基于改进LE和约束种子K均值的半监督故障识别
2019-08-31郭顺生
张 鑫, 郭顺生, 江 丽
(1. 武汉理工大学 机电工程学院,武汉 430070;2. 武汉理工大学 湖北省数字制造重点实验室,武汉 430070)
随着工业4.0在全球化的兴起,机械设备的故障诊断在正确率和诊断效率上需要达到更高的要求,而现代机械设备的故障数据往往呈现出非线性、非平稳性、非高斯分布的海量高维特性,采用传统的故障识别方法难以达到理想化的诊断效果[1-4]。研究如何从高维非线性的故障数据中,提取出对于故障识别有用的特征量,是当前故障识别领域的一大热点,对于实际的生产维护也有很好的指导意义。
传统的线性分析方法,如主元分析(Principal Components Analysis, PCA)算法[5]和独立主元分析算法[6]无法揭示复杂故障数据的非线性结构。此外,传统的非线性学习方法,如核主成分分析(Kernel PCA, KPCA)算法[7]在希尔伯特特征空间利用核函数执行了线性PCA,一定程度上提取了高维非线性数据的低维表征量。但是,如何选取最优的核函数提高KPCA算法的特征提取性能是一个巨大的挑战,而且它没有考虑样本的类别信息。核判别分析(Kernel Discriminant Analysis, KDA)算法[8]则要求数据服从高斯分布。自组织特征映射算法[9]计算较为复杂,且易陷入局部最优。上述传统的非线性算法难以挖掘蕴含在高维数据中的潜在信息,而流形学习则充分挖掘了非线性数据中潜在的几何结构和内在规律,为高维非线性故障数据的特征提取提供了一种新的思路[10]。
拉普拉斯特征映射(Laplacian Eigenmaps,LE)是一种经典的流形学习算法,它运用图拉普拉斯概念计算高维流形来得到低维特征表示[11]。在机械故障诊断领域,LE算法多采取和聚类算法组合的方式,但它们大多是无监督的[12-14]。这样的无监督方式忽略了故障的类别信息,缺少监督信息的约束,易造成分类结果不理想。然而,有监督的训练需要大量昂贵的有标记样本的支持。
基于约束种子K均值(Constrained Seed K-means,CSKM)算法[15]的初始聚类中心由标记样本生成,其可靠性对后续聚类效果影响很大。而在实际应用中,标记样本中难免会因外界环境干扰,造成一定的偏差,容易导致聚类结果的不理想。针对这些情况,本文在LE算法基础上进行改进,并提出了基于改进LE算法和CSKM算法的半监督识别模型。该模型利用大量廉价的未标记样本学习出数据的潜在流形结构,少量昂贵的有标记样本学习出整个流形上的类别信息,弥补了上述两种监督方式的不足。另外,本文提出的改进LE算法增加了对有标记样本的降维约束,使得同类样本点降维后更易聚集,异类样本点降维后更易分离,从而保证CSKM算法具有更理想化的初始聚类中心,优化了聚类效果。
1 改进拉普拉斯特征映射算法
