主题词法和自然语言法探测文献主题新颖性对比分析
2019-06-13
文本新颖性探测是指按时间顺序在给定的一些相关文献集中,比较新到相关文本与已有文本之间内容的冗余度,确定新到文本内容是否新颖[1]。对于科技文献质量的创新性、新颖性的分析评价,目前没有统一的标准,可以通过以下方法进行。一是基于文献计量学的引文分析法。该方法利用科学文献间的引用关系反映科技成果的学术价值以及学术地位,说明科学知识和情报内容的继承和利用,评价推荐出新颖性文献[2],其最大缺点是时间的滞后性。二是基于向量空间模型的相似度计算方法。应用最广泛的是向量夹角余弦值。Salton[3]提出TFIDF算法进行权重赋值,该方法体现的主要思想是当一个词语在特定文献中出现的频率越高,说明它在区分文献内容属性方面的能力越强;一个词语在特定文献中出现的范围越广,说明它在区分文献内容属性方面的能力越低。当前文本和以前文本之间的相似度越大,则新颖性越小[1]。三是基于关键词词频分析的方法。关键词是作者根据文章的主要内容、理论、方法、观点,通过概括、总结提炼出来用于揭示文章主题信息的自然语言,关键词数量通常少于自然语言词和医学主题词。不同作者因地域、时代的差异,对于事物、观点的称谓不尽相同。关键词具有一定主观性,无法做到表述一致,对文献新颖性分析存在不同程度的影响。因此,在文献新颖性分析之前,应对关键词进行规范化预处理,降低同义词、近义词、上下位词对分析结果产生的影响。四是基于创新型生物医学文献学术评价系统F1000的评价方法。F1000是生物医学领域同行评议的数据库,F1000专家对世界顶级的生物、医学杂志最新发表的文章从创新性、重要性、合理性、方法学等方面进行同行评定,选取最有价值文献给予推荐,帮助生物学及医学领域的研究人员掌握本学科领域的最新研究进展。同行评议是专家根据个人的态度对文献本身学术成就给予的评价,主观性大。五是突发词监测算法。根据词频变化率统计出低频但具有情报意义的突发词,探测新兴研究热点和研究趋势,适用于某研究领域前沿趋势的探测[4]。
