柴油增压发动机故障诊断参数数据的可信度研究*
2019-08-05杨丽娟
陈 雷,杨丽娟
(1.西安工业大学 计算机科学与工程学院,西安 710021;2.西安工业大学北方信息工程学院 电子系,西安 710200)
柴油增压发动机结构复杂,工作条件恶劣,使得发动机故障率较高,维修保养费用很大。据统计,发动机各种使用费用中维修保养费占比为15%~30%,且一旦出现故障,发动机的动力性、经济性、可靠性和安全性均会受到很大的影响,甚至会直接影响到发动机的使用寿命[1]。对于发生了故障的柴油机,快速地找出故障发生的原因,并根据故障发生的原因来有效地排除故障,从而保障动力装置能够正常、平稳地运行具有十分重要的意义[2]。
目前,国内外在柴油发动机的应用故障诊断的系统繁多,所做的工作综合来说主要集中在系统结构划分、系统功能划分以及算法实现这3个方面[3-5]。其中典型的故障诊断算法包含基于物理模型的方法、基于数据的方法、基于知识的方法和以智能算法为基础的融合算法。国外已将柴油发动机故障诊断系统广泛用于各类发动机系统中[4-7]。在柴油发动机故障诊断的算法研究方面,国内也做了很多工作,其中主要是采用自联想、自组织及概率等神经网络的发动机传感数据和气路部件的故障诊断方法得到了深入的研究。此外,柴油发动机还采用卡尔曼滤波器、遗传算法、数据统计分析方法、模糊算法、免疫算法及混沌算法等进行了研究[8-11]。但传统诊断方法仅利用传感器的实时数据进行分析与诊断,并未考虑到参数数据可信度以及历史诊断信息,导致诊断结果误报率高。
文中拟提出一种新的经验迭代算法,利用故障诊断信息确定每种诊断参数权重数值,对数据进行可信度加权使其中的野值剔除或者减轻其权重,将各个参数的数据融合得出概率值并判断发动机是否出现故障,以降低误报率。
1 故障诊断方法
故障诊断方法可以分为基于模型的方法、基于信号处理的方法和基于知识的方法。基于模型的方法需要建立比较准确的数学模型,基于信号处理的方法需要利用频谱分析、相关分析及小波分析等各种方法,基于知识的方法主要是利用诊断对象信息,专家诊断知识等[3]。其中发动机的故障诊断的数学模型非常难以准确地建立,错误的数学模型会诊断出错误的结果;发动机的工作环境、年限和功率的变化会引起其信号产生变化,因此若未考虑这些因素带来的影响,分析的准确率将会出现误差;最终利用专家的诊断知识诊断往往能取得意想不到的效果。
由于信息处理技术的发展和新型传感器的应用,柴油发动机的监测数据越来越多。文中采用了基于故障参数加权可信度的故障树诊断方法,柴油发动机的故障树如图1所示。
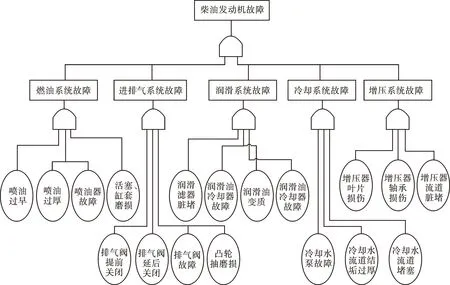
图1 柴油发动机的故障树Fig.1 A fault tree for diesel engines
用于状态监测与故障诊断的信息以各种形式存在于信息载体中,在发动机故障诊断过程中,可以获取发动机的负荷程度、功率、转速、燃油温度、燃油消耗率、滑油消耗量、滑油温度、滑油压力、冷却液温度、冷却液压力、增压器压力、增压器转速、排气温度、进气温度、进气压力和光谱数据等参数的实时数据和历史数据,通过这些参数的监测可以对发动机的故障进行准确的诊断[4]。
