注意力机制的LSTM-DBN维语人称代词指代消解
2019-07-23李东欣田生伟赵建国
李东欣,禹 龙,田生伟,李 圃,赵建国
(1.新疆大学 软件学院,新疆 乌鲁木齐 830008;2.新疆大学 网络中心,新疆 乌鲁木齐 830008;3.新疆大学 语言学院,新疆 乌鲁木齐 830046;4.新疆大学 人文学院,新疆 乌鲁木齐 830046)
0 引 言
在篇章级别文本语义的整体理解上,准确没有歧义的指代消解对其具有很大的影响。在信息抽取、自动文摘等自然语言处理中具有重要的作用[1]。Mc-Carthy等[2]将其转换为二分类问题,用于判断先行语和照应语之间的指代关系。王荣波等[3]基于篇章级别设计的多元判别分析模型,提高了句群自动划分的精确度。李国臣等[4]利用机器学习算法结合优先选择策略,针对篇章级别的文本,进行了指代消解研究。Ng等[5]研究了在挖掘语义信息方面指代消解所起的作用。Kong等[6]探索了更深层次的语义信息对指代消解的影响。许敏等[7]采用了格框架的方法进行指代消解。之后,王厚峰等[8-9]在中文领域给出了消解人称代词的基本规则。董国志等[10]提出了将语料库、规则预处理和最大熵模型相结合的方法。王海东[11]和孔芳[12]将语义角色应用在指代消解模型中,实验结果显示,引入语义角色能够更好地提高消解模型的准确率。
上述研究尽管在一定程度上提高了指代消解模型的性能,但是需要人工参与进行特征抽取和分析,因此,仍然存在许多不足。如:过程繁琐,耗时太久;传统浅层学习方法不能够很好地挖掘文本中深层的语义信息;处理复杂问题时,常常会出现泛化能力不足现象;不能很好地挖掘语义的深层细节信息。针对上述问题,文中利用注意力机制、长短时记忆网络和深度信念网络,构建了一种维吾尔语的人称代词指代消解模型。
1 相关研究
随着attention机制和深度学习算法在图像处理、目标检测和语音、视频识别等众多领域的广泛应用,也为指代消解的研究提供了全新的思路[13]。
Collobert[14]将词汇向量化,并作为初始值来训练指代消解模型。胡乃全[15]将特征向量应用在中文人称代词指代消解中,有效提高了系统的性能。Hinton[16]提出了基于RBM的Log-Bilinear语言模型。Hochreiter等利用长短记忆单元(long short-term memory)[17]模型有效解决了传统的RNN训练时的梯度爆炸和梯度消失问题,让RNN能真正有效地利用长短距离的信息;胡新辰等[18]将LSTM模型应用于语义关系分类问题,并取得了很好的效果。随后attention机制被大量应用于各种图像处理和自然语言处理模型中,为进一步解决传统attention机制的局限性,文献[19]将attention机制和RNN模型相结合,并提出全局(global)机制和局部(local)机制。文献[20]利用attention-based得到含有输入序列节点注意力概率分布的语义编码,并将其作为分类器的输入,以缓解特征向量提取过程中的信息丢失和信息冗余等问题。
