基于Stacking的Android恶意检测方法研究∗
2019-06-01董克源
董克源 徐 建
(南京理工大学计算机科学与工程学院 南京 210094)
1 引言
Android的核心代码是开源的,意味着任何移动设备厂商都可以拷贝一份源码,去进行加工开发和适配工作,然后推出自己的Android手机,这导致越来越多的手机和其他设备采用Android系统进行改造,于是Android的市场份额也越来越大。根据分析机构StatCounter从250个网站综合的大约150亿次访问数据,Android设备产生的流量在2017年3月首次超过了Windows PC,从后者的头上摘走第一大操作系统的王冠,然而,不幸的是,也正是因为Android是开源系统,某些不法分子可以通过源码了解此系统的基本结构和源代码,通过诱导用户安装Android恶意应用,从而攫取不法利益。所以,为了用户安全,Android恶意应用检测技术成为了当今热点问题。
现有的恶意检测方法主要可以分为三种,分别是基于静态分析的方法、基于动态分析的方法和基于静态和动态结合的方法[1~3]。本文提出的基于Stacking的权限分析方法属于静态分析的范围。基于权限特征的检测方法是一种常用的基于静态分析的恶意应用检测方法。这个方法首先提取Android应用的权限特征,然后使用数据挖掘、机器学习的方法对其进行分析检测,建立分类检测模型,这种方法往往能有效率高的优点,所以被广泛使用。DroidRanger[4]系统和 WHYPE[5]系统等从给定的应用中提取权限特征,并通过应用自然语言处理技术对应用请求的权限进行匹配,以及通过权限的使用情况来识别恶意应用。但是这个方法也存在一些缺陷,比如不同的分类算法针对同一类特征的检测效果不同,且无法预知哪个算法效果最优、使用单一的算法不能充分发挥权限特征在恶意应用检测时所起的作用。另外,通过申请的权限直接提取权限特征会出现冗余权限的问题,进而导致分类不够准确。
为了解决上述问题,本文采用两个方法。1)采用去除冗余权限的方法提取特征。在以往的方法中,都是分析Manifest中申请的权限作为权限特征[6~9],本文采用分析调用的api来再次确认权限的真正使用情况,可以更加准确提取权限特征。2)本文研究多种集成方法对恶意检测模型的作用,本文先后采用少数服从多数法、一票否决法、基于Stacking的集成方法[10~12],最后发现基于Stacking的方法能取的较好的结果。实验结果表明,本文提出的基于Stacking的Android应用恶意检测方法的准确率能达到96%左右,具有较好的检测效果。
2 基于Stacking的恶意应用检测方法
2.1 检测的框架
图1是基于Stacking的Android的恶意应用检测方法的应用框架。将收集到的恶意样本库和正常样本库的每个样本的权限特征持久化到数据库,和传统的权限特征不同,本次研究提取的权限信息是程序实际用的权限,剔除申请到的无用权限,然后用四个分类算法对训练集进行训练学习,得到四个基分类器,包括贝叶斯分类器、C4.5分类器、SVM分类器、感知机分类器。接着用训练得到的四个基分类器分别对训练集中的每个样本进行分类,这样可以组合得到新的特征,用这个特征再次训练出一个新的分类器模型,可以使用贝叶斯分类器。这样当我们需要对一个新的未知的应用进行检测的时候,需要先提取权限特征,然后用四个基分类器分类得到四个分类结果,最后用这个分类结果作为输入,输入到第二层分类器得到最终分类结果。

图1 基于Stacking的Android恶意检测方法研究
2.2 权限特征向量提取
传统的权限向量提取方法如下,作为对比实验
1)为样本文件建立一个n维权限向量(n代表最新安卓版本的权限总量),每一维代表一个权限,值可取true或false,其值代表样本是否申请该权限;初始化权限向量,每一维初始均取false。

