新型锁位式混合查询树射频识别防碰撞算法*
2019-07-18南敬昌高明明
南敬昌,樊 爽,李 蕾,高明明
辽宁工程技术大学 电子与信息工程学院,辽宁 葫芦岛 125105
1 引言
物联网是一种将用户应用终端拓展到人与物、物与物交互通信的新型网络技术和产业模式,是互联网、电信网和广播电视网的延伸与拓展[1]。射频识别(radio frequency identification,RFID)技术作为实现互联网感知层的数据采集技术[2],已被广泛应用于物流管理、制造工业、室内定位等领域。其中无源超高频(ultra high frequency,UHF)因其通信距离长、识别速度快、存储容量大、成本低而受到广泛关注[3]。但要实现多标签同时对阅读器做出响应,会不可避免地产生多标签碰撞问题,此时需要一个高效的防碰撞机制用于实现大量标签的追踪与识别[4]。
解决标签防碰撞问题本质上即为解决无线通信系统中的多路存取问题,基于时分多址(time division multiple access,TDMA)的RFID防碰撞算法因其原理简单,且无需进行硬件部分的改动而被广泛应用[5]。常用的标签防碰撞算法可以分为概率性算法和确定性算法[6]。基于ALOHA的算法[7-8]为传统的概率性算法,该算法识别吞吐率较低,且在标签数量未知时,不能保证所有标签被识别,易造成标签饥饿现象[9]。确定性算法[10]为基于树的算法,经典的树算法包含二进制搜索树(binary search,BS)算法[11]和查询树(query tree,QT)算法[11],后有人在QT算法的基础上提出了混合查询树(hybrid query tree,HQT)算法[12]。文献[13]提出一种锁位式的树形结构RFID防碰撞算法,该算法可发送锁位指令对发生碰撞的比特位进行锁定用来减少查询过程中的数据传输量。文献[14]在该文献[13]的基础上,结合经典的自适应多叉树(adaptive multi-tree search,AMS)RFID防碰撞算法,提出一种自适应后退锁位式(regressive lockadaptive multi-tree search,RLAMS)RFID防碰撞算法,通过搜索树的叉树后,对标签中的碰撞位进行提取,从而形成新的序列,可减少大量碰撞时隙的产生,但对于空闲时隙的减少并未作出改善。文献[15]提出改进的混合查询树(improved hybrid query tree,IHQT)RFID防碰撞算法,在阅读器查询碰撞标签前加入分支预测,通过预测判断出空闲节点并剪除,可达到彻底消除空闲时隙的目的,但该算法未能有效减少空闲时隙,数据传输量仍相对较大。
基于以上文献存在的问题,本文提出一种新型锁位式混合查询树(novel lock-bit hybrid query tree,NLHQT)算法。该算法加入锁位指令,只将碰撞位进行锁定并提取,从而形成新的标签序列,并对新产生的序列加入预测指令,通过预测将空闲节点进行消除。通过分析论证和仿真证明,本文的NLHQT算法不仅能够彻底消除空闲时隙,还能够大量减少碰撞时隙,尤其当标签中出现连续碰撞时,本文算法能够快速有效地对标签进行识别,从而有效提高搜索效率和阅读器与标签之间的数据传输量。
2 NLHQT算法
2.1 NLHQT算法预测描述
2.1.1 NLHQT算法碰撞指令描述
阅读器初始化时堆栈为空,此时所有标签都会响应,阅读器如果只读取到一个标签,则成功识别该标签,查询结束,若产生碰撞,则对标签的碰撞位进行锁定。根据曼切斯特编码原理,通过解码使阅读器检测的标签序列中碰撞标签的碰撞位置为X,相同信息位即非碰撞位置为原信息数。通过提取X所在的碰撞位信息,对碰撞位进行锁定,从而将锁定位形成新的标签序列。锁位指令的加入可以使标签在后续的识别过程中不再传输非碰撞位信息,进而在很大程度上减小冗余信息的传输。例如:产生碰撞的两个标签为01011000、11010100,则通过曼切斯特编码原理使阅读器检测到的标签序列为XX01XX00,碰撞位信息为D7、D6、D3、D2,对碰撞的位置进行提取,在后续的识别过程中,只需对这四位碰撞信息进行传输,减少了50%的信息传输量。
