基于隐马尔可夫模型的反射型XSS检测技术
2019-06-11
(1.浙江工业大学 经济学院,浙江 杭州 310023;2.浙江工业大学 信息工程学院,浙江 杭州310023)
自从进入Web 2.0时代以来,用户成为网站内容的贡献者,大量交互产生在客户端,同时也产生了大量的Web漏洞,对Web应用的安全构成了严重的威胁。跨站脚本攻击(Cross-site scripting,XSS)是一种危害严重的Web漏洞,其常年位居开放Web应用安全项目组Top10漏洞的前3 名。其中,反射型XSS攻击危害最为广泛,其危害主要有盗取用户Cookie、会话劫持和网络钓鱼等。在防御反射型XSS攻击时,最直接的方法是使用跨站脚本过滤器XSS-filter对用户提交的输入进行过滤,XSS-filter使用黑名单策略,能够对黑名单中的字符串进行过滤,然而黑名单策略是静态防御,只能利用已有的规则进行拦截,对于未知的反射型XSS检测效果并不理想。针对XSS攻击的检测,已经有相关工作者研究并设计了XSS检测方案,储泽楠等[1]提出使用k均值算法实现聚类并计算后验概率,以此初始化隐马尔可夫模型(Hidden Markov model,HMM)参数,生成具有更高检测率HMM网络入侵检测模型。Gputa等[2]提出在线和离线相结合的方法检测XSS攻击,对于移动云上的XSS检测有良好效果。Salas等[3]提出使用渗透测试的方法检测XSS漏洞,对于XML格式的跨站脚本攻击有较好检测效果,但是其他格式的跨站脚本攻击设计较少。林冬茂[4]提出对监控对服务器“写”操作的数据流,与规则库对比,以此判断是否为遭到入侵,此方法受到规则库的限制,只能拦截数据库中已有的攻击规则。
在研究了当前各种XSS攻击检测技术的基础上,针对现有反射型XSS攻击检测技术只能集中在特定领域或常见类型的不足,鉴于HMM具有强大的统计学基础与高效的数据处理能力,笔者改进了基于HMM的反射型XSS攻击检测技术,充分研究反射型XSS以及变形反射型XSS的构造原理,使用词集模型对样本进行词汇分割并序列化作为观察序列,进行HMM训练并生成检测模型,能够改善基于规则的检测器对于未知的和变形的反射型XSS的检测效果[5]。
1 XSS的分类和变形XSS
1.1 XSS的分类及特点
XSS根据利用手法不同可以分为反射型XSS和存储型XSS。
反射型XSS也称作非持久型XSS,攻击者构造一个含有恶意代码的URL,然后诱骗用户点击此URL,用户点击URL后,恶意JavaScript代码就会在用户的客户端执行,恶意JavaScript代码只在用户点击URL链接时触发,只执行一次,所以被称作反射型XSS。
存储型XSS也称作持久型XSS,存储型XSS不需要用户点击特定URL就能进行攻击,攻击者将含有恶意代码的页面上传到服务器上,然后用户在浏览包含恶意代码的网站就会执行JavaScript代码,一般出现在网站评论和转发处[6]。
在两种类型中,反射型XSS更为普遍,因为其构造简便,且变化形式较为丰富,反射型XSS能够直接在URL的参数中构造,可以利用规则进行过滤,或用机器学习的方法进行识别,而存储型XSS的URL中不一定含有攻击代码,目前还没有非常有效的方法对存储型XSS进行检测[7-8]。
1.2 变形XSS构造方式
