利用和声分散搜索算法解决动态共乘的乘客选择研究
2019-06-04侯立文
侯立文,刘 思,2
(1.上海交通大学安泰经济管理学院,上海 200030;2. 上海理工大学管理学院,上海 200093)
1 引言
动态共乘(dynamic ridesharing,DR,在我国称为拼车)就是某人利用信息交流平台为出行需求相匹配的他人提供及时搭乘服务,这在客观上对缓解城市交通压力,改善环境状况非常有益,大大提高了汽车服务效率,因而在诸如美国的西雅图,加拿大的哥伦比亚,欧洲的都柏林、苏黎世和亚洲的新加坡等地都流行起来,也催生了大量以此为业务的创业公司,如国外的uber、zimride、zipcar和国内的滴答拼车、51用车等,都取得了市场认可。而我国更是创造了春节拼车10天突破100万参与者的记录,目前已有北京、上海、杭州、广州等五十多个城市陆续开展了拼车服务。但现实情况也对DR提出了挑战,除了法律和信任等备受关注的问题之外,DR在带给乘客快捷、低成本的同时,也需要乘客有耐心、有时间与其他乘客共同完成一次出行(如果一辆车允许同时服务3位乘客,对一位乘客而言,最糟糕的情况是第一个上车,最后一个下车),也就是说,乘客在得到正效用的同时也伴随着负效用。由于DR是一种新兴出行模式,多数人希望能以乘客身份事先体验一下这种服务,因而造成市场上乘客的人数远远多于司机,于是如何为每个司机寻找合适的乘客就是DR服务得以实现的一个关键问题,因为乘客分布在城市的不同地点,需要在合理的时间内到达各自的目的地,而司机不仅要满足这些要求,而且也要符合自己的时间和目的地要求。
目前,关于DR的研究在国内外刚开始,两篇综述性文献Furuhata等[1]和Agatz等[2]分别从DR发展历程、对象分类、研究重点和模型方法等几方面进行了介绍,为该领域的研究梳理了脉络。根据这两篇文献,与本文研究相关的领域主要集中在共乘优化,优化的对象包括司机和乘客的最佳匹配Herbawi和Weber[3],程杰等[4];肖强等[5]、最优路线设计张瑾和何瑞春[6]、接送策略Abdel-Naby和Fante[7],Winter和Nittel[8]和信息利用Tao Chichung和Chen Chunying[9],Amey[10],以及运营成本和服务水平刘书曼等[11],邵增珍等[12]等几方面。大部分文献都属于理论研究,优化问题的模型结构和求解算法都比较丰富,特别是非经典优化算法的应用已十分普遍,极大拓展了人们对该领域问题的理解。