1.1 问题描述
给定高维空间RD上的一组训练样本和一组测试样本, 构成数据集X={x1,x2,…,xm,xm+1,…,xm+n},xi∈RD。 其中m为训练样本总数,n为测试样本总数,m+n即为总样本数,D为高维样本的维数。 假设其在低维空间Rd上的低维嵌入为Y={y1,y2,…,ym,ym+1,…,ym+n},yi∈Rd;d为低维样本的维数且d≪D。
1.2 拉普拉斯特征映射算法
LE算法主要目标是挖掘潜藏在原始高维流形中的低维流形特征,其实质就是要获得一个平均意义上的数据点局部近邻信息。它的基本思想是,在高维空间上距离很近的点,在低维空间上的投影也应该距离很近。LE算法所产生的映射可以看成是对几何流形的一种连续离散逼近的映射,通过构建数据点之间的邻域图来近似代表流形,并用Laplace-Beltrami算子近似标识邻域图的权值矩阵,实现高维流形的最优低维嵌入。其算法的步骤如下:
步骤1构造近邻图G。计算高维空间上所有数据点对之间的欧式距离,根据k近邻法,确定每个样本点的k个近邻点。如果高维空间上的两点xi,xj是近邻点,那么认为这两点之间有边连接,否则两点之间是断开的。
步骤2构造样本点间的权值矩阵。样本点间的权值选择有两种方法:①热核法(Heat Kernel),若两点xi,xj连通, 则其权值为Wij=exp(-‖xi-xj‖2/σ2); 否则Wij=0。② 简单法。这种方法较为简便,若两点xi,xj是连通的,则Wij=1,否则Wij=0。本文采用简单法,邻接权值定义为
(1)
步骤3计算低维嵌入
(2)
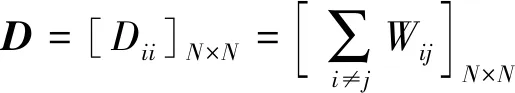
1.3 改进LE算法
传统半监督LE算法在标记样本类间相似度低的情况下,无法对标记样本生成精确的邻边矩阵与度矩阵,可能会造成异类样本有边相连的情况,造成流形学习的结果不可靠。本文提出的改进LE(Improved Laplacian Eigenmaps,ILE)算法,对标记样本的降维学习加以约束,使得同类样本间的低维流形更聚集,异类样本的低维流形更离散,为后续CSKM算法聚类结果提供更可靠的半监督信息,从而优化分类准确率。在计算样本近邻图G的邻边矩阵时,定义一置信度矩阵C, 如式(3)~式(5)所示。
(3)
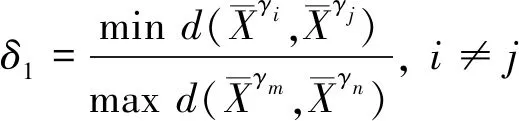
(4)
δ2=2-δ1
(5)
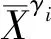
计算样本点间的欧式距离得到实际距离矩阵distance, 并通过置信度矩阵C进行约束, 构建两点间的理想距离矩阵A,如式(6)定义
A(Xi,Xj)=distance(Xi,Xj)×C(i,j)
(6)