2.1.2 NLHQT算法预测指令描述
阅读器在查询前缀m1,m2,…,mp后添加n位二进制1(n=1时对应二叉树算法,n=2时对应四叉树算法,n=2L时对应2L叉树算法),此时阅读器产生新的二进制序列m1,m2,…,mp11…(n个1),经锁位后的新标签接到阅读器的预测指令后,将前缀K1,K2,…,Kp与m1,m2,…,mp进行比较,若两者匹配,标签将ID前缀K1,K2,…,Kp后的n位二进制数换算成对应的十进制数a,同时向阅读器回应一个长度为2n的预测响应序列,该序列中的a位为1(从左到右依次为0~2n-1位),其余的2n-1位均为0。阅读器在接收所有标签响应后,将序列中记为0的对应位置的子节点判断为空闲节点,从而产生避开空闲节点的查询前缀。
虽然通过增大叉树可以缩短搜索层,从而减少碰撞时隙,但由于本文已通过锁位指令使算法减少碰撞时隙,且实际操作过程中,只有二叉树、四叉树和八叉树较易实现。其中若采用八叉树搜索,效率虽略有提升,但会急剧增加前缀优化的复杂度,进而影响算法的普适性。因此文中算法采用n=1和n=2分别对应二叉树和四叉树算法进行改进,在这两种情况进行论述与验证。
以下分别对n=1和n=2时的情况,对预测指令的设计思路进行分析举例:
发生碰撞的标签序列A、B、C、D分别为0010、0100、1001、0110。
n=1时,首次查询前缀无m1,只包含一位二进制数1,即查询前缀为1。标签A、B、C、D将第0位的二进制数换算为对应的十进制数。即A标签对应位置十进制数为0,标签B为0,标签C为1,标签D为0,其余位为0。即标签A、标签B和D回应预测响应10,标签C回应01,又二叉树查询共有两个子节点0和1,故标签A、B、D中第0位所对应的子节点为0,C标签中第0位所对应的子节点为1。进而产生新的查询指令,完成对标签首位的预测。则C标签成功识别,A、B、D标签以此类推继续查询。
n=2时,与n=1时情况类似,首次查询前缀无m1、m2,只包含两位二进制数11,即查询前缀为11。标签A、B、C、D将第0位和第1位的二进制数换算为对应的十进制数。即A标签对应位置十进制数为0,标签B与标签D为1,标签C为2。同时各标签回应一个长度为4的预测响应序列,该序列中标签换算出的十进制数对应位置为1,其余位为0。即标签A回应预测响应1000,标签B与标签D回应0100,标签C回应0010,又四叉树查询共有四个子节点00、01、10和11,故标签A中第0位与第1位对应的子节点为00,标签B与标签D中第0位与第1位对应的子节点为01,标签C中第0位与第1位对应的子节点为10。进而产生新的查询指令,完成对标签前两位的预测。则A标签与C标签成功识别,标签B和标签D以此类推继续查询。
2.2 NLHQT算法分析
假设在阅读器的查询范围内有4个标签,标签编码为8位,标签的ID分别为:标签A(01000010)、标签 B(01101110)、标签 C(01101101)、标签 D(11001110)。n=1时的NLHQT算法对标签的识别过程如表1所示,此时由于锁位指令减少了不必要的空闲时隙,故阅读器进行预测时,每次发送1即可判断出识别标签的空闲子节点。n=1时的NLHQT算法和n=1时的IHQT算法的比较如图1所示。由图1可知,采用本文算法对标签进行识别的过程中不仅没有空闲时隙的产生,还能够有效减少碰撞时隙的产生,提高识别效率。
n=2时的NLHQT算法如表2所示,与n=1相似,锁位指令的存在,使得预测阶段,阅读器每次只需发送“11”即可准确判断出空闲子节点的存在。n=2时的NLHQT算法和n=2时的IHQT算法的比较如图2所示。通过对比可以看出,当标签产生连续碰撞时,NLHQT算法能够在不产生空闲时隙的同时,大量减少碰撞时隙的产生,较IHQT的识别效率明显有所提升。