另外,许多其它领域的文献对本文的研究也具有借鉴意义,比如在传统合乘(carpool)和电话叫车问题(dial-a-ride-problem)领域,也常常需要建立包括最短路程在内的多目标优化问题,并且也会用到启发式算法Cordeau和Laporte[13],Dominik和Roberto[14]。而在车辆路径问题(vehicle routing problem)研究中,带有时间窗的同时取送货方面的研究Berbeglia等[15],Cortes等[16]在目标函数、约束条件和搜索算法等方面与本文有相似之处(不同点在于共乘不要求回归原点),比如颜瑞等[17]也是利用混合式启发算法对车辆装箱问题进行了优化,而符卓等[18]所考虑的需求可拆分和时间窗也与本文的研究有相似之处。
总体而言,由于问题背景不同,上述研究尚不能回答一般共乘(国内学者几乎都集中在出租车共乘)的最优乘客选择问题,面对大规模路网下既要找到效用最大的乘客,又要尽可能保持最短的行程还需要更有效的算法的帮助,而本文正是面对这一挑战,在确保司机参与意愿情况下,力求使所搜索到的乘客的效用和共乘行程同时达到最优。以优化的角度来看,本文所描述的DR问题属于多目标、多约束的大规模离散组合优化问题,最优解的搜索不但存在很多约束,同时也是一个多维度、多目标问题,有时甚至是一个随机过程中的多阶段、多层次的优化问题,因而求解具有较大难度。司机和乘客的分布点、路线、时间限制和获得的效用共同构成了这样一个复杂的DR系统,对于这样一个多目标优化问题,由于各优化目标之间存在无法改善的相互制约关系,只能根据Pareto原则在多个目标之间进行平衡和协调,当问题规模较大,且约束较多时,传统的经典算法不得不让位于各类智能优化算法,而本文所采用的加入分散搜索(Scatter Search,SS)机制的和声搜索(Harmony Search,HS)算法就属于这样一类算法,该算法以记忆库取值概率和微调概率取代了梯度搜索,因此并不需要衍生信息。通过对所构建的DR模型进行求解,证明该算法完全可行。
2 多目标共乘模型
本文假定在一个DR系统中,潜在乘客人数远远大于司机人数,也就是说,每个司机一定最多只能同时服务3位乘客(因为一辆轿车搭乘3位乘客其舒适性较高),且司机事前能获得乘客起讫点和时间约束的信息。这个系统希望每个司机所选择的乘客可从共乘服务中获得最大效用,这一考虑与毕笑天和何瑞春[19]等的研究比较类似,而乘客在获得正效用的同时也伴随着负效用。正效用主要来自于节省的成本、较好的便利性、社交机会和更多的自由时间,同时也省去了自驾车时的紧张感;负效用主要来自于接送其他乘客而耽误的时间和潜在的不安全感。当然系统也应确保司机在途径接送乘客的这几个固定点后所行驶的总路程最短。