2 维吾尔语人称代词的特点

人称代词在维语中的形式与汉语、英语有着明显的区别。(1)前者人称代词不包括反身代词,而英语和汉语包括反身代词;(2)维语的第三人称代词不仅没有性别区分,还可以指物体;(3)一、二人称有单复数之分,而第三人称没有。因此维语人称代词的单复数特征,为指代消解的研究提供了一个很好的依据。
3 基于Attention-Based LSTM-DBN的人称代词指代消解
3.1 人称代词指代消解整体处理流程
文中结合attention机制、LSTM模型和深度信念网络实现维吾尔语人称代词指代消解。其基本思想是:首先确定先行语和照应语对应的候选项,构建人称代词特征向量,挖掘出人称代词语义信息;然后利用多层感知器将十一项规则特征与挖掘出的人称代词语义信息进行融合;最后由softmax分类器进行分类,完成消解任务。指代消解整体流程如图1所示。
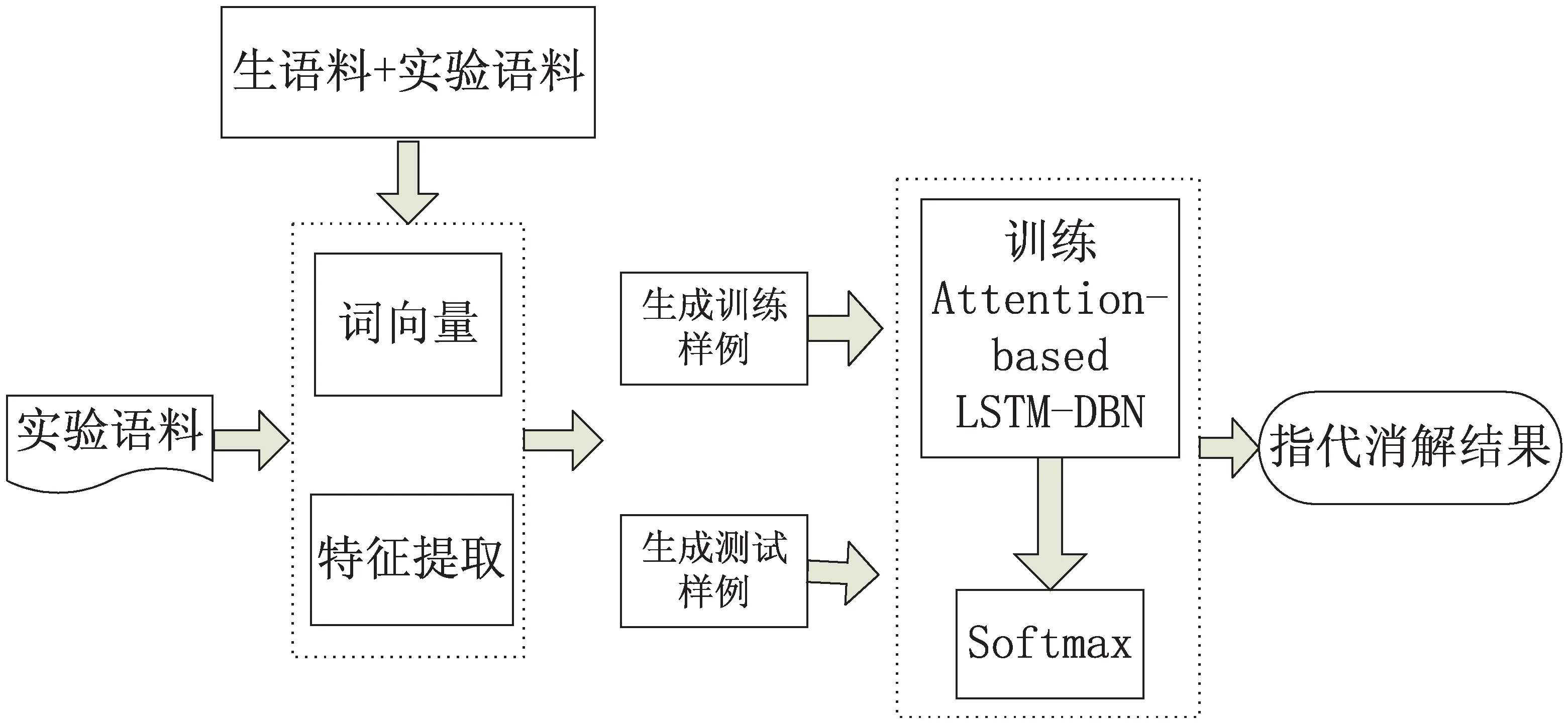
图1 基于Attention-Based LSTM-DBN的维吾尔语 人称代词指代消解框架
3.2 维语人称代词指代消解模型
通过Attention-Based LSTM挖掘文本中照应语和候选先行语上下文的语义特征,并作为深度信念网络的输入;然后经过DBN进一步挖掘出隐藏在文本中的深层语义特征;最后将挖掘出的人称代词语义特征与特征规则融合,经过softmax进行分类,完成维吾尔语人称代词指代消解。


图2 维吾尔语人称代词指代消解模型具体框架
3.3 注意力机制Attention-Based模型
针对在词汇转换成中间向量时,会导致很多细节信息缺失问题。文中通过添加注意力机制来提高模型输出信息的质量,减少计算时耗。
在图2中θ就是历史节点对最后节点的注意力概率,Xi是文本词语向量表示。计算出Xi对于文章总体的影响力权重,可突出关键词的作用,减少非关键词对于文本整体语义的影响。文中在编码阶段使用Attention-Based机制。维吾尔语人称代词语义特征表达式为:
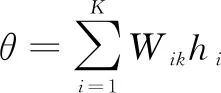
(1)
ri=tanh(Wxhm+Wprj)
(2)
rj=θHi
(3)
语义编码θ主要是通过注意力概率权重与历史输入节点的隐藏层的状态乘积的累加得到,表示人称代词经过模型后的语义表示;K表示输入序列的元素数目;Wik表示节点K对于节点i的注意力概率权重;Wx和Wp分别是模型训练时hm和rj的权重向量。
3.4 LSTM模型
LSTM模型是通过在RNN的基础上添加细胞控制机制(cell state),并通过输入门、遗忘门、输出门的控制,解决了RNN模型长期依赖问题和序列过长导致的梯度爆炸问题。
