一种基于FPGA的CNN加速器设计*
2019-06-10乔庐峰陈庆华
赵 彤,乔庐峰,陈庆华
(陆军工程大学 通信工程学院,江苏 南京 210007)
0 引 言
随着硬件GPU的快速发展和大数据时代的来临,深度学习迅猛发展,已席卷人工智能各个领域,包括语音识别、图像识别、视频跟踪、自然语音处理等在内的图、文、视频领域。深度学习技术突破了传统技术方法,大大提高了各领域的识别性能。应用深度学习技术到智能化移动嵌入式军事设备,将成为新一代深度学习的发展浪潮。
伴随着深度网络模型的性能增加,模型的深度越来越深,深度网络模型的高计算量和高存储弊端,严重制约着资源有限的应用环境,特别是智能化移动嵌入式设备。例如,8层的AlexNet[1]装有600 000个网络节点,6.1×107个网络参数,需要花费240 MB的内存存储、7.29×108次浮点型运算 次 数(The Number of Floating-point Operation,FLOP)来分类一副分辨率为224×224的彩色图像。随着模型深度的加深,存储和计算开销增加。同样分类一副分辨率为224×224的彩色图像,16层的VGGNet[2]装有1 500 000个网络节点,1.44×108个网络参数,需要花费528 MB的内存存储、1.5×1010次FLOP。
目前,对深度神经网络的实现多是基于通用计算机,不仅计算机体积大,还会因计算机的输入输出接口速度限制了整体速度,更限制了应用的广度与深度。另外,深度神经网络的设计者或使用者必须要对网络的工作软硬件环境有相当了解,才能将其应用在实际系统上,更限制了深度神经网络的发展。因此,若能适当采用现场可编程逻辑门阵列(Field Programmable Gate Array,FPGA)芯片的形式实现控制器,不仅可以大大缩小硬件体积,而且具有执行速度快、灵活度高的优点。