深度学习人脸识别系统的对抗攻击算法研究
2019-08-13陈晋音周嘉俊沈诗婧郑海斌
陈晋音,周嘉俊,沈诗婧,郑海斌,宣 琦
(浙江工业大学信息工程学院,杭州310000)
E-mail:chenjinyin@zjut.edu.cn
1 引言
深度学习[1]由于其良好的特征学习能力而被广泛应用,包括图像识别[2]、语音识别[3]、生物信息分析[4]、复杂网络分析[5]、自然语言处理[6]等.但是,随着研究的不断深入,研究人员发现深度模型面对对抗攻击存在脆弱性.以人脸识别系统为例,主要用于身份认证,一旦出现漏洞被攻击成功,后果十分严重.因此,研究针对此类应用的攻击,发现其中的脆弱性,对于提高模型的鲁棒性具有重要意义.
目前人脸识别领域中的主流算法都是基于深度学习的,但深度模型易受细微扰动的攻击[7].攻击者通过细微修改输入数据,使得扰动无法被用户肉眼察觉,但机器接受该数据后由原始的正确分类变为错误分类,这就是深度学习中的对抗攻击.一般认为,深度学习模型的高维线性等特征导致了对抗样本的存在,利用对抗样本干扰深度学习系统,这便是近年来人工智能领域出现的对抗攻击.目前具有代表性的对抗攻击方法有快速梯度符号法(Fast Gradient Sign Method,FGSM)[8]、基于雅可比的显著图的攻击(Jacobian-based Saliency Map Attack,JSMA)[9]、C&W 攻击法 (Carlini and Wagner Attacks,C&W)[10]、基本迭代法(Basic Iterative Methods,BIM)[11]以及DeepFool[12]等.图1为图像对抗攻击的一个例子.大熊猫的照片,添加算法生成的微小噪声后,图像识别模型以99.3%的概率将其错误分类为长臂猿[13],但对于人眼来说,无法区分两张图的差别.近期研究发现,对抗样本也可以存在于真实环境中[14],因为对抗样本经过打印后,仍具备欺骗系统的效果,该攻击被称为物理攻击.图2为物理攻击的一个例子,不同的人带着同一副眼镜,被监控识别为另一个人.还有一类情况,是同一个人带着不同的眼镜,可以冒充不同的人.