从图1中可以看出,引起发动机故障的所有故障状态信息,每个独立系统由不同部件及其故障引起,每个故障的产生由可监控的参数进行监控和诊断。凸轮轴磨损的故障故障树如图2所示。
凸轮轴磨损故障可由冷却水温度、排气、排温、增压压力、功率和光谱进行判断[5]。文中以梅赛德斯奔驰公司生产的OM457LAⅢ/9型柴油机的凸轮轴磨损为例进行实验。
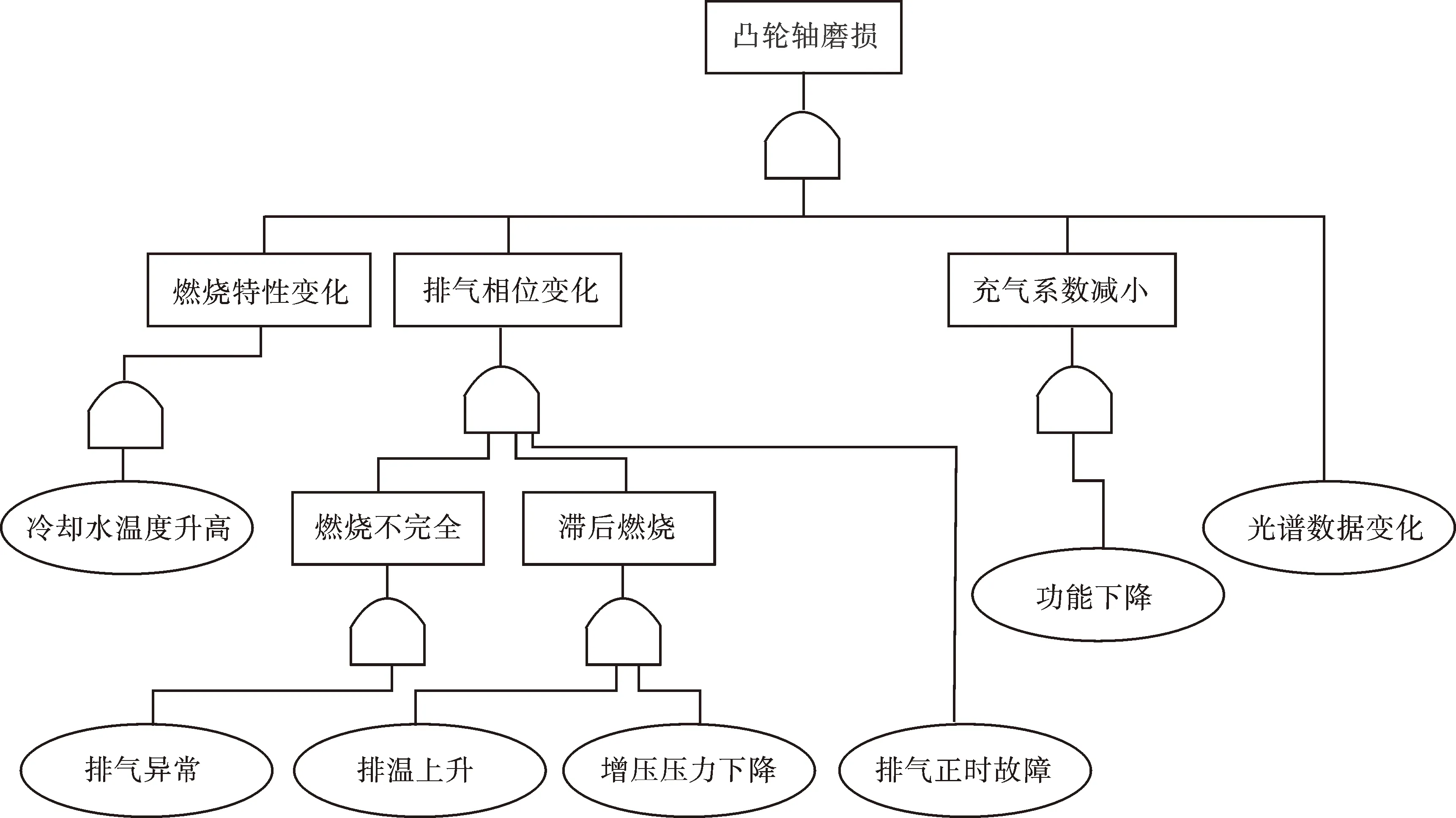
图2 凸轮轴磨损故障树Fig.2 A fault tree for camshaft wear
2 经验迭代算法
诊断系统需要利用多个采集的诊断参数数据作为诊断的输入,但是每个参数的数据对于每种故障的诊断作用程度不同。故障参数对于故障的诊断起到的作用并没有一个准确的定义和说明,因此,本文提出了一种根据参数诊断故障数的初始权值设置方法以及根据诊断结果信息自适应调整参数权值的算法——经验迭代算法。
在诊断某故障之前需确定每个诊断参数的权值,权值的设置多采用平均算法或者专家知识设置,其中平均算法没有考虑到每种参数的差异,而专家知识有太重的主观性。因此,本文提出了一种基于参数诊断故障数目的算法,一个参数能够用来诊断的故障越多,用其来诊断某个确定故障时的权值就应该越低。算法步骤为:
1)根据故障树查找出各个故障的诊断参数分别是几种故障的诊断输入参数。
2)根据参数诊断故障的数目确定初始权值函数γi,表达式为
γi=fi(xi)
(1)
式中:fi(xi)为故障诊断参数数目的函数;xi为判断故障的数目。γi随着xi单调递减。
3)对整个诊断参数的权值进行统一化处理,
即:
(2)
经过上述的处理实现了故障的诊断参数的初始权值,下一步将系统中的历史诊断信息加以利用,若在前面的诊断历史中某种参数对某种故障的诊断起到了作用,则要提高其诊断过程中的诊断权值;若某个参数在诊断中没有起作用或者起了反作用,则要减少其诊断权值。经过调取历史诊断信息进行多次迭代,使得诊断参数越来越准确,算法流程为:
1)系统从诊断信息库读取参数初始权值和最近诊断记录的权值,若没有权值信息,可以根据诊断故障的参数个数平均设置权值。
2)利用各个参数的权值以及经过可信度计算的参数数据进行融合故障诊断,并将诊断结果记录诊断库。
3)系统根据诊断结果对诊断的参数重新调整,调整方法如下:
若某参数的异常对于诊断正确起到了正作用,则对该参数存储在诊断库中的权值w增加一个系数α,同时将该故障的其他诊断参数的权值减少一个数值α*w/n(其中n为其余参数的个数);若故障诊断成功而参数数据没有异常或者起反作用,则将诊断库中的权值w减少一个系数α,同时将该故障的其他诊断参数的权值增加一个数值α*w/n。
4)利用上述的步骤将诊断的所有参数在每次诊断后进行调整,通过多次的诊断,可以将诊断过程中的各个参数的权值训练得越来越准确。
因此,系统确定了故障参数的初始权值,充分考虑了各个诊断参数的差异性。而后利用每次的诊断信息自适应调整每个参数诊断某故障的权值,随着诊断次数的增加,每种故障的诊断参数的权值越来越准确,为提高诊断准确率提供了十分可靠的保证。
3 实时获取参数的加权可信度
程序在利用获取的实时故障参数数据进行诊断时,没有考虑此时传感器采集的数据是否可信。假设传感器异常或者损坏导致采集了错误的数据从而引起数据的不可信,错误的数据会对最后的诊断结果产生错误的影响,因此,本文提出了邻域加权方法,利用传感器获取的序列数据来计算分析诊断时刻数据的可信度,通过可信度的加入可以减少不可信数据对诊断的影响[6]。
