基于兴趣度与类型因子的高校图书推荐算法
2019-06-11
(浙江工业大学 计算机科学与技术学院,浙江 杭州 310023)
随着信息化的飞速发展,数字图书馆的快速建设,高校图书馆存储了大量学生读者的行为数据,如何有效利用这些数据挖掘出有价值的信息成为了研究的重要方向。于此同时,个性化推荐在网络生活中的作用越来越明显,准确、高效的推荐系统可以挖掘用户潜在的消费倾向。高校图书馆个性化推荐是将高校图书馆大数据与个性化推荐结合的最好案列。
当前主流的核心推荐算法[1-4]有:1) 基于内容的推荐算法,它根据用户过去喜欢的产品,为用户推荐和他过去喜欢的产品相似的产品;2) 基于关联规则的推荐算法,同一用户借阅的不同图书可以认为之间有着关联关系,从借阅信息中搜索关联度最高的图书集合可以作为图书推荐的重要参考,李默等提出了一种基于标签和关联规则挖掘的图书组合推荐模型[5];3) 基于协同过滤的算法,基于用户的协同过滤与项目无关,它寻找当前用户最相似的邻近用户,推荐邻近用户借阅的图书给当前用户。黄太波等在数据量不同的情况下对不同的协同过滤算法进行了对比[6];何佶星等提出了一种基于项目评分系统的流行度划分结合平均偏好权重的协同过滤推荐算法[7];此外,王鹏等还提出了一种基于社会网络的图书推荐算法[8]。
1 问题定义和相关工作
高校图书馆的图书数量远大于学生数量,所以使用基于内容的推荐算法或者基于内容的协同过滤算法计算量太大,并不适用[9]。而基于用户的协同过滤算法适合用户比项目少(例如高校图书馆)的情况。该算法利用用户之间的相似性通过周围用户对某项目的评分来计算目标用户对该项目的评分[10]。评分矩阵[11]定义如下:用户对于项目的兴趣可以表示为1 个U×I的矩阵R,行向量表示1 个用户的评分集合,列向量表示1 个项目的被评分集合。4 个用户与4 个项目的评分矩阵为
(1)
然而,目前高校图书馆普遍缺乏为读者提供评分的渠道。文献[12]使用借阅持续时间这个特征作为兴趣度,文献[13]在其基础上增加了图书的大众受欢迎度的特征,但上述论文只是将特征直接使用,没有作归一化处理,导致结果偏差较大。笔者在两者基础上增加了续借次数作为兴趣度模型的一部分,并做了归一化处理。
高校图书馆图书数量太大,导致读者与图书能产生关系的矩阵非常稀疏。聚类是缓解矩阵稀疏的方法之一[14-15],文献[16]提出使用混合协同过滤的方法来解决矩阵稀疏的问题。该方法是在用户协同过滤的基础上,再使用基于项目的协同过滤来加权得到缺失的评分。在图书借阅信息中,只能通过有限的信息来取得图书之间的相似性权重,笔者提出使用中图分类号计算出的类型因子作为加权的权重。
所以笔者提出了基于兴趣度模型与类型因子的高校图书推荐算法,它是一种在不改变现有高校图书馆系统的结构,完全基于借阅记录的推荐算法。
2 算法描述
2.1 特征提取与最邻近搜索
协同过滤需要选择具有用户相关性的特征计算用户之间的相似性。笔者使用读者对不同类型图书的借阅频次u(i)作为读者的特征,特征向量U=(u(1),u(2),…,u(n)),其中n为图书类型的数量。
