一组用于快速人脸检测的分开Haar特征①
2019-08-22李昱兵周文兴赵季中
李昱兵, 周文兴, 张 霍, 赵季中
1(西安交通大学 电子与信息工程学院,西安 710049)
2(长虹美菱股份有限公司 技术研究中心,合肥 230061)
3(中国航天员科研训练中心,北京 100094)
目标检测过程中目标本身特征是系统检测成功的关键所在,若目标运动或变化、遮挡等,则很难获取目标的真实形态或值. 而今工业、消费领域中的诸多应用场景则对于效率、计算开销要求很高,比如在图像识别中最常见的人脸识别通常是通过对于目标物的背景值和固定点匹配来做区分,从而间接区分出目标图像,通过目标特征值反复确认,以得到最有效的检测结果.
1 哈尔特征
通常目标或运动检测都会采用目标特征检测、计算或补偿,采用不同算法来提高检测效率.
国内外有很多研究者在从事人脸识别研究,提出了较多人脸识别与检测方法,比如Schneiderman[1-4]等人,这其中就开发了基于受限制的贝叶斯网络[1]上的高性能探测器,这个检测器可以实现比较高的检测率,但由于它需要复杂计算,因此它不能被用于实时应用,还有进一步提升的应用空间. Viola和Jones也提出一种能使用哈尔(Haar)特征进行检测的新的Adaboost级联[4]方法,该探测器是第一个具有高命中率的人脸检测实时探测器,同样由于计算开销与复杂度等问题,还需要提升效率.
国内也有不少研究者去研究目标检测,比如区苏[5]提出相对稳定的值作为参考点,模拟相邻帧差分方法来做,但也不能够真正覆盖全部目标值,精确也需要进一步提升. 齐燕武等人[6]研究将Haar-like特征多分类器集成方法中将人的三个维度面,选择其中一个进行训练,另外两面和背景作为负样本,虽然做法也有效能够提供识别率降低误识别率,但多级联分类器的方法效率集成算法在使用时运算时间过长,实时性也有待提升; 江倩殷等人[7,8]提出方法也证实相关背景集成方式将检测的范围缩小,从运动范围区域内去获取Haarlike特征,提升了算法的实时性,这是一种新的思路,但是并不是适合多人群和静止人员的识别. 颜学龙、杨秋芬、蒋政等[9-14]则提出扩展Haar特征、提取特征,以此来获取和训练新的分类器,可相对准确找到与人相关的特征,效率也有所提升,通过他们的研究结果来看,研究成果不但不能够完全有效改善人脸识别的效果,还增加了计算量,应用也需进一步研究和挖掘. 综上分析,结合一般目标识别流程必须性,需要一种新型特征去提高目标位置的识别同时减少开销,因此能进一步提高效率的特征方法是值得去研究.
1.1 提高级联结构
帧国外学者维尔纳(Viola)和琼斯(Jones)的Adaboost级联框架[4]结合了三个关键思想,以达到高命中率和更少检测时间的目的. 首先,该方法需为每个图像使用“积分图”方法来加速Haar特征的计算,这个Haar特征将在第1.2部分中描述. 其次,该方法使用Adaboost算法来选择少量弱分类器一个接一个地连接成强分类器,定义了一个分布P(分布P—样本X的权重表达),采用弱学习算法取得既定弱分类器. 第三,该方法提出由这些每个阶段的分类器结合在一起组成级联分类器(如图1),在这种分类检测器中,每一个子窗口都会被检测到的,级联阶段构成可分为两步,第一步使用AdaBoost练习分类器,第二步不断调整阈值来最大限度减少负误视率.

图1 增强级联分类器的结构图
注意,默认的AdaBoost阈值旨在数据处理,为了在此过程中产生较低错误率. 一般来说,一个较低的阈值会产生较高的检测速度以及更高的正的误视率.
通过这些分类器一个接一个的链接形成级联,该方法中探测器可快速丢弃背景图像. 虽然这些想法非常简单,但比其他方法更有效,比如SVM[2]、贝叶斯决策规则[1]和神经网络[3]等.
1.2 Haar特征
使用的简单特征与哈尔基函数[15]有关. 哈尔特征包含三种类型(如图2左半部分所示),其值是白色的矩形区域像素和黑色矩形区域内像素和之间的差. 这些区域具有相同的尺寸和形状,水平和垂直相邻,但与Haar基础不同,这组特征是过于完整[4].