假设传感器采集的数据序列为:[x1,x2…xn]。程序将利用时刻t的数据Xt对发动机进行诊断,可以利用t时刻之前的数据进行可信度计算。传感器采集的序列数据服从高斯分布,以它们的高斯曲线作为传感器的特性函数[7],记为Pt(x),Pt-Δt(x)。
用置信距离测度表达时刻t的数据与前时刻数据的偏差大小,设:
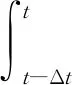
(3)
其中:
(4)
其中dti为t时刻与t-Δt时刻之间数据的置信距离测度,借助误差函数erf(θ),求得
(5)
假设r1表示xt-Δt对xt的支持权重,则r1为置信距离测度dti的函数,并且随着dti递减,根据具体情况可以设置多个数据的支持权重,从而获得多个ri,则:
ri=f(dti)
(6)
其中0≤ri≤1。
则在t时刻的数据xt存在一个一维支持矩阵
R=[r1r2r3…rn]
(7)
xt的真实支持程度应该由R体现,设xt的序列支持程度为ri,ri越大,xt的可靠性越高,则ri应满足以下条件:
由于与t时刻的数据距离越近的数据置信度越高,所以针对不同的时间距离,分配不同的权重系数:α1,α2,α3,…,αn,t时刻参数的综合可信度权值为
r=r1α1+r2α2+r3α3+…+rnαn
(8)
写成矩阵形式为
r=Rα
(9)
其中α=[α1α2α3…αn]T。
利用上述方法分别对所有要进行诊断的参数进行可信度的计算,计算产生了所有诊断参数的权值矩阵:
[αβ…φ]
经过可信度计算后,可利用根据先验知识设置的各参数置信权值进行比对,若采集的参数的可信度低于置信权值的下限,则认为此时的数据不可信,就可以将其视为野值剔除,若此时参数的数据在范围之内,就将此时的数据加上相应权值[8]。程序经过上述处理后,可以将诊断的所有输入参数中的野值进行剔除,其余的数据引入可信度降低了可信度低的数据的影响,加大了可信度高的数据的影响。
4 实验与仿真
文中以发动机的凸轮轴磨损故障为例进行实验仿真,凸轮轴磨损故障检测可以由以下6个参数:冷却水温度、排气、排温、增压压力、功率以及光谱进行检测,故障判据为:冷却水温度升高、排气异常、排温升高、增压压力下降、功率下降及光谱数据变化[9-11]。
本文以实时采集的100%负荷(发动机最大动力与负载相同)下各诊断参数的数据为例进行实验研究,由于光谱数据持续变化,发动机持续排气异常,因此不作为采集对象。图3为实时采集的100组数据,包括冷却水温度、排温、增压压力和功率。
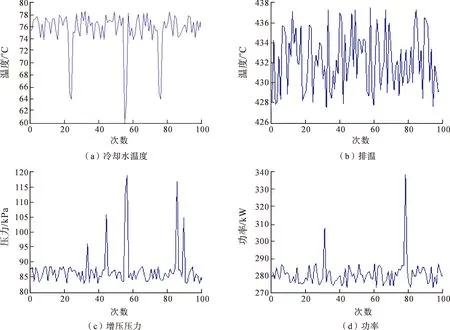
图3 各个诊断参数数据Fig.3 Diagnostic parameters
数据采集完毕,下一步确定发动机诊断参数的性能指标,由于出厂时厂家提供的参数指标随着发动机的工作而不准确,因此,本文利用发动机在100%负荷下运行700 h,每5 min采集一次数据,采集完成后利用统计参数法中的3σ统计法进行界限报警,计算出100%负荷下各诊断参数的正常值范围及故障值见表1。

