基于深度学习的混合推荐算法*
2019-06-25欧高亮汪海涛
欧高亮, 汪海涛, 姜 瑛, 陈 星
(昆明理工大学 信息工程与自动化学院,云南 昆明 650500)
0 引 言
随着大数据时代的到来,各大互联网公司对数据越来越重视,尤其是各大国内外的电商网站的实际需求是推进推荐算法研究的动力。国内外的电商网站上和社交网络上,最常见的推荐算法则是根据用户的历史行为数据来推荐用户可能会购买的或者感兴趣的商品或者话题。在现实的推荐系统中,影响推荐准确度的2个主要因素:数据稀疏性[1]、冷启动。在沉默用户占大多数的情况下,依赖用户历史行为数据的协同过滤算法的预测性能必然不够理想。
协同过滤推荐模型可以分为:早期提出的基于记忆的推荐;发展较为成熟的基于模型的推荐[2,3];前瞻性较好的混合型推荐[4,5]。基于模型的推荐中矩阵分解方法[2~4]是其最具代表性的一个方法。隐语义模型(latent factor model,LFM)[2]算法则是矩阵分解算法中较为常用的。LFM算法通过降维来获得隐含特征,进一步预测用户对商品的潜在打分,其推荐精度有待提高。
近年来,深度学习理论发展使得利用神经网络从大规模无标注数据中提取特征成为可能。Oord A V D[9]和Xang X提出直接用卷积神经网络(convolutional neural network,CNN)[8]和深度信念网络(deep belief network,DBN)[9]从内容信息中学习特征表示用于音乐推荐。为了综合利用评论文本和评论信息来提高推荐系统的效果,Wang H等人提出了协同深度学习(collaboration deep lear-ning,CDL)模型[10],CDL解决了模型在数据稀疏时,学习隐藏特征不充分的缺陷,其没有考虑沉默用户问题。当前国内研究人员,张敏等人提出了隐因子模型(stack and denoi-sing auto-encoder,SELFM)[11]来加强语义,利用层叠降噪自动编码器(SDAE)提取商品评论文本特征,将用户评论与评分联合,以此提高评分预测的准确性,但SDAE的学习能力和分类精度不如稀疏边缘降噪自动编码器(sparse marginalized denoising auto-encoder,SmDAE)。邓俊峰[12]提出的一种优化的SmDAE模型,把稀疏、边缘降噪编码器的优点联合在一起,增强了深度网络的学习能力和分类的准确度。
本文模型选用改进的SmDAE用来处理评论文本。
1 本文算法
结合深度学习和协同过滤的方法,提出了一种改进SmDAE与近邻项目影响力的矩阵分解模型相结合的混合推荐模型(Sm-LFM),在特征提取的部分,通过SmDAE算法从经过选词模型的评论文本中提取项目特征向量。并优化了SmDAE网络,Softmax是当前分类效果较好的分类器,并且把分类器加到整个网络的输出,把网络输出分类为商品评分的五类评分,并且将实际评分和预测评分参与SmDAE网络微调,将评分作为特征提取有效性反馈。在协同过滤部分,在数据过于稀疏会导致LFM模型不能很好显示项目的真实的特征,通过商品特征向量来计算近邻项目的影响力,将近邻项目影响力加入矩阵分解模型中以加强项目特征表征性,来提高算法效率与推荐精确度。
Sm-LFM模型主要框架如图1所示。Sm-LFM模型由评论处理模型,文本编码模型、LFM矩阵分解模型三部分构成。

图1 Sm-LFM模型框架
1.1 评论处理模型
文本编码模型所用的词空间大小由评论处理模型确定。每个商品全部评论合并评论文本特点是找不到任何规律的,其长短不一、词汇量变化大,且自动编码器的输入要求是定长。在评论文本各词出现频率差异较大,很难判断是不是商品特征的关键字。在所有评论中,少量的评论与评分相互矛盾,也没有实际意义,属于无效的评论。首先把无效的评论过滤,再采用关键词抽取方法(TFIDF)来确定每个词的重要性,TFIDF是当前文本处理比较常见的方法。选出TFIDF值最高一组构成一个词空间。每个商品的评论都有一个与词空间对应的相同维度的向量来表示,即评论处理模型的输入。
1.2 文本编码模型
1.2.1 自动编码器
自动编码器由输入层(h)、隐含层和输出层(y)组成,输入层和输出层规模相同,隐含层规模小于输入和输出层的规模。设编码函数为f,解码函数为g,则
h=f(x):=Sf(wx+p)
(1)
(2)
式中Sf和Sg分别为编码器和解码器的激活函数。
训练网络参数尽可能地使h和y靠近,其用重构误差L(x,y)来表示接近程度。当Sg为Sigmoid函数时,有
(3)
训练集样本是S,自动编码器的整体损失函数
(4)
对于稀疏自动编码器(SAE),其损失函数为
(5)