图1 图像对抗攻击实例Fig.1 Image adversarial attack instance

图2 物理攻击实例Fig.2 Physical attack instance
本文主要研究对于人脸识别模型的黑盒对抗攻击,通过面部配件对人脸识别系统进行图片和物理攻击,发现模型面对对抗攻击存在的脆弱性,为提高模型的鲁棒性提供指导.主要研究步骤为攻击模型的设计、面部配件的设计、进化策略的实现、数字与物理环境的实验测试与评估.主要研究对象为谷歌公司最新提出的FaceNet人脸识别框架.应用于对抗攻击的机器学习[16]算法主要涉及了进化算法中的粒子群优化[17](particle swarm optimization,PSO).本文创新点如下:
1)提出了一种基于进化计算的深度学习对抗攻击方法,实现了电子空间与物理空间的黑盒攻击;
2)将对抗攻击应用于目前最流行的FaceNet人脸识别系统,设计生物面部配件,实现电子空间与物理空间的真实场景的对抗攻击.
3)通过本文设计的对抗攻击算法生成大量对抗样本,利用对抗样本实现深度模型的对抗训练,从而有效提高其防御能力.
2 深度学习人脸识别模型的对抗攻击算法
本节主要介绍了待攻击的目标模型、模型的训练、PSO进化策略以及实现物理攻击需要的面部配件设计与理论支撑.
2.1 FaceNet:谷歌人脸识别系统
FaceNet[15]是 Google开发的最新人脸识别算法,通过CNN将人脸图像映射到欧式空间,将图片相似度与空间距离相关联来完成人脸识别任务.FaceNet创造性的使用triplets损失函数,将一个个体的图像与其他个体的图像分开,扩大类间距离,缩小类内距离.在LFW(Labeled Faces in the Wild)数据集上实现了99.63%的识别率.
给定一个图像,FaceNet的输出结果是排名第一的类别和其置信度分数,为适应本文的实验要求,修改源码使其返回排名前三的预测类别及其置信度分数.在这期间只修改输出的类别数量,不修改算法的其他部分,保证不影响模型的内部结构.
2.2 模型训练
为了演示冒充的攻击,本文使用了官方在VGGFace2数据集上预训练的特征模型训练了两个分类器Classifier-6,Classifier-47,分类对象包含了LFW数据集中的部分名人以及亲自为本文测试真实物理攻击的人员.
Classifier-47:包含17位LFW 数据集中的欧美人、17位CASIA-FaceV5数据集中的亚洲人以及12位自愿提供图像的实验人员(作者以及11位同事),每类约20张图片进行训练,用于测试算法生成的面部配件的图片攻击效果.
Classifier-6:包含2位LFW数据集中的名人以及4位自愿提供图像的实验人员(作者以及三位同事),每个人大约使用20张图像进行训练,用于测试算法生成的面部配件的图片攻击效果.
本文使用FaceNet自带的人脸对齐算法将人脸图像在训练之前进行预处理,以规范姿态对齐,同时将输出图像调整为160×160(神经网络要求的输入维度).最后利用FaceNet预训练模型训练这两个分类器,在测试集上均取得了100%的识别率,表明模型本身具有良好的识别性能.
2.3 粒子群优化(PSO)
粒子群优化是一种启发式和随机算法,通过模拟鸟群的行为来发现优化问题的解决方案[17].鸟被抽象为N维空间中的粒子,只有位置与速度属性,并包含一个由目标函数决定的适应度(fitness).在整个种群的运动过程中,每个粒子知道自己当前位置、自己历史最好位置(pbest)和整个种群发现的历史最好位置(gbest).每一次迭代中,粒子通过gbest和pbest以如下公式更新自己的位置与速度.

其中,vi、xi分别为第i个粒子的速度与位置,rand()为介于(0,1)之间的随机数,c1、c2为学习因子.公式(1)、公式(2)为PSO算法位置和速度更新的标准形式.
优化后的PSO加入了惯性因子w,使得粒子能保持运动惯性.其值较大时,全局搜索能力较强;其值较小时,局部搜索能力较强.因此采用动态的惯性因子可以得到更好的寻优结果.本文使用线性权值衰减策略,惯性因子更新如下:

其中Gk为最大迭代次数,wini为初始惯性因子,wend为迭代至最大进化代数时的惯性因子.加入惯性因子后,新的PSO算法粒子速度更新如下:

之所以选择线性权值衰减策略,是为了保证在对抗样本进化初期有较强的全局色彩搜索能力,尽可能避免陷入局部最优;在进化后期,有较强的局部搜索能力,保证算法快速收敛.
此外,粒子的位置受xmax限制,为避免描述对抗样本的粒子脱离有效解空间,本文使用反射墙,一旦粒子的某一维达到边界,则改变粒子速度方向,使得粒子始终处于有效解空间范围.
2.4 进化过程设计
为将PSO应用于本文的研究,本文将一张人脸图片渲染上不同纯色面部配件后的初始对抗样本作为不同粒子,粒子编码方式如下:扰动的所有像素点处的RGB值作为粒子的位置矩阵x,颜色(RGB)变化速度作为粒子的速度矩阵v,通过PSO迭代进化最终得到最优的对抗样本.
每一次迭代中,算法对所有的粒子进行预测获取Top-3置信度,同时也获取每个粒子的扰动像素信息.根据设计的目标函数计算每个粒子的适应值(fitness)根据每个粒子的fitness更新进化过程中的gbest与pbest.再通过更新后的gbest与pbest,利用公式(4)和公式(2)更新每个粒子的速度与位置信息.
在以上过程中,保存每一粒子的历史最优(pbest)以及种群的历史最优粒子(gbest).继续下一次迭代进化.
黑盒攻击时,输入一张图片,可以得到的输出仅为人脸识别后预测的前三类以及它们的置信度分数,本文将这个预测过程建模为O(x),输出称为Top-3.返回的Top-3实际为一个有序列表,包含的三个类别以置信度分数降序排列.对于原始图像(未加入扰动),其Top-3中排名第一的即为真实身份类标label;而对于一张成功实现目标攻击的对抗图像,其Top-3中排名第一的为攻击者设定的目标标签target.
由于黑盒模型FaceNet只返回预测的前三类,如果目标在迭代预测的Top-3中,PSO可以取得进展,更新粒子速度与位置;若目标不在迭代预测的Top-3中,该算法无法计算适应度函数,无法获得进化反馈.为解决这一问题,本文通过一种中间模拟的算法,来保证PSO的连续运行.
为了使得PSO迭代时,对抗性目标函数能够收敛,对于一张图像的预测结果,本文考虑以下情景:
a)若target在Top-3中,则当前目标curr_target为攻击者设定的target;
b)若target不在Top-3中,则将第二高置信度分数的类作为当前目标curr_target;若出现前一次迭代预测中未出现的新类,则将新类作为当前目标curr_target.
算法的目的是通过在连续运行的PSO迭代中通过对不同目标进行中间模拟来达到最终目标,尝试中间冒充可以使得种群离开原先的解空间,朝着可能使target被返回到Top-3的解空间移动.
2.5 物理可实现性
2.5.1 面部辅助配件设计
数字环境的脸部像素扰动虽然可以在图片攻击时实现人脸冒充,但可能无法成功应用于物理场景.为解决这一问题,本文使用面部配件(主要是眼镜框)来实现物理攻击.使用面部配件的一个优点是它可以相对容易的在实际场景中使用,不会轻易被人为识破.打印出的眼镜框等面部配件可以使攻击合理且隐蔽,让攻击者看起来更加自然.
在本文的实验中,先后使用了图3所示的眼镜框.将这些镜框部署到对齐后的人脸图像时,镜框帧分别占据了大约7%.

图3 未加扰动之前的面部配件(眼镜框)模板Fig.3 Facial accessories(glasses frame)template before undisturbed
为寻找实现冒充攻击所需的配件颜色,本文首先将配件颜色初始化为纯色.随后将配件渲染到需要攻击的对象的人脸图像上,通过PSO算法迭代更新配件的颜色.
2.5.2 扰动的对抗性
扰动的对抗性,即生成的配件渲染在脸部图像上后所能达到的攻击效果.扰动的对抗性越好,生成的配件越容易实现攻击目标.
在PSO进化过程中,最终的目标是最小化适应度函数(fitness),即由f(x+r)定义的目标函数最小化,其中r是应用于图像x的扰动.f(.)是根据预测输出的Top-3计算得到的.本文的研究中,按如下公式定义扰动的对抗性函数:

其中,scorelabel表示真实标签在Top-3中时真实类label的置信度分数,scoretop表示Top-3中排名最高的类的置信度分数,当 label不在 Top-3中时,便以 top代替 label;scorecurr_target是当前目标的置信度分数,curr_target根据2.4中定义的方法来确定,rank表示它在Top-3中的排名.当target不在Top-3中时,PSO运行在中间模拟过程,函数应该增加MF(文设定它是一个足够大的惩罚项,远远大于gbest或pbest).如此设计对抗性函数保证尽可能的提高target的置信度分数,降低label的置信度分数,最终使得target的分数排名第一,而label的排名降低甚至掉出Top-3,从而成功实现对抗目标.
2.5.3 扰动的平滑性
自然图像一般具有较好的平滑性和渐变性.为了使得打印得到的面部配件更具有现实特征,更容易被接受,本文需要提高扰动的平滑性.此外,考虑到采样噪声的影响,扰动中相邻像素之间的极端差异不容易被相机精准捕捉.因此,不平滑的扰动不太具有物理可行性和隐蔽性.
为保证扰动的平滑性,对于扰动r,本文定义了平滑度函数T(r):
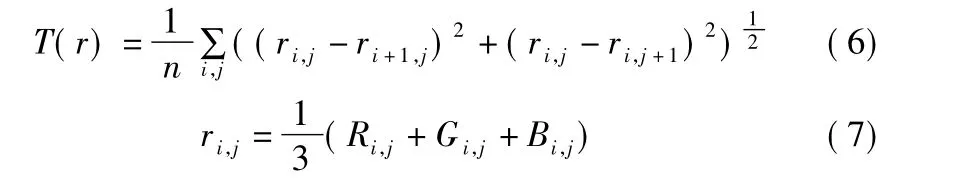
其中ri,j是坐标(i,j)处的r中的RGB三通道像素值的平均.当相邻像素的值彼此接近时(即扰动平滑),T(r)较低,否则较高.因此,通过最小化T(r),本文改善了扰动的平滑度并提高了物理可实现性.
同时,本文定义了两种像素扰动模式,点扰动与块扰动.点扰动模式下,配件区域的每个像素点以各自的进化速度扰动;块扰动模式下,配件按坐标划分区块,同一区块中的像素点按相同进化速度扰动,不同区块间的像素点按不同进化速度扰动.
2.5.4 目标函数
最终,为确保能使图像分类错误并成功冒充目标的扰动是平滑和有效的,本文需要通过求解以下多目标优化问题来寻找扰动:

其中k是多目标函数的平衡系数,本文称之为平滑系数,x是攻击的原始图像.
3 实验结果与分析
实验平台:i7-7700K 4.20GHzx8(CPU),TITAN Xp 12GiBx2(GPU),32GBx4 memory(DDR4),Ubuntu 16.04(OS),Python 3.6,Tensorflow-gpu-1.3,Tflearn-0.3.21.
3.1 点扰动镜框实验
本文在实验初期主要针对面部配件中的眼镜框进行了4组点扰动实验,分别攻击2.2节中提出的两种分类器,在每组实验中,本文改变了分类器和平滑系数,具体设置如表1所示.
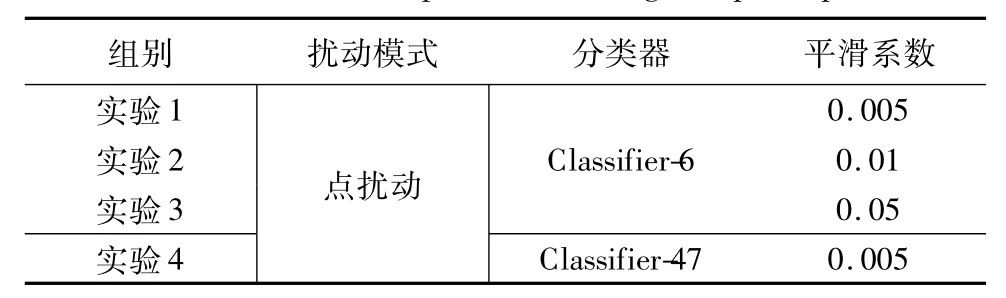
表1 点扰动镜框实验设置Table 1 Glasses frame experiment settings of point perturbation
在每组实验中,作者从相应分类器被训练的对象中挑选了4个{label-target}对,进行4组测试.其中两对随机选择,另外两对进行挑战性的测试,即target不在FaceNet针对源图像预测返回的Top-3中,用于检测本文提出的中间模拟算法的有效性.
每次进行冒充攻击,在PSO运算时,通过随机生成60幅不同颜色的纯色眼镜,将之渲染到源图像,初始化60个粒子.PSO的迭代周期设置为750,MF设置为40,gbest和pbest的权重 c1、c2设置为2,惯性因子从0.9 衰减到0.5.
在2.4节的算法设计中,规定了适应值(fitness)低于设定阈值且在连续60次迭代周期中不再减小,或者超过最大迭代周期数,则PSO运算结束.对于冒充攻击,衡量攻击成功的标准是源图像被预测分类为指定的目标.根据PSO运算结束时的样本预测情况,成功率统计如表2所示.
实验1-实验3针对分类器Classifier-6,平滑系数递增.图4展示了实验1-实验3的源-目标对以及在不同平滑系数下生成的对抗样本,列(a)为执行攻击的冒充者(label),列(b)至(d)分别为平滑系数等于 0.005、0.01、0.05 时的对抗样本,列(e)为冒充对象(target).表3展示了实验1-实验3攻击成功时的结果数据.表3中iter_num为攻击成功时的迭代轮数,score为预测对抗样本时target的置信度分数,T(r)为生成扰动的平滑分数,fadv为生成扰动的对抗性分数.
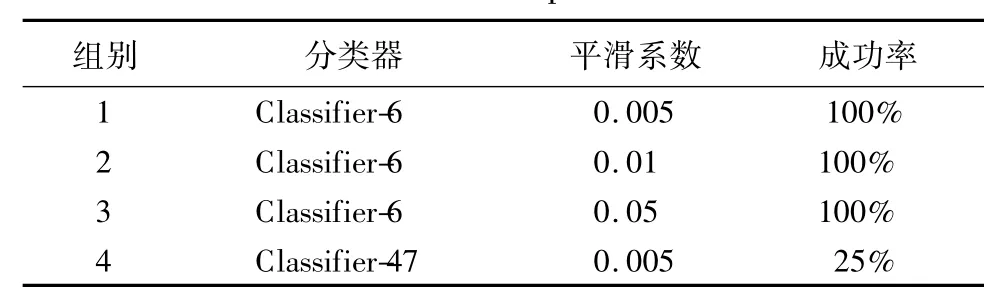
表2 镜框实验成功率Table 2 Glasses frame experiment success rate
在实验 1-实验 3 中,平滑系数设置分别为 0.005、0.01、0.05.这是一个参数调节过程,在保证攻击成功的情况下,寻找尽可能使扰动更平滑的系数约束.以实验2的测试2为例,Zhoujiajun被指定冒充Jincongcong,源图像以91.46%的高置

图4 实验1-实验3成功冒充案例Fig.4 Example of successful impersonation in experiment 1-3

表3 实验1-实验3测试结果数据汇总Table 3 Experiment 1-3 test result data summary
实验4中4组测试只有一组成功实现冒充.根据实验设置进行分析,对于攻击成功率低的原因总结如下:
1)多目标函数中的扰动对抗性和平滑性相互制约,扰动越平滑不一定代表对抗性越好,从而导致目标函数虽然收敛但未能达到攻击成功的效果;
2)扩充数据集时,训练的分类器类标过多,可能导致中间模拟过程向有效解空间移动更加困难,可能导致攻击成非目标类;
3)代码优化问题.
针对上述原因,在后续实验中修改设置,继续尝试攻击.
3.2 块状扰动镜框实验
为了使眼镜上的扰动与现实世界中设计的眼镜框架纹理更贴近,本文将眼镜扰动按坐标区分为若干块.点扰动模式下,配件区域的每个像素点以各自的进化速度扰动;块扰动模式下,同一区块中的像素点按相同进化速度扰动,不同区块间的像素点按不同进化速度扰动.针对块扰动,本文进行了2组实验,分别攻击2.2节中提出的两种分类器,在每组实验中,设置了不同的平滑系数,具体设置如表4所示。

表4 块扰动镜框实验设置Table 4 Glasses frame experiment settings of block perturbation
实验5针对同一{label-target}对,在不同区块数量设置下进行了三组对比测试,图5展示了实验5在8、16、32区块扰动下生成的对抗样本.