根据文献[16]选择合适的k值为8,最优的嵌入维数d=β-1(β为样本类别数), 对理想距离矩阵A进行排序, 对每个样本点选择前k个最近邻的点, 并设置连接权值Wij=1, 从而构建近邻矩阵W与度矩阵D。 通过“1.2”节中提出的方法,计算得到高维模式空间的低维嵌入ε1,ε2,…,εd。
2 基于改进LE和约束种子K均值的诊断模型
2.1 约束种子K均值算法
在现实的聚类任务中,利用额外的监督信息使得模型取得更优的聚类效果,称为半监督聚类[17]。本文利用半监督聚类算法对降维后的数据进行聚类分析,以标记样本为监督信息,实现聚类效果的最优化。
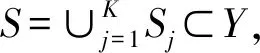
步骤1利用标记样本监督信息,初始化聚类中心。
(7)
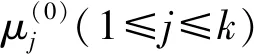
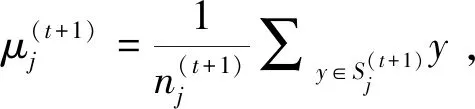
步骤4更新迭代次数t→t+1,重复上述步骤,直至收敛。
2.2 半监督诊断模型
根据高维空间上不同故障样本呈现出不同的流形结构,本文提出基于改进LE算法的故障诊断模型,如图1所示。其基本思路是:运用ILE算法对原始高维模式空间进行流形学习,挖掘其潜在流形结构,从而提取表征故障本质的低维流形特征。其中,大量的无标记样本可以学习出潜在的流形结构,少量标记样本学习出样本空间上的类别信息。提取出的低维流形涵盖故障空间的主要特征,将它们输入到CSKM分类器中,通过迭代寻优的方式,实现最佳聚类效果从而识别出机械设备的工作状态、诊断其故障类型。本文算法的诊断步骤如下:
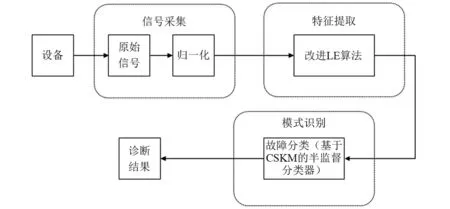
图1 基于改进LE算法的半监督故障识别模型Fig.1 Semi-supervised fault identification model based on improved laplace feature mapping
(1) 构建原始高维模式空间
通过传感器对故障设备进行数据采集,采用min-max标准化法对时域振动信号进行归一化处理,从而得到一个原始振动时间序列构建的高维模式空间。
(2) 低维特征提取
通过“1.3”节提出的改进LE算法对高维故障数据进行流形学习,提取表征故障本质的低维流形特征。
(3) 基于约束种子K均值的分类器
低维流形特征包含有标记样本与测试样本,有标记样本含有类别信息,一同输入到后续半监督分类器中。分类器最终输出一个类别标识矩阵,同低维嵌入矩阵一同进行可视化聚类,并得到故障类型的诊断结果。
3 实验验证