Table 1 NLHQT algorithm recognition process withn=1表1 n=1时的NLHQT算法识别过程
2.3 NLHQT算法流程
2.3.1 NLHQT算法指令
(1)Request(UID,1)锁位指令:阅读器通过判断标签发生碰撞的准确位置,将发生碰撞的比特位置为“1”,未发生碰撞的比特位置为“0”,标签在接收到该指令后,将自身的标签与阅读器的信息进行比较,将阅读器对应比特位为“1”的位置进行提取,形成新的标签序列。
(2)Request(s,m,n),其中s为更新的查询前缀,m为待识别标签与阅读器查询前缀进行比较的最高位(即检测到碰撞的最高位),n为待识别标签与阅读器查询前缀进行比较的次高位(即检测到碰撞的次高位,n=1时没有此项),由高位到低位依次为从左至右的0~p(标签编码为p位)。
2.3.2 NLHQT算法步骤
NLHQT算法识别步骤如下:
阅读器初始化堆栈为空,阅读器发送Request(11111111)搜索指令,阅读器识别范围内的所有标签响应。
阅读器根据标签的响应,对时隙状态做出判断。若只有一个标签做出响应,则阅读器成功识别该标签,直接跳转到“结束”,若有多个标签同时做出响应,则出现碰撞时隙,跳转到“发送查询指令”。
根据曼切斯特编码原理,对发生碰撞的标签的比特位进行判断,将碰撞位置为“1”,非碰撞位置为“0”,阅读器发送锁位指令Request(UID,1),将置“1”的碰撞比特位进行锁定,进而形成新的标签序列,并将该序列发送给阅读器。
阅读器执行预测指令Prognosis(1)(n=1时)或Prognosis(11)(n=2时)。

