增强型稀疏后缀数组索引的高错误率reads比对
2019-08-13韦好,钟诚
韦 好,钟 诚
(广西大学计算机与电子信息学院广西高校并行分布式计算技术重点实验室,南宁530004)
E-mail:394178293@qq.com
1 引言
将高通量DNA测序仪产生的read序列映射(比对)到参考基因组是生物信息学中十分重要的研究问题之一.映射(Mapping)过程是高通量测序技术(HTS)数据处理中的第一步也是最耗时的步骤,它采用索引串匹配的方法将read序列与参考基因组进行比对,确定每一条read在参考基因组上的位置,这一过程在基因组分析流程中起着关键作用.序列比对算法大致分为两大类:基于哈希表索引的算法和基于前缀/后缀树(数组)索引的算法[1].第一类算法通常为参考基因组建立一个哈希索引表,根据“种子(seed)-扩展”策略,将比read短得多的子序列(称为种子)直接定位到参考基因组,然后根据每个映射位置上的种子扩展的结果来确定read的位置.这类算法虽能有效检测识别出单核苷酸多态性(single nucleotide polymorphism,SNP)或结构变异,但其最大的缺陷是内存空间占用很大.基于哈希表索引的代表性的比对算法有BFAST[2]、SOAP[3]、MAQ[4]、YAHA[5]和 FSVA[6].第二类算法通常搜索参考基因组的前缀/后缀树(数组),然后利用BWT(Burrows-Wheeler Transform)[7]方法计算每条 read 在参考基因组中的位置.这类比对算法可以节省大量存储空间和有效地减少参考序列与read序列之间的非精确匹配,但其比对速度较慢.基于前缀/后缀树(数组)的代表性比对算法有BWA[8]、Bowtie2[9]、SOAP2[10]和 HPG[11].
在单分子测序仪的最新进展中,研究人员获得了比Sanger测序仪提供的长度更长的reads.自2010年,Pacific Biosciences发布的第一个实时单分子测序仪PacBio RS以来,单分子测序仪产生的reads长度一直在增加[12].另一方面,long read(长序列)包含参考基因组中较高的错误率(约为15%)、更多结构变异以及错误装配,因此针对long read的比对算法必须允许比对中包含空位(gap)和存在部分比对read序列[13].为了比对 long read序列,2017年,Lin等人提出的Kart[14]算法使用BWT对参考序列建立索引并进行种子筛选,实现有效比对较长的read序列,但当read序列中错误率与突变率较高时,Kart算法的召回率(recall rate)明显下降.
本文采用增强型稀疏后缀数组(enhanced sparse suffix array)[15]对参考序列建立索引,自适应调整种子的最小长度,通过搜索参考序列与read序列之间的最大精确匹配(Maximal Exact Matches,MEMs)和超大精确匹配(Super Maximal Exact Matches,S-MEMs)作为种子查找候选区域,从而有效增加种子集合中的种子数量,以进一步提升比对算法的召回率,实现映射更多的read序列.
2 改进的long-read比对算法
2.1 Kart算法分析
Kart算法将给定read序列及其候选区域划分为简单区域(simple pairs)和普通区域(normal pairs),其中所有简单区域均由MEMs构成.设read序列集R与参考序列G之间的MEMs长度为Lk,MEMs在参考序列G中出现次数为Occ.Kart算法通过BWT数组搜索所有长度Lk大于最小长度h并且出现次数Occ小于50次的MEMs作为种子.当read序列长度增长时,Kart算法对普通区域进行二次筛选种子,缩短普通区域的长度,以达到快速比对的目的.Kart算法中种子的最小长度h的值设定在10至16之间,当read序列长度不断增加时,设定的种子的最小长度值远小于read序列的长度,且通过BWT算法搜索到的MEMs之间会存在大量的重叠(overlap).另外,long read(长序列)中包含许多简单和复杂的错误(例如,插入删除和结构变异).当long read序列中错误率和突变率逐渐增加后,Kart算法的召回率明显下降,这就意味着Kart算法能够识别的read数量大大减少.
2.2 改进的算法
在给出改进算法之前,首先介绍最大精确匹配MEMs和超大精确匹配S-MEMs两个概念[16].
定义1.假定i,j为字符串下标,lm为位置i至j的子串长度.当满足如下条件时,则(i,j,lm)被称为长度n的参考序列G和长度为m的read序列集R中的序列r之间的最大精确匹配(MEM):
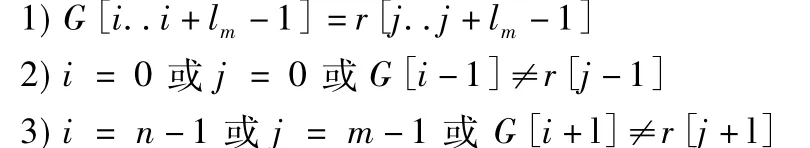
条件2)和条件3)分别被称为左极大性(left-maximality)和右极大性(right-maximality).如果只有条件1)和条件2)成立,则称(i,j,lm)为左最大精确匹配.如果只有条件1)和条件3)成立,则称(i,j,lm)为右最大精确匹配.
定义2.在reads序列与参考序列之间,不被其他最大精确匹配所包含的最大精确匹配称为超大精确匹配(S-MEM).
为了解决Kart算法召回率较低的问题,本文提出一种改进的比对算法,其主要思想是:采用增强型稀疏后缀数组对参考序列建立索引,搜索参考序列与read序列之间的MEMs和S-MEMs,将它们作为种子定位候选区域,然后对候选区域之间的普通区域进行无空位/空位(ungap/gap)比对,以产生比对结果.因为种子长度相对于read长度来说是非常短的,所以种子的最小长度h是影响比对召回率的关键因素之一.为了避免过多MEMs产生重叠,算法初始时依据参考序列长度设定种子的最小长度h.当搜索MEMs和S-MEMs时,依据read的长度自适应调整种子的最小长度h,获取长度大于h的MEMs和S-MEMs.从S-MEMs的定义可知,S-MEMs不与其他MEMs重叠.因此,将所有S-MEMs优先选为种子可以减少MEMs之间的大量重叠.特别地,当read长度越长时,能够找到的S-MEMs越多,种子之间的互相重叠区域越少.相对于MEMs来说,S-MEMs的数量较少,若只使用S-MEMs作为种子,算法的召回率将会降低.因此,本文结合使用MEMs与S-MEMs作为种子进行扩展比对以提高算法召回率.
算法1描述了本文改进的long-read比对算法(称为sufKart算法),算法2给出了搜索MEMs和S-MEMs作为种子的算法.