普通的反射型XSS容易被XSS-filter检测,攻击者通过构造变形XSS来绕过检测,例如利用空格来分离敏感词:对于JavaScript而言,可以构造如下变形攻击载荷:,其中用空格键将javascript隔开,可以绕过XSS-filter。利用大小写混淆来构造变形XSS:
,如果黑名单中没有对大小写过滤,那么这种方式就可以绕过XSS-filter,还有其他变形XSS攻击构造方法,例如对标签属性值进行ASCII转码,将URL中的关键词转化为URL编码等手段来绕过检测[9]。
基于规则的XSS检测器的黑名单机制难以应对变形的反射型XSS攻击,基于HMM的检测器在处理XSS攻击样本时,对攻击样本从整体结构上进行分词并提取特征,形成的检测模型能更全面地检测XSS攻击。
2 基于HMM的反射型XSS检测器设计
HMM是一种应用广泛的机器学习技术,它提供一种基于数据训练的概率识别系统,借助于现有模型训练和评估算法,能够良好地应用于模式识别领域。HMM已成功地应用于语音识别、文本抽取和入侵检测等领域,笔者正是利用具有良好的文本数据处理能力,结合反射型XSS攻击的样本特征,对攻击样本进行特征提取加入HMM模型训练,生成基于HMM的反射型XSS检测器。
2.1 反射型XSS检测方案设计
基于HMM的反射型XSS检测器设计主要分为HMM模型训练和HMM模型验证两个部分,如图1所示。HMM模型训练阶段的目的是生成HMM攻击检测模型,模型训练中最重要的一部分是观察序列的生成,观察序列由反射型XSS攻击训练样本经过处理得到,先进行数据清洗,然后进行词汇分割并对每部分进行词集编码,编码之后进行序列化作为HMM模型的观察序列,用观察序列训练HMM检测模型。模型验证部分是用训练得到的HMM检测模型对测试样本进行评估,以验证模型的识别效果。

图1 HMM检测系统结构图Fig.1 HMM detection system structure chart
2.2 特征选择与提取
2.2.1 数据清洗
模型训练需要先将攻击载荷进行序列化作为观察序列,而反射型XSS攻击载荷中包含有函数体、攻击关键词等,攻击载荷的元素较多,在特征提取之前需要进行样本数据处理。在样本处理时应先进行数据清洗,数据清洗应先剔除掉样本中非关键因素。一个完整的URL请求包括协议、域名、端口、虚拟目录、文件名和参数,实际上XSS攻击样本和正常样本的区别主要在于虚拟目录、文件名和参数等部分,因此只需保留虚拟目录、文件名和参数。
由于部分攻击载荷为了躲避检测进行了编码,主要有HTML编码和URL编码,因此在词法分割之前需要进行相应的解码。以攻击载荷%3Cscript%3Ealert%28/42873/%29%3C/script%3E为例,这段字符串进行了URL编码,需要将其解码为。
为了减少特征空间,剔除掉非关键元素之后需要将参数的某些部分范化,主要包括参数中的超链接和数字,将超链接范化为"http://u"的形式,将所有数字范化为数字0,将超链接和数字范化对攻击样本的特征提取没有影响。将正常样本和反射型XSS攻击样本分别进行数据清洗,得到两种数据清洗后的样本。
1) 数据清洗后的正常样本为
/qte_web.php?qte_web_path=@rfiurl?qte_web_path=@rfiurl?
/environment.php?dir_prefix=http://u?
