计算的复杂性,提高了运算速度。
1.5 模型的评价
模型性能以校正相关系数(Rc)和校正均方根误差(RMSEC)及预测相关系数(Rp)和预测均方根误差(RMSEP)为评价指标。评价原则:Rc和Rp越接近1,RMSEC、RMSEP 越接近0,模型效果越好。
2 结果与分析
2.1 样本集的划分
为了提高模型的预测精度,采用Kennard-Stone(K-S)[29]法从测试完毕的100 个枣果样本中随机选取20 个用于检验模型的适用性,以3∶1 的比例对剩余80 个样本进行样本集和验证集划分,最终选择校正集样本60 个,验证集样本20 个。为考虑相对介电常数ε′和介电损耗因子ε″对预测结果的共线性影响,将两者合并建立预测模型。样本统计结果见表1。

表1 校正集与预测集样本VC 的统计结果Table 1 Statistical results of VC contents in Calibration set and Predication set
校正集和预测集的样本范围分别为344.42~435.11 mg/100 g 和353.25~410.01 mg/100 g,校正集涵盖预测集,说明样本划分合理。
2.2 长枣的介电参数分析
将55 个频率下的ε′值作为样本的前55 个变量,55 个频率下的ε″值作为样本的后55 个变量,样本的变量总数设为110 个。
图1为某一枣果样品在1 kHz~1 MHz 范围的介电谱。由图1可知,相对介电常数ε′随频率的增大先增大后减小,尤其在高频率下减小迅速,其中6.31 kHz 时ε′为最大值;介电损耗因数ε″变化规律类似,10 kHz 时出现较小ε″值,22.39 kHz 时出现最大ε″值。
2.3 长枣的介电特性与VC 的线性关系分析
为了探寻介电参数与长枣VC 的线性关系,本文建立了55 个频率点下的ε′和ε″与长枣VC的线性关系式y=aX+b,其中y 代表ε′或ε″,X代表VC 含量,a 和b 为拟合系数。如图2所示,Rε′和Rε″分别表示各频率点下ε′和ε″与VC 的线性相关系数。

图1 某一枣样品的介电谱随频率变化图Fig.1 Variation of dielectric spectrum of a long jujube sample

图2 长枣的介电特性与VC 含量的线性关系Fig.2 The linear relationship between the dielectric properties of Lingwu Long Jujube and VC content
由图2可知,所有频率点下的ε′和ε″与长枣VC 均呈正相关,且线性相关系数值均小于0.6,表明单一频率下的ε′和ε″与长枣VC 相关性较弱,仅以单一频率下的介电参数值很难用于预测长枣的VC 含量。有必要探讨是否用更多的介电参数或全频谱预测长枣内部的VC 含量。
2.4 有效信息提取
2.4.1 CARS 算法提取有效信息 图3显示根据CARS 算法提取有效频谱信息的结果。设定MC 采样50 次,采用5 折交叉验证法计算,因每次运行CARS 结果具有随机性,故在每个设定的蒙特卡洛抽样次数下运行20 次,取20 次建立的PLS 模型中最小RMSECV 值作为结果筛选标准。
由图3可知,在1 次CARS 算法中,由于衰减指数函数的作用,随着采样次数的增加,在采样前期变量数快速减少,表明算法"粗选"和"精选"的过程。随着采样次数的增加,单个PLS 模型的5 折交叉验证RMSECV 值呈现由大到小再到大的变化过程。采样7 次时RMSECV 值最小值为2.35。最终,从57 个变量中选定23 个变量(13 个ε′,10个ε″)作为特征频谱组合,结果见表2。
2.4.2 GA 算法提取有效信息 长枣介电频谱通过GA 算法筛选的有效信息如图4所示。横坐标为介电频谱的各频率点,纵坐标为不同频率点被筛选的频次,频次越高表示该点适应性越强,与长枣VC 相关性越高。
GA 算法运算过程中,设定遗传代数为100,以最小的RMSECV(交叉验证均方根误差)值和最高的R2值组合作为筛选标准。经20 次随机搜索后,得到最大R2值为89.72,最小RMSECV 值为3.72。最终选定特征频率35 个 (23 个ε′,12 个ε″)。
2.4.3 SPA 算法提取有效信息 应用SPA 算法对频谱数据进行有效信息提取,结果如图5所示。
SPA 算法运算过程中,设定变量数选择范围3~20,步长为1,根据RMSEC 值随变量个数的变化确定最佳特征变量数。如图5所示,当变量个数为14 时,RMSEC 值最小为2.95。变量个数大于14时其RMSEC 值不再减小。最终选定特征频率14个(9 个ε′,5 个ε″)。
2.4.4 UVE 算法提取有效信息 因UVE 是基于偏最小二乘回归系数选择变量的一种方法,故在应用UVE 算法提取频谱有效信息前,首先根据PLS 交互验证模型中RMSECV 的最小值确定PLS模型的最佳主成分数。本研究设定主成分为10。UVE 算法提取有效信息结果见图6。

