基于Python的新闻聚合系统网络爬虫研究
2019-07-10
(山西管理职业学院,山西临汾市 041051)
网络中的冗余信息过多,用户阅读不同的信息需要在不同站点之间频繁切换,这无形中增加了获取新闻的难度,也增加了时间成本。
因此需要构建一个新闻聚合系统从多个来源收集新闻,并以特定的格式进行汇总。新闻聚合系统中的新闻数据需要通过网络爬虫来获取,这其中包括web爬虫、CMS、API、web爬虫调度器和socket服务器的实现等。
1 工具
1.1 网络爬虫
网络爬虫是一个特定的机器人,是一种按照一定的规则,自动地抓取网络信息的程序或脚本。目前主要有以下几个比较实用的工具可以用来抓取网站并提取其内容:
(1)Scrapy
Scrapy是一个用Python编程语言编写的web爬虫框架,Scrapy支持网页抓取和页面提取。
(2)BeautifulSoup
BeautifulSoup是用Python编程语言编写的HTML解析器,可以用来从网页中提取内容,BeautifulSoup不能单独用作网络爬虫。
(3)Link Grabber
Link Grabber是一个用Python编程语言编写的库,可以用来从网页中提取统一资源定位器(URL),它有附加的功能,可以在锚标记内提取文本。
1.2 网络爬虫的比较
衡量网络爬虫的性能应从以下指标来考量:爬行能力(HTML解析器是否可以在安装时自行抓取Web页面)和处理能力(HTML解析器是否可以解析格式复杂的HTML页面)。
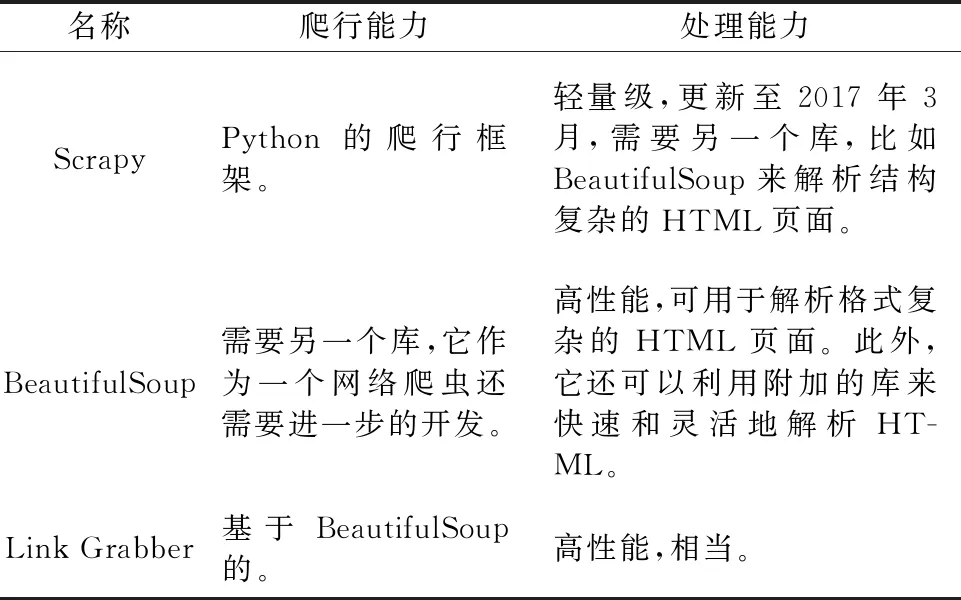
表1 爬虫的比较
1.3 Web应用程序框架的比较
Web应用程序框架应从以下两个方面进行比较:速度(在接收客户端请求时,框架返回响应的时间等)和性能(内置的功能,如库、框架模板等)。

表2Web应用程序框架的比较
1.4 建议解决方案