近年来,国内多位学者进行了文献主题新颖性探测的相关研究。如徐爽[4]通过突发词监测算法研究了全身炎症反应综合征治疗药物,根据词频变化率统计出低频但具有情报意义的突发词,探测该领域新兴研究热点;杨建林[5]运用基于关键词对逆文档频率的方法进行主题新颖性的度量;陈斯斯[6]应用词重叠法和基于共词的逆文档频率量化法对比分析探测评估医学文献主题新颖性,得出词重叠法更优的结论。
有研究通过自然语言词对方法(以下简称“自然语言法”)计算了文档主题新颖度,探讨了文档主题新颖度与F1000推荐文献、引用情况分属于科技论文评价的不同维度、不同范畴,不可一概而论[7]。本文在此基础上提出了基于医学主题词词对法的文献主题新颖性探测方法(以下简称“主题词法”),运用两种方法对同一文献集进行文档主题新颖度的计算并进行比较分析,探讨两种方法计算文档主题新颖度结果的一致性和差异性,以及两种方法的优缺点和与F1000推荐文献的关系。
1 研究方法与工具
1.1 研究方法
医学主题词词对逆文档频率原则(Inverse Document Frequency of Mesh Pair,MPIDF),即一对共现的医学主题词词对在量化某文档的主题新颖度时的价值随着在该文档之前发表的、包含该对共现医学主题词词对的文档数量的增加而降低[5]。
医学主题词时间逆文档频率是指若t为文档D中的一个已标引的主题词,在文档D之前发表的所有文档中包含已标引主题词t的文档数为N,则称N+1为以文档D为参照的主题词t的文档频率,记为MT-IDF(D,t),称N+1的倒数为以文档D为参照的主题词t的时间逆文档频率,记为MTIDF(D,t)。
医学主题词词对时间逆文档频率是指若t1、t2为文档D中共同出现的两个已标引的医学主题词,在文档D之前发表的所有文档中同时包含已标引医学主题词t1、t2的文档数为N,则称N+1为以文档D为参照的医学主题词词对t1、t2的文档频率,记为MPT-IDF(D,t1,t2),称N+1的倒数为以文档D为参照的医学主题词词对t1、t2的时间逆文档频率,记为MPTIDF(D,t1,t2),得到MPTIDF(D,t1,t2)≥(MPTIDF(D,t1),MPTIDF(D, t2))。
主题词法文档主题新颖度是指文档D中所有以自身为参照的医学主题词词对的时间逆文档频率的平均值称为文档D的主题新颖度,记为NOV(D,M)。计算公式为:
式中,ti、tj为文档D中已标引的第i和第j个医学主题词,显然NOV(D,M)∈(0,1)。
1.2 研究工具
1.2.1 F1000
F1000是近年来生物医学领域同行评议的文献评价数据库,每年对全球文章总数不足2‰的优秀精品医学论文进行推荐和点评,给出F1000得分,依据学术贡献和科学价值挑选出优秀论文推荐给全世界的生物学和医学研究者[8],帮助生物学及医学领域的研究人员掌握本学科领域的最新研究进展。研究人员发表的论文被F1000收录并获得推荐,是对该论文和研究人员的高度认可。
1.2.2 MeSH
《医学主题词表》(Medical Subject Headings,MeSH)由美国国立医学图书馆编制而成,主要目的是提供一个分层组织的术语,用于MEDLINE/PubMed和其他NLM数据库中生物医学文献信息的索引和编目以及检索利用[9-10]。MeSH由主题词(Descriptors,亦称“叙词”)、副主题词(Qualifiers,亦称“限定词”)和增补概念构成[9]。副主题词指主题词所论述的重点课题的自然范畴或通常发生的某一方面,对主题概念起限定作用[9];副主题词与主题词进行逻辑组配,专指性更高,可以提高查全率和查准率,是实现智能化检索的重要途径。
本文选取自然语言法相同文献集,在同篇共现基础上计算主题词法文档主题新颖度,提取PubMed中已标引的MeSH词汇代表文章的主要内容。该文献集内含401篇文献(其中F1000推荐文献33篇),具有MeSH标引的文献346篇(其中F1000推荐文献30篇),从中提取MeSH标引词汇7 021条记录,组合成词对后共计约8万条记录。根据主题词法文档主题新颖度公式计算出每篇文章的新颖度值,结合自然语言法新颖度结果进行对比分析。
2 实验结果和结论
2.1 文档主题新颖度分区
文档主题新颖度值及分区情况统计见表1和表2。

表1 两种方法计算的文档主题新颖度值(部分)
注:* 代表F1000推荐文献
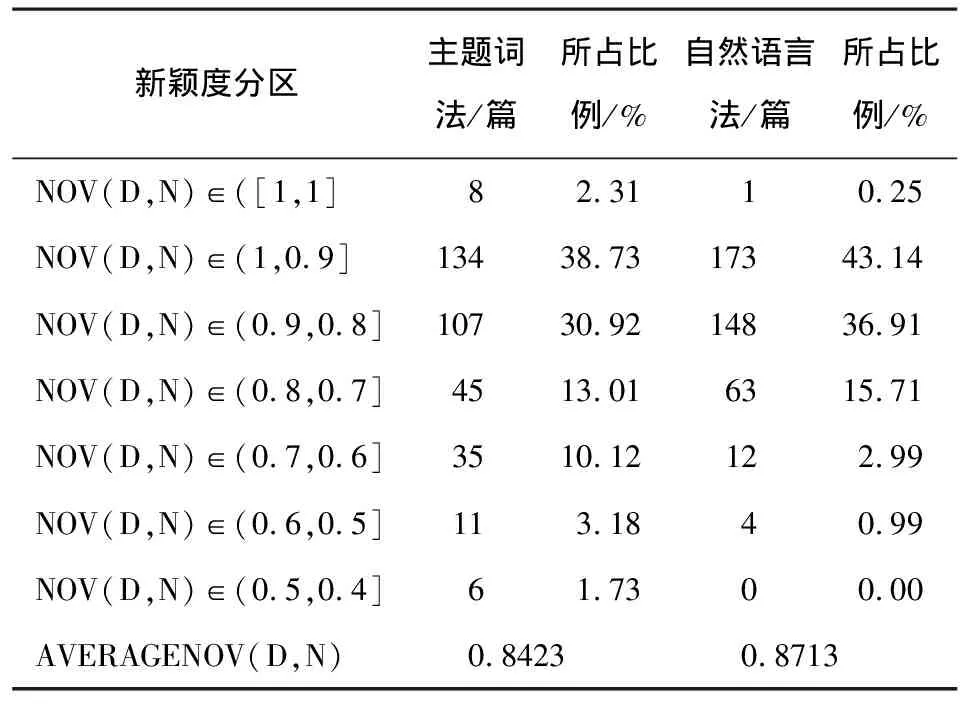
表2 主题词法和自然语言法文档主题新颖度值分区
对主题词法和自然语言法获得的文档主题新颖度值进行Spearman相关性比较显示,两种方法在计算文档主题新颖度之间呈正相关,相关系数为0.593,P=0.000,可见主题词法和自然语言法在计算文档主题新颖度方面有相对等效的价值。