目前,虽然已有一些研究[3-6]将神经网络控制器实现在FPGA芯片上,但将深度神经网络的方法实现在FPGA芯片上的研究越来越受到重视,并展现出很有希望的前景。已有研究发现,使用FPGA实现后硬件在执行速度上可将原本限制于普通计算机I/O的毫秒等级速度提高到微秒等级的快速输出,高处理速度将可使深度神经网络应用在更多需要快速反应的应用上。深度神经网络会因FPGA硬件体积较小和功耗较低提高使用者的兴趣,尤其在学习精准度上没有因为硬件化而有太大差异。此外,由于FPGA的可重复编程性,可以方便地实现算法更新和目标重定义。
1 CNN加速器的基本架构
由于目前神经网络的规模越来越大,层数也越来越深,而受限于FPGA上的存储资源,必须借助外部存储芯片,才能完成整个网络的运行。因此,本设计采用将外部DDR存储芯片与运算FPGA相结合的方式,架构如图1所示。由图1可以看出,整个硬件平台的架构由运算FPGA芯片和存储芯片DDR组成,FPGA内部由总控和运算单元(PE)组成。

图1 CNN加速器的基本架构
1.1 总控模块
总控主要负责对输入的特征图、网络的权重以及产生的中间结果进行管理,并负责各PE与外部DDR之间的通信和数据转换,结构如图2所示。
总控模块包含DDR控制器、数据接口、数据解析/打包模块以及存储中间结果的FIFO。
DDR控制器用与FPGA与外部DDR之间的通信,包含运行DDR接口协议的IP核。在满足一个突发的条件后,它将FPGA内部的数据传输到DDR或者将DDR里的数据传输到FPGA。其余部分按数据流向可以分成两部分。
第一部分,数据流从DDR到FPGA。在FPGA模块开始运行后,先将一部分特征值与网络权重值预先存储在FPGA内部。待整个系统运行起来后,在需要数据参与运算时,通过DDR控制器发送读取命令给DDR(包括读取的bank号,读取的行列号以及突发的长度)。DDR接收到命令后,将相应的数据以突发方式传输到FPGA中。由于DDR传输来的数据含有标记信息(包括该数据的特征图编号、行列号等),所以FPGA在接收到数据后,要先通过数据解析模块解析数据,再存储到相应的FIFO中,以便PE读取。