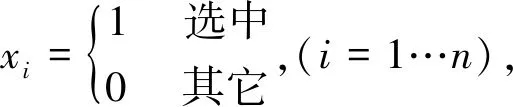
(1)
其它各参数含义如下:
ui+-共乘带给第i个乘客的正效用
ui--共乘带给第i个乘客的负效用
di、di+k-从停车点i或i+k到下一个停车点的距
S-车速(常量)
d0-从司机的出发点到第一个停车点的距离
vi-司机从服务第i个乘客获得的效用
V0-司机的保留效用(常量)
T0-司机的时间要求
Ti-第i个乘客的时间要求
目标函数f1指明,最优解必须使得乘客获得的净效用最大,如果乘客的负效用大于其获得的正效用,那么xi=0,所以从这个意义上讲,这里的正负效用都应属于感知效用(perceived utility)。目标函数f2的含义就是最优解应构成最短路,尽可能减少司机的成本。
3 和声分散搜索算法
3.1 和声搜索算法和分散搜索算法
和声搜索最早由Geem等[20]在2001年提出,是模仿乐师在创作过程中不断尝试使自己演奏的乐器发出的音符尽可能与其它乐器完美匹配,在每次调整过程中,都记住匹配完美的部分,再继续调试其余部分,如此反复,直至形成“最优曲调”。和声搜索算法主要由三个变量共同实现:和声库大小、和声记忆库保留概率(Harmony Memory Considering Rate,HMCR)和扰动概率(Pitch Adjusting Rate, PAR)。相比传统的最优化算法,和声搜索算法利用的已知量较少Mahdavi等[21],Verma等[22],初始值的确定较容易,而且是一种根据记忆库取值概率和微调概率进行随机搜索的算法,从而取代了梯度搜索。
分散搜索算法是一种为了解决复杂的整数规划问题而提出的采用智能迭代机制的全局搜索算法王晓晴等[23],它运用种群策略和“分散-收敛集聚”机制获取高质量和多样性的解,并保存在参考集中,这种具有一定记忆能力的参考集使得搜索策略调整成为可能,通过结合迭代得到的合并子集共同更新参考集,以此迅速获得全局最优解。分散搜索算法注重在多样性和集中性两方面进行搜索,很适合求解大规模多目标优化问题Beausoleil[24],Russell和Chiang[25]。
