结合CNN和文本语义的漏洞自动分类方法
2019-08-27曲泷玉贾依真郝永乐
曲泷玉, 贾依真, 郝永乐
(中国信息安全测评中心,北京 100085)
随着互联网的飞速发展,人工智能、云计算、大数据等技术层出不穷,个人乃至社会对于信息化技术的依赖程度日趋加深,进而导致大量数据泄露、网络攻击、木马传播等信息安全事件频频爆发,给经济、政治、文化等诸多领域带来了严重威胁,网络空间安全形势的严峻性不容忽视. 然而,导致网络安全问题产生的主要根源在于网络信息系统存在的安全漏洞. 安全漏洞是计算机信息系统在需求、设计、实现、配置、运行等过程中,有意或无意产生的缺陷[1]. 网络攻击者可以利用漏洞对计算机系统进行攻击和破坏,从而影响计算机信息系统的正常运行. 据国家信息安全漏洞库(CNNVD)统计,截至2018年6月,CNNVD收录的信息安全漏洞已达110 000余个,其中危害等级在中危及以上漏洞占比达93%,近5年新增漏洞数量总体呈上升趋势[2]. 基于已有基数庞大的漏洞信息,关于漏洞自动化分类模型的研究具有非常重大的研究意义和应用价值,主要体现在以下两方面:一方面,针对不同类型的漏洞,按其危害等级采取分类应急措施方案,从而降低漏洞管理与系统维护成本,提高漏洞销控的及时性;另一方面,不同类型的漏洞对信息系统所造成的危害程度不同,通过从现有大量漏洞描述中提取不同类型的漏洞特征属性,进而为未知漏洞的发现及解决方案的建立提供前瞻性的预警分析[3].
对于漏洞信息来说,除漏洞编码之外,漏洞描述是区分信息安全漏洞的重要载体,以“短文本”的形式描述了该漏洞的漏洞宿主、产生原因、存在位置、受影响范围等,是人们对于漏洞信息认知和修复的最直接的信息来源. 近几年,有关深度学习在文本分类方面的技术应用已广泛展开深入探索,并取得了一定的研究成果. Conneau等[4]在Y.Kim研究的基础上提出一种深度卷积神经网络模型进行文本分类;杜昌顺等[5]提出了使用分段卷积神经网络来进行文本情感分析.
基于以上研究基础,一部分信息安全领域研究学者尝试将机器学习方法应用在漏洞自动分类当中,使用该方法可在一定程度上提高分类效率,避免手工分类的误操作. Li[6]提出一种SOM聚类方法对漏洞信息进行无监督分类;Chen等[7]提出了一种基于支持向量机(SVM)的漏洞自动分类模型,可对漏洞信息进行分类、推广和预测;廖晓锋等[8]提出一种隐含Dirichlet分布主题模型(LDA)和支持向量机(SVM)相结合的方法,在主题向量空间构建一个自动漏洞分类器,其准确度提高8%. 其中,绝大部分研究工作以国外漏洞库的漏洞信息作为实验数据,仅在词汇向量空间层面构建漏洞分类模型,不足以应对国内信息安全漏洞分类需求.
为了更加适用于国内漏洞的分析研究,并在已有的基础上提高分类效率,本文以国家信息安全漏洞库(以下简称“CNNVD”)的漏洞信息作为实验数据,建立基于CNN和文本语义的漏洞自动分类模型. 通过自动化判定威胁类型,进一步对危害级别较高、影响较为严重的安全漏洞,及时快速开展预警通报和修复消控,从而提高漏洞处置效力.