本文作为算法验证的实验数据来自于美国Case Western Reserve University电气工程实验室的滚动轴承故障数据[19],滚动轴承实验台由一个1 491.4 W的三相电动机、一个扭矩传感器和一个加载电机组成。试验轴承(型号为6205-2RS JEM SKF)安装于电动机的驱动端,加速度传感器粘贴于驱动端正上方的机壳。本文采用的实验数据均在以下工作参数下测得:电机负载功率可选0~2.24 kW,对应转速分别为1 797 r/min,1 772 r/min,1 750 r/min以及1 730 r/min。数据记录仪(16通道)采样频率为12 kHz。依托于上述实验条件,进行以下两组实验。第一组实验选择相同故障尺寸,验证本文算法对故障类别的识别效果,第二组实验针对滚动体故障,验证不同受损程度的分类效果。两组实验同时与KPCA+KNN(K-Nearest Neighbor)算法、KDA+KNN算法、LE+KNN算法进行实验对比,验证本文算法的优越性。上述三种对比算法的诊断过程为:分别采用KPCA算法、KDA算法、LE算法对高维流形结构进行特征提取,再通过K近邻算法进行故障模式分类。通过五折交叉验证,分别确定KPCA算法和KDA算法对应的最佳核(本文全部选用RBF(Radial Basis Function)核函数)宽度σ[20]。
3.1 轴承故障类型诊断实验
为验证本文算法对轴承故障类型的识别效果,选取故障尺寸为0.53 mm的四类故障(内圈故障、球体故障、外圈故障、正常)数据,进行如下模拟实验。
对每类故障分别构建100组样本,其中10组为含有类别标签的有标记样本,另外90组无标记样本作为测试样本。每组样本含有1 024个采样点,均在电机转速1 750 r/min条件下测得。将高维空间的故障样本映射到低维特征空间上,利于实现故障分类与可视化聚类。这400组样本作为原始高维数据输入到本文的算法模型中,样本共分为四种类型,故确定算法的嵌入维数为d=3,设置CSKM算法迭代上限t=10,置信度系数由式(4)、式(5)求得。四种算法模型的详细参数如表1所示。

表1 实验一参数选择
图2展示了四种组合算法对不同故障类型的识别效果。可以看出,KPCA作为一种无监督算法,类内离散度高且类间没有明显的划分。图2(b)中有监督的 KDA算法较之KPCA算法,分类效果有明显的改善,但对于“正常”与“球体故障”两类样本的聚类效果提升不大。图2(c)中,传统LE算法较好的实现了不同故障状态的识别,但对球体故障和外圈故障无法进行明显的划分,且分界面处样本划分混乱。图2(d)中的ILE算法则成功分离了这两类样本,四类样本在二维空间上划分明显。因此,本文提出的算法组合体现了更好的分离性能与聚类效果,能更好地表征和识别轴承的故障状态。
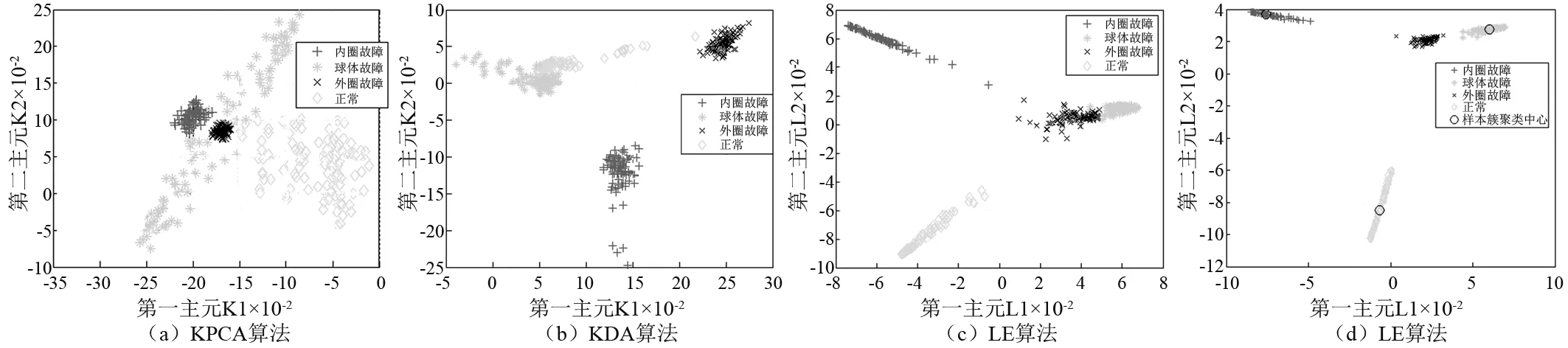
图2 四种算法的低维映射结果Fig.2 Low-dimensional mapping results of four algorithms
表2为上述四种算法多次运行后,计算耗时与识别率的对比结果。其中,计算耗时为特征提取与分类器耗时的总和。可以看出,KDA,KPCA两种算法虽然耗时较低,但识别精度过低(低于80%)。而本文提出的改进LE算法结合约束K均值分类器,计算耗时要比LE+KNN的组合更低,且识别率接近98%,识别效果优于其他三种算法。

