高并发系统解决方案与分布式技术选型探讨
2019-08-10陈代旺
陈代旺

摘要:高并发在实际生活中随处可见,然而解决方法却是一个难点,但这个问题又不得不去优化甚至解决。本文主要围绕“高并发的产生以及解决高并发的一些思路”展开叙述。其中包括在解决高并发问题中系统所采用的一些常用解决方案、同类技术的选择、采用相关技术后带来的新问题及其解决方案,并且本文只探讨后端主要框架,暂时不考虑数据库层面。
Abstract: High concurrency can be seen everywhere in real life. However, the solution is difficult, but this problem has to be optimized or even solved. This article focuses on "the emergence of high concurrency and some ideas for solving high concurrency". These include some common solutions used in the system to solve high concurrency problems, the choice of similar technologies, new problems brought by the adoption of related technologies and their solutions, and this article only discusses the main framework of the backend, temporarily not considering the database level.
关键词:高并发;分布式;Spring Cloud;OAth2.0
Key words: high concurrency;distributed;Spring Cloud;OAth2.0
中图分类号:TP311.5 文獻标识码:A 文章编号:1006-4311(2019)17-0251-03
0 引言
所谓高并发就是在一个时间段内产生多个请求(我们可以简单理解为“同时”),这些请求可能是系统能处理的,也有可能是系统不能处理的。但是我们一般请求下谈到的高并发是系统处理不了的情况,因为它并没有一个标准,而是相当于系统而言的,所以本文后续提到的“高并发”默认是指系统满负载情况下还不能满足需求的情形。以学校教务系统为例,正常情况下我们可以在系统中正常进行各种操作,但是如果到了选课的时候就可能会出现相应缓慢、部分用户无法访问和服务器直接宕机等情况,在选课的时候就处于高并发时段,这个时段中服务器压力增大以至于产生各种不希望出现的情况。比如一台服务器每秒可以处理1000请求,但是在某一个使用高峰期中,每秒产生了1500个请求,这个时候就产生了高并发。对于这个问题,我们的解决方案可能有:多出的500请求直接被丢弃、等待系统处理完其他1000请求后再来处理这500请求、增加服务器数量来提高系统处理能力。下面我们将对上述所谈到的三个解决方案进行分析与实现方法,并选出一个尽可能好的方案深入研究讲解。
1 现代系统常用架构方式
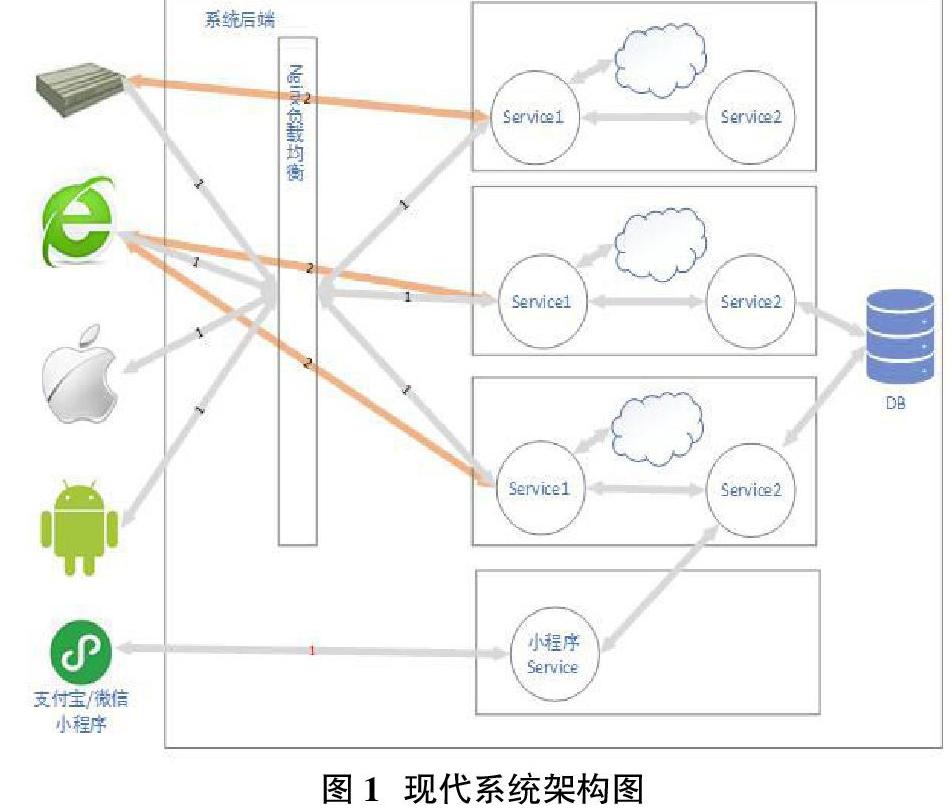