图2 总控模块的结构
第二部分,当卷积运算完成后,产生的中间结果要从FPGA内部传输到DDR。这时数据流从PE中出来,先经过数据打包模块为每个数据打上相应的标签,包括该数据的层号、特征图的编号以及行列号等信息,而后打包完的数据发送到输出FIFO进行缓存,等到满足一个突发条件后,该突发数据经由DDR控制器发送到外部DDR进行存储。
1.2 数据处理单元(PE)
对于目前最常见的网络,最多是3×3和5×5卷积核。所以,对于PE架构,有以下两种设计:图3(a)是卷积核为3×3时的PE结构,图3(b)是卷积核为5×5时的PE结构。PE中主要由存储阵列控制器、RAM阵列和乘加操作运算矩阵构成。存储阵列控制器负责对RAM阵列中的数据进行管理,控制行列号的转换和RAM阵列读写操作的控制;RAM矩阵存储相应的特征值和权重;乘加操作运算矩阵负责对输出的特征值与权重进行计算,以得到最终结果。本设计针对卷积核的不同设计不同的PE,目的是针对不同网络的结构特性调整整个设计中PE的分布,从而使性能达到最优。
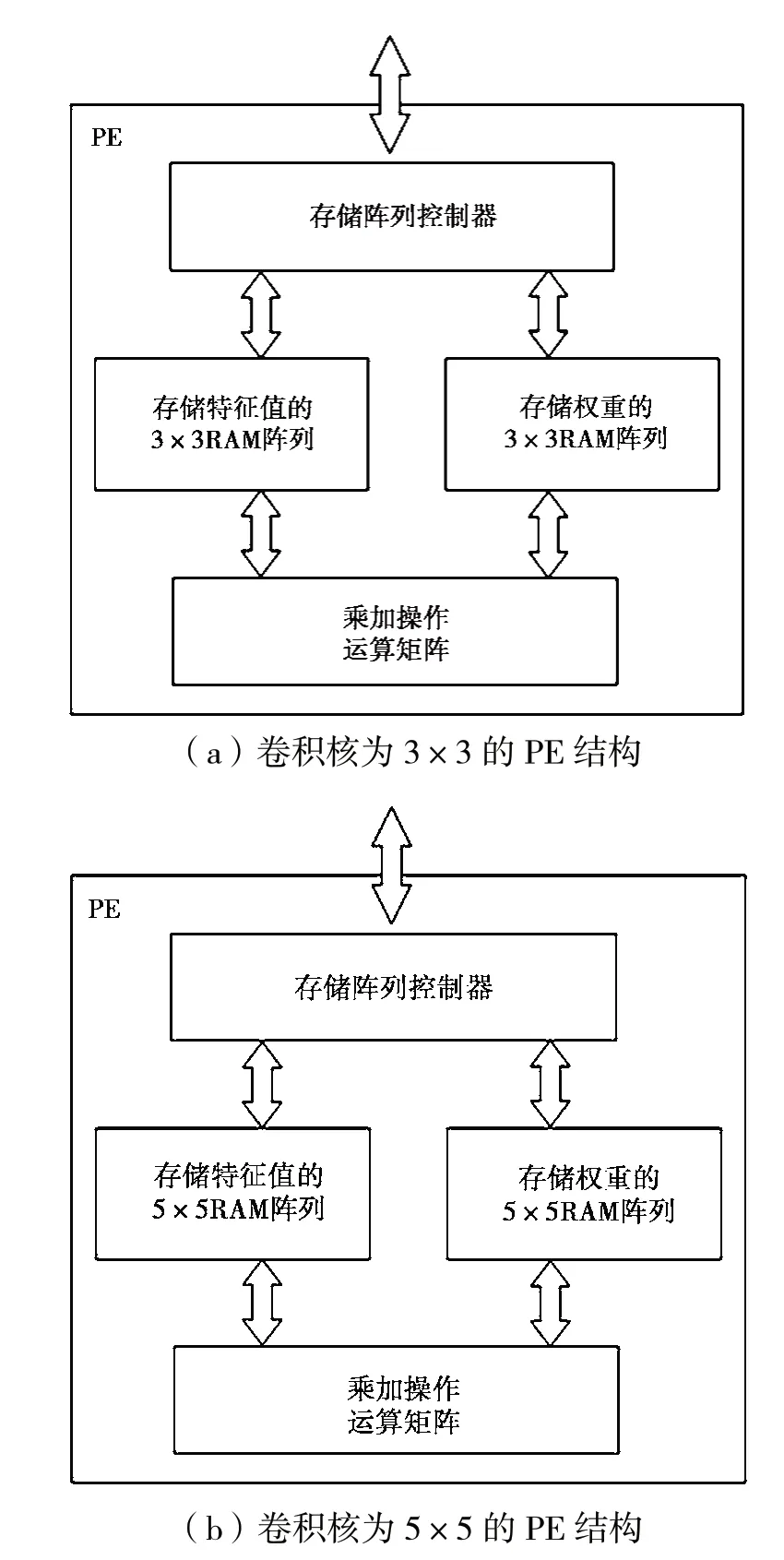
图3 数据处理单元(PE)的结构
2 存储管理
在硬件中实现多计算资源来加速CNN的推断过程,存储带宽的限制常常是处理CNN的瓶颈[7]。例如,对于卷积层来讲,大量的乘加操作必然导致大量的存储器读写。因为每个乘加操作需要至少2个 存储器读操作和1个存储器写操作,而FPGA内部存储资源的限制,必须要把大部分网络参数和中间结果存储在外部DDR上,所以会严重影响吞吐率和能量消耗,甚至比乘加运算本身的能耗还要大。
2.1 特征值及网络权重的存储