/examples/jsp/jsp0/jspx/infosrch.cgi?cmd=getdoc&db=man&fname=|/bin/id
2) 反射型XSS攻击样本为
/0_0/api.php?op=map&maptype=0&city=test
/mobile/goods_list.php?type=1&sonmouse-over=alert(/0/)
/include/dialog/templets.php?adminDir-Hand="/>
2.2.2 词汇分割与编码
样本数据清洗之后需要进行词汇分割,词汇分割有词集模型和词袋模型两种,词集模型规定每个词汇只能存在出现或者不出现两种形式,而词袋模型规定出现0 次或多次,并统计每个词汇出现次数。对于本模型,不需要统计其次数,只需要判断词汇的有无,因此选用词集模型即可。
1) 第三方链接:有相当部分攻击样本中含有第三方域名作为攻击者服务器,其作用是接收并存储盗取的客户端信息,第三方链接作为一个独立的部分,明显区别于URL中其他部分,因此http/https需要单独作为一类词汇。
2) 属性标签:反射型XSS攻击需要在URL中执行JavaScript攻击代码,常见的onload属性就是负责在页面加载执行一段代码,例如onload="alert(′XSS′)就代表执行alert函数。Onerror属性是负责在错误发生时执行一段代码,当然还有其他属性。属性标签的特征是属性加等号的形式。
3) JavaScript函数:反射型XSS会调用一些危险函数完成攻击,例如alert( )函数常用于弹出对话框并显示参数里的内容,使用弹窗本身没有问题,但是如果攻击者借助document属性,例如alert(document.cookie),就能够盗取客户端cookie,类似的函数还有很多,将这些JavaScript函数分为一类词汇。
4) < >标签:< >标签主要有等。< >以及其里面的内容作为一个整体划分为一类词汇。
5) 单双引号:以alert('XSS')和alert("XSS")为例,前者是用单引号中包含攻击代码,后者是用双引号包含攻击代码,单双引号一般用于将函数参数或属性值包含在内,以区别于其他字符。
6) <和>:<和>是2 个标签,不同于完整的< >标签,两者中左尖括号代表标签开头,右尖括号代表结尾。例如