在现代系统中(特别是用于商业用途的系统),我们可能会为了用户的使用方便而为系统提供WEB界面;但是可能有部分功能是在WEB界面上难以实现或者无法实现的,这个时候我们可能会为系统提供Android端和IOS端;但是由于现在用户设备配置等原因,大多数用户都不想在自己的手机上安装太多的软件,所以我们又把系统常用功能提取出来放在小程序端;还有可能有些业务需要后端直接与相关硬件相连,为他们提供数据服务,比如收款所用的POSS机。如“图1”所示,尽管终端可能会以各种不同的形式出现,但它们的最终目的都是用于系统后台数据落地展示以及相关数据的收集,所以我们很容易从图中看出整个系统的核心便是系统后台,只有系统后台稳健运行为所有依赖它的终端提供正常快速的服务才能保证各终端正常工作并且使系统数据同步更新。
2 高并发解决方案
2.1 数据异步处理
在传统的网络编程中,我们尝尝采用同步的方式进行请求,即我们请求一个方法或者网络接口获取数据时,请求方需要一直等待被请求方处理完成并且返回处理结果或者等待时间过长达到超时时间后,请求方才能进行下一步操作。一般情况下,实际应用中的系统处理速度不可能永远比产生任务的一方慢,而是有时候处理速度更不上任务产生方(这里不考虑在某些情况下系统并未达到满负荷而处理能力未增加,只简单假设系统性能与处理能力成正比),大部分时间里系统处于空闲状态。如果以二八定律来看,正常情况下,一天中只有20%的时间里对系统的使用率会很大,而系统在80%的时间里都处于“空闲”状态或者负载量极轻。所以我们可以利用这个定律充分利用系统资源,即将20%的高峰请求的一部分分摊给其余80%的空余时间里给系统处理。
由于系统在收到请求时不一定会马上进行处理并返回结果,而是将该请求暂存起来等系统有空闲时间了再去处理,所以从设计开始就不能让请求者等待系统返回处理结果,而是当系统处理完成后,系统通知请求发送者或者按照事先约定的规则进行下一步操作。而收集请求的一部分通常采用中间件来完成这个操作,如消息队列中间件,它以超高的速度使得发送过来的请求全部收集起来,并按接收的顺序将请求转交给处理系统进行处理。
2.2 服务器集群+负载均衡
在实际应用中,往往有很多操作是我們必须要实时等待对方处理结果后才能进行下一步操作,这种情况下就不能完全使用2.1介绍的方法,但是我们能对处理系统进行优化,使其能处理更多的请求,比如代码优化、提升服务器CPU的运行速率以及直接增加服务器的数量等。而直接增加服务器数量应该是最简单也最有效的方式。我们将多台服务器做同样的工作称之为“集群”,在一个集群中,我们请求集群中的任何一台服务器都能得到相同的结果,这样就能提升系统的处理能力。
但是请求者需要怎样决定自己将请求发送到哪个服务器有是一个问题,因为在理想的情况下,我们总是希望相同配置的服务器在单位时间能处理的请求数是相同的,所以我们可以采用负载均衡在解决这个问题。如“图1”所示,负载均衡分为服务器端负载均衡和客户端负载均衡,常见的服务器端负载均衡就是通过Nginx做反向代理,也就是说请求者将所有请求都发送给Nginx,再由Nginx去决定请求哪一台服务器,“图1”中标“1”的请求就属于服务器端负载均衡。客户端负载均衡是指客户端在请求前就已经知道了可用的服务器列表,而自己需要请求拿一台完全由客户端自己决定,而这种情况通常是由相关算法计算出来的,“图1”中标“2”的请求就属于客户端负载均衡。
3 系统拆分
一个单体系统中,随着时间的推移,它所存在的缺陷就会逐渐被暴露出来。