k邻近搜索是1 个在尺度空间中寻找最近点的优化问题。先选定1 个样本,通过计算与样本的距离,获得与目标节点距离最近的k个邻居。使用U作为用户特征。由于余弦相似能很好的反映读者在各个图书类型上的借阅比例,即用户的借阅偏好的相似性,所以使用余弦相似来计算用户之间的相似度为
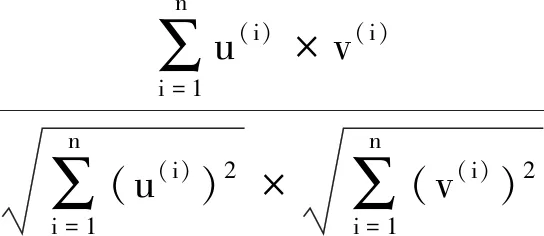
(2)
将与目标读者的距离最小的k个近邻读者组成1 个读者集合,用Uk表示。
2.2 归一化的读者兴趣度模型
提出使用读者对某本图书的借阅时长,该图书的受大众欢迎度以及续借次数3 个维度的特征来构建兴趣度模型。
2.2.1 借阅时长
读者对1 本图书借阅时间越长说明其对该图书越感兴趣。计算1 条借阅记录的借阅时长百分比为
(3)
式中:Tr(u,i) 为读者u返还图书i的时间;Tb(u,i) 为读者u借阅图书i的时间;Tc为图书馆的超期临界值。如果某条借阅数据超期,很有可能是学生忘记了归还读书,或借阅时间处于寒暑假,学生无法及时归还图书,应该把这条数据作为噪声数据删除。然后将百分比映射为1~5的兴趣度值,即
(4)
2.2.2 图书受欢迎度
可以认为在图书馆中被借阅次数越多的图书,读者感兴趣的程度会越高。以图书被借阅的次数t划分图书的受欢迎度,以图书被借阅次数的最大值max为基准将图书划分为5 个级别,分别赋予1~5的兴趣度值,即
(5)
2.2.3 续借次数
只有读者在对图书非常感兴趣的时候,才会对图书进行续借,否则即使在临界时间内还未看完也会将图书归还,由于续借次数tr对兴趣度影响较大,所以将该因素的分值设置的相对较高,即
(6)
最终以3 个分量的平均值作为读者u对图书i的综合兴趣度值,即
like(u,i)=[like1(u,i)+like2(u,i)+
like3(u,i)]/3
(7)
2.3 加入类型因子的兴趣度计算
2.3.1 图书类型因子计算
根据中国图书馆图书分类法,每一本图书都有自己的图书编号,该编号是一串字符串序列S1S2…Sk…Slength,包括英文字母和数字,每1 个字符表示1 个类别,左边的字符表示大的分类,右边的字符表示小的分类。
两本图书之间的类型因子factor(i,j)为
(8)
式中:length为图书编号的总位数;k为图书i和图书j编号中最后一个相同字符的位置下标。
2.3.2 补全兴趣度矩阵中的数据
由于兴趣度矩阵的稀疏性,通过计算近邻读者对已借图书的兴趣度进行类型因子加权得到兴趣度矩阵中缺失的数据,即
(9)
式中:v为目标读者的近邻读者,v∈Uk;B(v) 为近邻用户v的图书借阅集合。
2.3.3 协同过滤计算
将兴趣度矩阵中的数据补全以后,接下来就可以使用协同过滤来计算目标用户对目标图书的推荐度like(u,i),即
(10)
式中sim(u,v) 为由式(2)计算出的读者u与读者v之间的余弦相似度。根据运算结果,可以将预测出的目标读者u对图书兴趣度进行排名,得到1 个top-N的推荐集合。
3 算法流程
算法基于兴趣度模型与类型因子的协同过滤算法
输入目标读者u,用户借阅记录(包含账号,借阅图书的中图编号、图书类别,借阅时间Tr和归还时间Tb),图书超期临界值Tc,近邻数k,推荐个数N。