(41)世祿權臣不信,非毀玄帝降言誠訓。(《太上說玄天大聖真武本傳神呪妙經註》卷六,《中华道藏》30/579)
具体词汇分割规则如表1所示,在词汇分割之后需要进行编码,按照词汇分割规则,对被分割的词汇依次进行编码,每个词汇都有一一对应的编码,然后序列化作为观察序列进行输入,进行HMM模型训练。

表1 词汇分割规则表Table 1 Table of vocabulary segmentation rules
2.3 HMM模型训练与模型验证
HMM包含两层:观察层和隐藏层。观察层是待识别的观察序列,隐藏层是一个马尔可夫过程。
HMM将一个随机过程称作一系列状态的转移,状态集为S={s1,s2,…sN},t时刻的状态用qt表示,并满足qt∈S={s1,s2,…sN},状态能被观察到的叫作观察值,表示为ot,ot是观察集合V={v1,v2,…vM}的一种。
2.3.1HMM参数
HMM参数[10]由3 部分组成:
1) 转移概率矩阵A为
式中aij为从状态si转移到sj的转移概率。
2) 观察概率矩阵B为
式中bjk为在状态sj下产生vk的概率。
3) 初始状态概率π为
π={πi=P(q1=si)},1≤i≤j
式中πi为第1 个状态q1取si的概率。
因此可以用参数λ=(N,M,A,B,π)来表示HMM。HMM主要解决3 个问题:评估问题、解码问题和学习问题,本模型使用到评估问题和学习问题。


图2 HMM模型训练过程图Fig.2 HMM model detection flow chart
2.3.2 训练过程
HMM具体训练过程如下:
1) 将反射型XSS训练样本进行数据清洗后,提取词集并序列化生成观察序列O={o1,o2,…oT}。
2) 使用前向 - 后向算法计算观察序列概率P(o|λ)。
3) 使用Baum-Welch算法对模型参数A,B,π重估计。
HMM模型验证需要解决的问题:将测试样本提取词集并序列化,作为观察序列O={o1,o2,…,oT},已知HMM模型参数λ=(N,M,A,B,π),求模型产生观察序列的概率P(o|λ),属于HMM评估问题的范畴,将得到的概率值取自然对数Ln(P(o|λ))并与阈值比较,比阈值小的为攻击样本,比阈值大的为正常样本。
3 实验与结果分析
实验环境包括操作系统64 位Ubuntu 16.04,处理器英特尔酷睿i5 2467M,内存8 G,编程语言Python 3.5,预装机器学习模块HMMLearn。