Table 2 NLHQT algorithm recognition process withn=2表2 n=2时的NLHQT算法识别过程
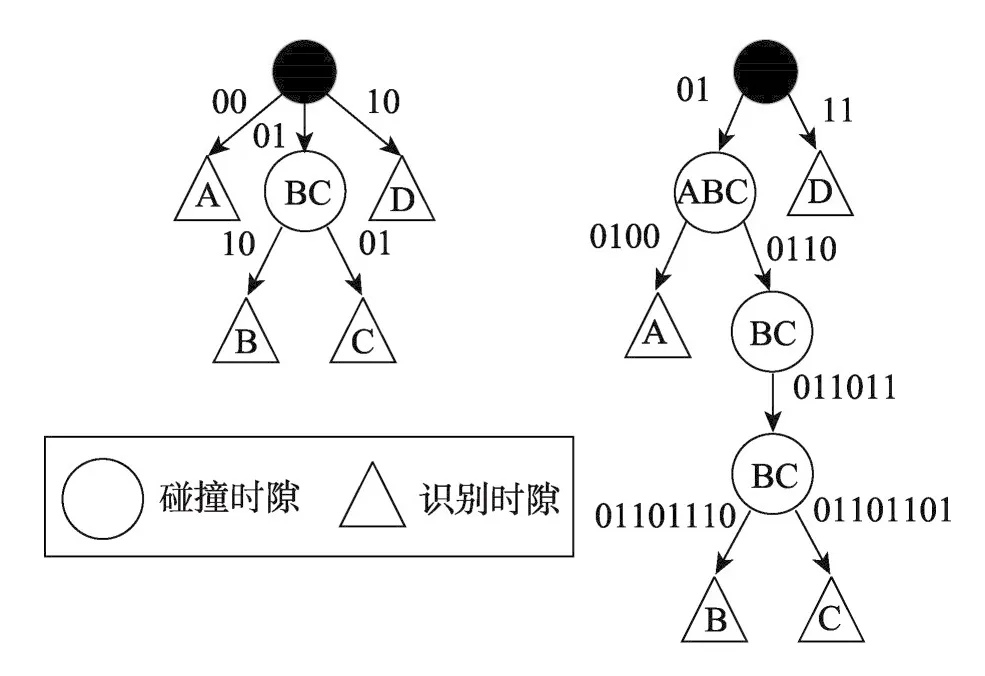
Fig.2 Algorithm flow withn=2NLHQT andn=2IHQT图2 n=2的NLHQT和n=2的IHQT算法流程
标签通过预测指令,将标签的第0位(n=1时)或标签的第0位和第1位(n=2时)转换为对应的十进制数a,并向阅读器返回一个长度为2位(n=1时)或4位(n=2时)的响应,该响应总的a位为“1”,其余位为“0”。
阅读器在接收到所有标签响应后,将序列中记为a的对应位置的子节点判断为有用节点,其余判断为空闲子节点,并将有用子节点形成查询指令所需要的查询前缀s。通过查询前缀对标签进行识别。
判断标签是否碰撞,若碰撞,转到“发送查询指令”;若不碰撞,则成功识别。
判断堆栈是否为空,若为空,则全部识别成功;不为空,则堆栈弹出查询前缀,返回“发送查询指令”。
算法流程如图3所示。
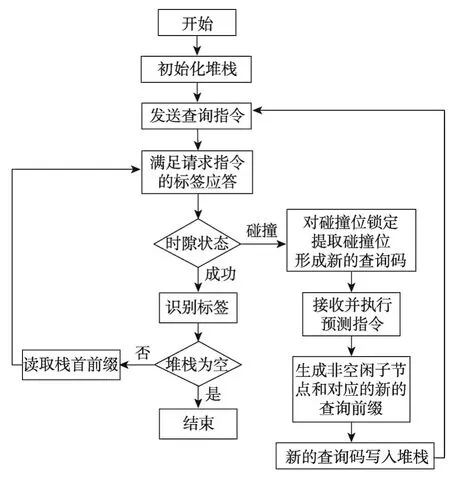
Fig.3 Algorithm flowchart图3 算法流程图
2.4 NLHQT算法性能分析
2.4.1 总时隙数
本文利用曼切斯特编码原理锁定碰撞位信息,在传输过程中可以减少数据传输信息量。设标签UID信息为X位长度的二进制数,其中有x位发生碰撞,阅读器读取范围内的标签数为M。故在最理想时,M个标签在各位上产生碰撞,(为取小于等于该数的最大整数)。在最不理想的情况下,N个标签在不同位置上均产生碰撞,即x=M。
n=1时,总时隙数T为:

n=2时,总时隙数T为:

2.4.2 吞吐率
吞吐率指单位时间内通过某节点或者某通信信道成功交付数据的平均速率,可得:

2.4.3 通信复杂度
NLHQT算法的复杂度由标签通信复杂度和阅读器通信复杂度构成,它代表标签被成功识别所需要的总的传输位数,表示为:
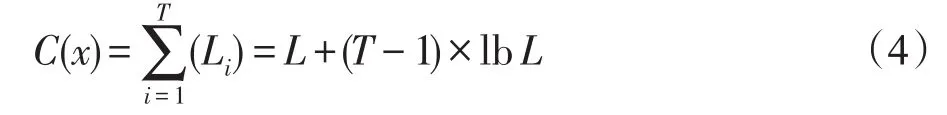
其中,C(x)表示NLHQT算法成功识别x个标签时的通信复杂度,L表示首次查询的通信位数,Li表示每次查询的通信位数(不包含首次查询)。锁位指令降低了新算法的标签通信复杂度,有效减少了Li,且NLHQT算法与IHQT算法的阅读器通信复杂度大致相同,故NLHQT算法具有更低的通信复杂度。
2.4.4 阅读器查询次数
经典多叉树算法的阅读器查询次数为成功时隙数、碰撞时隙数与空闲时隙数的总和。虽然本文算法增加的分支预测会增加阅读器的查询次数,但是由于分支预测消除了所有的空闲时隙,消除了阅读器对于空闲时隙的查询,故又一定程度上减小了阅读器的开销。
在NLHQT算法中,阅读器对成功时隙需查询一次,对碰撞时隙需查询两次,第一次查询获得碰撞时隙信息,第二次查询得到碰撞时隙中空闲子节点的位置。设碰撞时隙数、空闲时隙数和成功时隙数分别为T1、T2和T3,则NLHQT算法的阅读器查询次数t为:

当n=1时:

当n=2时:

2.5 实验仿真分析
本文利用Matlab中搭建的RFID防碰撞算法仿真平台进行仿真,选择理想无损信道,统计经典的查询树QT算法,以及混合查询树HQT算法,在自适应多叉树AMS算法基础上改进的自适应后退锁位式RLAMS算法、IHQT算法和NLHQT算法的总时隙数、碰撞时隙数、吞吐率、通信复杂度和阅读器开销。且考虑到实际操作和算法的普适性,查询树算法叉树过多,会增加算法复杂度和实现程度,增加算法操作过程的工作量。且由于文中算法的改进已使得碰撞时隙在n=1和n=2时得到很大程度的减少,故本文只需考虑与二叉树和四叉树查询对应的情况,即n=1和n=2时的情况即可,在这两种情况下,不仅算法复杂度和实现程度低,且满足查询速度快和降低碰撞时隙的条件。为保证各算法之间的公平比较,假设系统内的标签为均匀分布,排除控制字节和校验冗余的影响,参考ISO18000-6标准,随机生成ID长度为96 bit的标签,信息传输率为40 kb/s,标签仿真数量最大为1 000,仿真结果取20次均值。
图4为QT算法、HQT算法、RLAMS算法、IHQT算法和NLHQT算法分别在n=1时和n=2时的总时隙数的比较。通过统计总时隙数可以分析出,在识别标签数量相同的情况下,n=1时的NLHQT算法总时隙数已经小于QT算法、HQT算法、RLAMS算法和n=1时的IHQT算法,甚至小于n=2时的IHQT算法,而n=2时的NLHQT算法的总时隙数较n=1时的NLHQT算法的总时隙数进一步减小。结合图4的分析,考虑到HQT算法与RLAMS算法均为在四叉树查询算法的结合上的改进,使得此两种算法性能较经典查询树QT算法已明显优化,为公平论证文中算法性能,后续主要针对四叉树条件下,即n=2时的IHQT算法和NLHQT算法进行论述。图5为QT算法、HQT算法、RLAMS算法、IHQT算法和NLHQT算法分别在n=2时的碰撞时隙数的比较。通过对碰撞位时隙的提取,从图5可以看出,由于锁位指令的存在,使得本文算法在n=2时的碰撞时隙较QT算法、RLAMS算法和n=2时IHQT算法的碰撞时隙明显减小。随着标签数量的增加,虽然NLHQT算法总时隙数逐步增多,但是由于预测指令避免了空闲时隙的产生,且同时锁位指令减小了碰撞时隙的产生,NLHQT算法较其他四种算法性能具有明显优势,能够有效减少总时隙数和碰撞时隙。
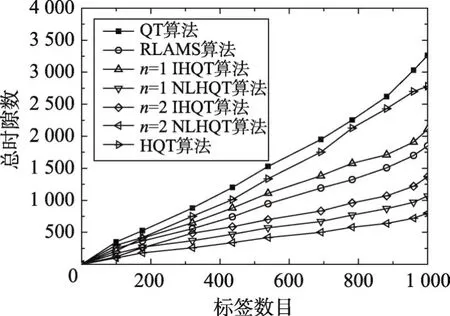
Fig.4 Comparison of total number of slots图4 总时隙数的比较

