汉语内层最长名词短语的识别研究
2019-06-10钱小飞
钱小飞
(上海大学 文学院,上海200444)
一、引言
汉语信息处理领域所关注的名词短语主要包括基本名词短语和最长名词短语。 基本名词短语内部结构相对简单,其识别(赵军、黄昌宁 1999b;徐艳华 2008)和分析(赵军、黄昌宁 1999a;张瑞霞、张蕾 2004)研究都取得了较好的效果。 最长名词短语内部结构复杂,20 世纪90 年代以及2000 年的研究主要集中在识别上(Chen&Chen 1994;李文捷等 1995;周强等 2000),之后,统计机器学习方法的应用使得最长名词短语识别的效果得到了很大提升(Baiet al. 2006;冯冲等 2006;代翠等 2008;鉴萍、宗成庆 2009;Zhanget al. 2010)。然而,针对汉语最长名词短语内部结构的分析研究还不多见。代翠(2009:42)使用条件随机场(Conditional Random Field,简称 CRF)模型对汉语最长名词短语作了完全分析,取得了75.6%的分析正确率,但分析和评测都没有针对名词性成分,而名词性成分是揭示句法语义结构的重要内容,也是句法分析的难点。
汉语内层最长名词短语(inner Maximal Noun Phrase,简称 iMNP)识别的目标是在标注了表层最长名词短语(surface Maximal Noun Phrase, 简称 sMNP)的句子中,分析出其内部多层次的最长名词性成分,即位于最长名词短语之中,而又不直接被名词短语包含的名词性成分(钱小飞、侯敏 2017: 131),如例(1)中的“艺术/n”:
(1) {艺术/n 对象/n}创造/v 出/vB{懂得/v[艺术/n]和/c 能够/vM 欣赏/v[艺术/n]的/u 大众/n}。 /。①本文例句(包括其中词性标记)均来自于清华汉语树库。为了便于读者区分内层和表层最长名词短语,笔者使用{ }标识表层最长名词短语,使用[ ]标识内层最长名词短语。
由于 iMNP 数量相对较少,边界成分的邻接概率较低,本文采用 CRF 模型和基本名词块提升规则相结合的 iMNP 识别方法,以缓解数据稀疏、结构歧义和边界歧义等问题,改善识别效果。
二、iMNP 的层级分布
由于汉语名词短语构造复杂,iMNP 呈现出多层级分布。 例如,最长名词短语“{贯彻/v 落实/v[ 1邓小平/nP 同志/n 关于/p [ 2 建设/v [ 3 有/v [ 4 中国/nS 特色/n ] 的/u 社会主义/n ] 的/u 思想/n ] 和/c十四大/nR 精神/n ] 方面/n}”,其中的阿拉伯数字标识了 iMNP 的不同层次。 根据对清华汉语树库(Tsinghua Chinese Treebank,简称TCT)的统计,iMNP 共计28065 例,分布在四个不同的层次上。
iMNP 具有明显的层级分布倾向性,分布在第一层的iMNP 占95.22%;分布在第二层的 iMNP占4.64%;分布在第三、四层的iMNP 数量很少,所占比例分别为0.14%和0.01%(钱小飞、侯敏2017:132)。 因此,第一、二层尤其是第一层是 iMNP 识别的重点。
分布在第一层的 iMNP 主要由含“的”名词短语引入。 而分布在第二、三、四层的 iMNP 不仅可由含“的”名词短语内嵌主谓、动宾或介宾等结构构造而成,同时主谓、动宾结构直接作定语也是一种重要嵌套因素。
复杂短语及其变体参与构造最长名词短语可使得结构嵌套更深,如例(2):
(2){上海/nS}在/p{贯彻/v 落实/v[邓小平/nP 同志/n 关于/p[建设/v[有/v[中国/nS 特色/n]的/u 社会主义/n]的/u 思想/n]和/c 十四大/nR 精神/n]方面/n}很/dD 积极/a,/,很/dD 认真/a,/,很/dD 有/v{成效/n},/,
当然,一些括号、引号等标点符号以及并列结构参与构造最长名词短语,也容易使得结构复杂化,从而形成深度嵌套。