针对维吾尔语人称代词特征选择问题,文中采用结合注意力机制的LSTM模型用于提取特征。传统的模型在挖掘文本语义信息时,往往忽略了上下文语义信息,使得信息缺失严重。LSTM模型具有短暂的记忆存储功能,在挖掘人称代词语义信息时可以充分利用记忆单元中存储的上一时刻的词汇信息,挖掘出当前时刻人称代词的语义特征;因此LSTM模型能够更好地从上下文中挖掘出人称代词的语义信息。
设输入的词序序列为X={X1,X2,…,Xi},在t时刻,LSTM的输入有三个:(1)当前时刻LSTM的输入值xt;(2)上一时刻LSTM的输出值hkt-1;(3)上一时刻的单元状态Ckt-1。LSTM的输出也有两个:当前时刻LSTM的输出值hkt;当前时刻的单元状态Ckt。则在t时刻LSTM单元可以表述为:
fkt=δ(Wf·[hkt-1,xt]+bf)
(4)
ikt=δ(Wi·[hkt-1,xt]+bi)
(5)
Okt=δ(Wo·[hkt-1,xt]+bo)
(6)
hkt=Okt·tanhCkt
(7)
Ckt=fktCkt-1+iktδ(WC[hkt-1,xt]+bC)
(8)
其中,f,i,O,C分别表示模型中的遗忘门、输入门、输出门和记忆单元;W为权重;b为LSTM模型中的偏置项;δ为激活函数sigmoid。
3.5 深度置信网络
为了确保在训练过程中,特征向量映射到不同空间特征时,都尽可能多地保留特征信息,减小对学习目标过拟合的风险,文中在模型后半部分采用深度置信网络。

训练过程可分为:
预训练:单独地无监督地训练每一层RBM网络,确保网络获得高阶抽象特征。
微调:利用反向传播网络微调网络的权重。
3.6 softmax分类器
利用多层感知器将Attention-Based LSTM-DBN模型学习到的维吾尔语人称代词语义特征与人称代词特征规则进行融合,然后将融合后的特征送到softmax分类器进行分类,并明确照应语和先行语的指代关系,完成维吾尔语人称代词指代消解研究。
3.7 生成训练实例和测试实例
将人称代词与其之前出现的名词短语按照一定的规则进行两两配对。生成训练实例时,因为指代链的信息是已经知道的,所以可以先对已识别出的人称代词进行判断,确定其是否在某个指代链中。若在,则将其视为照应语,并查找该照应语对应的先行语;如果不存在,则将该人称代词视为非待消解项,而且不用寻找该人称代词对应的先行语。经过统计实验语料,在文中实验中,将距离某个照应语Xn在五句之内的所有名词短语视为匹配项,并将匹配项与该照应语一一进行匹配。若是存在某个名词短语NPi(0 在生成测试实例时,因为指代链的信息都是未知的,所以将识别出的所有人称代词都视为照应语,与其距离为五句之内的名词短语依次进行匹配,配对形式为<照应语,候选先行语>,然后通过模型判断它们之间是否存在指代关系。 不同的特征对模型的消解性能具有重要的影响。