Fig.5 Comparison of the number of collision slots图5 碰撞时隙数的比较
表3为QT算法、HQT算法、RLAMS算法、IHQT算法和NLHQT算法分别在n=1时和n=2时的算法性能比较。从表中可以看出,本文算法通过增加预测指令进行额外查询的方式,不仅能够有效消除空闲时隙,对于碰撞时隙的有效减小还能很大程度提高阅读器的查询效率和查询速率。通过对识别时间的统计可以看出,本文算法能够很大程度降低算法识别时间,有效提升防碰撞性能,因此本文算法较其他几种算法具有更好的整体性能。

Table 3 Algorithm performance comparison表3 算法性能比较
图6为QT算法、HQT算法、RLAMS算法、IHQT算法和NLHQT算法在n=2时的吞吐率的比较。通过在统计总时隙数的基础上,对碰撞位x和总时隙数T按式(4)进行运算获取吞吐率,从图中可以看出本文算法的吞吐率在0.85左右,明显高于其他三种算法的吞吐率,进一步验证了本文算法能够在有效减少总时隙T的同时通过锁位指令减少碰撞位x。因此NLHQT算法具有更高的搜索效率和速度。
图7、图8和图9为QT算法、HQT算法、RLAMS算法、IHQT算法和NLHQT算法综合n=1和n=2情况下统计的标签通信复杂度、阅读器通信复杂度和总通信复杂度的比较。从图7中可以看出,NLHQT的锁位指令使得标签被查询的通信位数大大降低,通过统计平均分析发现本文算法使得标签通信复杂度得到大量简化。从图8中可以看出,NLHQT和IHQT的阅读器通信复杂度大致相同,由于对于空闲时隙的分支预测使得阅读器通信复杂度较其他算法明显降低。故从图9可以看出,本文算法的总通信复杂度明显低于其他三种算法,这说明对碰撞位的锁位和对于空闲时隙的分支预测能够同时有效地降低阅读器和标签的通信复杂度。虽然随着标签数目的增加,NLHQT算法通信复杂度有所增长,但对比另外四种算法,增长速度明显较为缓慢。

Fig.6 Comparison of throughput rates图6 吞吐率的比较

Fig.7 Comparison of tag communication complexity图7 标签通信复杂度的比较
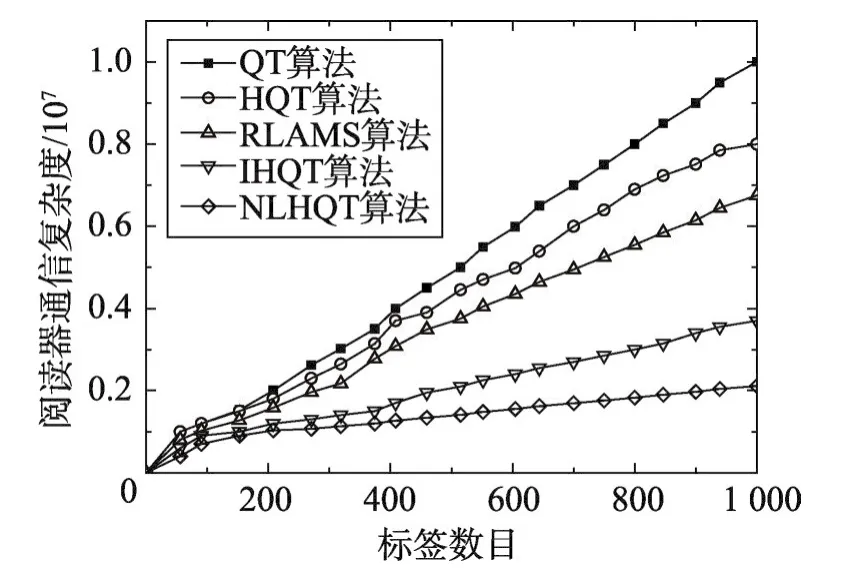
Fig.8 Comparison of reader communication complexity图8 阅读器通信复杂度的比较