主题词法计算新颖度的范围为PubMed中已有MeSH标引的346篇文献,未标引的55篇文献主要是因下载文献过新而尚未进行标引。主题词法计算出的新颖度最高值为1,共有8篇,说明其在区分最高级别、最卓越文献方面不是特别理想;该方法计算出的最低值为0.439。新颖度值相差0.1分为一个区间,计算结果可分为7个区间,平均新颖度值为0.8423,大于平均新颖度值的文献有212篇,占统计文献总数的61.27%。
2.2 F1000推荐文献文档主题新颖度分区情况
两种方法计算的F1000推荐文献文档主题新颖度分区见表3。用主题词法计算该文献集中MeSH标引的364篇文献中,F1000推荐文献30篇;用自然语言法计算该文献集全部的401篇文献中,F1000推荐文献33篇。
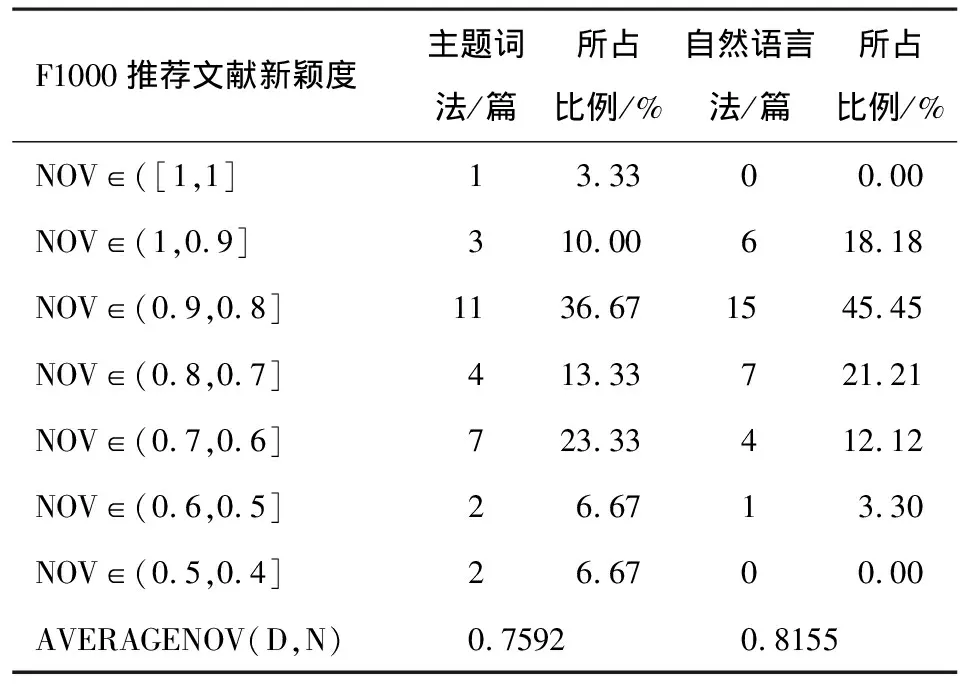
表3 主题词法和自然语言法计算的F1000推荐文献文档主题新颖度分区
用主题词法计算的F1000推荐文献中的新颖度最高值为1,最低值为0.448,计算结果共分为7个区间。该方法计算出的平均新颖度值为0.7592,大于平均新颖度值的文献有18篇,占统计文献总数的60%,与自然语言法占比等同,说明在识别高质量文章情况下,两种方法计算结果基本一致。
2.3 两种方法计算结果分布的一致性比较
两种方法计算结果分布的一致性是指主题词法和自然语言法计算出的文档主题新颖度值均分布在某区间的文献数占统计文献的比例。Meet/min方法是目前被公认的一种简单有效的评估协同程度的方法[11],运用Meet/min方法将两种方法计算出的新颖度值分区在同一区间内的共同文献数量可定义一致率的概念,公式如下。结果见表4和图1。

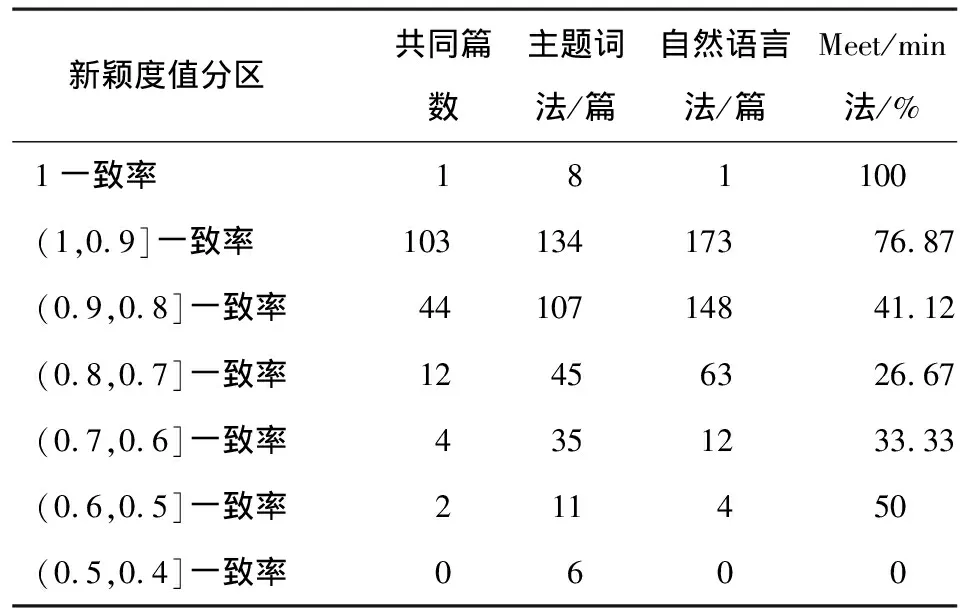
表4 主题词法与自然语言法计算的新颖度值一致率
从表4可以看出,随着新颖度值的增加,分布在同一区间内的文献篇数也在增加。新颖度值在0.5~0.8之间的一致率呈下降趋势,可能由于统计文献的样本数量较少所致;新颖度值在0.7~1之间的一致率呈上升趋势,说明新颖度值越高,主题词法和自然语言法在计算文档主题新颖度方面越能获得相同的预测效果。