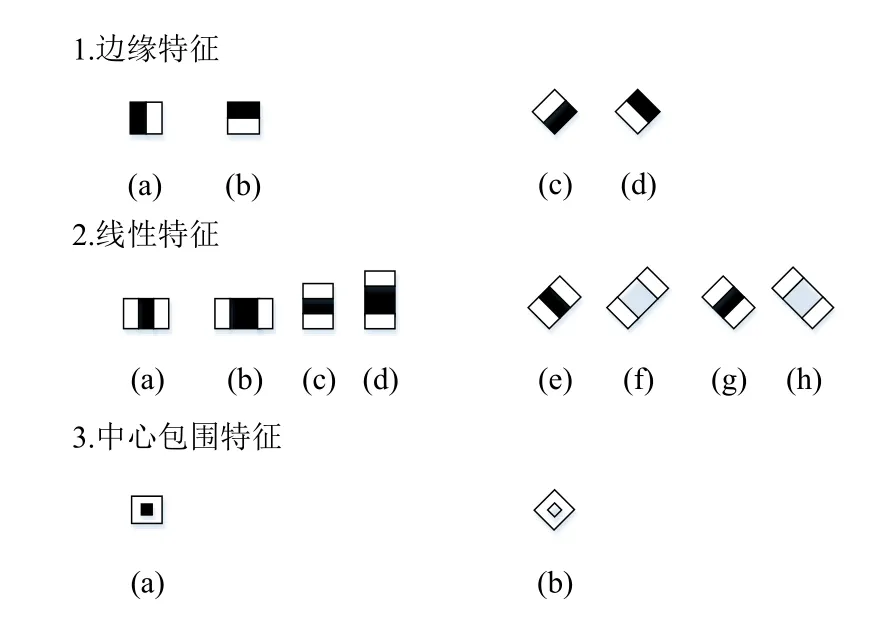
图2 Haar和Haar-Like特征
对于哈尔特征的计算,维尔纳(Viola)和琼斯(Jones)研究成果则是用一个“积分图”来加速Haar特征计算(如图3(a)). 首先,计算原始整体图像的像素值,得到所有左上角区域像素值,然后计算这些像素值的总和为:
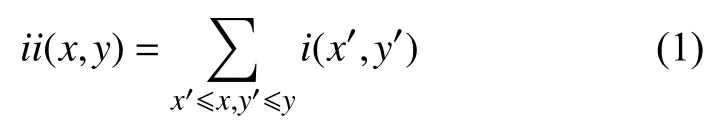
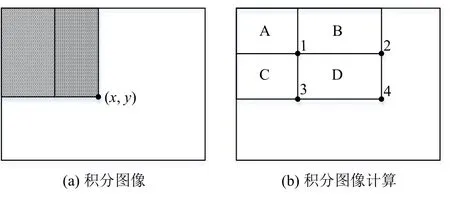
图3 Haar特征的积分图
在特征值计算中,只需要整体图像的4个像素的值来计算一个矩形内的所有像素值的总和(如图3(b)):
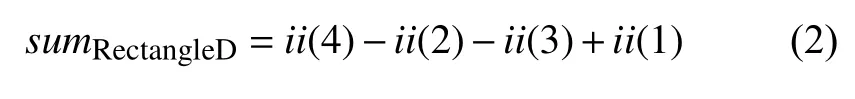
针对上述方式,Lienhart和Maydt[15,16]使用了一组类Haar的特征(图2中的右半部分),通过将哈尔特征旋转45度[5],即一组类Haar的特征(如图4(a)),其也提供了积分图来加速该方法的类Haar特征(如图4)的计算:
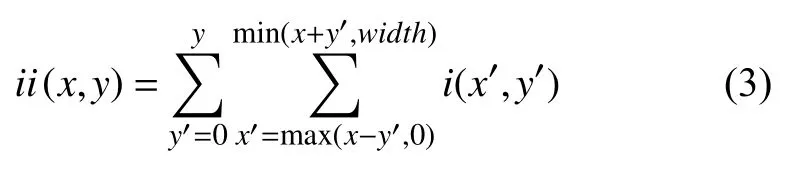
在特征值计算中,这个公式与Haar特征是相同(图4(b)):
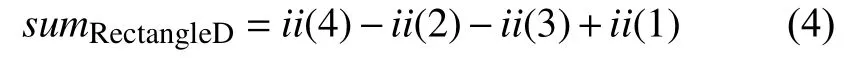
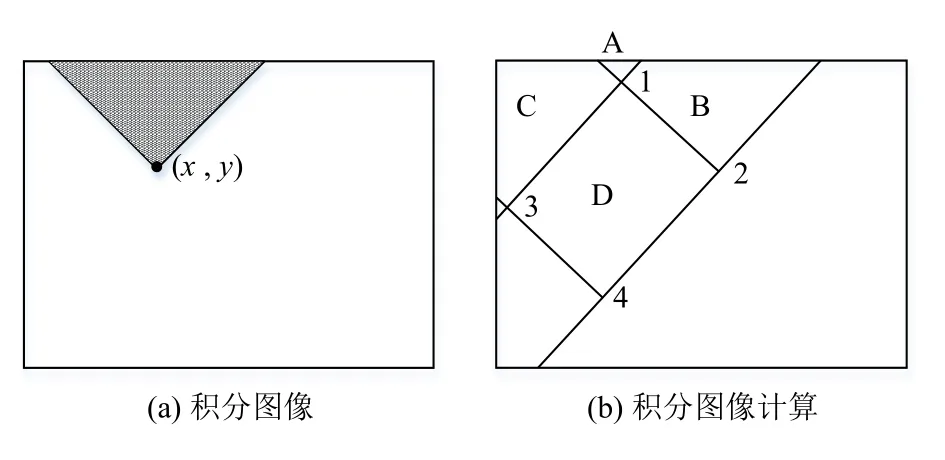
图4 Haar-like特征的积分图
2 分开的Haar特征思路