基于和声搜索算法里和声库的保留特点,借用精确算法中分支定界法的思想,本文将和声搜索和分散搜索两种算法结合了起来,把分散搜索机制加入到和声搜索算法中,构造出和声分散搜索(Harmony Scatter Search,HSS)算法,该算法既保留了和声搜索算法的全局搜索能力,又充分利用了分散搜索算法的灵活性,从而非常适合解决大规模路网下多目标0-1规划共乘模型。
3.2 算法步骤
3.2.1 初始解选择
由于多目标问题解的特殊性,HSS算法在初始值的选择上对HS算法进行了改进,避免了大部分初始解都是劣解而导致搜索效率低下的情况。算法首先根据解集的精度系数A(即精度的倒数)对决策变量的取值范围M(是一个A1*n维的矩阵,A1是第一次迭代的精度系数)进行划分,之后将每段的中位数随机放入和声库内,这里称为和声实验集(Trial Set),初始大小为TS(也是一个矩阵)。同时,对实验集中所有m个目标向量初始化,即F=F(f1,f2,…,fm),其中,fi为目标集中某一目标函数,并将实验集中的每个解向量的初始标志Flag置为1。
(1)
TS=M(Random(xi-median))
Fx=F(fj(TS))Flag=[1,1,…1]
TS设定好之后,根据实验集中每个目标的值,按Pareto最优解的选择机制筛选出当前实验集中的非劣解集,将其放入和声参考集(Reference Set)中,并设初始参考集理想容量值为RS。这样,经过基本HS算法处理的初始非劣解集就产生了。当经过N1次迭代产生RS’大小的非劣解集后,初始化迭代结束。
3.2.2 实验集和参考集的更新
初始化的实验集经筛选进入参考集后,寻优将采用SS机制。与分枝定界的思想一致,即每个参考集中的解集都是一个寻优子树的根节点。SS算法搜索的每个子集就是根节点产生的子节点。每次随机产生的子节点如果劣于父节点,那么就去掉这一分枝。每产生一次子节点,都要放入实验集进行筛选更新。具体步骤如下:
步骤1初始化产生参考集的容量RS(即根节点个数,也就是利用SS算法搜索RS棵树),每棵树的子节点数目Node设定为:
(3)
(4)
步骤3由于每个解分量有PAR的可能性进行扰动,而PAR与每个参考集中各个解分量xi的方差成正比。
PAR=PAR*Variance(ReferenceSet(xi))
(5)
步骤4将所有产生的第二层子树的解集更新到实验集中,并将原根节点解集(即参考集)中的解集也放入实验集,然后按Pareto最优解原则再次筛选非劣解。
步骤5当迭代次数小于N2时,返回步骤1,否则,第二次筛选计算停止。
步骤6根据具体问题要求和解的结果决定是否进行精度为Ai=3的第三次筛选,筛选过程同第二次筛选,依次类推。