图3 长枣介电谱的CARS 筛选图Fig.3 CARS screening of dielectric spectra of Long Jujube
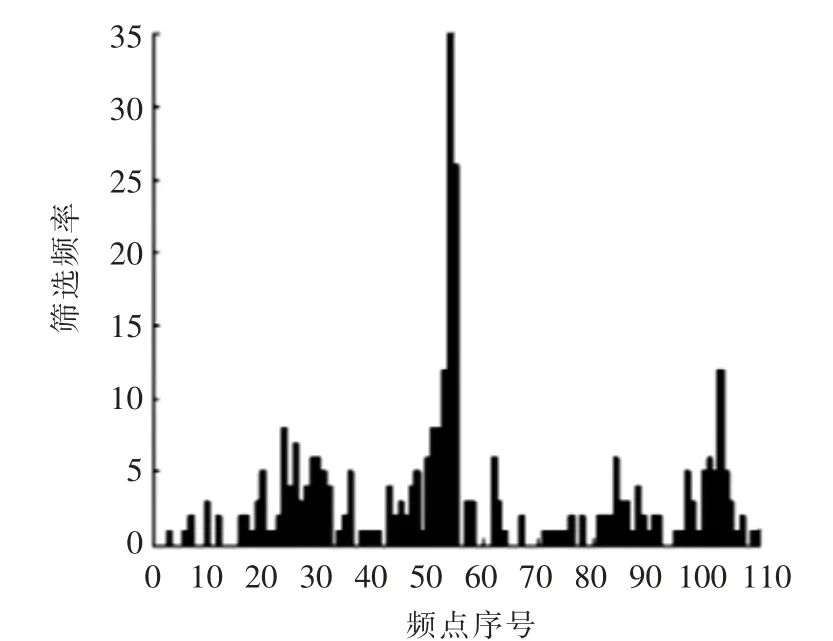
图4 长枣介电谱的GA 筛选图Fig.4 GA screening of dielectric spectra of Long Jujube

图5 长枣介电谱的SPA 筛选图Fig.5 SPA screening of dielectric spectra of Long Jujube

图6 长枣介电谱的UVE 筛选图Fig.6 UVE screening of dielectric spectra of Long Jujube
图6中,竖线左边为110 个频谱变量,右边为110 个随机变量,两条水平虚线为变量选择阈值。阈值的选择标准为随机变量稳定性最大绝对值的99%。两条虚线之内的信息被看作无用信息,虚线之外的信息被看作有用信息,其对应的频谱点被作为有效信息提取出来。最终选定特征频率38 个(30 个ε′,8 个ε″)。经各算法提取的特征频率点见表2。

表2 特征频率点列表Table 2 List of characteristic frequency points
2.5 模型建立
2.5.1 建立长枣VC 预测模型 将各算法提取的特征介电参数作为输入量,VC 值作为应变量,建立PLS、LSSVM 模型,见表3。