由于在不同的训练数据集的图像中,Haar特征在相邻矩形的边缘位置和角度不同,一些正样本的边缘不在相邻矩形中间,这使得相邻矩形之间的不同值没有足够能力将负样本分离出来. 因此,本文创新提出在相邻矩形之间添加一个不关心区域(如图5左半部分),即为分开的Haar特征(Sep-Haar). 通过在黑色和白色矩形之间添加一个不关心区域,可以避免在不同的样本中有不同位置和角度的边缘在这个不关心区域被覆盖,这样就可以为每个特征获得一个更有效的值,然后使用一个新的阈值将正样本从负样本中分离出来,从而获得更大的命中率(HR)或更小的误报率(FAR).
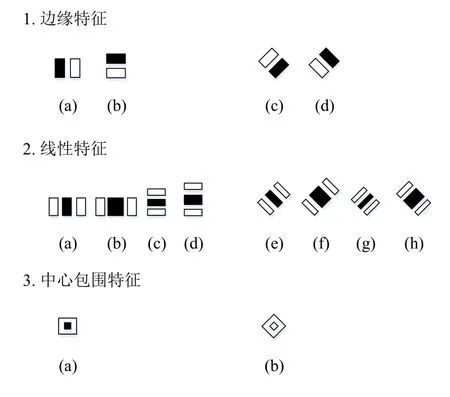
图5 分开的Haar特征
3 使用Sep-Haar特征人脸检测
3.1 宽度选择
在为不关心区域的宽度添加不同值之后,采用这种方式将获得相对于传统Haar特征4倍以上的特征数量,这将增加学习过程中的计算和时间开销. 本文提出为这个宽度选择最好的几个值(如图6中的“d”),基于上图的思路,在学习训练前为训练样本上增加一个从负12度到正12度的旋转过程,让这个不关心区域覆盖所有边的范围为负12度到正12度,以达到检测旋转脸部和取得选择区域宽度的最佳值的目的.
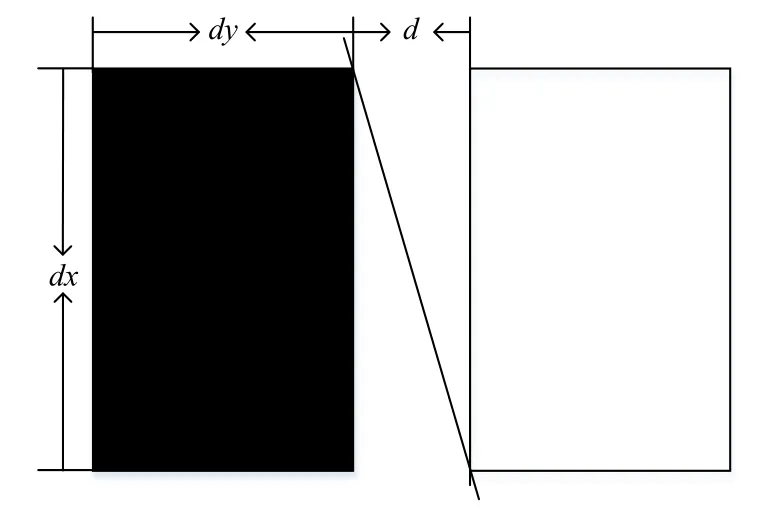
图6 分开的Haar特征宽度参数
因此,本文提出在“dx”和tan(12度)的乘积上选择最佳宽度值“d”:
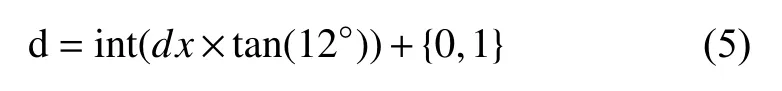
表1显示了间距“d”的选择取决于长度“dx”的值.