训练环节,反射型XSS攻击样本从漏洞提交网站exploit-db和XSS漏洞提交网站XSSed中获取,挑选1 000 个典型的反射型XSS样本作为训练样本,经过词集模型处理后加入HMM模型训练,形成HMM检测模型,对攻击样本观察序列概率值取自然对数,将最大值作为本模型的阈值。
验证环节分两个实验,实验1选取500 个反射型XSS样本和500 个正常请求样本,其中正常请求样本从Web服务器日志中获取,规定反射型XSS样本为正样本,正常请求样本为负样本。为了全面评价HMM检测模型的效果,本实验引入准确率、误报率和漏报率等3 个评价指标[12]。
准确率表示分类的准确度,即
(1)
式中:FN为被错误判定为负样本的正样本的数量;FP为被错误判定为正样本的负样本数量;TN为被正确判定为负样本的负样本数量;TP为被正确判定为正样本的正样本数量。
误报率表示错判为正的负样本占总的负样本的比例,即
(2)
漏报率表示错判为负的正样本占总的正样本的比例,即
(3)
将500 个反射型XSS样本和500 个正常请求样本作为测试样本进行模型验证,计算观测序列概率值取自然对数Ln(P(o|λ)),为了直观表示两种样本的输出值Ln(P(o|λ))的分布区间,各取前50 个样本绘制HMM模型检测图,图3显示了两种样本经过HMM模型计算的输出值Ln(P(o|λ)),正常样本输出值大多数在0~30,而反射型XSS样本的输出值普遍高于这个区间,初步证明检测模型具有良好的检测能力。
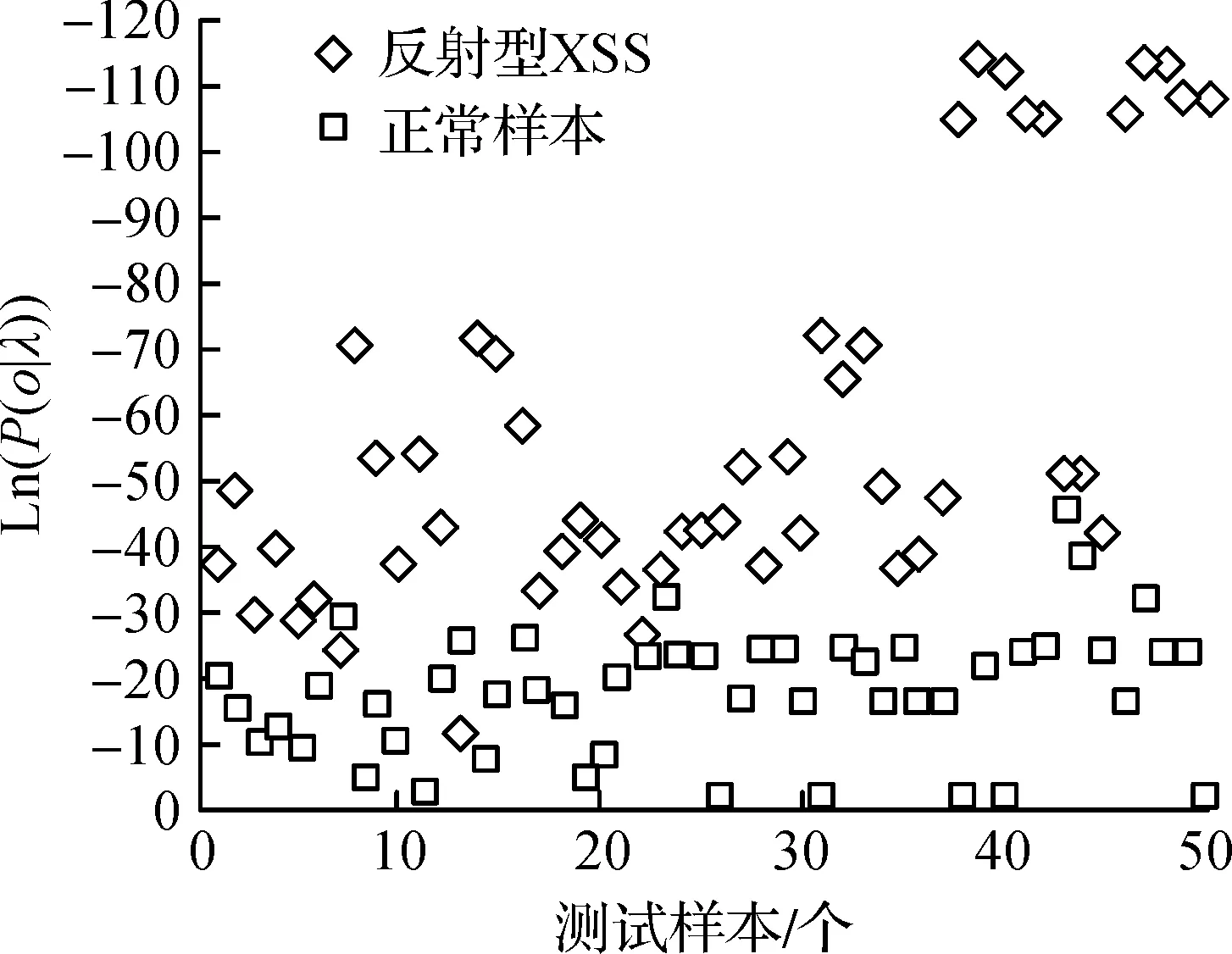
图3 HMM检测图Fig.3 HMM detection chart
将训练样本加入模型计算,取输出概率的自然对数中最大值作为HMM检测模型的阈值,基于此阈值的检测效果如表2所示。

表2 HMM检测模型的检测数据Table 2 Detection data of HMM
WebKit内核集成有XSS-filter,而Chrome浏览器正是基于WebKit内核开发,Chrome浏览器中的XSS-filter也被称为Chrome XSS-filter,这是一种典型的基于规则的XSS检测器。为了对照,将同样的攻击样本和正常样本作为Chrome XSS-filter的测试样本,测试结果如图4所示,HMM检测模型的准确率比Chrome XSS-filter要高,这代表着本模型对攻击样本和正常样本的整体判别能力较强。