三、iMNP 识别的难点与策略
(一)识别难点
尽管 iMNP 识别具备一些有利条件,比如其平均长度(2.21 词)比 sMNP(3.03 词)小(钱小飞、侯敏2017:132), 同时还具有非常明显的左邻接词类特征, 大多数 iMNP 分布在动词和介词之后, 但是 iMNP 识别也有其自身的难点。 现择要例举如下:
第一,数据相对稀疏。相较于 sMNP,iMNP 的数量较少,位于深层次(第二、三、四层)的数据尤为稀缺,这增加了统计机器学习方法和实例性规则应用的难度。
第二,iMNP 呈现多层级结构,如何选择合适的分析策略是一个重要问题。
第三,从某一层的结构来看,iMNP 的边界歧义主要表现为左边界处的动词介词内含型歧义、名词边界歧义和量名边界歧义。
具体而言,第三个难点又包括多种情形,现例举其中五种:
1)名词性成分+动词性成分+De+中心语
动词介词内含型歧义。常见结构是名词性成分作动词性成分的主语,形成主谓结构作定语。然而,名词性成分也可以作为其后定中结构的修饰语,如“厂房/n 高耸/v 的/u 烟囱/n”。
2)代词+名词短语+方位词+[谓语]②此处[ ]表示其中成分可出现也可不出现。+De+中心语
名词边界歧义。 代词和名词短语之间形成连续的名词边界歧义,如“这/rN [ 实际/n ] 上/f 虚无缥缈/iV 的/u 海市/n”。
3)代词+主语+谓语+De+中心语
名词边界歧义。 代词和主语之间形成连续的名词边界歧义,如“那些/rN [ 品质/n ] 低劣/a 的/u 药材/n”。
4)量词+名词短语+ 方位词+ [谓语]②+ De + 中心语
量名边界歧义。 量词和名词短语之间形成连续的量名边界歧义,如“一/m 颗/qN [ 药典/n ] 上/f 没有/v 的/u 定心丸/n”。
5)量词+ 主语+ 谓语+ De + 中心语
量名边界歧义。 量词在 sMNP 中一般不充当左邻接词, 但在iMNP 中这种歧义现象较为常见,如“一/m 杯/n [ 香味/n ] 浓郁/a 的/u 雀巢/nR 咖啡/n”。
上述歧义类型大都是谓词性结构嵌入名词短语所形成的线性表现,与关于谓词性成分是构造复杂最长名词短语的重要因素的论断一致。 相较于 sMNP,iMNP 虽然也存在连续的动词或介词边界歧义,但是比例较低。
(二)识别策略
识别策略的确定需要着重考虑以下两个方面的问题:一是如何识别多层级结构;二是如何降低数据稀疏、结构歧义和边界歧义可能造成的影响。
多层级结构的识别有两种策略可供选择:第一种是不分层识别,一次性识别所有的边界位置;第二种是分层识别,由上至下逐一识别每一层的iMNP。 我们选择分层识别策略,理由如下:
其一,不分层识别主要存在两个局限性:一是不能保证左右边界数量相同,识别完成后需要对左右边界重新匹配;二是iMNP 也存在边界重叠的现象,比如“是/vC 在/p [ [ 通货膨胀/n ] 长期/d 威胁/v的/u 背景/n ] 下/f 发展/v 起来/vB 的/u”。 不分层识别通常只能识别边界位置,而不能确定一个边界位置上的边界数量。
其二,iMNP 的多层级结构呈现明显的倾向性分布特征,分布在第一层的iMNP 达到95.22%,因此 iMNP 的识别效果基本取决于第一层结构的识别效果。 在某种意义上,这对于解决多层级识别中的数据稀疏问题是一个有利条件。如果能够找到其他方式对深层结构的数据进行补充,即可通过多层级的方式完成 iMNP 的识别。
我们发现,iMNP 与基本名词块③基本名词块是基本块(Base Chunk)中的名词块,包括双词或多词构造的基本名词短语和单个名词实现的基本块。有着较好的映射关系,在 TCT 中,约82%的 iMNP 由基本名词块直接实现,而基本名词块可以在整个句子范围内,而非上一层 iMNP 范围内进行训练,数据量较为充足。 因此,借助对基本名词块映射为 iMNP 条件的判断,可以召回部分漏识的 iMNP,并取消部分错误识别的 iMNP 的资格。
