基于人体关键点的分心驾驶行为识别
2019-07-23夏瀚笙
夏瀚笙,沈 峘,胡 委
(南京航空航天大学 能源与动力学院,江苏 南京 210016)
1 概 述
近年来,随着国内汽车保有量的增长,交通事故发生的频率也在逐年增加。其中,驾驶员在驾驶过程中注意力不集中是导致交通事故发生的主要原因之一。驾驶员注意力不集中主要有两个方面,分别是疲劳驾驶和分心驾驶。疲劳驾驶是驾驶员在感到疲倦的情况下仍然驾驶,驾驶员没有足够的精神状态。与疲劳驾驶不同,驾驶员在分心驾驶时,仍然具有良好的精神状态,但是忙于其他事情,例如打电话,发短信,喝水等。如果驾驶员的驾驶状态可以由车载设备检测到,并及时地提醒驾驶员注意安全,则可以很好地避免事故的发生。
多年来,对驾驶员异常行为识别的研究一直是个热门的方向。早期的研究[1-5]主要集中在识别驾驶员是否疲劳驾驶。采用的方式是要求驾驶员佩戴传感器以获得驾驶员的生理信息,例如血压,心率和脑电波等。这些方法成本较高并且准确率低。更重要的是,侵入式的研究方法,会对驾驶员的驾驶行为造成干扰。随着计算机视觉技术的发展,越来越多的研究人员围绕计算机视觉的方法展开研究。非侵入式的,不会影响驾驶员的驾驶体验,同时成本大大降低。可利用安装在车辆仪表盘上的相机来收集驾驶员的图像,然后通过图像的分析,判断驾驶员状态是否出现异常。
文献[6]通过结合AdaBoost与核相关滤波算法进行人脸检测及跟踪,然后采用级联回归方法定位特征点,提取眼睛和嘴巴部分,再利用卷积神经网对眼睛和嘴巴状态进行识别,从而进行疲劳驾驶识别。文献[7]基于肤色模型对驾驶人人脸进行检测,然后利用基于PCA的人脸局部特征来识别驾驶员特征,判断驾驶员是否有疲劳驾驶。
相比于疲劳驾驶,分心驾驶则更为常见,近年来,有关分心驾驶行为的研究逐渐增多。文献[8]使用Faster R-CNN网络[9]来检测驾驶员的双手位置,并判断驾驶员手中是否拿着手机。文献[10]建立以径向基为核函数的驾驶人分心状态判别SVM模型,采用遗传算法(GA)优化SVM模型惩罚参数C和核函数参数g。文献[11]提出了基于反向双目的驾驶状态检测方法。根据Hough算法进行车道线检测和识别,计算车辆偏航率;同时采用多点透视算法对驾驶员头部姿态进行估计;再建立基于高斯隶属度函数模糊判断规则,根据车辆偏航率与驾驶员头部姿态对驾驶员驾驶状态进行识别。
在著名的机器学习竞赛网站Kaggle上,State Farm公司举办了一个关于分心驾驶识别的竞赛。参加比赛的队伍中,toshi-k队伍利用检测器检测出驾驶员的身体轮廓,然后按照检测出来的身体轮廓将图片裁剪,再利用深度卷积网络进行识别。Soteria公司提出的Soteria系统将VGG16网络[12]的全连接层改为全局均值池化(global average pooling,GAP)以减少网络参数,同时防止因训练数据不足而导致过拟合。
图1为State Farm数据集的驾驶员行为示例。可以观察到,当驾驶员手握方向盘,同时正视前方时,他很大可能正专注于驾驶,如图1(a)所示;当驾驶员低着头,并且稍微抬起胳膊,他很有可能是在看手机、发消息,如图1(b)所示;当驾驶员抬起胳膊,靠近耳朵,他很有可能是在打电话,如图1(c)所示;当驾驶员抬起手靠近嘴巴时,他很有可能是在喝水或饮料,如图1(d)所示。
因此,正确地识别驾驶员是否存在分心行为,关键在于卷积神经网络理解驾驶员的姿态行为。为此,文中提出一种使用驾驶员的人体关键点位置信息来帮助卷积神经网络识别驾驶员分心驾驶的方法。首先介绍Alpha Pose系统,并利用该系统获取驾驶员的人体关键点坐标位置。然后根据驾驶员上半身的9个关键点坐标,利用高斯公式生成9张关键点的热力图。最后基于VGG16网络和ResNet50网络[13],探讨8种将热力图和卷积层的输出特征融合的方式。