图1是对346篇主题词法新颖度值和401篇自然语言法新颖度值做成的散点图,横坐标为文献序列号,纵坐标为新颖度值,其中346篇文献中每个序列号分别对应图中两个颜色的点以及它们分布的位置,所对应的两个点的距离就是两种算法新颖度值的差距。
从图1可以看出,新颖度值越高,两种颜色点的分布越密集,主题词法和自然语言法计算出的文档主题新颖度值分区越一致。
2.4 两种方法计算结果分布差异性比较
两种方法计算结果分布差异性是指同一篇文献经主题词法和自然语言法两种方法计算后得到的新颖度值之间的差值。结果见表5和图2。

图1主题词法和自然语言法新颖度一致性的分布散点图
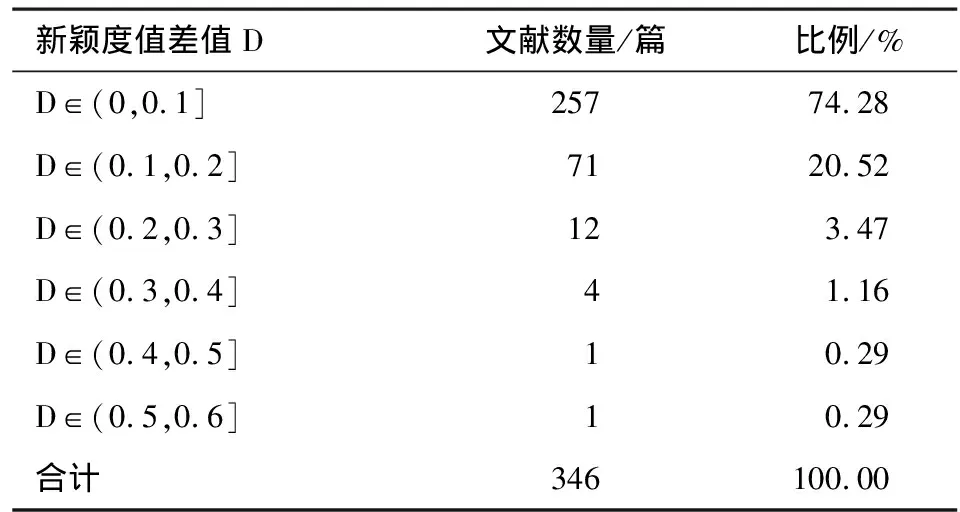
表5 主题词法和自然语言法计算的新颖度值差异
从表5可以看出,同一篇文献经主题词法和自然语言法两种方法计算得到的新颖度值之差在0~0.1的最多,为257篇,占统计文献总数的74.28%;差值在0.1~0.2的文献为71篇,占统计文献总数的20.52%;差值在0.2~0.3的文献为12篇,占统计文献总数的3.47%;差值在0.3~0.4的文献为4篇,占统计文献总数的1.16%;差值在0.4~0.5的文献和在0.5~0.6的文献均为1篇,分别占统计文献总数的0.29%。
说明绝大多数文献经两种方法计算得到的新颖度差值在0.1以下。
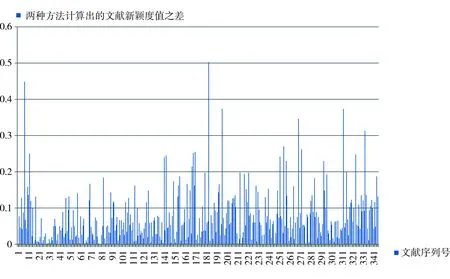
图2 主题词法和自然语言法新颖度差异
图2是根据用两种方法对346篇进行计算得到的每篇文献新颖度差值做成的一个柱状图,横坐标代表文献序列号,纵坐标代表两种方法计算的新颖度差值。从图2可以看出,同一篇文献经主题词法和自然语言法计算出的新颖度值之差在0~0.1之间分布最多,差值在0.1~0.2之间的文献数量次之,说明两种方法在计算文档主题新颖度值方面差异不大,在探测文档主题新颖度方面具有等同的效果。
2.5 F1000推荐文献新颖度与其他指标比较
两种方法计算的F1000推荐文献文档主题新颖度值与其他指标的比较见表6。