四、多层级 iMNP 识别
(一)系统流程
多层级 iMNP 识别的基本思路是在识别上一层 iMNP 的基础上,识别当前层次的 iMNP,直至达到规定的训练深度,或者无法发现当前层次存在目标结构为止,基本流程如图1 所示:

图1 多层级 iMNP 识别流程图
在图1 左部的训练模块中,所获取的“第i 层训练语料”并不是完整的句子,而是标注了第i 层iMNP 信息的第i-1 层iMNP。 在图1 右部的测试模块中,“更新测试语料”是指将已识别的第i 层iMNP的边界信息写入测试语料。
(二)特征及标记集
在统计机器学习模型中,支持向量机(Support Vector Machine,简称SVM)和 CRF 模型都能较好地克服数据稀疏问题。 相较于 sMNP,iMNP 长度较小,绝大部分 iMNP 的内部结构更接近于基本名词块。根据徐昉等(2007)、年洪东(2009)的研究,在基本名词短语识别上,相较于 CRF 模型,SVM 没有特别的优势。 因此,本文采用 CRF 模型④本文采用的条件随机场工具包是由日本松本实验室 Taku Kudo 博士开发的CRF++(version 0.51)。,并且为每一层结构设置独立的标记集,同时允许不同的模板设置。 分层特征选择如表1 所示:

表1 分层特征选择
表1“标记集”列中,B 表示 iMNP 的起始词位置,I 表示除起始词位置之外的位置,M 表示除起始词和结束词位置之外的中间位置,E 表示 iMNP 结束词位置,O 表示iMNP 外部,S 表示单词 iMNP。 经过调试,iMNP 识别在特征窗口[-2,2]能够取得较好效果,使用的特征包括词语和词类。
五、基于规则的修正
iMNP 总量不足sMNP 的1/6(钱小飞、侯敏 2017:132),数据稀疏、结构歧义和边界歧义可能造成错识和漏识问题。 鉴于此,我们引入规则来修正识别结果。
(一)iMNP 与基本名词块
研究基本名词块实现为 iMNP 的条件有助于将基本名词块确认为 iMNP,同时也有助于否决错误识别的 iMNP。 我们把基本名词块确认为 iMNP 的过程称作基本名词块的提升。
iMNP 与基本名词块的关系可从实现关系和层次分布两个方面进行考察。 从实现关系来看,TCT中由基本名词块直接实现的 iMNP 的比例远大于 sMNP(65%)。从层次分布来看,基本名词块可以分布于各个层次,尤其是第一层和最内层。 这使得基本名词块具备了提升为各个层次 iMNP 的可能,从而有望改善发生在各个层次上的错识和漏识问题。 请看例(3):
(3)当/p[[2 川/n]上/f 有/vJY[2 水/n ]浇/v[2 地/n ]的/u 富/a 队/n ]来/v[1 粮站/n ]卖/v[1 粮/n]的/u 时候/n
在例(3)中,第一层有两个 iMNP 与基本名词块重合,第二层有三个iMNP 与基本名词块重合。
(二)基本名词块提升规则
1.上下文提升规则
为了判断基本名词块是否可以提升为 iMNP,我们根据经验编写了由基本名词块的上下文信息组成的 74 条上下文提升规则,规则形式可以描述如下:
(4) [attrib_loc_val]+→judgement
(4)中箭头前部分表示条件;箭头后部分表示如果基本名词块符合该条件,应该执行的动作或者判断;[]+表示该规则可以有多个条件。在条件部分,attrib 表示属性,包括词形word、词类tag、词形词类wordtag 三种类型;loc 表示上下文相对于当前基本名词块的位置,值为 0 时表示 iMNP 中心词位置;val表示属性值。 在动作部分,当judgement 的值为 MT 时,表示提升该基本名词块;当 judgement 的值为 MF 时,表示否决该基本名词块。 请看(5)—(7):
(5)tag_-1_v tag_1_v →MT
(6)wordtag_-1_在/p wordtag_1_里边/f →MT