1 信息安全漏洞分类标准
根据漏洞的多方面属性,目前国内外针对多个维度已形成不同的漏洞分类标准,主要有3大类,分别为基于利用位置的分类,基于生命周期的分类和基于技术类型的分类. 本文漏洞分类研究工作从技术类型的角度出发,采用了CNNVD漏洞分类标准. 该标准将信息安全漏洞按照其形成原因及危害影响划分为5个层次26种类型,判别漏洞类型时可根据漏洞类型的层次关系,按照包含关系依次分别是:配置错误、代码问题、资源管理错误、数字错误、信息泄露、竞争条件、输入验证、缓冲区错误、格式化字符串、跨站脚本、路径遍历、后置链接、SQL注入、注入、代码注入、命令注入、操作系统命令注入、安全特征问题、授权问题、信任管理、加密问题、未充分验证数据可靠性、跨站请求伪造、权限许可和访问控制、访问控制错误、资料不足. 目前,CNNVD所有收录的漏洞信息均按照上述标准进行分类.
2 基于CNN和文本语义的漏洞分类模型
2.1 卷积神经网络
卷积神经网络是一种深度监督学习下的机器学习模型,具备善于挖掘数据局部特征、适应性强的特点,是近几年计算机视觉、语音识别等众多科学领域的研究热点之一,并逐步在自然语言处理中得到广泛应用.
卷积神经网络的基本结构由输入层、卷积层(convolution)、池化层(pooling)、全连接层及输出层构成[9-12]. 其中,卷积层是特征提取的重要模块,由多个特征映射图组成,其主要特点是局部感知和权重共享. 卷积层的神经元通过卷积核(kernel)与上一层特征面的局部区域相连,由卷积核在整个特征映射图(feature map)上进行卷积,捕捉整个图像或者文本的特征. 而卷积核有深浅之分,浅层卷积核捕捉的是弱抽象类特征,如图像边缘,文本某个词的类别等. 随着层数增多,非线性程度开始增强,卷积后得到的是较深层次的抽象特征,如图像中的具有某些特定形状的物体或者文本中上下文的关系等. 每一层的卷积输出都是对输入信息特征的进一步提取和整合. 池化层位于卷积层之后,同样由多个特征映射图组成,并与上一层一一映射. 池化层用于获取图像或文本中最有价值的信息片段,忽略对模型有少量促进甚至抑制的信息. 从而在保留显著的特征信息的基础上有效降低输出结果的维度,减小了网络规模和参数的作用,防止过拟合. 全连接层是将每一层结点都与上一层的所有结点相连,综合以上提取的全部特征. 为防止此层参数过多而导致过拟合,多数网络中在全连接后加入dropout层随机对参数进行舍弃不更新,以一定概率将全连接隐层结点的值设为0[11].
2.2 信息安全漏洞自动分类模型
本文采用CNN模型针对漏洞描述的短文本进行安全漏洞分类. 把漏洞分类模型分为3个模块:文本词向量预处理模块;包含卷积层和池化层的特征提取模块;回归分类模块. 结合CNN和文本语义的漏洞分类流程如图1所示.
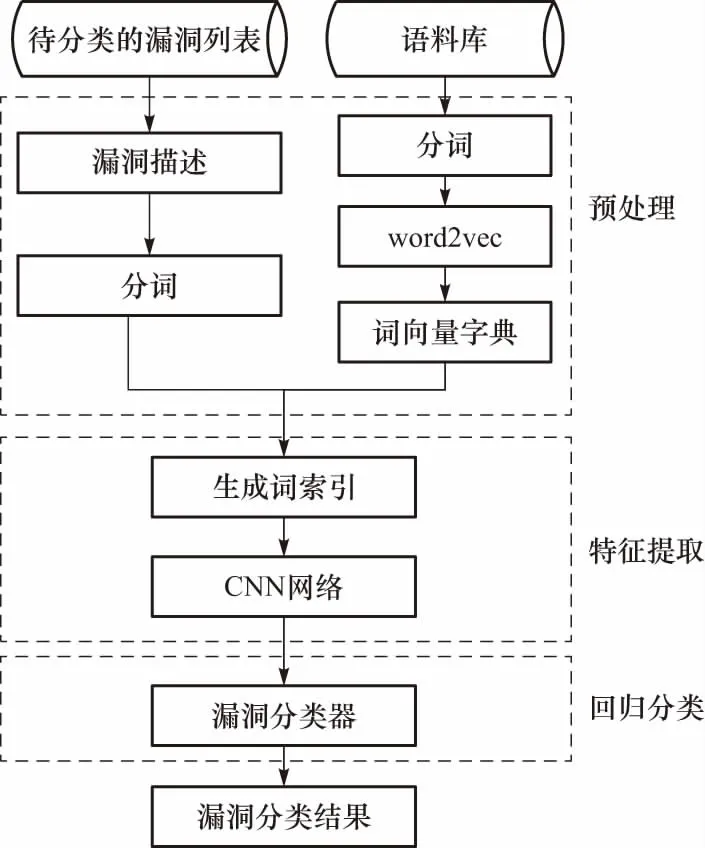
图1 基于CNN的漏洞分类流程Fig.1 The process of vulnerability classification based on CNN
第一部分是词向量预处理模块,对输入的漏洞文本数据进行预处理,包括分词与去除停用词. 对漏洞描述文本进行词处理,然后根据每个词的特征利用Word2vec算法提取每个词的特征,作为CNN模型的输入层. 使用词向量层对文本信息进行矢量化,将原始One-Hot编码的词(长度为词库大小)映射到低维向量表达,降低特征维数. 本质上是特征提取器,在指定维度中编码语义特征,这样语义相近词之间的欧氏距离或余弦距离也比较近.