表1 100%负荷下各诊断参数的正常值范围及故障值Tab.1 The normal value range and fault value of each diagnostic parameter under 100% load
通过表1中的数据诊断范围对实时采集的数据进行故障诊断,其计算方法为:
1)表1中的故障数据分为了5级:正常范围内1级、低于标准值2级和高于标准值2级,因此,本文将参数的故障程度的权值也分5级,为5个级别数据范围设置权重系数分别为:-1.1,-0.8,0,0.8,1.1。根据超限的程度确定各诊断参数超限的权值δi。
2)根据上述的初始权值的算法查找各个参数诊断的故障数目,其中:冷却水温度升高参数是判断6个故障的输入参数;排气异常参数是判断2个故障的输入参数;排温升高参数是判断9个故障的输入参数;增压压力下降参数是判断4个故障的输入参数;功率下降参数是判断13个故障的输入参数;光谱数据变化参数是判断4个故障的输入参数。
3)确定各个参数的初始权值:冷却水温度升高初始权值为1/6;排气异常初始权值为1/2;排温升高初始权值为1/9;增压压力下降初始权值为1/4;功率下降初始权值为1/3;光谱数据变化初始权值为1/4。
4)对各个参数的权值进行统一化处理:经式(2)计算得出冷却水温度升高权值为0.123;排气异常权值为0.369;排温升高权值为0.082;增压压力下降权值为0.184 5;功率下降权值为0.057;光谱数据变化权值为0.184 5。
5)计算数据的可信度:本文利用上述t56时刻的数据进行诊断,此时功率为281.4 kW,排温为434 ℃,增压压力为112.4 kPa,冷却水温度为60 ℃,光谱数据变化且排气异常。通过可信度计算得出功率的可信度为0.96;排温的可信度为0.93;增压压力的可信度为0.67;冷却水温度的可信度为0.58,其他参数没有具体数据且现象一直没有变化,可将其可信度置为1。
6)根据可信度设置参数最终权值:本文设置可信度数值低于0.7的为无效数据,所以增压压力数据和冷却水温度数据不作为计算数据,但是要将其初始权值分配给其他参数。其中各个参数的故障程度权值分别为:增压压力权值为-0.8,冷却水温度权值为-1.1,功率权值为0.8,排温权值为1.1,光谱数据变化权值为1,排气异常权值为1。
经过计算得到了经过可信度计算和没有通过可信度计算的诊断概率情况如图4所示。
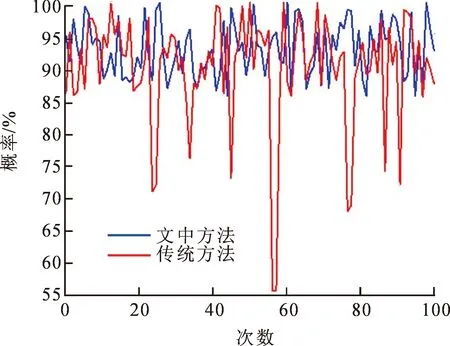
图4 故障诊断概率对比图Fig.4 Comparison of fault diagnosis probability
从图4可以看出,在参数数据没有发生异常的情况下,两种方法的诊断结果基本持平;当某些参数出现异常数据时,文中方法诊断结果更加准确,随着诊断参数异常的增加,诊断结果更加可靠。
5 结 论
本文针对传统的诊断方法没有考虑历史诊断信息的问题提出了经验迭代算法,通过该算法可以使得每种故障参数的自动分配初始权值。对采集的数据的异常进行可信度计算,可剔除野值或者降低异常数据的权重。
以文中方法和传统方法分别进行了实验仿真,实验结果表明:在参数数据未发生异常情况下两种诊断方法的结果基本持平;但是当某些参数出现了异常数据时,文中方法可得到更准确的结果,传统方法诊断概率明显偏低,并且随着诊断参数异常的增加,越能体现出文中方法诊断的优越性。