基于Web应用程序框架以及网络爬虫的比较,我们将使用Laravel框架作为其web应用框架和BeautifulSoup作为其网络爬虫框架。选择使用Laravel框架,是因为与CodeIgniter相比,它使用了更现代的体系结构和PHP7特性,它也有一个与新闻聚合系统的发展相关的功能,即ORM。使用Laravel创建API也非常简单,因为它具有更高级的路由和单元测试功能。
对网络爬虫来说,选择使用BeautifulSoup作为网络爬虫,因为与Link Grabber相比,BeautifulSoup不是一个复杂的框架。此外,截止到2017年5月,Link Grabber的开发已经停滞了几个月。而BeautifulSoup性能较高,可用于解析格式复杂的HTML页面。此外,它还可以利用附加的库来快速和灵活地解析HTML。如图1展示了新闻聚合系统的概况,因篇幅所限,这篇论文只涵盖了方框内2的部分。
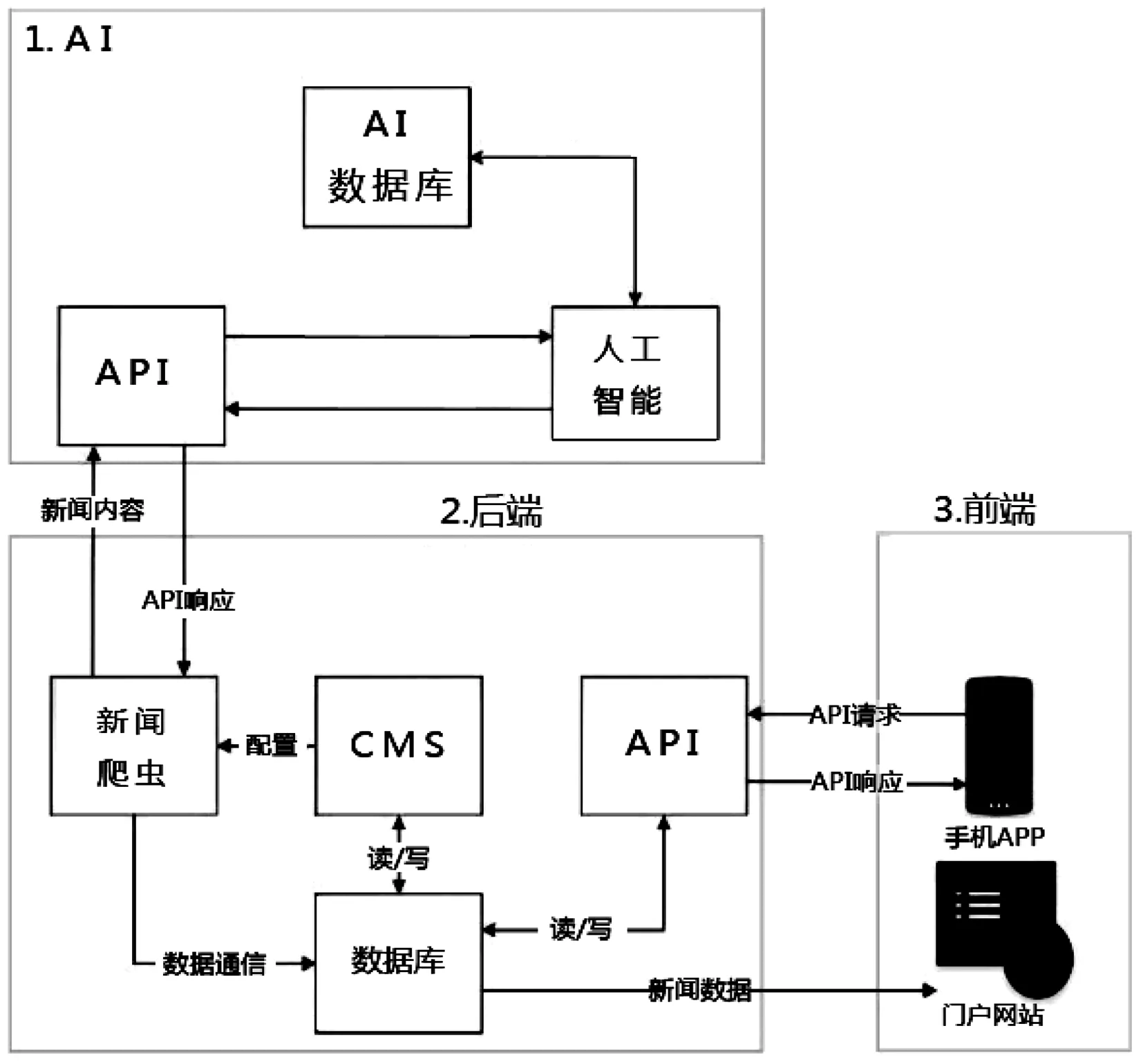
图1 系统概况
2 解决方案设计
2.1 解决方案架构
系统后端构架如图2所示,每个实体都有自己的功能来支持后端系统的操作,每个模块具体功能如下:
(1)Laravel框架是一个PHP框架,它可以用来托管应用程序的CMS,以及为移动客户端提供API,laravel框架主要将应用程序数据存储在MySQL数据库中,它还能够将通知数据通过Redis服务器发送到Socket服务器,从而向用户发送通知。
(2)Laravel REST API是Laravel框架的一个组件,REST API被用作移动客户端与框架之间的接口。
(3)Python新闻爬虫用于从各种来源检索Web页面数据,并提取要分析的内容并将其存储到MySQL数据库中。要分析新闻文章,爬虫会通过向AI发送一个HTTP请求来发送数据,分析的结果将决定提取的消息是否会存储到数据库中,或者被丢弃。