设read序列集R共有ln条序列,每条long read序列的长度为m.算法2是sufKart算法中最耗时的部分,它对每条long read搜索MEMs,然后在MEMs集合中搜索S-MEMs,搜索MEMs和S-MEMs所需的时间为O(m2+o),其中o为右最大精确匹配的数量.算法1https://github.com/lh3/wgsim中步2循环迭代执行ln次,步7所需时间为O(m2+o),步9和步10所需时间分别为t1和t2,t1和t2均小于O(m2+o).算法1所需时间为lnO(m2+o)=O(ln×m2+ln×o).改进的 long-read比对算法 sufKart的时间复杂度为O(ln×m2+ln×o).
sufKart算法采用增强型稀疏后缀数组对参考序列建立索引,通过搜索参考序列与read序列之间的MEMs和SMEMs的方法,将MEMs和S-MEMs作为种子定位候选区域.在搜索MEMs和S-MEMs之前,根据read序列的长度动态调整种子的最小长度,使得suf Kart算法能够比对不同长度的read序列.同时,结合使用MEMs和S-MEMs作为种子进行扩展的方法能够有效减少种子之间大量的重叠,从而更准确定位到相似区域.因此,sufKart算法可以明显提升召回率.
3 实验
3.1 实验环境与数据
实验使用的计算机配置2个10核Intel Xeon(R)CPU E5-2660,2.2GHz处理器,内存容量128GB,操作系统为Linux ubuntu 16.04 LTS,采用C++语言编程实现算法.
本文采用模拟数据与真实数据进行实验测试,参考序列为人类基因组(hg19).模拟数据采用Wgsim1https://github.com/lh3/wgsim模拟器自动生成,长度分别为 1000bp、1500bp、2000bp、2500bp、3000bp、4000bp和5000bp的read序列;错误率分别为2%,5%,10%和15%,突变率分别为2%,5%,8%和10%.真实数据采用Ion Torrent测序平台产生的reads平均长度为172bp的数据集SRR946843,454测序平台产生的reads平均长度为574bp的数据集SRR003161和PacBio平台产生的reads平均长度为7116bp的数据集M130929.
在模拟数据实验中,本文与文献[14,16]一样使用精确度(precision rate)和召回率作为评估比对算法的性能指标.设read数据集中有N条序列,其中有M条序列被映射到参考序列(即这M条read序列在参考序列中出现),当一条read的映射位置与其模拟映射位置的差值在30bp以内,则认定这条read被正确映射(true mapped)[14].记 reads数据集中被正确映射到参考序列的read数量为TM,序列比对算法的精确度((precision rate)和召回率(recall rate)的计算方法如下[14]:

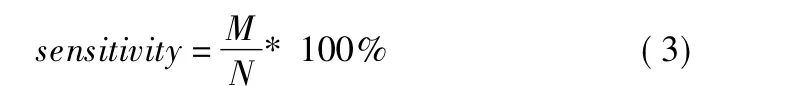
3.2 模拟数据实验结果
首先,对长度分别为 1000bp、1500bp、2000bp、2500bp、3000bp、4000bp和5000bp的模拟数据read序列,对于错误率与突变率不同取值的情况,实验测试sufKart和Kart算法的精确度与召回率.对于不同长度的reads,当错误率分别等于2%、5%、10%和15%(突变率取Wgsim的默认值)时,图1和图2分别给出了Kart与sufKart算法的精确度和召回率.
根据以上公式可知,如果每条read都被正确映射,那么精确度等于召回率.
在真实数据实验中,因为无法预知read的实际映射位置,且最优的比对算法应可以识别最大数量的碱基,所以采用运行时间、敏感度和平均比对长度作为评估指标.比对算法的敏感度(sensitivity)的计算方法如下[14]:
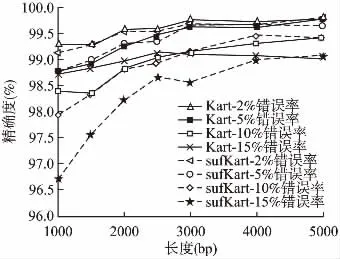
图1 不同错误率的模拟数据上算法的精确度Fig.1 Accuracy of algorithms for simulated reads with different error rates
从图1和图2中可以看出:当错误率为5%、read长度分别等于1500 bp、2000bp和3000bp时,sufKart算法的精确度高于Kart算法.当错误率为5%、10%和15%时,sufKart算法的召回率整体上均高于Kart算法;特别地,当错误率分别为15%、read长度为 1000bp时,sufKart算法的召回率为96.47%,而Kart算法的召回率仅为70.68%.这表明,当read的错误率逐渐增大时,本文的sufKart算法的召回率比Kart算法更高,且能映射更多的reads序列.
对于不同长度的reads,当突变率分别等于2%、5%、8%和10%(错误率取Wgsim的默认值)时,图3和图4分别给出了Kart与sufKart算法的精确度和召回率.

图2 不同错误率的模拟数据上算法的召回率Fig.2 Recall rate of algorithms for simulated reads with different error rates
由图3和图4可知:当突变率高达8%以上时,不论是精确度还是召回率,sufKart算法几乎均高于Kart算法.