针对存储带宽的限制问题,本设计提出一种能降低对外部存储带宽需求的方案。具体地,针对目前应用最广泛的3×3卷积核,进行以下设计。对于一张224×224的特征图,采用如图4所示方式进行存储。对于一个224×224的特征图,在整个运算开始前,先将该特征图的前3行值存储到3×3的RAM阵列中。在RAM阵列中,每一行RAM只存储特征图的同一行值。这样存储便可在一拍就得到卷积结果,而不需要额外的操作。
对于CNN的参数,采用如图5所示的格式进行存储。可以看到,该层网络共有32个3×3的卷积核。本设计将这些卷积核存储到一个3×3的RAM阵列中,3×3卷积核中的每个权重值分别存储到不同的RAM中。这样权重值与特征值相对应,可以在一拍内得出计算结果。
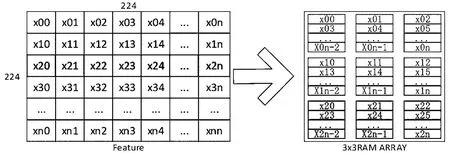
图4 特征值的存储示意

图5 权重的存储示意

对于当前存储在RAM阵列中的特征图和权重,计算完成后会得到分属于32个不同特征图的结果,这样需要用FIFO进行缓存,而后经过一次DMA突发,将属于同一个特征图的特征值送到外部DDR,以最大限度的节省带宽。
2.2 存储管理模块的设计
存储管理模块的设计流程如图6所示。
由图6可以看出,本设计运算开始后,先固定一个权重值,而后遍历特征图,以使得该部分的输出属于同一个特征图,方便对其进行存储。在当前存储权重的RAM阵列运行到最后一个值时,更新存储特征图的RAM阵列,以保证流水的不中断,也使设计的并行化达到最大。
对于每一组ram来讲,每一行的3个ram存储同一行的特征值,即需要预先将特征图的3整行分别存储到片内,而后从第四行进行更新。在对同一行进行卷积操作时,只有列号进行变化,而行号保持不变。只有在整列结束,所有的值都更新完毕后,再进行行号的变化。
当存储在RAM阵列中的权重值运行到最后一个时,开始进行特征图的更新,在此之前会将一整行特征图以DMA突发的方式传输到片内FIFO中进行存储,再从FIFO中一次取出一个特征值更新RAM阵列中的特征值,具体过程如图7所示。