(7)tag_-1_、tag_1_c →MF
(5)表示当基本名词块前一个词和后一个词均是动词时,将该基本名词块提升为 iMNP。 (6)表示当基本名词块前一个词是介词“在”,后一个词是后置词(方位词)“里边”时,将该基本名词块提升为 iMNP。(7)表示当 iMNP(可与基本名词块重合)前一个词是顿号,后一个词是连词时,否决该基本名词块。
2.限制性规则
尽管上下文提升规则的设计较为可靠,但是仍然无法完全避免句法歧义等问题的影响。 比如,当“名词性成分+动词性成分+De+中心语”结构位于宾语位置时,上下文提升规则对于消解歧义显得力不从心,很容易将其中作修饰语的名词性成分提升为 iMNP。 因此,我们编制了一个动词配价表,收录了9955 个动词的配价信息,并利用这些信息设计了3 条限制性规则,以降低上下文提升规则的使用风险:
一是当loc_-1 位置上的动词为一价动词,或者不具有带宾语的能力时,禁止使用上下文提升规则。
二是在“名词性成分+动词性成分+De+中心语”结构中,当动词性成分为一价动词时,禁止使用上下文提升规则。
三是在“名词性成分+任意成分+De+中心语”结构中,当“任意成分”不包含动词时,禁止使用上下文提升规则。
3.结构化提升规则
因为iMNP 多由外层含De 最长名词短语所包含,所以本文所设计的5 条结构化提升规则主要针对含De 结构。 当“v bnc1De bnc2”“p bnc1De v”“v bnc1De v”结构实现为最长名词短语时,其中的bnc1都可以提升为iMNP。此外,当上层iMNP 只包含一个De,De 前只有一个动词或介词时,将位于De 前、动词或介词后的基本名词块提升为iMNP;当上层iMNP 只包含一个De,De 前只有一个介词,而没有动词和形容词时,取消介词前iMNP 的资格。
(三)识别算法
基本名词块提升在多层级iMNP 识别完成后进行,识别算法如下:
输入:多层级iMNP 识别结果、基本名词短语识别结果和基本名词块提升规则库
输出:iMNP 最终识别结果
1) 顺序扫描句子中每一个基本名词块NBCi⑤单词基本名词块在扫描过程中直接识别。
2) 如果NBCi与最长名词短语MNPj不重合且不交叠
3) 在限制性规则约束下,若匹配上下文提升规则成功,将NBCi提升为iMNP
4) 若匹配结构化提升规则成功,将NBCi提升为iMNP
5) 输出识别结果
六、实验结果及分析
(一)多层级iMNP 识别效果及分析
为了检验识别系统的性能,我们先采用随机抽样程序对TCT 语料进行了5 次随机抽样,每个样本的容量设置为2000 句。 然后,将样本集合中每4 个样本合并为训练语料,剩余1 个样本作为测试语料,构造5 组训练测试语料对,在正确标注sMNP 的基础上识别iMNP,并进行5 折交叉验证,结果如表2 所示:

表2 多层级iMNP 识别结果

续表2
实验取得了85.60%的结构正确率(ST_prc)和77.49%的结构召回率(ST_rec),结构F1 值为81.34%。我们发现,相较于数据稀疏,结构歧义和边界歧义才是造成iMNP 识别错误的深层次原因,而数据稀疏加剧了两者的影响。 识别错误包括以下几个方面:
其一,上层结构识别错误对下层结构造成不利影响,即上层结构的一个识别错误会影响到多个下层结构的识别。
其二,联合结构造成边界歧义。 iMNP 内部联合结构较多,识别错误主要包括三种情况:一是并列名词短语被错误地切开;二是包含动词性结构的短语和名词短语并列造成的识别错误,如当名词短语和主谓结构并列时,并列项和主语被错误识别为iMNP;三是动宾结构和主谓结构并列时,宾语和主语被错误识别为iMNP。
其三,“v n n”潜在歧义格式。 “v n n”作名词短语,常常被错误划分为“v [ n n ]”,主要包括两种情况:一种是较为常见的多词块,如“反/v [ 腐败/n 斗争/n ]”;另一种是特殊句法位置上的临时组合,如“那/rN 已/d 被/p 丑化/v 的/u 读/v [ 书/n 姑娘/n ]”中的“读/v [ 书/n 姑娘/n ]”。