(4)MySQL数据库是用来存储和检索数据的数据库系统,之所以使用MySQL,是因为该框架支持本地MySQL数据库的ORM系统,Python新闻爬虫还可以直接与MySQL系统通信,而不需要使用Laravel框架作为中间件。
(5)Redis服务器是内存中的数据结构系统。在本研究中,Redis被用作Laravel框架和套接服务器之间的消息代理。它还被REST API用作缓存驱动程序,以减少对MySQL数据库的查询。
(6)Socket服务是Node.JS的一个实例,用于为其客户端提供WebSocket服务,它用于从Laravel框架向连接的客户端广播数据,其使用Socket.IO来进行WebSocket实现。

图2 后端构架
2.2 开发方法
这个项目采用了敏捷开发方法,鼓励早期的软件交付给客户。在这种情况下,这允许研究人员为主要客户端提供应用程序的早期测试,主要客户端是移动应用程序和AI新闻分析器。我们还利用了测试驱动开发(TDD),测试驱动开发允许开发人员编写包含模块功能需求的测试,测试完成后,将创建一个函数或模块来传递需求。它还确保代码重构或合并不会产生错误,因为代码将在部署之前进行测试,TDD用于本项目的API开发。
2.3 API设计
在API用例中有两个角色(如下图3所示):用户和经过身份验证的用户。认证的用户之间唯一的区别是拥有一个有效的API令牌,有一些API端点只对身份验证的用户具有独占性。
(1)身份验证:用户可试图通过提供他们的凭证来验证系统的身份,一旦证书生效,系统将向用户发出访问令牌。访问令牌的生命周期是有限的,可以在过期时间之前刷新,并在结束后很短的时间内刷新。
(2)注册:用户可以通过提供数据向系统注册,一旦用户注册,他们就可以尝试对系统进行身份验证。
(3)获取新闻列表:任何用户都可以通过搜索获取新闻类别或获取热门新闻(头条新闻)来检索新闻列表,一旦他们获得了新闻的列表,他们就可以通过访问另一个端点获取新闻的细节。
(4)获取新闻文章:用户可以获取新闻的细节和评论。