对于边缘降噪自动编码器(mDAE),其损失函数为
(6)
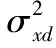
1.2.2 稀疏边缘降噪自动编码器
在编码器的隐含层上同时引入了SAE的稀疏性限定条件和mDAE的边缘降噪限定条件,形成SmDAE,显然SmDAE也就具有两种网络的优点。其网络结构如图2所示。

图2 SmDAE的网络结构
在隐含层上分别加入SAE和mDAE的约束表达式,归纳式(5)稀疏自动编码器和式(6)边缘降噪自动编码器的损失函数表达式,得到的SmDAE的损失函数
JmDAE(θ)=L(x,fθ(μx))+JSAE+JmDAE
(7)
1.2.3 改进的SmDAE特征提取
评论文本通过SmDAE处理后得到的只是商品特征,预测的评分以及用户对商品的喜爱程度才是最终的结果。为了充分利用评论文本的信息以提高特征质量,优化SmDAE网络,整个网络的输出后面加上分类器,把输出分类为商品评分的五类评分,且将实际评分和预测评分作为特征的有效性反馈,此时的优化目标需在式(7)的基础上加上预测评分和真实评分损失函数Y
(8)

通过训练网络来优化损失函数J。因为单层SmDAE网络的特征提取能力不足,也不能充分体现网络的优势。因此,解决的方法则是堆叠,形成多层SmDAE网络。通过首先分层训练每层SmDAE,再微调整个网络已达到网络最优化。
1.3 基于近邻项目影响力的矩阵分解模型
1.3.1 近邻项目的相似度计算和影响力计算
比较项目相似性时,只需要计算每个项目特征向量的相似性即可。采用余弦相似度来计算项目的相似度,余弦值越接近1则越相似。假设A[A1,A2,…,An],B[B1,B2,…,Bn]为两个n维特征向量。相似度计算
(9)
为了反映近邻项目对目标项目的影响,本文将近邻项目对目标项目的影响力融入到矩阵分解模型中。假设影响力为X,则N个近邻项目对目标项目的影响力为
(10)
式中X为项目产生的影响力,T为近邻项目的集合,Wf为每个近邻项目产生的影响力隐式反馈。
1.3.2 矩阵分解模型
用户行为数据集即用户—项目评分矩阵,使用LFM对其降维,R矩阵为用户—项目评分矩阵,矩阵值Rui为用户u对项目i的评分。LFM将评分矩阵RU×I分解为2个低维度矩阵PU×N与QN×I。用户U对商品I的评分模型为
(11)
将近邻项目的影响力加入到评分模型中,得到新的评分模型
(12)
所有的评论集合为K,最优化损失函数C来估计参数,损失函数