把所有得到的解向量代入目标函数,得到相应的目标向量值,然后对每个目标向量值进行Pareto最优解筛选。只有满足Pareto优胜关系时,才能从实验集中淘汰被支配的解向量,这样既保证了解集的多样性,又不会造成Pareto 最优解的遗漏。在算法中,每个解向量都会有一个Flag标记,当某个解向量被判断为劣解后,其对应的Flag被置为0。比较结束后,所有Flag=1的解向量都是当前的支配解。以上算法的流程如图1所示。
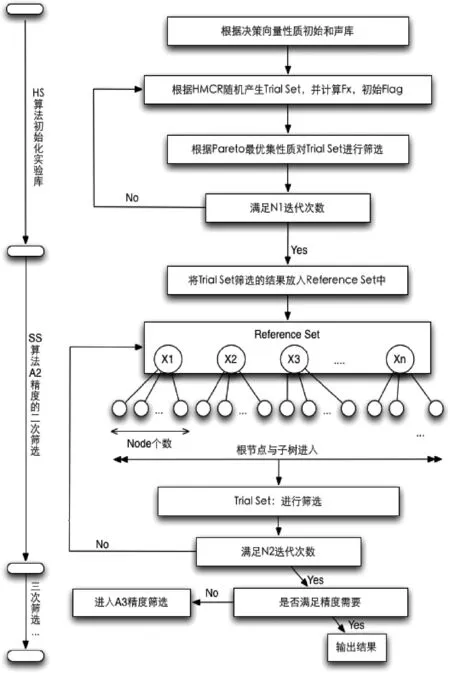
图1 和声分散搜索算法流程图
4 仿真实验
4.1 参数设置
首先构建一个由100*100稀疏矩阵的邻接图生成的路网(即该路网由1万个节点构成),为便于理解和展示,图2仅给出了一个10*10的路网。对一个DR系统而言,所有司机和乘客都会分布在该路网中,而路网中节点间的距离、每个乘客的目的地和司机与乘客的时间约束都将随机产生,当然,时间可以进一步区分为等待时间和行驶时间,然后利用模型确定估值[26],但考虑到本文的重点,在此不做深入讨论。比较相邻节点间的距离限制为50,乘客获得的正负效用区间分别是[10,30]和[5,15],司机的效用区间为[1,10],司机的保留效用设定为5,车速范围是[30,80],司机和乘客的行程时间要求都不超过90。迭代次数设为10万,这也是初始和声库的大小,根据经验,可设HMCR=0.8,PAR=0.1。实验所对应的场景是:在这1万个节点的每个节点上都有一个候选乘客(节点编号即为乘客编号),他们都有自己唯一的下车点(也已编号标记)和时间限制,司机从起点出发(不在图中),去往终点Node100。
根据效用的设置方式下面将对两种情形进行仿真实验,第一种情形是基本模型,假设司机和乘客的效用都可以直接从它们的效用区间中任意选取,但一旦选定,就不能再变,模型中的其它参数也是如此。第二种情形则以合适的效用函数替代效用值区间,根据事先给出的效用函数求得效用值,其余参数仍然采用第一种情形里的设置。

图2 100个节点构成的路网
4.2 算法流程与仿真结果