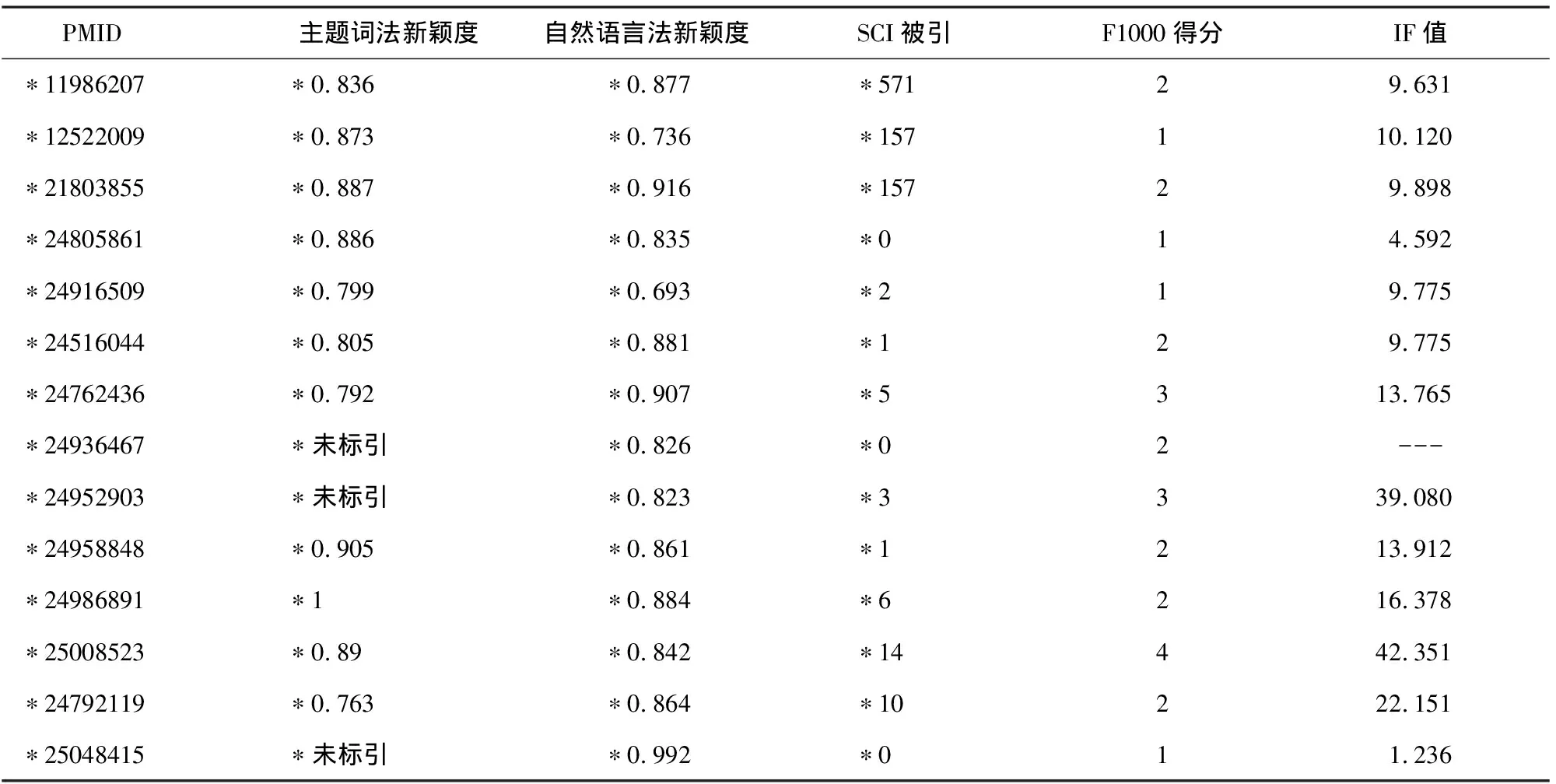
表6 主题词法和自然语言法计算的F1000推荐文献文档主题新颖度情况及其他指标比较(部分)
上述表格各列数据经过统计学方法判断均没有统计学意义,自然语言法新颖度值、IF值及F1000得分都不存在相关性,主题词法新颖度值和F1000得分弱相关,说明相比自然语言法而言,主题词法计算新颖度值与同行评议结果趋于一致。
图3表示两种方法计算的文档主题新颖度值与F1000得分的关系,横坐标表示F1000得分,纵坐标表示新颖度值,中间的横线代表两种方法计算的新颖度中值,两者距离越相近,说明两种方法计算出的新颖度值越靠近。从图3可以看出,随着F1000得分的增高,两种方法计算的新颖度越相关。两种方法计算得到的新颖度值的高低与文献所在期刊的IF值并无明显相关性。
3 讨论
3.1 两种方法优缺点对比分析
从计算层次来看,两种方法均是从文本层出发进行的主题新颖性探测,不同之处在于主题词法是在同篇共现基础上进行的计算,能将整个文献集内经过MeSH标引的文献进行计算获得新颖度值;自然语言法是在同篇同句共现基础上进行计算,将提取的自然语言词汇经公式计算后获得的新颖度值[7]。
从计算范围来看,主题词法计算了文献集内经MeSH标引的346篇文献,自然语言法计算了文献集内的全部文献401篇,计算范围比主题词法广泛。
相比较而言,主题词法具有不可替代的自身优势,它将自然语言转换成规范化名词术语,在揭示文章主要内容、表达主旨含义上更加科学、准确,在计算新颖度值上更加准确,与同行评议结果符合度更高;自然语言法通过MetaMap提取自然语言词汇,在进行计算时可以不受时间的限制而将整个文献集内的全部文献进行计算得到不同的新颖度值,在一定程度上代表主旨含义,在揭示新兴主题概念方面具有更高的价值[7]。

图3 两种方法新颖度值与F1000得分关系
虽然MeSH每年都在更新,但仍然滞后于科学技术的发展。新的科技词汇要在出现一段时间后才会经过专家学者推荐核准为正式的主题词用于文章标引,这在体现最新科技研究成果方面会受到制约。同时最新发表文献因尚未进行MeSH标引,在进行计算时有一定限制,早年发表的文献也存在缺失标引或者未标引的情况。而自然语言法因受MetaMap自由度影响,随其词汇源不断更新,MetaMap提取新兴科技词汇的效果好则结果好,反之亦然[7]。