图5 实验5中不同数量区块扰动对抗样本对比Fig.5 Comparison of disturbance examples from different quantity blocks in experiment 5
实验6针对Classifier-47分类器,选择同实验1-实验3中相同的4个label进行实验.考虑到数据集扩充后,增加类标数量对攻击成功率的影响,故将平滑系数设为0,即从目标函数中删除平滑指标,仅保留对抗性指标,尽可能提高攻击成功率,因此,攻击成功率可达到100%.图6展示了实验6的源-目标对以及在不同区块下生成的对抗样本,图6(a)为执行攻击的冒充者(label),图6(b)至图6(c)分别为区块为16,32时的对抗样本,图6(d)为冒充对象(target).表5展示了实验6攻击成功时的结果数据.表5中block_num为划分的区块数,iter_num为攻击成功时的迭代轮数,score为预测对抗样本时target的置信度分数,fadv为生成扰动的对抗性分数.

表5 实验6测试结果数据汇总Table 5 Experiment 6 test result data summary
相比于实验1-实验3中的点扰动和平滑指标约束,实验6因采用块扰动,且删去了平滑指标,加快了平均攻击成功时间;但块扰动因具有相对简单的像素分布,故具有的对抗性较弱,使得攻击成功时traget的置信度分数较低;有趣的是,实验6-4的结果中 fadv等于0,因为对抗样本经FaceNet检测返回的Top-3中不存在原始对象label,即原始对象label的置信度排名已经跌出前三,从而达到了公式期望的最佳攻击效果.

图6 实验6成功冒充案例Fig.6 Example of successful impersonation in experiment 6
3.3 对抗训练
对于实验6分类的模型,进行四次对抗训练,每次训练向训练集中加入部分扰动样本.分别用干净样本(Clean test set)和对抗样本(Adv test set)进行测试,模型识别精度如表6所示.

表6 对抗训练的测试精度Table 6 Test accuracy for adversarial training
未经过对抗训练的情况下,分类器对对抗测试集的识别精度为0,经过对抗训练之后,分类器能成功识别部分对抗样本.经过4次对抗训练,对抗样本对模型的攻击效果为0,分类器能正确识别所以对抗样本.除此之外,经过对抗训练后,分类器对干净样本的测试精度也有一定的降低,但是降低幅度略小,不影响分类器识别效果.
对抗训练作为传统的对抗防御策略,能在一定程度上加强模型的鲁棒性.对对抗样本的预测能力随着对抗训练轮数的增加而提高,图7显示了随着对抗训练轮数的增加,模型在对抗样本正确标签的预测置信上的表现.
随着对抗训练轮数增加,模型对对抗样本正确标签的预测置信度不断提高,最终预测正确,达到防御的效果.
4 结语
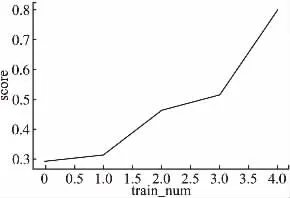
图7 对抗训练后对抗样本分类为正确类标的置信度Fig.7 Confidence in classifying adversarial example into correct class after adversarial training
目前图像识别的对抗攻击多数局限于数字环境,本文通过固定扰动位置,针对适合进行物理攻击的人脸识别场景,通过生物面部配件对最新的人脸识别框架FaceNet进行了人脸对抗攻击.本文通过使用改进的PSO进化策略生成对抗配件,在数字环境中实现了较好的攻击效果;通过打印并佩戴对抗配件,在真实环境中依然能实现冒充攻击,证明了物理攻击的可实现性.最后利用对抗训练进行了防御测试,验证了该方法能提高模型鲁棒性.