因此,提取的特征要能够使模型快速、有效、准确地对词汇间的指代关系进行判断。经过查看阅读国内外大量的关于汉语和英语指代消解的研究文献,结合维语特点通过实验筛选出以下十一个特征。 (1)如果照应语是代词(Anaphor Pronoun.):此特征表示为Vap={0,1},如果照应语是代词,则Vap=1;如果不是,则Vap=0。 (2)如果候选先行语是代词(Candidate Pronoun.):此特征表示为Vcp={0,1},如果候选先行语是代词,则Vcp=1;否则Vcp=0。 (3)是否嵌套(Nest Pron.):此特征表示为Vnest={0,1},如果照应语与候选先行语都是互相嵌套,特征值Vnest=1;否则Vnest=0。 (4)性别一致性(Gender Agreement.):该特征表示为Vga={0,0.5,1},如果照应语和候选先行语的性别一致,特征值Vga=1;如果性别不一致,则特征值Vga=0;如果照应语和候选先行语有一个未知,特征值Vga=0.5。 (5)语义类别的一致性(Semantic Agreement.):该特征表示为Vsa={0,0.5,1},如果候选先行语与照应语的语义类别一致,该特征值Vsa=1;如果不一致,则Vsa=0;如果照应语和候选先行语中有一个未知,该特征值Vsa=0.5。 (6)单复数的一致性(Number Agreement.):该特征表示为Vna={0,0.5,1},如果照应语和候选先行语的单复数一致,该特征值Vna=1;如果不一致,Vna=0;如果照应语和候选先行语中有一个未知,则该特征值Vna=0.5。 (7)词性的一致性(POS Agreement.):该特征表示为Vpos={0,1},如果候选先行语与照应语词性一致,该特征值Vpos=1;否则Vpos=0。 (8)命名实体特征(Name Entity.):该特征表示为Vname={0.1,0.3,0.6,1},若候选先行语的实体类型是人名,该特征值取1;若候选先行语的实体类型是机构名,该特征值取0.3;若是地名,该特征值取0.6;若是其他,该特征值取0.1。 (9)语义角色特征(Semantic Role.):该特征表示为Vrole={0,1},若候选先行语的语义角色是施事者,则该特征值Vrole=1;否则Vrole=0。 (10)“格”语法一致性(Case Gramma.):该特征表示为Vcg={0,0.5,1},如果候选先行语和照应语格语法一致,则该特征值Vcg=1;若不一致,则Vcg=0;若照应语和候选先行语中有一个格语法未知,则该特征值Vcg=0.5。 (11)距离特征(Distance.):该特征表示照应语和候选先行语语句的空间距离。距离越大,存在的指代关系的可能性越小。特征表示为Vdistance=g(d),对空间距离进行逆向取值,并归一化在0和1之间。 