第二部分是特征提取模块,将矢量层得到固定维度词向量输入到特征提取模块,经卷积层后送入、ReLU激活层、池化层和全连接层. 为防止模型过拟合并在测试集上达到很好的泛化效果,在每层卷积后增加batchnorm层通过batchnorm层对数据做归一化操作去除数据相关性,减小数据的绝对差异,突出其相对差异,使模型更稳定的同时加快收敛速度.
首先,求出当前batch数据x的均值为
(1)
其次,计算当前batch的方差为
(2)
再次,对当前batch数据x做归一化操作:
(3)

第三部分是回归分类模块,本文采用具有类间抑制作用的的softmax层对漏洞文本特征进行分类预测. 训练时采用交叉熵函数计算漏洞分类损失,公式如下所示.

(4)

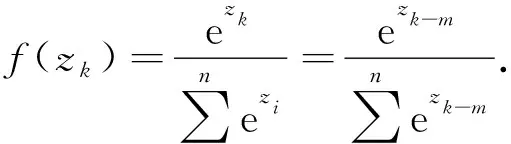
(5)
m=maxzi.
以漏洞描述“远程攻击者可通过提交特制的URL利用该漏洞绕过身份验证,访问重要的服务.”为例,其安全漏洞类型判定示意图如图2所示.
步骤1 对该段描述进行预处理,输出“远程 攻击者 提交 利用 漏洞 绕过 身份 验证访问 服务”,并将其进行矢量化;
步骤2 通过CNN网络的卷积层、池化层、全连接层,对该矢量层进行特征提取;
步骤3 通过回归分类计算,根据漏洞类型最大概率,该漏洞类型为授权问题.
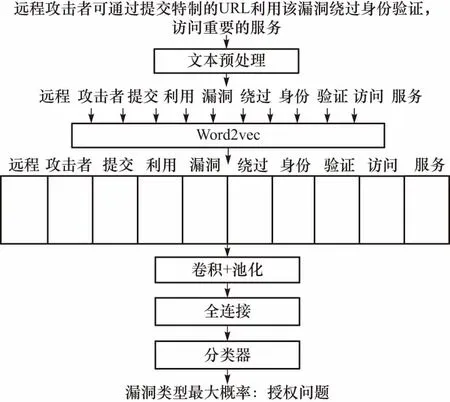
图2 基于CNN的漏洞分类模型结构Fig.2 The structure of vulnerability classification model based on CNN
3 实验及结果分析
3.1 实验数据
本实验数据来自国家信息安全漏洞库(CNNVD)发布的互联网公开漏洞信息,截止2018年6月13日,CNNVD收录漏洞数据总量已达110 736个. 本文选取其中最为常见的6个漏洞类型进行实验,分别是:输入验证、授权问题、注入、缓冲区溢出、跨站脚本、信息泄露. 其中每个漏洞信息包含以下属性项:漏洞名称、CNNVD编号、漏洞类型、危害等级等. 本文采用CNNVD的漏洞描述文本作为输入,按照6∶1的比例分配训练集与测试集. 表1为CNNVD漏洞数据样例,截取本文重点关注项目.