输出Top-N的图书推荐列表
1) 统计读者的借阅图书类别频次向量U。
2) 使用式(2)余弦相似公式得到与目标读者u最相似的k个近邻读者。
3) 使用式(7)计算所有近邻读者v对目标图书i的兴趣度like(v,i)。若v与i不存在借阅关系,则执行4);若存在借阅关系,执行5)。
4) 使用式(8)计算图书之间的类型因子,并使用式(9)补全评分矩阵中的缺失值。
5) 使用式(10)计算u对未借图书i的兴趣度like(u,i)。
6) 得到所有推荐图书的预测兴趣度最大的N个读者。
4 实验对比
4.1 实验评价标准
由于高校图书借阅数据兴趣度矩阵稀疏的特点,并且通过数据计算发现近邻集合中被借阅多次的图书只占所有图书的3%,所以难以使用推荐命中率和查全率去评判算法的推荐效果。因此,选择使用平均绝对误差MAE来衡量算法的效果。MAE是最常用的一种衡量推荐算法效果的标准[17],它是推荐集合与测试集合的评分差值,即
(11)

4.2 实验环境与数据预处理
实验环境为Intel(R) Core(TM)i7-4712MQ CPU @2.30 GHz,内存8 G,500 G硬盘,操作系统为Windows 8,算法使用Java编写。使用的数据来自浙江某高校图书馆2010年至2011年的借阅数据记录,数据库为mysql,涵盖18 个学院,22 个图书类型,借阅记录543 958条。借阅记录数据包括自增字段、用户编号、用户名称、用户性别、学院编号、学院名称、操作类型、操作时间、中图分类号、图书名称、图书类型、图书作者、图书出版社、图书出版年份和isbn编号等15 个维度。
实验剔除了部分字段缺失的借阅记录和重复记录。经过对每位用户在不同类型图书上的借阅频次的统计可以构建1 张新的数据表。由于图书有22 个类别,所以新表的数据一共有22 个维度。表1是从数据表中截取的一部分学生的图书借阅频次,从表1可以明显发现不同学院的学生借阅图书的类型分布差异非常明显。

表1 用户借阅频次统计表Table 1 User borrowing frequency
接着将表1的用户进行最近邻搜索。表2是当近邻数k=5 个时,其中2 位读者的近邻用户及用户相似度。

表2 读者近邻用户表Table 2 Reader’s close neighbor user
4.3 实验设置与结果分析
4.3.1 不同近邻数k和不同推荐数N下的MEA比较
实验设置:为了对比算法在不同近邻数k和不同推荐个数N环境下的推荐效果,使用1 000 名读者的借阅记录作为实验样本数据进行推荐,得到的实验结果如图1所示。
实验分析:在推荐系统实践当中,选取近邻数k的值是非常关键的,如果k值太小则推荐效率不高,如果k值太大,则会增大算法运行负担。从实验结果可以看出:当近邻数从10 个增加到50 个时,推荐效果明显增强。这是因为当近邻数很少时,能推荐的书目也很少,没有包含目标读者喜欢的大部分图书。当近邻数k达到60 个的时候,推荐效率不再有明显的提升。这是因为当近邻数达到一定数量后,推荐的图书中几乎包含了目标用户所有感兴趣的图书。