表1 “d”的取值
图像是运动目标误判的结果,为什么会出现这种现象? 接下来的实验将揭示原因.
3.2 机器学习
在Adaboost和级联算法中[4],一个误报率阈值用于控制舞台的性能,本文研究提出的Sep-Haar特征可以通过使用很少的弱分类器来实现这个阈值,在检测器学习中使用更多弱的分类器来获得更好的性能(图7),新的特征设计与新的检测器将获得新的创新效果.

图7 机器学习步骤[4]
最佳的阈值是保障能在相同的误报率和检测时间内达到更好的命中率的基础,同时为了保证检测时间,还需要保持每个阶段都使用的弱分类器,并且可将误报率阈值更改为弱分类器数量阈值,通过反复试验找到此最佳值即将误报率阈值设置为原始阈值的0.8倍,就可以达到这个目的.
每个阶段的误报率减少,也可减少级联学习阶段的数量,使用最后的误报率阈值来控制它,当最后的检测器的误报率达到这个阈值时,整个过程学习就完成了.
4 实验
为了更好的测试人脸在小角度偏转下的本特征的人脸检测效果,本实验选用了UMIST人脸数据集(图8)和UMIST脸部测试集[17]进行实验,通过单一的实验结果来验证后这种新的特征设计思路的效果. UMIST人脸数据集是一个多视角数据集,该数据集其中包含了20人564个灰度图像,每个具有各种姿势从一侧到前方. 通过实验,获取总共有10 152个灰色的脸部样本,大小为20×20,这些样本来自于这些564个样本,包括镜像、旋转角度分为负12、正9、负6、负3、0、正3、正6、正9、正12.
图8 UMIST脸部测试集中的样本示例
在检测中,实验中使用UMIST脸部测试集,它包含1148个灰色图像,大小为320×240到640×480,在一个测试图像中只有一个人脸. 首先,使用相同的模型参数来训练两个20个阶段的检测器,这两个cascade分类器在各个stage中的结束性能阈值是一样的,命中率为99.8%,误报率为50%. 其中一个使用传统Haar特性(称之为检测器1),另一个使用Sep-Haar特性(设为检测器2),相同的各阶段结束条件和阶段数意味着检测器1和2有着近似的识别率每个阶段. 本文研究者近20天在台式电脑上完成这一训练学习过程.
使用UMIST人脸测试数据集来测试这两个检测器的性能,图9也反应了学习测试过程中的命中率和误报率的表现,表2中则呈现了总检测时间关系对比.
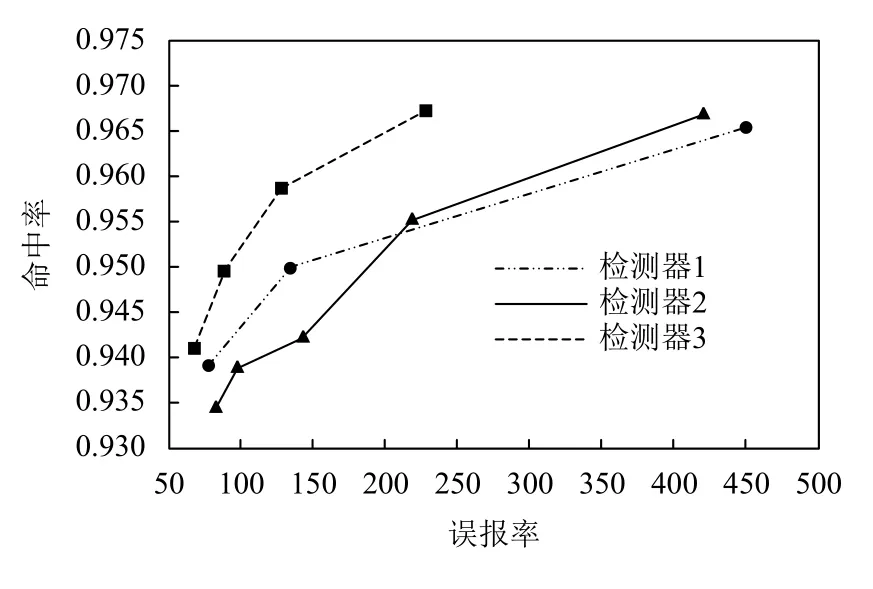
图9 3个检测器的性能比较图
检测器1和检测器2在每个阶段都接受相同的参数训练,这两个检测器的性能几乎是相同的(如图9所示),本文研究结果认为性能的差异来自于每个阶段的细微差别. 由于在阶段训练的Adaboost算法中,它会一个接一个地添加弱分类器(特征),直到阶段的性能达到我们想要的(99.98%的命中率,50%误报率)[4]. 而表2显示了使用Sep-Haar的检测器与传统Haar特性检测器在相同的训练参数下对比,检测2的检测时间比检测器1少约10%. 这是本文提出的Sep-Haar特征的优点.