表2 实验一算法对比
3.2 滚动体故障严重程度诊断实验
本实验选取轴承滚动体不同故障尺寸(无故障,0.18 mm,0.36 mm,0.53 mm)作为故障类型,验证本文算法对滚动体故障严重程度的分类效果,并与上述三种算法组合形成对比实验。图3为滚动轴承不同故障尺寸下时域特性,无法明显区分四类故障尺寸。
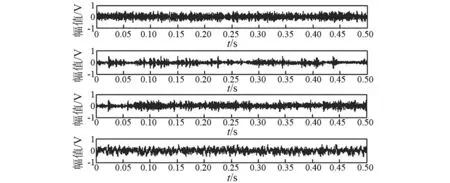
图3 不同故障尺寸的原始时域Fig.3 Original time domain of different fault sizes
样本条件与“3.1”节实验相同,每类故障类型包含100组样本(共100×1 024个采样点,电机转速1 772 r/min下测得),其中包含10组标记样本和90组测试样本。四种算法参数设置如表3所示。

表3 实验二参数选择
图4(a)为KPCA算法对上述样本的聚类效果,可以看出四种故障尺寸间无法明显划分,分类情况和聚合情况都很差。图4(b)中KDA算法的类内距较之KPCA算法有了较好的改善,但有三种类型的样本投影混合在一起,无法区分。这二类算法对轴承故障尺寸的分类效果都不理想,准确率也都较低。
图5(a)、图5(b)分别为LE+KNN组合算法与本文算法对有标记样本的聚类效果。从图5(a)可知,故障尺寸0.18 mm的标记样本与故障尺寸0.36 mm的样本高度重合,分离度很差。而图5(b)中四类有标记样本聚类后分类效果明显,且同类样本几乎集中于一点,因此本文算法对有标记样本的降维效果大大优于LE+KNN。
图5(c)、图5(d)为两种算法对测试样本的降维效果。从图5(c)可知,经LE算法降维后类内体现了很好的聚合性,但是由于传统LE算法的聚类效果过度依赖于有标记样本的可靠性,始终无法将故障尺寸为0.18 mm与0.36 mm的两类实现分离,最终导致识别准确率较低。而图5(d)中基于聚类效果更好的有标记样本,本文算法组合清晰的区分了0.18 mm与0.36 mm两类样本,同一类型的样本内部重合度较高,仅有一例0.18 mm样本被错标为正常,准确率大大提高。与传统LE+KNN相比,本文提出的算法模型改善了有标记样本聚类后类间距过小的情况,提高了有标记样本的可靠性,对轴承故障尺寸的分类效果明显更优,识别准确率更高。

图4 KPCA与KDAFig.4 Kernel principal component analysis and Kernel discriminant analysis
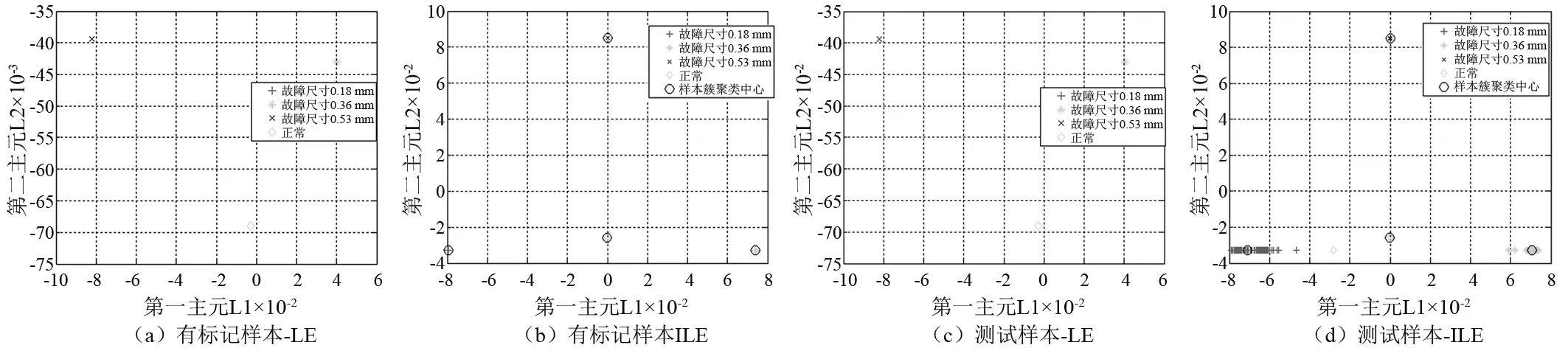
图5 LE与改进LEFig.5 LE and improved LE