其四,De 后主谓结构的干扰。 De 后名词短语作最长名词短语的中心语,但是诸如“一/m 门/qN 在/p[ 理论化/vN 和/c 数量化/vN 基础/n ] 上/f,/,进一步/d 综合化/v、/、生态化/v、/、社会化/v 的/u 理论/n 与/c应用/vN 并举/v 的/u 两栖/b 科学/n”的结构使De 后名词短语的归属发生了歧义。
其五,iMNP 的特殊歧义序列造成识别错误。比如,“名词性成分+动词性成分+De+中心语”的潜在歧义造成模型无法判断名词性成分什么时候应该被识别为iMNP,什么时候不应该被识别为iMNP。当然,模型无法考虑该序列的上下文特征,如左邻接动词和中心词的搭配特征,这也是造成识别错误的一个原因。
(二)基本名词块提升规则的修正效果及分析
因为基本名词块的中心词构成较为封闭,主要为名词,所以在识别基本名词短语的基础上,其外部的单个名词均可作为单词基本名词块。 鉴于此,我们首先采用CRF 分类器基于BMEO 标记集对测试语料中的基本名词短语进行预标注,取得了90.83%的结构正确率和92.63%的结构召回率,结构F1值为91.72%。
基本名词块提升实验采用自动标注了iMNP 及基本名词短语,且正确标注了sMNP 的5 份测试语料。实验采用了82 条修正规则,其中,上下文提升规则74 条,限制性规则3 条,结构化提升规则5 条。实验结果如表3 所示:

表3 修正实验结果

续表3
修正规则召回了部分漏识的简单结构,使得结构召回率提高了1.22%,结构F1 值提高了0.50%。然而,其对“m qN n v De”等名词边界歧义,“n、n v”等名词短语与动词短语联合的结构,“v n n”等动宾结构作定语,还没有辨别能力,仍然需要进一步改进。
不容忽视的是,修正规则也导致了部分识别错误,造成了结构正确率有所下降。 本文在此仅例举一种识别错误,即限制性规则仍然无法完全约束“名词性成分+动词性成分+De+中心语”结构中“名词性成分”作定语的条件,如“芬/nP 阴差阳错/iV 的/u 婚姻/n”中包含一价动词,“芬/nP”作定语而非主语,又如“范丽/nP 带/v 着/u 抽泣/v 的/u 回答/vN”中包含二价动词,“范丽/nP”也是作定语而非主语。 由于限制性规则是上下文提升规则的附属限制性条件,我们对5 份测试语料分别计算“上下文提升规则+限制性规则”和“结构化提升规则”的错误率⑥错误率=(执行规则导致的错误结构数÷执行规则的总次数)×100%。,结果如表4 所示:
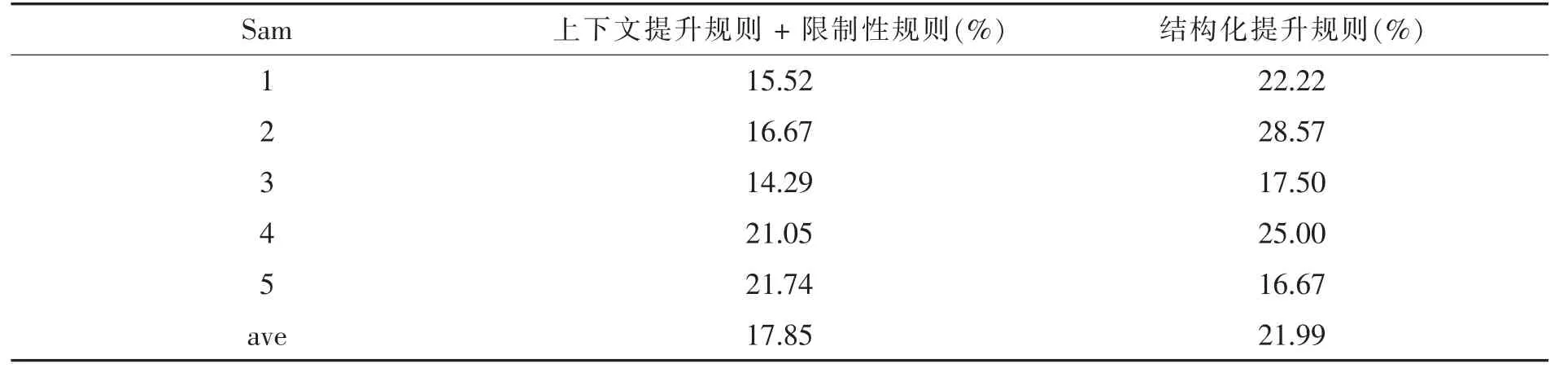
表4 修正规则的错误率
我们在实验过程中发现,内层名词性成分的结构并不像我们想象的那样简单,其内部仍然存在比较多的歧义,特别是结构歧义和名词边界歧义,加之深层结构数量比较少,导致识别错误较多。尽管基本名词块提升规则能在一定程度上提高iMNP 的识别效果,但是其并不能完全化解所有歧义,因此需要更多句法语义知识的参与。
七、结语
综上可知, 本文设计的多层级iMNP 识别系统借助CRF 模型和基本名词块提升规则, 取得了85.23%的结构正确率和78.71%的结构召回率, 可以为名词短语理解和内部语义角色标注等奠定基础。 然而,因为相较于sMNP,iMNP 的数据更为稀疏,分布具有层级性,而相较于基本名词块,iMNP 的内部结构更为复杂, 所以iMNP 的识别方法还有待进一步改进。 除了进一步提高分类器的识别正确率,如采取多分类器融合的方法提高统计机器学习方法的识别效果,还有必要在句法分析的过程中进一步引入语言学规则,如在词表中收录含v 简单组块,运用上下文无关文法(Context-Free Grammar,简称CFG)规则验证上层iMNP 的识别结果,反馈并指导下层iMNP 的识别。
感谢清华大学周强老师为本文研究提供TCT。