表3 基于长枣介电频谱建立的VC 含量预测模型Table 3 Prediction model of VC content based on dielectric spectrum of Long Jujube
由表3可知,(1)PLS模型结果分析:经CARS、GA、SPA、UVE 对频谱预处理后所建模型的Rc、Rp值均大于全频谱-PLS 模型且各值均大于0.85,RMSEC、RMSEP 值基本小于全频谱-PLS 模型,表明频谱预处理对模型优化是有意义的。
(2)对比4 种频谱预处理方法提取特征频率点个数,SPA、CARS 算法对比GA、UVE 算法,两者提取有效频点数最少,分别占全频谱的12.72%,20.90%,而两者所建PLS 模型Rc、Rp值均小于GA-PLS、UVE-PLS 模型,RMSEC、RMSEP 值均大于GA-PLS、UVE-PLS 模型。其原因可能为:SPA算法在解决信息重叠的同时,将部分相关信息一并剔除,导致模型效果变差;CARS 算法只能衡量变量单区间PLS 模型优劣,无法对整区间模型水平作出判断。
(3)对比UVE-PLS、GA-PLS 模型可发现,两者在保留特征频点个数基本一致的情况下,UVEPLS 模型和GA-PLS 模型Rc、Rp值分别为0.9871、0.9460 和0.9455、0.9209,RMSEC、RMSEP 值分别为3.9322、4.0400 和4.2485、4.1512;UVE-PLS 模型Rc、Rp 值略大于GA-PLS 模型,而RMSEC、RMSEP 值略小于GA-PLS 模型,故UVE-PLS 模型稳定性及预测精度均优于GA-PLS 模型。PLS建模过程中选定UVE-PLS 模型为最优模型。
(4)LSSVM 模型结果分析:SPA-LSSVM 模型Rc、Rp值分别为0.8016、0.7567,均小于全频谱-LSSVM 模型(Rc为0.8927,Rp为0.7931),故其校正及预测能力较全频谱-LSSVM 稍差,经CARS、GA、UVE 对频谱预处理后所建模型的效果明显优于全频谱-SVM;GA-LSSVM 模型Rc、Rp值和RMSEC、RMSEP 值分别为0.9355、0.9037 和5.1347、6.7537,其Rc、Rp值 均 小 于UVE-LSSVM 和CARS-LSSVM 模型,而RMSEC、RMSEP 值均大于UVE-LSSVM 和CARS-LSSVM 模型;其在模型精度及稳定性方面次于UVE-LSSVM 和CARSLSSVM,后两者虽在模型校正能力方面相似,但UVE-LSSVM 模型的预测精度明显好于CARSLSSVM。LSSVM 建模过程中选定UVE-LSSVM 模型为最优模型。
(5)对比UVE-PLS、UVE-LSSVM 发现,UVEPLS 模型在校正能力、预测能力及模型精度方面,均优于后者,故UVE-PLS 为长枣VC 预测的最佳模型。分析原因可能为:UVE 是基于偏最小二乘回归系数选择变量的一种方法,计算过程中可通过引入噪声变量达到逐一剔除无关原始变量的目的。“精确”去除冗余信息的同时极大地保留了有效信息。
2.5.2 模型验证 将随机选出的20 个未参与建模的样本作为独立预测集,验证UVE-PLS 模型的适用性,结果见图7。
实测值与预测值点呈对角线分布且以小幅度在对角线上、下波动。t 检验表明,各项指标预测值与实测值无显著差异。

图7 UVE-PLS 模型验证Fig.7 UVE-PLS model validation
3 结论
以鲜摘灵武长枣为研究对象,在1 kHz~1 MHz 频率范围,通过CARS、GA、SPA、UVE 算法对以相对介电常数ε′和介电损耗因子ε″组成的110个变量进行优化筛选,最终分别选定23、35、14、38 个特征频率点,将其作为输入变量建立长枣VC 的LSSVM、PLS 模型。结果表明:对PLS 模型,频谱筛选方法的优等级排名为UVE>GA>CARS>SPA;对LSSVM 模型,频谱筛选方法的优等级排名为UVE>CARS>GA>SPA;选定UVE-PLS 为最佳预测模型,其Rc、RMSEC、Rp、RMSEp 值分别为0.9871、3.9322、0.9460、4.0400,验证模型R2值为0.9617,表明UVE-PLS 模型具有较好的预测精度、稳定性及适用性,基于介电频谱无损预测长枣VC 含量的方法是可行的。