由图7可以看出,在更新完特征值后,RAM阵列中的列号要进行变化,且更新过的RAM中的读指针要加1,以方便对RAM阵列操作,即对于外部接口来讲,每次只需要对列号为0、1、2的RAM进行操作,便可以读取相应的操作数。
当一整行特征值更新完毕后,要进行行号的转换,具体过程如图8所示。
由图8可以看出,一行特征值的最后一个更新完毕后,相应的RAM阵列的行号也发生变化,从而为下一次操作做准备。对于外部接口来讲,每次只需要对行号为0、1、2的RAM进行操作,便可以读取相应的操作数。
特征值的行列号与权重值的对应关系,如表1 所示。特征值与权重的对应关系是固定的,所以每次运算的操作数均严格按照卷积神经网络的运算规则,不会出现位置的不匹配而导致错误的 结果。
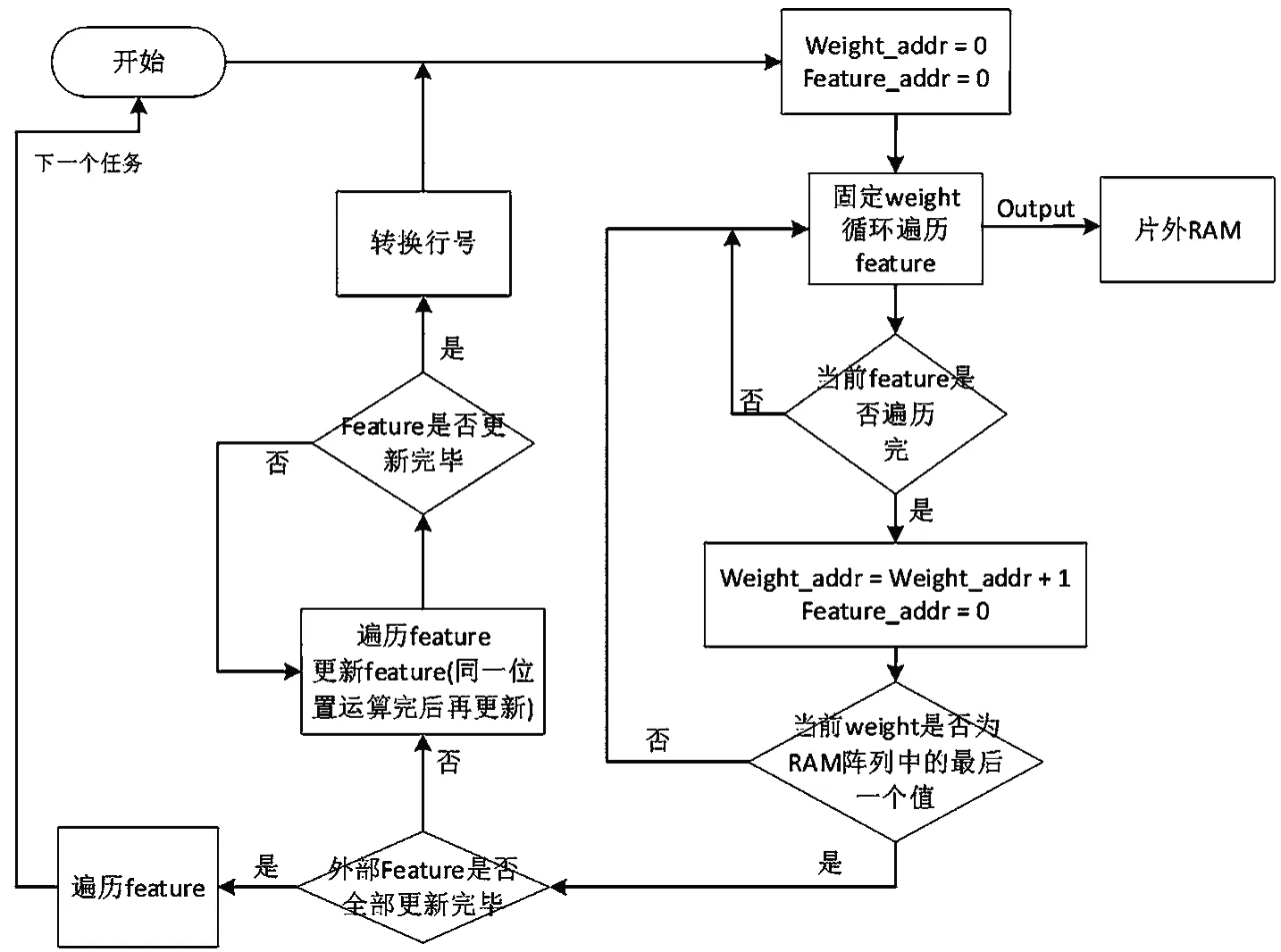
图6 存储管理模块的流程
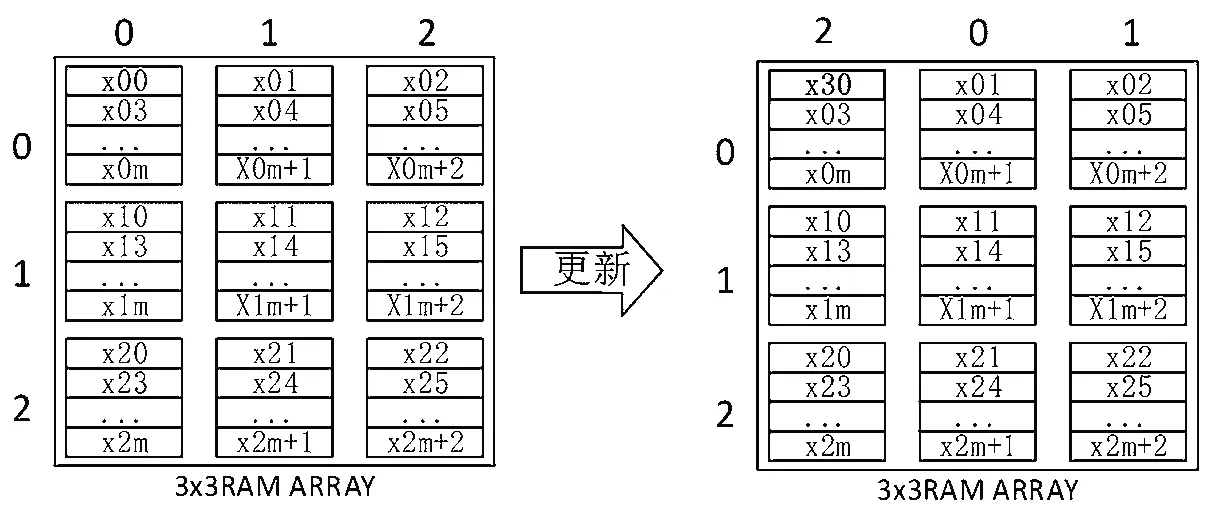
图7 RAM阵列更新时的列号变化
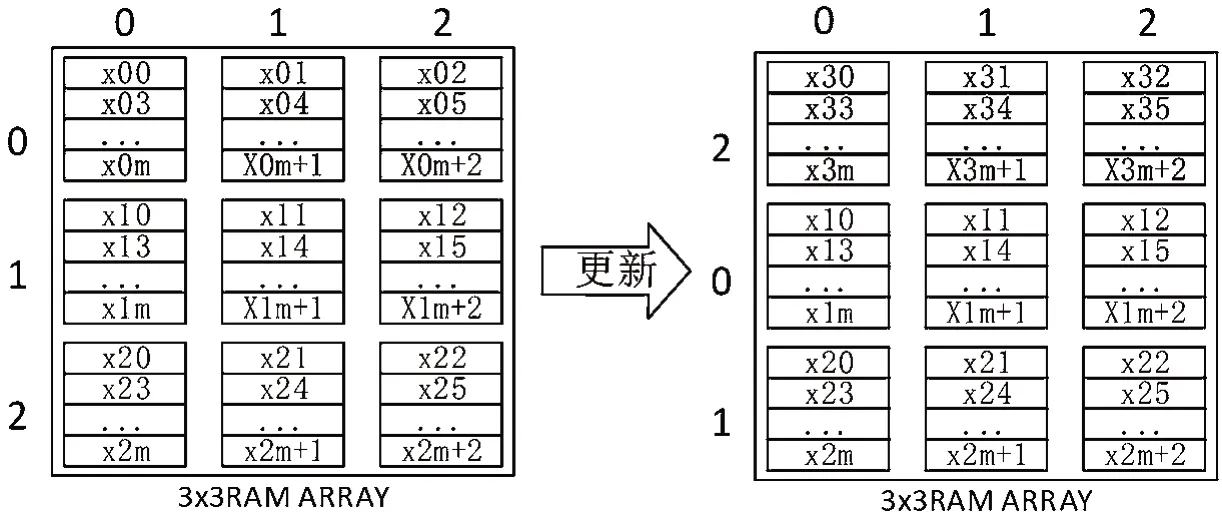
图8 RAM阵列更新时的行号变化

表1 特征值的行列号与权重值的对应关系
3 卷积算法优化
对于stride=1的3×3卷积,采用Winograd算法[8]来加速整个计算。Winograd算法的基本原理即用加法运算代替乘法运算,以减少运算量。例如,本设计中采用F(2×2,3×3),共需4×4=16次乘法运算,而标准的算法则需2×2×3×3=36次乘法。
对于F(2×2,3×3),其输出为:

其中,

式(2)中剩余的参数g为3×3的滤波器,d为4×4的特征值矩阵。每一个特征图被分割成了4×4的子特征矩阵,相邻的两个子特征矩阵之间有2个特征值的重叠。