表1 CNNVD漏洞数据描述Tab.1 CNNVDD escription of vulnerability data
3.2 评价指标
采用图像分类任务中的F1值作为衡量漏洞分类的性能指标,计算F1值公式如下:
(6)
F1可以同时兼顾召回率R(recall)和准确率P(precision)反映漏洞分类模型的整体性能.
3.3 实验结果和分析
实验采用facebook开源框架pytorch搭建CNN网络进行验证漏洞分类效果[13],在CNN模型中使用word2vec预先训练256位词向量. 采用inception网络结构提取特征,选择3、4、5三种尺度的卷积核,每种卷积核数目设置为相同的数值,最后分类输出数目为6,使用自适应梯度优化算法ADAM训练模型. 同时为了验证batchnorm的有效性,本文尝试两种实验策略.
策略1:去除所有batchnorm层,在最后的全连接层后增加dropout层,dropout层随机参数设为0.5.
策略2:去除dropout层,所有卷积层和全连接层增加batchnorm层. 经试验表明如图2所示,增加batchnorm层的分类模型在20 000次迭代即收敛到稳定,而dropout达到相同的F1值需要40 000次迭代. 采用batchnorm层可以提升1倍以上的训练速度,性能较dropout网络模型高1个点,而且模型具有更好的稳定性.
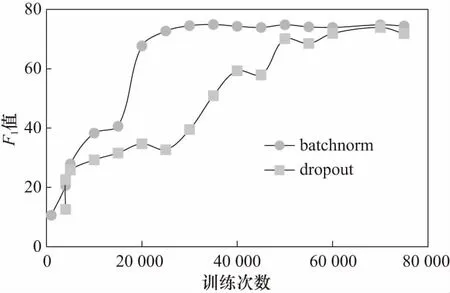
图3 收敛速度曲线图Fig.3 Curve of convergence rate
本文进一步与传统文本分类方法SVM模型进行比较,在表2中,“Ours_DropOut”是在CNN基础上增加DropOut层,“Ours_BatchNorm”是在CNN基础上每个卷积层之后增加BatchNorm规范化数据,由表2实验结果可知,基于CNN和文本语义的漏洞自动分类方法显著高于传统SVM方法.
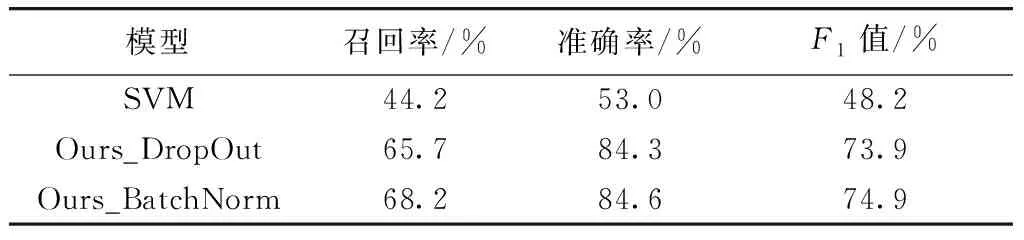
表2 漏洞分类测试结果Tab.2 Vulnerability classification test results
4 结 论
为解决大规模漏洞分类,提出了一种基于CNN和文本语义的信息安全漏洞分类方法,以国家信息安全漏洞库(CNNVD)的漏洞数据作为实验对象,在文本预处理的基础上利用CNN善于从短文本中挖掘特征的优点,对国家信息安全漏洞库收录的信息安全漏洞进行自动分类,实验结果表明相对于传统的分类方法,CNN在准确率、召回率等有了一定的提高. 未来的研究工作主要是将该算法应用到重大安全漏洞的及时快速预警系统上,以便针对漏洞类型的不同危害识别采取有效的防范措施,维护良好的网络安全环境.