表4为实验二中四种算法的计算耗时与识别率的对比。结合实验一的结果,综合耗时与精度两大要素,本文提出的改进LE算法在轴承故障诊断中的表现明显优于其他三种。

表4 实验二算法对比
上述两个实验中,分类器的判别结果如图6所示。可以看出应用约束种子K均值分类器,使得本文模型有了良好的迭代特性,这是KNN分类器不具备的。
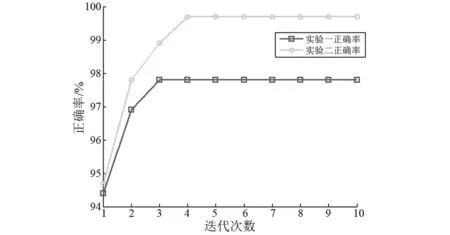
图6 识别准确率随迭代次数变化趋势Fig.6 The trend of the identification accuracy when iterations added
3.3 可靠性验证
对各算法组合的聚类结果进行后续验证,以确保模型诊断的有效性。故障诊断是典型的模式识别问题,可以采用类内距来衡量模式识别的聚类效果[21]。在后续实验中, {α1,α2,…,αd}是低维嵌入的投影向量,每类样本的类内距参数定义如式(8)
(8)
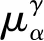
对实验一的聚类结果进行类内距验证,结果如表5所示。从整体来看:KPCA算法的聚类效果最差,尤其对球体故障的聚类效果很不理想。KDA算法较之KPCA算法有了一定的提高,但其正常样本的类内距仍然较大。LE算法对四类故障的聚类效果较为平均,也比上述两种算法的聚类效果更好。而本文提出的改进LE算法聚类效果最好,其类内距均小于其他三种算法。
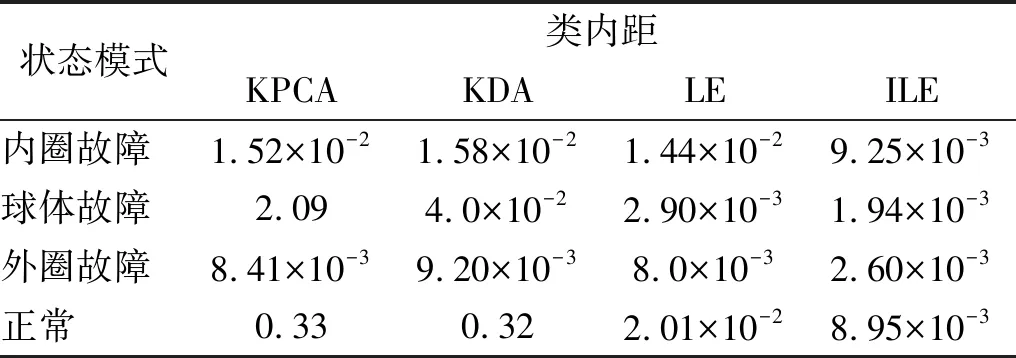
表5 类内距验证
为进一步验证改进LE算法的有效性与可靠性,采取五折交叉验证方法进行如下实验。分别选择“3.1”节与“3.2”节中的四类轴承故障数据组成两个样本集,每类故障样本数目为100。将每个样本集打乱后等分为5个不相交的子集,每个子集分别作为测试集,其它为训练集。实验结果表明,改进LE算法对轴承故障类型的识别效果良好且结果可靠。

表6 五折交叉验证
4 结 论
本文基于流形学习的思想,采用半监督的方式,提出一种基于改进拉普拉斯特征映射(ILE)算法和约束种子K均值的半监督故障识别模型。
(1) 利用LE算法的非线性降维能力,对高维复杂样本空间进行降维学习,继而在低维空间上进行样本分类。同时对LE算法做出了相应的改进,添加置信度因素使得同类标记样本降维后距离更近,异类标记样本距离更远,为约束种子K均值算法提供了质量更高的初始簇中心。
(2) 通过两组实验验证,证明了本文算法在轴承故障类型和滚动体受损程度上都有很高的识别精度。采用类内距对实验一进行参数验证,对比KPCA,KDA,LE算法,证明了改进LE算法有更好的识别效果。
(3) 采用五折交叉验证方法进一步证明了改进LE算法的有效性与可靠性。因此,与传统方法相比,本文提出的基于改进LE算法的故障识别模型能更好地表征轴承健康状态,并明显提高故障识别性。