表2 三个检测器在UMIST数据测试中的时间花费
根据检测器1的20个阶段中每个阶段使用的特征数来训练一个在各个阶段使用相同特征数目、使用不同训练参数并基于Sep-Haar特征的检测器(称之为检测器3),相同的特征数意味着检测器1和3有着近似的运算量和运算时间,让每个阶段的特征数量与检测器1相同. 在级联训练中,每个阶段的分类器都独立训练,让本阶段的弱分类器数目扽与检测器1的弱分类器数目相同,直到最后的检测器误报率远小于检测器1的误报率. 由于使用Sep-Haar特征的每个阶段的误报率都有很大的减少,所以只需要15个阶段就能达到本文研究最初想要的目标. 图9也显示检测器3比检测器1命中率能提高0.8%. 表二显示检测器3的检测时间和检测器1近似(少1%). 综上,在人脸检测的应用中使用Sep-Haar特征训练的检测器可在相同误报率和检测时间中达到高0.8%的命中率.
通过实验验证研究,使用Sep-Haar特征的检测器能够做到减少10%检测时间. 首先在每个阶段都训练几个带有Haar特性和Sep-Haar特性的检测器,且误报率(FAR)分别是0.5、0.1和0.01.
其次实验数据,如表3展示了通过比较不同特征类型和参数中每个阶段使用的弱分类器的数量. 从表3中可以看出,Sep-Haar特征中使用的弱分类器的数量比Haar特征少了8%到10%. 在一个阶段的检测中,需要用阶段分类器来计算弱分类器的所有特征值(如图1(a)),所以减少8%到10%的弱分类器是可以减少10%的检测计算时间.

表3 分类器内部各Stage使用特征数量表
再使用相同数量的弱分类器来训练一些检测器,二者进行性能比较. 通过实验得到的数据如表4显示由于这些检测器的每个阶段使用的弱分类器的数量是相同的,每个阶段的检测时间是相同的,但使用Sep-Haar特征能够明显减小误报率.
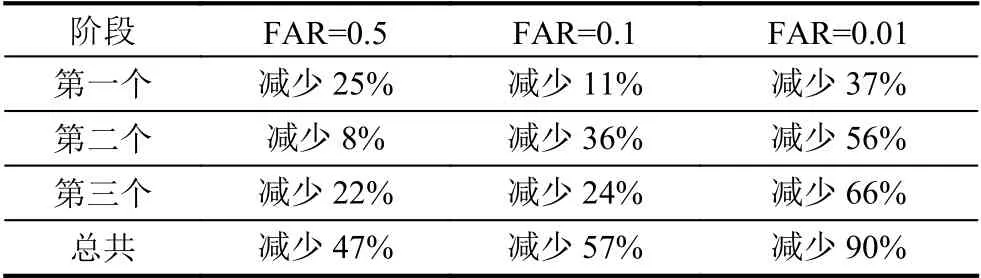
表4 各FAR条件下Haar分类器相同特征数的条件下,分开的Haar特征减少的误报率百分比
5 结论与展望
本文主要介绍了一组用于训练增强级联分类器的Sep-Haar特征的设计思路和验证结果,这组特征在使用不同的训练参数并在每个阶段可以减少误报率30%,或者减少10%的检测时间,命中率也提高了0.8%. 本文研究成果是在总结前人研究成果的基础上,运用了新的设计思路,这种新的技术成果在现有的机器视觉学习和图像处理、检测方面有着较大的应用价值. 通过实验证明本文研究成果即Sep-Haar特征相对传统Haar特征在使用时是更高效的,在人脸识别算法中应用也是真实可行的,它可以广泛应用需要图像检测识别、目标识别的应用中,也能够提高效率.