由于是求两个最优目标,所以仿真过程分为在最短路上寻找满足约束条件的可行解和在可行解中寻找效用最大的乘客这两步。对于第一步,最短路上的时间约束和司机获得的效用是判断节点是否可行的依据,为此首先计算司机与路网中任意3个节点(也就是3个潜在乘客)及其对应的下车点组合而成的DR系统的最短路(有100*98*96种组合),然后再根据最短路上的行程时间判断是否满足约束条件。所有满足约束的节点组合构成可行节点集(也就是解向量),最后根据所有可行节点的目标值确定Pareto最优解集。对于最短路径问题,我们采用经典的Dijkstra算法来实现,而在所有候选乘客中寻找满足约束条件的可行解则是一个0-1规划问题。将问题稍作转换便可利用启发式算法(即HSS算法)求得结果,经过多次迭代最终可得到可行解的和声库,并同时计算出目标函数值(即可行乘客获得的效用以及经过的总距离),然后将可行解进行多目标优化处理,得到最终的Pareto最优集。具体仿真过程如图3所示。
图3 仿真计算流程图
仿真运算进行了3次(采用主频为2.2MHz,内存为8G的四核服务器进行计算,每次耗时大约4小时,因此没有进行太多次实验),每次都显示出有9个Pareto最优解,表1展示了其中一次的结果。比如在第一组中,司机所选的乘客是编号为第205、758和第960号,此次共乘带给他们的总效用是50,总行程2919。本次总行程的变化范围是4542-2727=1815,方差为800。当总行程大于4381后,就不存在最优解了,说明超过该行程的乘客效用比目前的最优解都低。
图4展示了此次仿真所获得的所有可行解和Pareto最优解的分布,就最优解而言,总行程越大,带给乘客的效用也越大,这符合成本与收益的一般关系,但最优解集似乎可分为两部分,它们之间有显著的跳跃性。
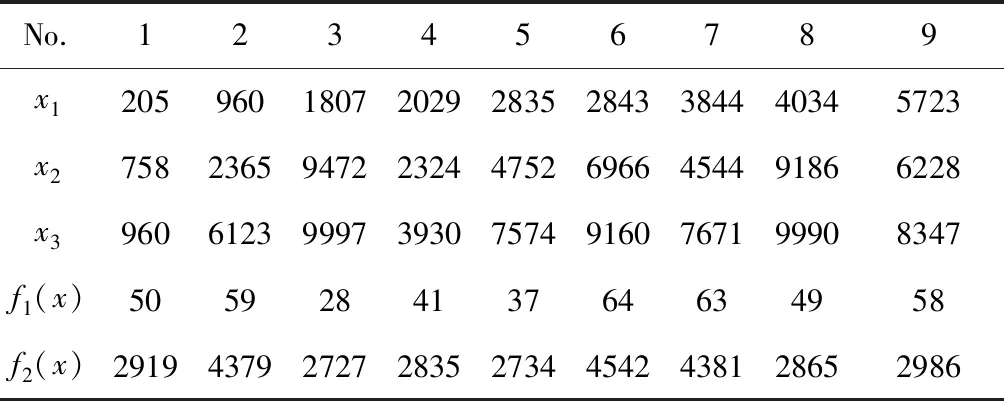
表1 基于效用区间的仿真结果
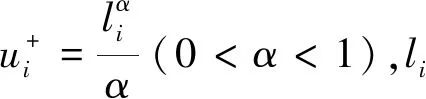
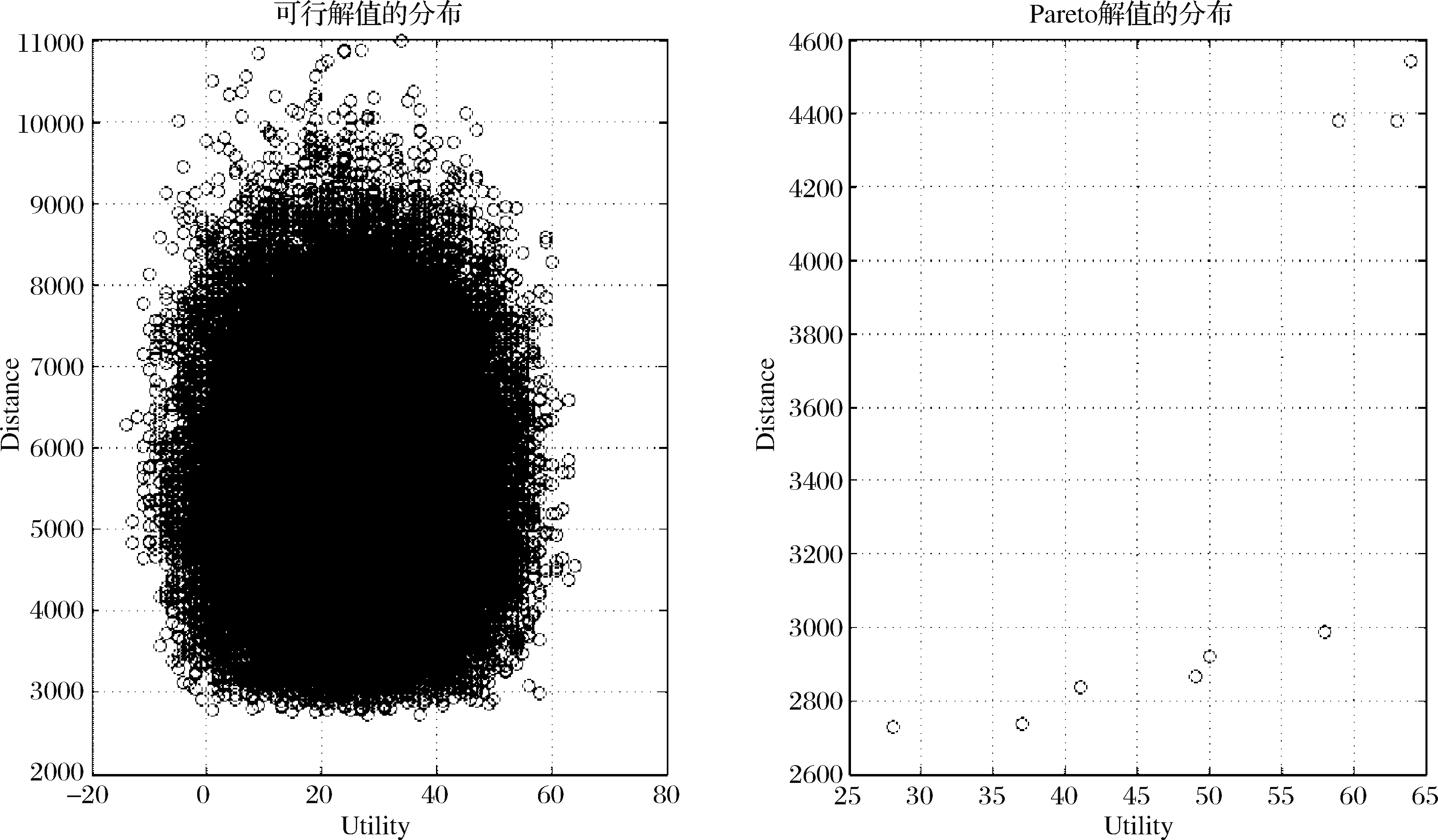
图4 模型的可行解和 Pareto 最优解的分布(效用区间)
表2是第二种情形的仿真结果。与第一种情形相比,最优解增加了4个,乘客的效用有大幅度提升(均值增加了1.7倍),总行程的变化范围(4142-2677=1465)和偏差(方差为500)也都显著缩小。这些结果说明采用效用函数形式能发现更多合适的乘客,而且带来更大的效用和更短的行程。

表2 基于效用函数的仿真结果
图5是此次仿真对应的可行解与Pareto最优解的分布。可行解的分布显示出存在一个上界,而且大量集中于该上界附近。同时,Pareto最优解也显示了一定的连续性,这不同于第一种情形的跳跃式。
4.3 算法比较