设空间距离为d,若d≥10,则Vdistance=1;若d<10,则Vdistance=0.1×(10-d)。 根据上述的十一个特征,提取的特征向量值如表1所示。 表1 训练和测试实例格式 实验语料来自天山网等维吾尔语网页网站。首先用网络爬虫在网上下载网页,然后经过去重和降噪后筛选出包含小说等内容作为实验语料。在维吾尔语语言学专家的帮助指导下,标注完成的语料共300篇。实验语料中第一、二和三人称代词占比分别为:35.36%、11.42%、53.23%。 利用自然语言处理中常用的MUC标准对实验结果进行测评。准确率P:模型的准确程度;召回率R:模型的完备性;F1值:指代消解性能,表达式为: (10) (11) (12) 为了确保实验结果的有效性,避免实验的不确定性,在进行实验时,将实验样本全部随机打乱,确保数据的随机性。实验采用五倍交叉验证,取其平均值作为实验结果。参数设置如下:学习率0.01;批处理样本数15;词向量维度150;迭代次数100;LSTM隐藏层节点数目110;RBM层数2。 文中采用Word Embedding将词汇向量化表示作为本文模型输入的数据。Word Embedding区别于传统的文本数据表示方法,提供了更好的语义特征信息,可以避免传统词向量的维度过高的问题,并且解决了向量稀疏问题,从而降低了模型的训练难度。 WordEmbedding的不同维度,对指代消解的性能也有一定的影响,维度越高含有的语义信息也越多。为了探索不同维度的词向量对实验结果的影响,文中分别将10维、50维、100维、150维、200维的词向量作为模型的输入数据。实验结果如表2所示。 由表2可知,Word Embedding的维度选择对模型的准确率有很大的影响。随着Word Embedding维度的增加,反映整体性能的F1值也逐步提高,并在Word Embedding维度达到150维时,综合值F1、准确率P和召回率R均达到了最高值,使实验获得了最优的效果,F1值也达到了78.83%,准确率达到了81.14%。当将Word Embedding的维度继续增加时,综合值F1却没有继续增加,反而降低了;这是因为高维度向量中虽然包含了丰富的语义信息,但是也引入了噪音和无用的干扰信息,会产生过拟合现象,造成模型对数据的泛化能力降低,影响了模型指代消解的性能。 表2 不同维度下指代消解性能对比 % 为了验证模型的有效性,将文中模型与传统LSTM、LSTM、DBN等深度学习模型进行对比,结果如表3所示。 表3 模型对比结果 % 从表3可知,LSTM模型在准确率、召回率、综合值等指标上均高于传统的LSTM模型,这是因为LSTM模型充分利用了短时信息记忆功能的记忆单元,能够将上一时刻存储的关键词汇信息用于挖掘下一时刻的词汇语义信息。文中模型比LSTM实验性能更优,是因为当输入文本过长时,LSTM模型不仅容易丢失大量的细节信息,且不能很好地分配权重比,造成信息的缺失,从而影响模型的性能。