针对Winograd算法的特性,可以令U=GgGT,V=BTdB,则式(2)变成:

本设计在运算开始前,可以将卷积核与特征值提前进行转换,而后直接在FPGA内部进行运算,以减少大量的重复性工作。
4 结果分析
本设计是在Xilinx Virtex7 xc7vx690t平台上执行的,采用流水结构,将每层单独设计,而后统一控制,提升了速度。在流水线设计中,每一层的运算量要保持大体相等,否则会产生流水线的瓶颈,从而降低整个流水线效率。
本设计以Alexnet为例,对提出的相关算法进行实现,并与其他的FPGA实现方式进行对比,得到的结果如表2所示。可以看出,采用本方案提出的存储管理和运行框架,可以达到较高的性能,且在表格所列举的5个设计方案中,本设计的能耗性能比最高。
此外,将该FPGA平台的实验结果与GPU的实现结果进行对比,结果如表2所示。
本设计采用NVIDIA TitanX的GPU,在Caffe框架[13]下对Alexnet进行实现。在GPU的实现中,采用Winograd算法对设计进行加速,得到的结果如表3所示。可以看出,在实现相同的网络时,虽然GPU的性能要高于本设计,但是本设计能耗性能比是GPU的2.7倍。

表2 不同平台实现Alexnet的性能对比
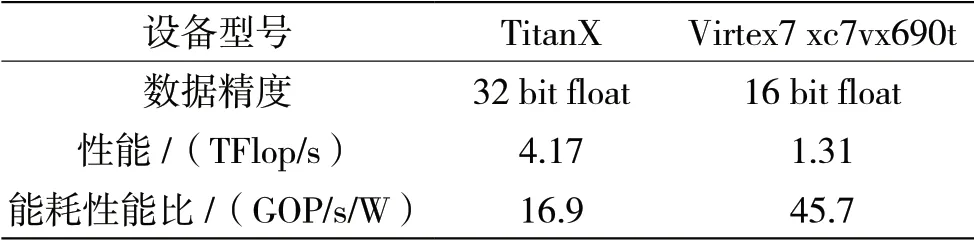
表3 本设计与GPU的性能对比
5 结 语
本文对基于CNN的FPGA硬件平台进行研究,设计了一种高效的硬件平台架构,提出了一种能够有效降低存储带宽的存储管理方案。在此基础上,采用Winograd算法降低运算量,并对卷积核为3×3和5×5的处理模块分别进行设计,使得该硬件平台能够更加高效加速CNN。本设计在Virtex7 xc7vx690t上实现了Alexnet,性能为1.31 TFlop/s,平均性能功耗比为45.7 GOP/s/W,结果优于目前较流行的集中设计方案。