图1 驾驶员行为示例
2 Alpha Pose系统
2.1 系统简介
Alpha Pose系统是由上海交通大学提出的一个开源的多人姿态估计系统,如图2所示。
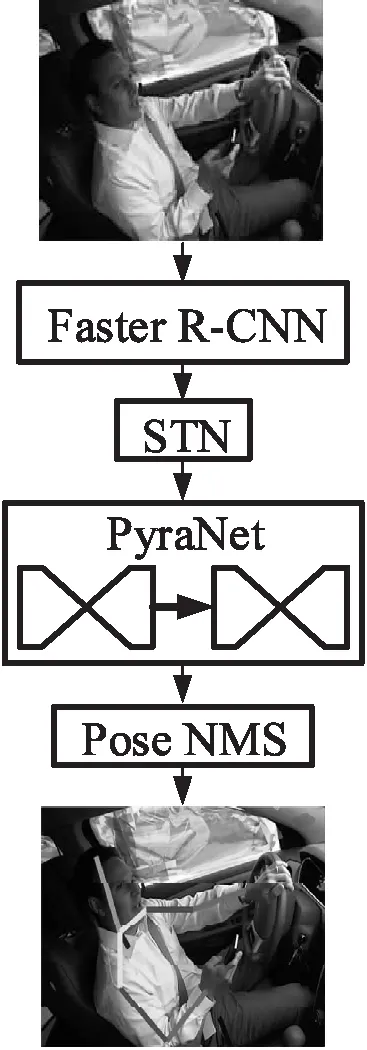
图2 Alpha Pose系统
Alpha Pose系统采用的是自上而下的形式,由四部分组成,即Faster RCNN网络、空间变换网络(spatial transformer network,STN)[14]、PyraNet[15]以及姿态极大值抑制模块。Faster RCNN用于检测人的位置,输出的是人的位置框坐标。空间卷积网络用来调整Faster RCNN得到人的位置框。PyraNet是Stacked Hourglass网络[16]的改进版,用来获取人体关键点的坐标。姿态极大值模块用来消除Faster RCNN检测出来的多余人体框位置,获取最终的人体关键点坐标。
通过Alpha Pose系统,可以精确地得到输入图片中人物的人体关键点的坐标位置。分心驾驶行为主要依据的是驾驶员上半身的姿态,因此,文中只使用Alpha Pose系统获得驾驶员上半身的9个关键点位置,分别是:头顶、颈部、胸膛、左肩、右肩、左肘、右肘、左腕、右腕。
2.2 热力图
为了将关键点的位置信息融入到卷积网络,需要根据9个关键点的坐标位置,由高斯公式生成9张热力图。高斯公式如下所示:
Response=exp(-((x-i)2+(y-j)2)/2σ2)
(1)
其中,x,y是热力图中每个像素点的坐标;i,j是对应的关键点的坐标;σ是关键点响应的范围。热力图中所有像素点的值在[0, 1]之间,距离关键点的位置越近,响应值越大。
根据高斯公式生成的9张热力图,如图3所示。

图3 热力图
3 基于人体关键点的分心驾驶行为识别
3.1 网络结构设计
在深度卷积网络中,随着卷积层数的增加,卷积层学习到的特征也逐渐从低阶发展到高阶。例如,在常见的分类卷积网络中,网络的第一个卷积层学习到的可能是边、角、曲线等低阶特征,而第二个卷积层学习的则是第一个卷积层输出的低阶特征的组合,如半圆、矩形等。因此,将姿态信息(即热力图)和卷积网络的不同层的特征图进行融合,产生的效果也不一样。文中以VGG16网络和ResNet50网络为基础网络,尝试8种结构将热力图融合到不同的卷积输出层中,以获得最好的实验效果。VGG16网络结构和ResNet50网络结构如图4所示,实验中需要将最后一个全连接层的输出数改为10。

输入:224×224(RGB)Conv1.conv3-64 conv3-64Pool1(Max)Conv2.conv3-128 conv3-128Pool2(Max)Conv3.conv3-256 conv3-256 conv3-256Pool3(Max)Conv4.conv3-512 conv3-512 conv3-512Pool4(Max)Conv5.conv3-512 conv3-512 conv3-512Pool5(Max)FC4 096 FC4 096 FC1 000