图3 不同突变率的模拟数据上算法的精确度Fig.3 Accuracy of algorithms for simulated reads with different mutation rates

图4 不同突变率的模拟数据上算法的召回率Fig.4 Recall rate of algorithms for simulated reads with different mutation rates
在实际应用中,各类测序平台产生的reads不仅仅只包含简单的插入删除错误而且还包括比较复杂的结构变异.因此,本文生成不同错误率和突变率的模拟reads数据集进行实验.表1给出了长度1000bp,错误率分别为2%、5%、10%和15%,突变率为2%、5%、8%和10%时,Kart和 sufKart算法对模拟数据reads进行实验获得的精确度和召回率,其中“E02-R02”表示错误率为2%,突变率为2%的reads数据集,其他类推.
从表1可以看出:当每组模拟数据reads的(错误率,突变率)分别为(2%,5%)、(2%,8%)、(5%,2%)和(5%,5%)时,sufKart算法的精确度高于Kart算法,且召回率几乎也高于Kart算法.当错误率为10%和15%时,虽然Kart算法的精确度稍高于sufKart算法的精确度,但是sufKart算法的召回率远高于Kart算法;特别地,当错误率高达15%时,sufKart算法的召回率比Kart算法高2至3倍.此外,sufKart算法的精确度的值与召回率的值彼此更为接近,也就是说sufKart算法能够正确映射更多的reads序列.

表1 不同错误率和突变率的模拟数据上算法的精确度和召回率Table 1 Accuracy and recall rate of algorithms with different error rates and mutation rates on simulation data
3.3 真实数据实验结果
本文采用3组真实数据集 SRR946843、SRR003161和M130929对 sufKart和 Kart算法进行实验测试.其中,SRR946843是Ion Torrent测序平台产生的平均长度为172bp的reads数据集,SRR003161是454测序平台产生的平均长度为574bp的reads数据集,M130929是PacBio测序平台产生的平均长度为7116bp的reads数据集.两种算法的平均比对长度和敏感度的结果如表2所示.
表2的实验结果表明,对于真实数据集SRR946843和SRR003161,sufKart算法在平均比对长度和敏感度两方面明显高于Kart算法.对于M130929数据集,Kart算法的敏感度与suf Kart算法的敏感度几乎相同;当read序列长度达到7000bp以上时,Kart算法的平均比对长度大于sufKart算法的平均比对长度,这是因为此时sufKart算法中种子集合内的MEMs数量不够多,导致候选区域数量较少,从而降低了sufKart算法的平均比对长度.在运行时间方面,sufKart算法所需的运行时间稍高于Kart算法.这是因为sufKart算法需要花费一些时间,用于搜索reads和参考序列之间的最大精确匹配(MEMs)和超大精确匹配(S-MEMs)作为种子查找候选区域,以有效增加种子集合中的种子数量,从而使得sufKart算法比对结果的敏感度较之Kart算法有所提升.

表2 真实数据上算法的平均比对长度、敏感度和运行时间Table 2 Average alignment length,sensitivity and runtinme for algorithms on real data
综合模拟数据和真实数据的实验结果表明,本文算法sufKart的比对结果在召回率和敏感度总体上优于Kart算法,且sufKart能够识别更多的reads.
4 结束语
本文给出的sufKart算法的新颖之处是:采用增强型稀疏后缀数组对参考序列建立索引,在筛选种子阶段,种子的最小长度依据read长度和错误率进行自动调整,同时搜索MEMs和S-MEMs,产生更多有效的种子,这些种子之间重叠较少,减少了大量去除种子之间重叠的工作,能够更准确的定位候选区域.sufKart算法在筛选种子阶段需要花费较多时间搜索MEMs和S-MEMs以产生更多的有效种子.对于计算密集型的任务,可以采用GPU计算来加速.我们下一步的工作将借鉴文献[17]的并行比对处理思想,研究设计GPU并行算法来提高种子筛选的效率,以减少long-read比对算法所需的时间.