(5)获取另一个用户数据:用户可以获得另一个用户数据,比如他们的评论历史和最新成果。
(6)内容提交:经过身份验证的用户可以提交评论和喜好等内容。他们可以对文章发表评论并回复评论等。
(7)个人数据管理:经过身份验证的用户可以获取他们的个人数据,如新闻阅读历史、新闻喜好列表、新闻首选项和通知设置,并且可以更新他们的新闻偏好和通知设置。
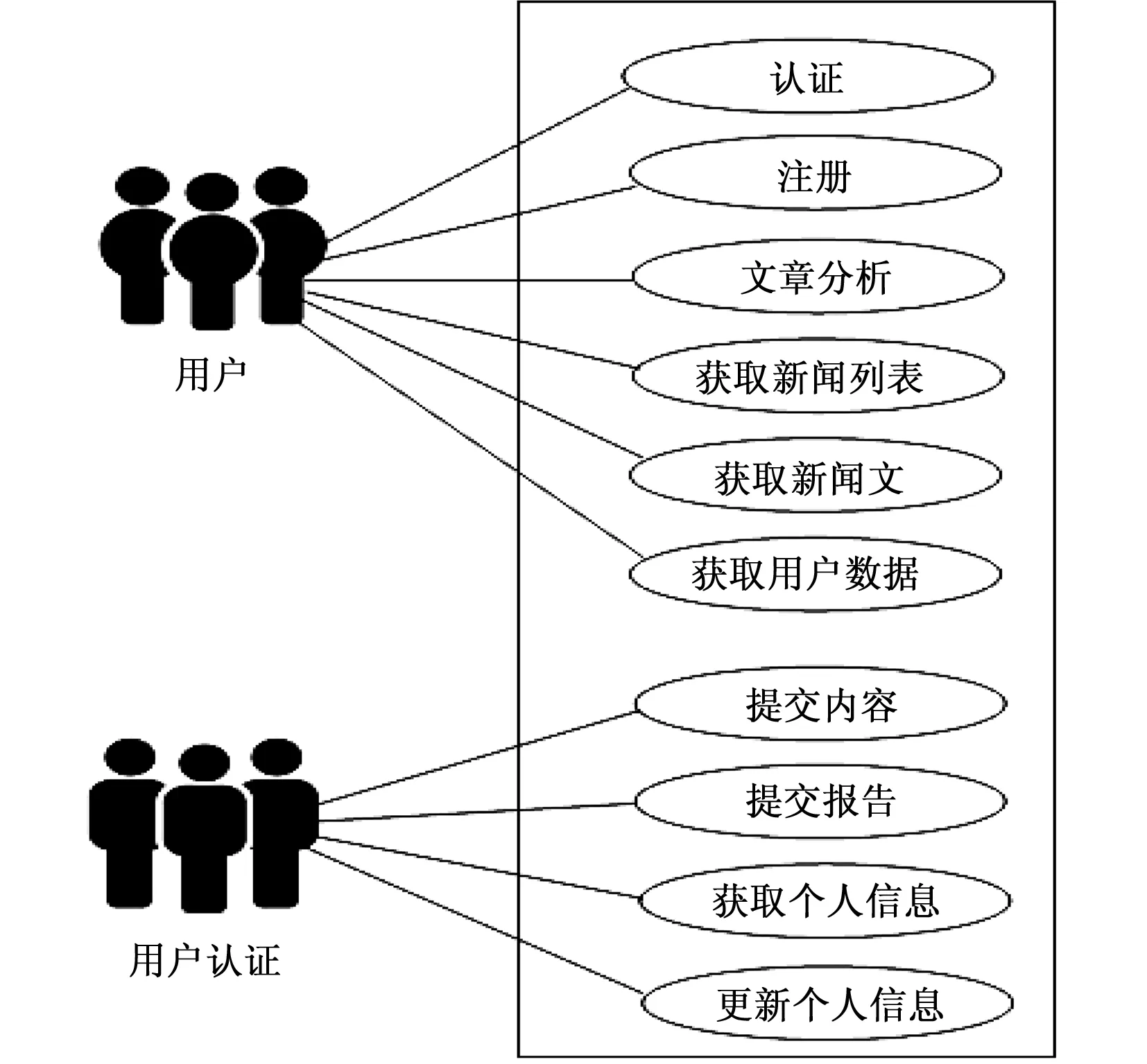
图3 API用例
2.4 爬虫设计
爬虫的设计中需要设置日志文件,假如在Linux环境下没有合适的日志文件,当计划任务开始后,命令行界面可能会被爬虫程序的输出淹没。用户可以通过设置来启动爬虫,例如,如果用户想从新闻站点sina.com获取数据,他们可以设置sina作为程序参数启动爬虫。为了简化调度任务,爬虫还可以设置扫描所有可用站点,只要每个站点的配置文件是有效可用的。
爬虫设计中需设置四个标记:第一个标记是限制标记,如果用户希望限制提取页面的数量,则可以设置限制标记;第二个标记是调试标记,如果希望程序在错误发生时立即退出,则可以设置此标记,当用户正在为站点构建配置文件时,这很有用。第三个标记是详细标记,如果用户希望看到当前爬行操作的进度,则可以设置详细标记;第四个标记是输出标记,用户可以选择抓取结果的输出目标,例如,用户可以选择输出到JSON文件中或数据库中进行进一步的处理。
3 测试和实施
3.1 服务器需求
表3显示了本项目的服务器需求:
3.2 测试系统规范
后端应用程序运行在Raspberry Pi2上,并在表4中显示了规范说明:

表3 服务器需求

表4Raspberry Pi2规范
3.3 API测试结果
API测试使用PHPUnit自动化测试,测试用例是根据移动应用程序的要求编写的,测试结果表明,所有的API端点都通过了测试用例。整个测试花费了2.36分钟,其中包括36个测试用例(包括错误测试)。为了加快测试的速度,测试使用存储在内存中的SQLite数据库。每个测试都可能包括HTTP代码判定、JSON结构判定或JSON输出判定。JSON结构和JSON输出判定之间的区别在于,在结构判定上,它只判定JSON的整体结构(不包括值),而输出判定则希望判定准确的值。