从应用性能来看,如果一个应用本身就面临性能方面的瓶颈,那么将其拆分后部署于多台服务器上会极大地减轻因性能带来的问题。从“图1”中可以看出,一般系统都是以暴露接口的方式对外提供服务,而且可能有各种功能不同的接口,随着应用的拆分,可能有一部分接口也随着功能的分离而被拆分出去,这样就能给原来的服务器减轻很大压力。
从开发角度来看,随着新功能的增加,系统结构可能会越来越臃肿,越来越不利于后续的维护工作。因为在一个系统中,可能存在多个子模块,从宏观上看这些模块组成了一个完整的系统,但如果就某个具体模块而言,它或许可以被独立开来,也或许只有小部分功能需要与其他模块进行耦合,但是这部分可以采用接口调用方式降低他们之间的耦合度。而这样做可能导致连专属于该系统的数据库部分都能被独立出来,所以数据库也可以使用不同的机器来部署,从而使系统性能进一步提升。这样做拆分后,从整体上看,系统模块更多,需要维护更多的节点,出现问题的可能也就越大,但是从局部来看,我们的开发逻辑却更加清晰,因为在系统开发中,往往都是循序渐进对功能进行逐渐完善,而非一气呵成,所以大多时候开发人员关注的只是其中一个点而已,从而使得开发逻辑更加清晰明了。
从维护角度来看,上面虽然也说到了其中的不足之处,但是其好处也是显而易见的,因为维护人员的最终目标是尽可能地使系统能够稳健运行,能达到我们使用的需求。而在上述问题中,我们总是担心可能会因为其中一个模块宕机而影响整个系统的正常工作,所以在实际生产中,常常是将所有模块都单独部署两份及其以上,即常说的集群,而每一份就是一个独立的服务,当其中一个服务宕机后还有其他的服务器来维持整个系统的运行,并且就算整个模块全部宕机,那也只会影响到需要使用该模块的部分,其他不相关模块将不会受到影响。
4 服务间通信技术选择
在单体应用中,经常存在方法(函数)调用的情况,在调用过程中,我们可能会向一个方法传递相应参数,然后等待方法的返回结果,但是在分布式系统中,这些服务通常在不同的计算机上运行,这种情况下我们就不能向以前调用方法一样调用其他服务的方法,调用方式就变成了模块之间的相互调用,而这种调用很明显不是直接的函数调用,而只能通过网络远程调用完成,这种通过网络来发送盒接收处理数据的方法,其中就涉及到数据传输方式,即服务间通信的问题。
对应服务间通信的技术,目前常用的有阿里系的Dubbo和Spring Cloud原生方案,在Spring Cloud中,服务提供者以HTTP协议提供服务,服务器消费者在消费时也是通过HTTP协议进行消费,而HTTP是短连接,即每次请求后都会与调用方断开连接,需要使用时在进行连接建立。相比之下,Dubbo则提供了更多的选择,比如Dubbo框架则提供Dubbo协议以及HTTP协议,而Dubbo协议是基于Socket(套接字)协议制定的协议,其特点是服务提供者与服务消费者双方永远保持者连接状态,以便他们之间能够随时进行数据通信。从协议层面看,似乎Dubbo相比于Spring Cloud原生通信更胜一筹,但实际体验时就需要从项目使用场景进行多方面考虑了。原因一,Dubbo在使用时,需要服务提供者与服务消费者双方共同使用一份方法接口,以省去服务提供者Controller层,但是也带来一个问题,那就是当服务提供者需要在接口中增加一个抽象方法时,就算服务器消费者未使用到这个方法也要重新编译并运行才能使双方正常工作,否则就为因为接口不兼容导致错误。原因二,如果忘记对Dubbo配置心跳检测,则长时间不调用服务消费方将可能使双方建立的长连接被断开,从而导致错误产生。反观Spring Cloud原生远程调用,Spring Cloud使用弱依赖进行消费,即在没有实际产生消费时不需要考虑服务的启动顺序(Dubbo如果不配置禁用检测时必须考虑),很多时候也不会因为修改了提供方接口而必须编译并重启消费方服务。