Fig.9 Comparison of total reader communication complexity图9 总阅读器通信复杂度的比较
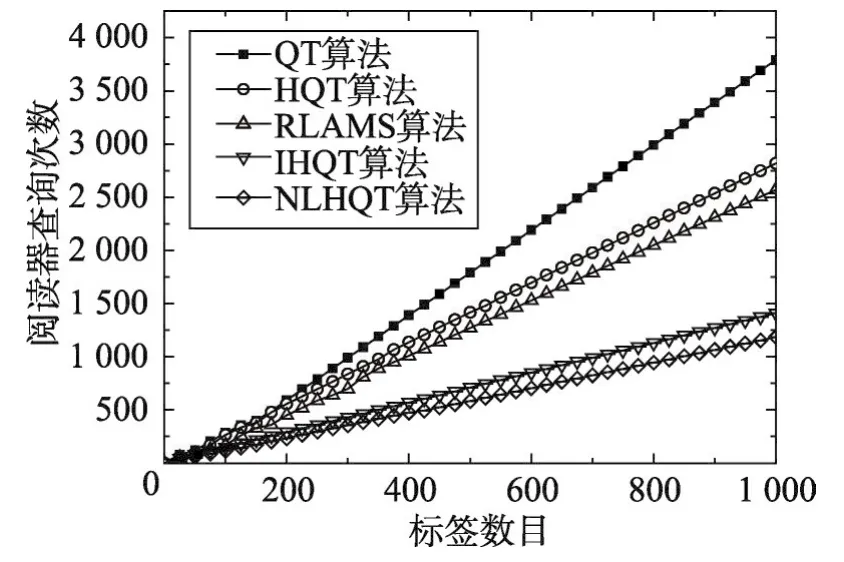
Fig.10 Reader overhead comparison图10 阅读器开销的比较
图10展示了QT算法、HQT算法、RLAMS算法、IHQT算法和NLHQT算法综合n=1与n=2情况下的阅读器查询次数随阅读器标签数量增加的变化曲线。由图10可以看出,NLHQT算法均比其他算法的阅读器查询次数少,这是因为虽然IHQT算法增加了额外的查询和碰撞时隙较多,在面对二叉树和四叉树条件时的阅读器查询次数较其他算法更多,但NLHQT算法在IHQT算法的基础上,不仅消除了空闲时隙,还依靠锁位指令大大降低了碰撞时隙,使得本文算法能够较其他算法降低阅读器的查询次数。
3 结束语
本文提出了一种新型的锁位式混合查询树算法,并阐述了算法的锁位式策略和消除空闲时隙的基本思想,对于算法的识别过程进行了详细的说明,且在保证算法性能的同时降低算法复杂程度,本文设置参数在n=1和n=2时的NLHQT算法进行性能分析,即在二叉树和四叉树的基础上进行优化,从而进一步使得算法更易于实现。通过利用Matlab仿真软件分析对比了几种算法在总时隙数、碰撞时隙数、吞吐率和通信复杂度等性能上的特点,可以看出本文算法能够有效减少碰撞时隙的产生,消除空闲时隙,降低通信复杂度,提高吞吐率,从而达到提高识别效率的目的,整体性能均有所提高。且本文算法同时适用于二叉树和四叉树情况下的查询算法,可用范围较为广泛,算法复杂度较低,易于实现。