λ2‖QI‖2+λ3‖X‖2
(13)
协同过滤算法容易过拟合的主要原因就是评分矩阵过于稀疏,在损失函数中加入了正则项λ1‖PU‖2+λ2‖QI‖2,防止过拟合,采用随机梯度下降法来最小化损失函数,该算法是最优化理论里最基础的优化算法,首先通过求参数的偏导数找到最速下降方向,然后通过迭代法不断地优化参数,系数λ则需要反复实验得到。式(13)中的C则是LFM模型的最小化的目标。
文本编码模型可以微调整个矩阵分解的过程,来提升模型预测准确率,同时在优化LFM模型时,也可以微调文本编码模型的参数,使整个模型的性能最优化。在数据过于稀疏会导致LFM矩阵分解模型不能很好地显示项目的真实的特征,本文将近邻项目影响力加入矩阵分解模型中以加强项目特征表征性。
2 实 验
2.1 数据准备
实验数据集采用亚马逊数据(Amazon product data)。亚马逊作为美国最大的电商平台,其评论数据集真实有效;几乎涵盖了所有商品的种类;子数据集根据平台的商品类别划分的,由于数据集过于庞大,本文实验中选择性下载艺术、食品、手机、鞋类、办公用品等5个用于实验的其中5个5核心“小”子集,这5个数据评论子集评论内容翔实,文中实验选择的5个数据集各方面皆互异,对于测试本文模型在不同环境下的性能有益。
实验数据集随机按照1∶9分成测试集和训练集,为了对比实验的条件尽可能一致,因此,对比实验也用本文模型相同的训练集合测试集。
本文采取均方根误差MSE来评价模型性能。假设测试集为T,其中,RUI是用户u对商品i的实际评分,UI是模型预测出来的用户u对商品i的评分,则MSE定义为
(14)
2.2 实验设计
选择CDL和混合SDAE模型[13]作为本文的对比模型。CDL模型将概率化LFM模型与贝叶斯SDAE模型相联合,CDL模型通过从商品的内容和标签来提取特征,从而得到用户对商品评分的数学期望。用Theano来实现CDL模型,CDL中LFM模型与本文模型的部分参数、细节尽可能相同。混合SDAE模型是将极限学习机和SDAE相结合推荐模型,使用逐层自编码的思想将极限学习机与降噪自编码器堆叠,计算的堆栈降噪自编码器的深度学习模型,最后通过用模型提取的特征应用于最近邻算法预测打分。对于混合SDAE模型中SDAE,与本文模型的网络层数、部分参数、细节尽可能相同。
对于本文Sm-LFM模型,通过评论处理模型选择出2 000个TFIDF值最高的词,作为文本编码模型的输入,文本编码模型中选择3层SmDAE网络,隐含特征空间的维数取n=300,系数取λ1=λ2=λ3=0.1。此中SmDAE网络的第一、二、三层的输出维度取值依次取800,80和5,降噪参数每层都相同为0.94,近邻数目取10个。文本编码模型和矩阵分解模型都用较为常见的方法训练,前者采用Adam方法,后者采用随机梯度下降方法。
为确保本文模型和对比模型的对比性,采用均方根误差(mean square error,MSE)作为衡量模型预测评分准确度的指标均方根误差,即预测评分与测试集真实的评分的MSE。
2.3 实验结果与分析
2.3.1 不同模型性能对比
在Sm-LFM、混合SDAE模型[13]和CDL模型上分别运行测试数据集,从表1可以看出,Sm-LFM模型的性能在5个子数据集上均有提升,相比CDL和混合SDAE模型都有较大的提升。提升效果最好的和最差的分别是鞋类和办公用品,前者提升了近8.4 %,后者提升近1 %。
在同样使用深度学习网络提取特征的情况下,Sm-LFM比混合SDAE模型性能提升约 5.43 %,混合SDAE模型没有引入额外的特征加强信息,且其评分预测使用极限学习机和最近邻算法严重依赖特征质量,且学习能力弱于Sm-LFM使用的SmDAE。Sm-LFM比CDL模型性能最高提升8.370 %,CDL模型通过从商品的内容和标签来提取特征的能力不如通过SmDAE从评论文本提取特征的能力。
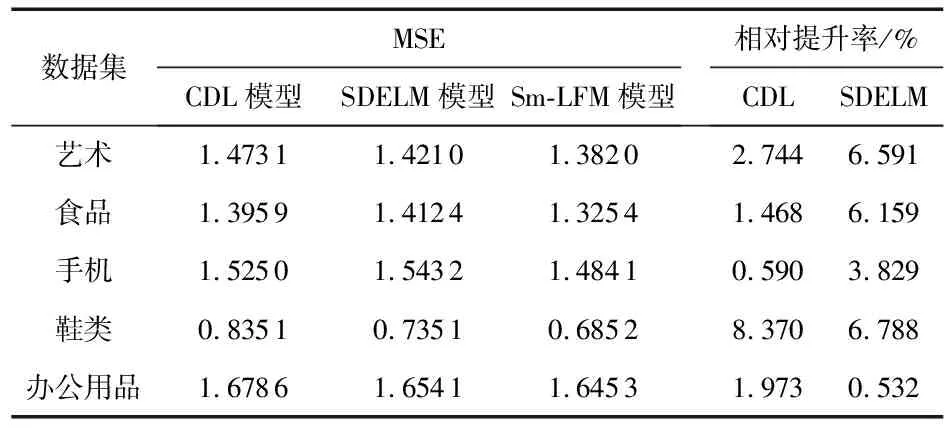
表1 性能对比
2.3.2 超参数的影响
超参数n代表了SmDAE网络从评论文本中提取出的项目特征的有效维度,也是矩阵分解的隐因子空间维度,即式(9)中的n。因此,n的取值将会很大程度影响算法的精确度,图3是不同n值对SmDAE的MSE性能的影响。由图 3可以看出,当n值低于100时,提取不到有效的项目特征;当n值过大时,引入干扰信息会使MSE的值增大;式(13)中λ根据反复实验得到,当λ1=λ2=0.1,且n=400时,模型性能最优,MSE为0.68。
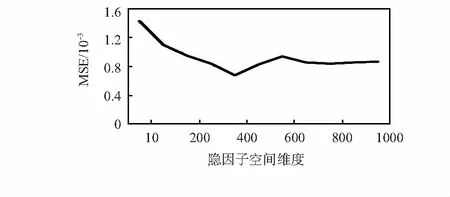
图3 超参数n对模型性能(MSE)的影响
3 结 论
本文提出Sm-LFM模型,概括考虑评论文本与评分用来挖掘商品的潜在特征,并考虑了近邻项目对预测评分的影响,预测评分的准确率上相比混合SDAE模型和CDL模型有所提高,虽然本文模型的训练时间相比对比模型花费的更多,但本文模型不需要每一次数据更新都重新开始训练,只需微调模型即可,所以,本文模型的平均训练时间相比其他模型来说,依然较短。在下一步的工作中,考虑将评论文本中的无效评分与评分和评论文本内容不符合的评论过滤,并且将尝试把更多文本分析相关的深度模型引入推荐算法中来进一步来提高算法效率与推荐精确度。