本文两种文档主题新颖度的计算方法,对评价量化文献主题新颖性提出了全新指标,两者在一定程度上有着等效价值,随着计算的文档主题新颖度值的增高,两种方法计算出的新颖度值越相近。
3.2 论文不同层面评价指标分析
本文两种方法计算的文档主题新颖度是从文本层面出发而进行的客观量化分析评价,分别从文中提取词对进行计算,通过发现对比之前文献集中尚未出现的词对情况来证明文献的新颖程度,对文献集中每一篇文章给出评价,相对更加客观。同行评议指标F1000评分相对简单,仅将各位专家评分累积求和即可获得F1000得分。F1000是基于同行评议的论文评价,难以保证评价的绝对客观性,同时也存在运用范围不够广泛、全面的情况。
本文发现F1000得分与主题词法新颖度值存在弱相关,表明该方法通过提取代表主旨含义的医学主题词词对进行计算后得到的新颖度值与专家同行评议在一定程度上一致,也就是从论文评价的不同层面给出相对一致的结论。这也与刘春丽发现不同类型计量指标对同一组论文影响力的评估具有一致性的结论相符[12]。
3.3 文献提取和计算过程中的不足
PubMed数据库中记录的错误对于结果有一定的影响,如自然语言法提取文献已经限定PT为非Review,而主题词法在提取已标引MeSH词汇时有Review的出现,PubMed数据库在录入方面存在不一致情况,会对结果产生一定影响。
主题词法在进行计算时,选取只保留“主题词”“主题词/副主题词”一致即可,把加权符号去除,不考虑加权标引。因考虑到文献集内不同文章进行加权标引一致情况较少,所以只要文章出现同样的标引词即认为一致,可能会对计算结果产生影响。
4 结语
主题词法和自然语言法可从文本层面计算文档主题新颖度,两者各有优势,自然语言法在计算范围和最新发表的文献推荐方面要略优于主题词法,主题词法在揭示文章主旨含义方面优于自然语言法。
根据相关性比较,主题词法和自然语言法在计算文档主题新颖度方面具有相对等效的价值。新颖度值越高,两种方法计算出的文档新颖度值分区越一致。
主题词法文档主题新颖度与F1000得分呈弱相关,说明主题词法的文档主题新颖度准确性更接近于专家同行评议。