5 数据共享之单点登录
在一个分布式系统中,有些模块是直接面向用户的,而这些模块又可能是以集群的方式进行部署。如“图2”所示,假设该图是由“A服务-1”、“A服务-2”、“A服务-3”和“A服务-4”组成的一个集群,因为这些服务的功能完全相同。当用户第一次请求服务可能是“服务-3”为用户提供服务,但是当用户第二次请求服务是,可能是“服务-1”为用户提供服务,试想一下,假设用户在“服务-3”上完成登录,但是在“服务-1”上没有登录,这是很不合理的,所以我们需要将用户的登录信息进行共享,以至于让所有服务都能访问到。而目前业界常用的解决方案是通过Redis内存数据库来缓存这类需要共享的数据。
6 数据共享之授權认证
一般情况下,我们会将具有某些特殊功能或者其功能和其他模块差别非常大的模块单独独立出来作为一个全新系统。这里也邮件系统为例,它和其他模块既相互独立,同时也相互依赖,从逻辑上看,它们应该拥有独立的登录授权系统,即用户在其他模块登录并不影响在邮件系统的登录,反之也成立,但是系统归属层面上看,不管是邮件系统也好还是其他模块也好,他们都应该属于同一个主体,共同使用同一个账户进行登录。还有可能用户在其他模块已经登录,并且上点击了一个具有明确标题的邮件,从用户体验角度来看,这时候应该直接跳到邮件系统并显示邮件的完整内容,而不应该再去提示登录。
针对以上问题,可能有很多解决方案,比如在跳转前,双方后端系统先进性沟通等,但我认为目前应该采用OAth2.0开放授权协议来完成这一跳转操作更为合理。如“图3”所示,由于整个授权并没有夸系统,所有在使用过程中我们不一定要走完OAth2.0协议的整个流程,我们可以根据实际情况选取一部分即可。比如上述的邮件问题,我们可以在点击时先去认证系统获取一个一次性令牌,这部分对应上述A和B步骤,并且带上令牌和邮件地址去访问邮件系统的认证接口,当认证通过后邮件系统将为用户办理登录手续,并自动跳转到用户需要访问的页面,这部分对应于上述C和D步骤,其中在C和D中间,“Resource Serve”会请求“Authorizatior Serve”以验证“Client”传递过来的Token是否正确。
7 结语
正所谓条条大路通罗马,这句话在程序界也同样适用,所以我们需要根据自己的实际情况对技术进行选型,甚至将已有系统进行改造,从而实现自己的个性化需求。比如我们在开发前期,由于系统大部分地方都需要进行修改等原因,所以这个阶段对于服务间通信就不适合选取Dubbo作为通信框架,因为在这个时候它所具有的逆势远远大于其优势,反观原生Spring Cloud的服务发布方式,其虽然说也具有逆势,但是在一定程度上这种逆势是可以被接受的。
参考文献:
[1]翟永超 著.Spring Cloud微服务实战[M].电子工业出版社,2017.
[2]Spring Cloud https://spring.io/projects/spring-cloud.
[3]骆斌 主编.需求工程:软件建模与分析[M].高等教育出版社,2009.
[4]Dubbo通信协议使用 http://dubbo.apache.org/zh-cn/.
[5]OAuth 2.0 — OAuth https://oauth.net/2/.
作者简介:陈代旺(1996-),男,云南昭通人,本科生,主要研究方向为软件开发。