3.4 爬虫测试结果
爬虫通过SSH客户机测试系统。接口采用命令行接口(CLI),可以在CLI中执行的每个命令也可以由系统执行,爬虫的主要目的是定期从新闻网站获取新闻。Crontab是类Unix操作系统中的任务调度程序,在此用于启动预定的爬行会话。为了测试爬虫的实际功能,使用以下命令直接将命令输入到CLI:
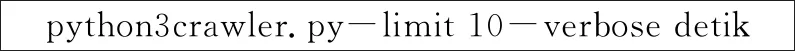
以上命令包含两个可选参数和一个必选参数,处理结果可能根据目标网站的内容而有所不同。在详细的测试结果中显示找到了60个链接。但根据参数的设置,如果链接的总数超过10个,链接提取器模块就会停止爬行。然而在详细数据中显示它只扫描了60个链接中的3个,这是因为爬虫会检查数据库中的链接,在限定时间内已经被爬行过的链接不再爬行。
3.5 爬虫扩展
为了增强爬虫的性能,用户可以通过添加配置文件或输出程序来增加爬行器的功能。用户可以向爬行器添加额外的配置文件,以允许爬虫遍历不同的网站,配置文件包含爬虫程序的数据,以便爬行器在网站上爬行,并对页面数据进行跟踪;通过为爬行器创建一个提供程序类,用户可以添加其他输出提供程序,而不只是输出到JSON,这样便于用户对不同类型的信息进行更合理的利用。
4 结 语
本文研究的爬虫不限于可以提取新闻站点的新闻,通过用户设置自定义配置文件,还可以提取其他多种类型的网站数据,并按照用户的需求使用多种输出方法来保存爬虫提取的数据。爬虫还有改进空间,比如为了提高爬虫的性能,添加作为守护进程运行的功能,这将使体系结构不依赖于诸如Crontab之类的任务调度程序等。爬虫本身是开源的,可以在此基础上对爬虫进行进一步的更新和完善。