尽管本模型的误报率较低,但是改善幅度不大,这是因为正常样本的构造较为简单,基于规则的XSS-filter对于正常样本的识别也有较高的能力。本模型漏报率的提升效果比较明显,这是因为XSS-filter难以识别变形的或者复杂的反射型XSS攻击,而本模型使用了词集模型,从反射型XSS攻击的整体结构进行特征提取,比XSS-filter黑名单模式更具有针对性。

图4 2 种检测器的准确率、误报率和漏报率比较Fig.4 Comparison of the accuracy false alarm rate and missed alarm rate of two detectors
实验2验证本模型对变形反射型XSS的检测效果,选取100 个变形反射型XSS攻击样本,变形反射型XSS包含编码、大小写混淆等多种变形方式,作为对照,使用Chrome XSS-filter检测同样的变形样本,统计两种检测器的有效检测数,实验结果如图5所示。本模型对变形反射型XSS的有效检测数远远多于Chrome XSS-filter,这是因为Chrome XSS-filter的黑名单机制难以检测出不在黑名单中的变形反射型XSS,而本模型对样本词法分割需要基于攻击样本的整体结构,将变形的反射型XSS也加入特征提取之中,形成的观察序列更具有代表性。
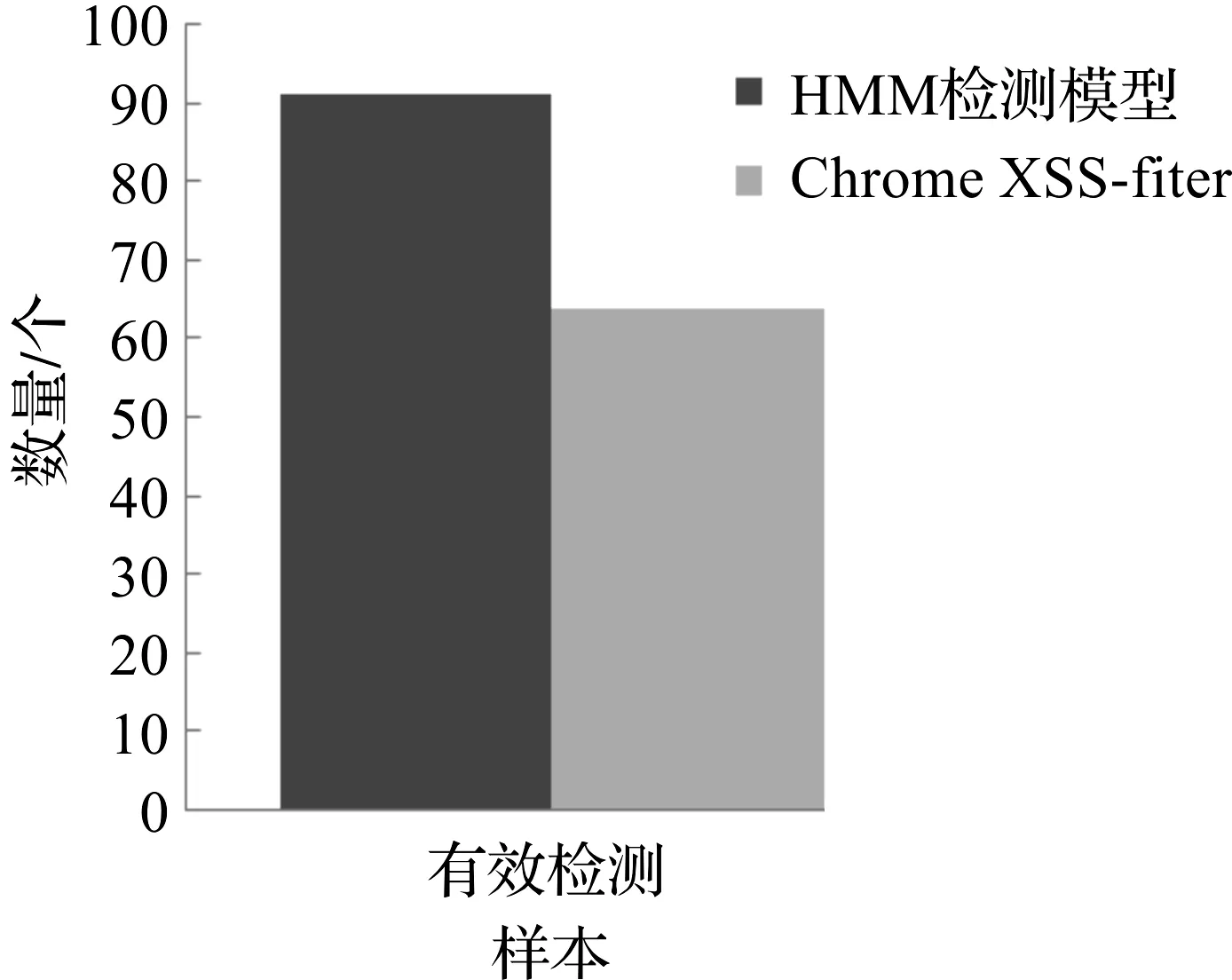
图5 变形反射型XSS检测效果比较Fig.5 Comparison of detection performance of variable reflected XSS
4 结 论
传统的基于规则的XSS检测器难以防御变形的和未知的反射型XSS攻击,因此提出使用HMM用于反射型XSS攻击检测,运用词集模型对样本进行处理,将攻击样本和正常样本进行词汇分割并序列化作为观察序列,经过HMM训练和测试,达到了良好的准确率、误报率和漏报率,验证了HMM在反射型XSS攻击检测领域的可行性。将包含变形的反射型XSS攻击的训练样本加入特征提取,生成的HMM检测模型对于变形的反射型XSS检测效果比Chrome XSS-filter更好。相对于基于规则的XSS检测器,HMM检测器对反射型XSS攻击样本的识别能力更强。实验后续需要完善的地方是将最新的变形XSS攻击样本加入特征提取之中,以进一步提高HMM检测模型的性能。