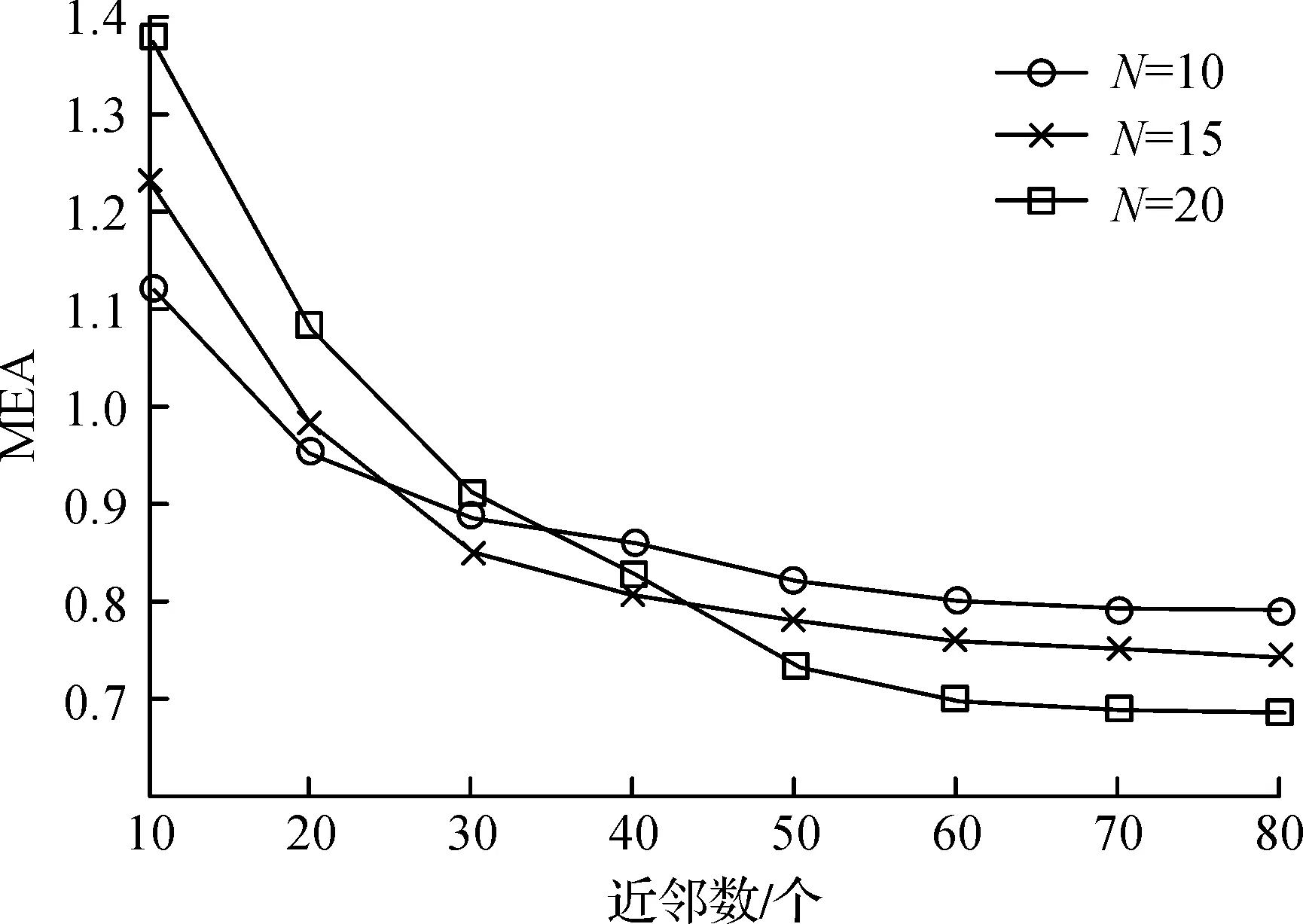
图1 不同近邻数k与不同推荐数N下的MEAFig.1 The MEA of different nearest neighbors k and the different recommended number N
还可以发现当近邻数比较少时,推荐个数越少效果越好,这是因为此时能推荐的书目比较少,包含目标用户喜欢的书也少,所以推荐的图书越多,反而将用户不喜欢的图书推荐了出去。当近邻数比较多时则推荐个数越多效果越好,这是因为此时能推荐的书目多,推荐列表中包含目标用户喜欢的书也多。
4.3.2 与其他两种兴趣度模型的MEA比较
实验设置:为了证明笔者提出的基于3 种因素建立的三维兴趣度模型的推荐效果比文献[11]中的一维兴趣度模型和文献[12]中的二维兴趣度模型的效果更好,首先将其他两种模型都进行归一化处理,否则无法比较。在不同近邻数k参数下进行了实验。设置推荐个数N为30,样本读者数量为1 000 人。实验结果如图2所示。

图2 不同兴趣度模型的MEAFig.2 The MEA of different interest models
实验分析:从实验结果可以看出,一维和二维兴趣度模型的MEA相差不大,笔者提出的改进过的三维兴趣度模型比其他两种兴趣度模型的推荐效果更好。这是因为续借次数是最能反映读者喜好的一个因素,比其他两种因素对用户兴趣度的反映更明显。
4.3.3 中图类型因子与书名分词的MEA比较
实验设置:为了比较书名分词之后相同词语词频的图书权重和中图号类型因子的图书权重的推荐效果,本实验使用Stanford的NLPCORE分词库进行分词,并在不同近邻数k的参数下进行了比较。设置推荐个数N为30,读者数量1 000 人。实验结果如图3所示。

图3 类型因子与书名分词权重的MEAFig.3 The MEA of the weight of the type factor and segmentation of book name
实验分析:从实验结果来看,基于类型因子的权重比基于书名分词权重的推荐效果要好。这是因为若按图书书名分词并统计相同词频的次数作为相似度会产生一定的问题,例如《人月神话》是一本软件工程方面的图书,按书名来分可能会被归到神话小说的类别。而笔者提出的中图分类号类型因子,它不仅可以反映图书类型等显性信息,还能反映出书架位置、是否属于同一丛书等隐性信息的相似性。当近邻数在20 个以内时,由于得到的待推荐图书列表重合率较低,所以MEA值相差较大。当聚类数达到50 个以上后,得到的待推荐图书集合重合率开始变高,所以MEA值相差变小。
5 结 论
提出了一种基于兴趣度模型与类型因子的高校图书推荐算法。该算法的创新之处在于建立了一种三维的兴趣度模型来表示,解决了高校图书推荐因为缺乏评分而无法使用协同过滤算法的问题,并且使用类型因子解决借阅关系稀疏的问题。实验表明:笔者所提算法在高校图书馆应用中有一定的推荐效果和实用价值。之后的研究可以在笔者所提的兴趣度模型之上找到一种更能精确表达读者兴趣度的方法,使推荐效果更好。