(a)VGG16网络
(b)ResNet50网络
图4 VGG16网络模型和ResNet50网络模型
图4中,Conv1.表示网络第一阶段,Conv2.表示网络第二阶段,以此类推。Conv3-64表示卷积操作,其中卷积核大小为3×3,输出通道数为64,以此类推。Pool表示池化操作,其中Max是最大值池化,Average是均值池化。FC表示全连接层。
基于VGG16的4种结构分别是:
结构a:9张热力图和3通道的RGB图像串接,通道数变为12,作为Conv1.的输入。
结构b:9张热力图经过1×1的卷积,输出尺寸为112×112、通道数为64的特征图,和相同尺寸的Pool1的输出特征图相加,作为Conv2.的输入。
结构c:9张热力图经过1×1的卷积,输出尺寸为56×56、通道数为128的特征图,和相同尺寸的Pool2的输出特征图相加,作为Conv3.的输入。
结构d:9张热力图经过1×1的卷积,输出尺寸为28×28、通道数为256的特征图,和相同尺寸的Pool3的输出特征图相加,作为Conv4.的输入。
基于ResNet50的4种结构分别是:
结构e:9张热力图和3通道的RGB图像串接,通道数变为12,作为Conv1.的输入。
结构f:9张热力图经过1×1的卷积,输出尺寸为112×112、通道数为64的特征图,和相同尺寸的Conv1.的输出特征图相加,作为Pool1的输入。
结构g:9张热力图经过1×1的卷积,输出尺寸为56×56、通道数为64的特征图,和相同尺寸的Pool1的输出特征图相加,作为Conv2.的输入。
结构h:9张热力图经过1×1的卷积,输出尺寸为56×56、通道数为256的特征图,和相同尺寸的Conv2.的输出特征图相加,作为Conv3.的输入。
3.2 损失函数
损失函数采用的是Softmax损失,如式2所示:
(2)
其中,N是批量的大小,n是样本类别数;xi表示第i个样本的特征向量,yi为其对应的标签;Wj是类别j类别对应的权值,bj是类别j对应的偏置,Wyi是类别yi对应的权值,byi是类别yi对应的偏置。
4 实 验
4.1 State Farm数据集
State Farm是State Farm公司在Kaggle上发布的一个竞赛数据集。它包含81个驾驶员,共102 150张图。所有的图片尺寸都是640×480像素。驾驶员的行为分为10个类别,分别是:安全驾驶、左手发信息、右手发信息、左手打电话、右手打电话、调收音机、喝水或饮料、向后拿东西、化妆或者抓耳挠腮、和乘客说话。
该数据集的图片都是从视频上截取的视频帧,同一个驾驶员所对应的图片高度相关。因此为了验证实验的准确性,训练和测试数据需要按照驾驶员来分,同一个驾驶员对应的所有照片只能是在训练集和测试集中选其一。
文中选择26个驾驶员对应的照片用做测试集,约占总的图片数的22%,剩下的55个驾驶员对应的照片作为训练集,约占总的图片数的78%。
4.2 数据预处理及训练参数
文中实验均在Caffe框架上进行。训练过程中,所有图片首先被缩放到224×224尺寸。然后做数据增广,包括随机旋转(最大旋转角30度),随机水平翻转。
训练参数上,每一批量的训练样本数为128,动量为0.9,权重衰减为0.000 5,使用在ImageNet上训练好的VGG16模型进行微调,总共训练15个epoch,初始学习率为0.01,分别在5个epoch和10个epoch的时候下降一次,下降因子为0.1。
4.3 实验结果
8种网络结构的实验结果如表1所示。

表1 4种网络结构的实验结果对比
将Toshi-k的方法和Soteria系统的方法在同样的数据集上进行训练和测试,结果如表2所示。
在VGG16网络结构中,结构a和结构b相比于原始的VGG16网络不但没有提升,反而有所下降。结构c的提升最明显,结构d略有提升。原因在于人体关键点的信息属于高阶特征,在VGG16网络结构中,如果直接将热力图信息和原图或者Pool1层输出的特征图进行融合,反而会对后面网络的特征学习造成干扰。而到Pool3时,由于输出的通道数有256个,远大于热力图的9个通道数,同时特征图的变小,导致姿态信息对网络的帮助效果很小。
同样,在ResNet50网络结构中,结构e和结构f相比于原始的ResNet50,性能下降。结构g性能提升明显,结构h性能略有提升。因为直接将热力图信息和原图或者Conv1.阶段输出的特征图进行融合,会对后面网络的特征学习造成干扰。而到Conv2.阶段,虽然输出的特征图尺寸没变,但是通道数有256个,减弱了姿态信息对网络的效果提升。
可以看出,文中提出的结构g性能要优于Soteria系统和Toshi-k方法。
5 结束语
由于驾驶员是否出现分心驾驶行为和驾驶员的姿态密切相关,因此文中提出通过在VGG16网络中添加驾驶员的姿态信息,来帮助识别驾驶员的分心行为。为了验证方法的有效性,在State Farm数据集上进行了实验验证,尽管实验结果比较理想,但是文中的工作仍有一些不足之处。首先,训练的样本量较少,没有充分利用深度网络的学习能力,特别是有全连接层的网络,在训练的时候需要谨慎调参,防止过拟合;其次,数据集拍摄的角度是在驾驶员的右侧,左边有时遮挡很严重,影响了识别的效果。因此,接下来的工作可以围绕增加数据量以及数据的复杂程度,尝试ResNet101等更为深层的网络来提高识别的效果。