因此文中模型加入了Attention机制。注意力机制能有效降低数据维度、提高计算速度,将输入的长文本映射成含有语义信息的数据编码,避免造成信息的缺失。单一的DBN模型在其评价标准上比Attention-Based LSTM-DBN模型的相对较低,是因为Attention-Based LSTM-DBN模型中,长短时记忆网络模型能够更好地联系上下文,挖掘出人称代词语义信息,受限玻尔兹曼机网络能够保证特征向量达到最优化,挖掘出更深层次的语义特征,从而提高输出质量。结果表明,文中模型在维吾尔语人称代词指代消解研究中性能够优。 在同等条件下,将文中模型与SVM、SAE、ANN进行对比,结果如表4所示。 表4 与其他模型实验对比结果 % 由表4可知,3种模型中,SVM和ANN在准确率、召回率、综合值均低于文中模型。这是因为浅层机器学习模型SVM和ANN,相较于Attention-Based LSTM-DBN挖掘文本数据中隐藏的深层语义信息的能力相对较差,不能更好地利用数据中隐藏的信息。而文中利用深层神经网络构建的人称代词指代消解模型,能够更好地适应复杂的数据分布情况,挖掘出更深层次的语义信息。因此文中模型相较于浅层机器学习更适用于代词的消解研究。 维吾尔语人称代词指代消解对于维吾尔语自然语言领域的研究和发展具有重要的意义。目前在自然语言领域的研究主要针对的是英语、汉语等大语种,而针对维吾尔语等小语种的指代消解的研究相对较少,此外也没有充分考虑上下文的语义信息,数据转换过程中信息丢失严重,不能够很好地挖掘出更深层次的语义特征。针对这些问题,采用Attention-Based LSTM-DBN模型,对文章的上下文语义特征进行挖掘。并且利用词向量将文本转换成含有丰富语义信息的特征向量作为模型的输入。根据维吾尔语人称代词指代的现象抽取11项规则特征,利用两类融合后的特征,完成维吾尔语人称代词指代消解研究。通过与长短时记忆网络等模型进行对比实验,验证了该模型在篇章级别文本上挖掘深层语义特征的有效性,提高了维语人称代词指代消解的性能。而与其他模型进行的对比实验,验证了Attention-Based LSTM-DBN模型在挖掘深层次的维吾尔语人称代词语义信息方面比浅层机器学习算法更具优势,能更好地应对复杂的数据分布情况。3.8 特征提取




4 实验结果与分析
4.1 语料来源
4.2 实验测评标准

4.3 实验设计
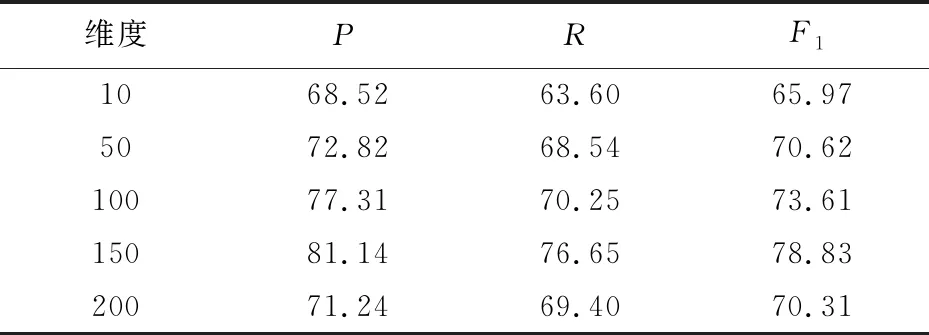
4.4 Word Embedding对实验的影响
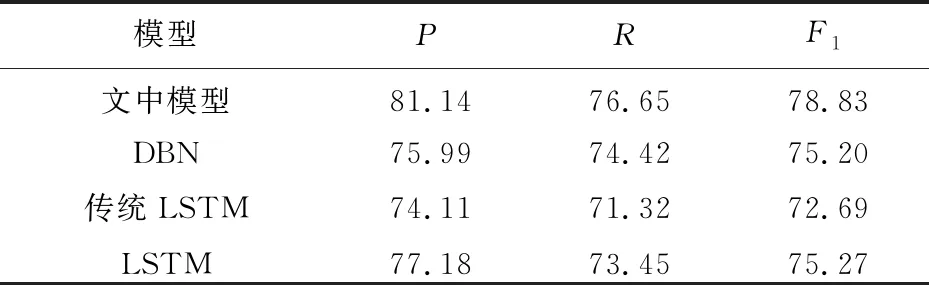
4.5 模型对比实验
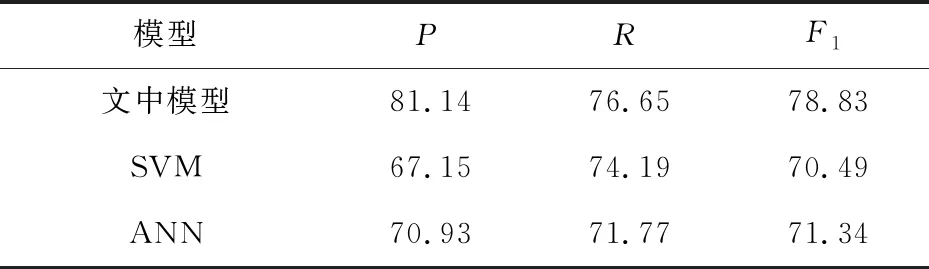
4.6 与其他模型对比实验
5 结束语