为了进一步展示HSS算法的优势,我们也使用了Xia Jizhe等[27]提出的禁忌搜索算法(TABU Search algorithm)同时对问题进行了仿真,禁忌搜索算法也是一种广泛使用的智能优化算法,禁忌图带有记忆功能,而禁忌搜索机制常常能避免算法陷入局部最优,并使其搜索方向跳出有限的解域。但是同时计算速度较慢,尤其在多目标优化问题中往往不容易找到最优的帕累托曲面解。我们在第一个基本拼车问题中,设置了相同的参数和初识范围,使用禁忌搜索方法和HSS方法对计算同时进行了仿真,得到的结果比较如下:
从图中结果可以得到,HSS算法不但可行解数量多于TABU搜索算法的结果,而且HSS算法仿真结果Pareto最优解集为13个,TABU搜索算法的仅为8个。同时从Pareto解最优曲线的形状看出,TABU搜索算法的曲线并不光滑,存在未找到的最优解可能性很大,而HSS算法结果的最优曲线上解相对密集,解的质量也同时也优于TABU搜索算法。再者,TABU搜索算法的运行时间是HSS算法运行时间的7.76倍左右,算法的复杂度也远高于和声搜索算法。
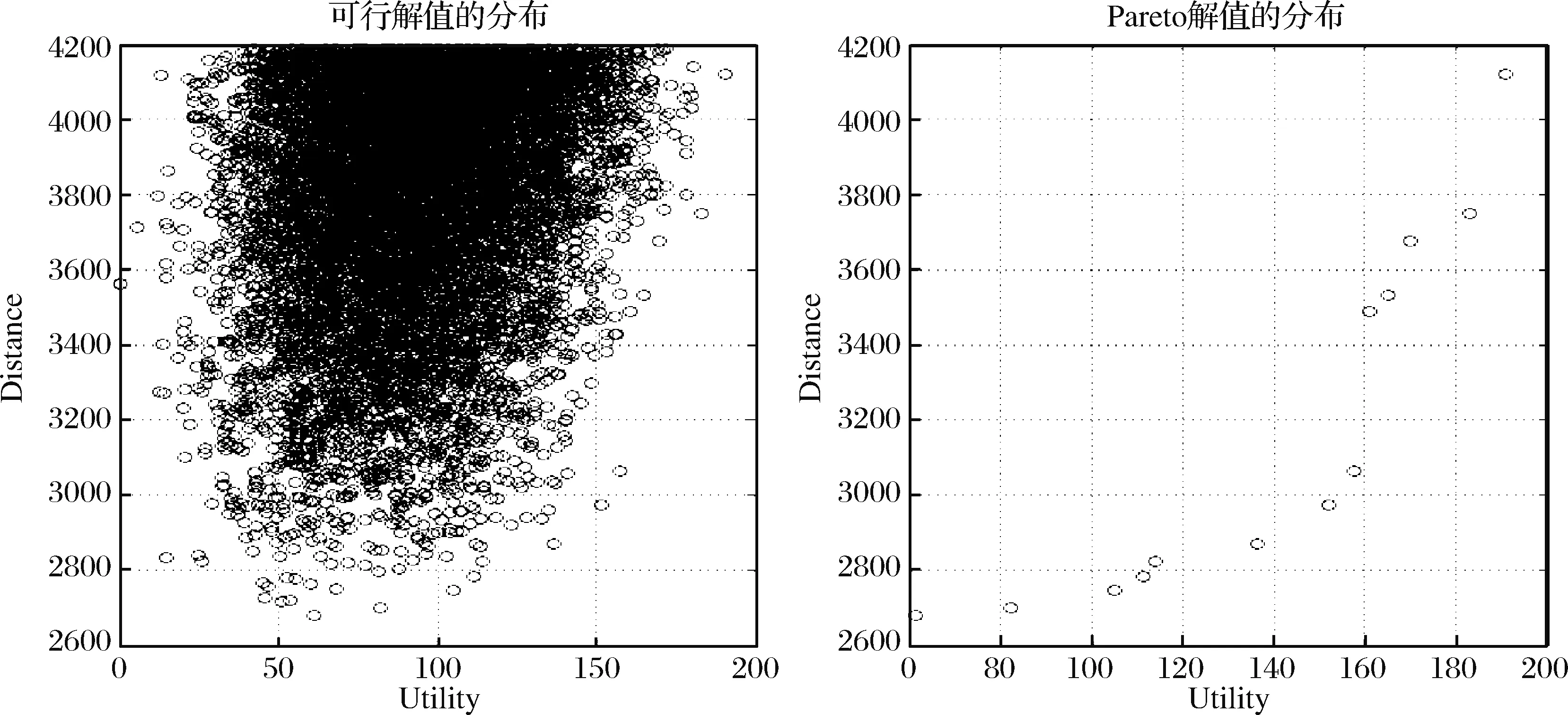
图5 模型的可行解和 Pareto 最优解的分布(效用函数)
图6 HSS算法得到的可行解和Pareto最优解分布曲线
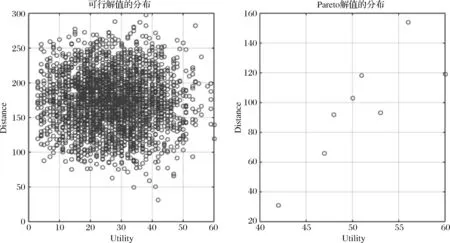
图7 TABU Search算法得到的可行解和Pareto最优解曲面
5 结语
DR服务的出现为缓解当前城市交通压力提供了一种补充途径,然而由于市场上司机和乘客数量的不对称导致DR匹配的实现往往不能达到最佳水平,乘客从共乘中获得的效用可能伴随着更长的行驶距离,为此本文在考虑了乘客效用最大化和行驶距离最短两个目标的前提下,建立了针对最佳乘客选择的多目标优化模型,模型的求解采用HS算法和SS算法的结合,从而有利于在大规模路网条件下找到Pareto最优解。在进行仿真实验时,针对乘客效用的两种形式分别进行了实验,结果显示,采用效用函数能发现更多合适的乘客,而且还能得到更好的Pareto最优解。总体而言,本文的研究既包括建立双节点路网系统,并找出所有节点组合的最短路径,也完成了一个离散的多目标0-1规划问题的求解,从而进一步拓展了DR领域的研究内容,但尽管如此,本文尚存在一些不足,最明显的就是各个参数的标定或随机化处理,比如车辆速度和时间窗,而这正是本文后续的主要研究内容;另外,针对HSS算法的进一步优化和改进也值得研究,以便提高模型的运算速度。