2)使用ApkTool工具对样本文件进行反编译工作,得到样本文件的配置文件AndroidManifest.xml文件。
3)对反编译得到的AndroidManifest.xml进行解析,提取出其中的uses-permission节点,得到该样本所申请使用的权限集合。
4)分析处理样本文件申请权限集合,修改样本对应的权限向量,将样本文件所申请的权限对应位修改为true,得到该样本的权限特征向量。
5)对每一个apk样本重复1)~4)步骤,得到样本集的权限特征。
本文新提出的权限提取方法如下:
1)首先构造“API-权限”之间映射关系,构造过程可以查看Android官方文档,主要参考现有的PScout成果,找到api和权限之间多对多的映射关系;
2)将映射关系存储到数据库;
3)按照传统的权限提取方法提取出样本文件的权限向量A
4)为该样本文件建立一个n维权限向量B(n代表最新安卓版本的权限总量),初始化权限向量,每一维初始均取false。检索反编译后的文件,查询所有使用到的api,根据api-权限映射表,查询所有可能用到的权限,将对应的权限值置为true;

5)更新权限向量A,每个值等于f(x)&p(x),取A矩阵中B矩阵中相同的权限对应的值进行与运算,都为true保持为true,否则修改为false;
6)对每一个apk样本重复3)~5)步骤,得到样本集的权限特征。
2.3 集成分类
对于获取的样本权限特征,传统方式是将其作为单分类器的输入进行训练模型,然后用这个模型来对新的安卓apk进行检测,这样的好处是方便快速,但是缺点是检测的效果不是很好。本文采用的方法是使用多个分类器训练多个模型,包括朴素贝叶斯、C4.5、感知机和SVM,再对多个模型的训练结果进行集成。本文实验采用多种集成方式,包括少数服从多数、一票否决法、Stacking元学习策略法。最终发现使用Stacking元学习策略法作为集成方法能大大提高检测效果。
算法1:Android malicious detection algorithm based on Stacking
2:Output:classifier model
3:Step1:learn base classifiers
4:for i to T do
5: learnModelibase on D
6:end for
7:Step2:construct new training data
8:for i=1 to m do

10: adddhtoDh
10:end for
11:Step3:
12:learnModelNBbased onDh
13:returnModelNB
第一行的训练数据是上述提取的权限特征向量和安卓程序是否是恶意的标签。输出是集成分类模型。在第四行到第六行,采用多种分类算法训练得到基本分类模型,第八行到第十行,根据学习到的分类模型对训练集进行分类,得到分类结果,{bayes result,C4.5 result,perceptron result,svm result},再加上真实的分类标签,组合成为新的特征值。第十二行用新组合得到的特征,训练出朴素贝叶斯(NB)模型。如此,基于Stacking的Android恶意检测模型已经建立完毕。当拿到新的apk,可以提取权限特征,然后采用Step1得到的多种基本分类器分类,根据分类结果组合新的特征后,采用Step3得到的朴素贝叶斯分类器进行分类,得到最终检测结果。
3 实验验证
3.1 实验设置
本实验从第三方应用市场下载了1000款Android应用,包含475款恶意应用和525款正常应用作为的样本集,样本集中的这些应用覆盖了娱乐、教育、体育、卫生、新闻、财经等多种类型,具有代表性。所有的实验都在内存为8 GB RAM,处理器为Intel(R)Core i7-7500U CPU 2.70GHz 2.90GHZ 的机器上完成,采用ApkTool对样本进行反编译,采用了Java语言实现APK样本的特征提取,采用Java语言实现基于Stacking的集成分类算法。
3.2 实验结果
实验中采用的是常用的评价标准:正确率、灵敏度、特效度和精度。先介绍几个常见的模型评价术语:
1)True positives(TP):被正确地划分为良性软件的个数,即实际为良性软件且被分类器划分为良性软件的实例数;
2)False positives(FP):被错误地划分为良性软件的个数,即实际为恶意软件但被分类器划分为良性软件的实例数;
3)False negatives(FN):被错误地划分为恶意软件的个数,即实际为良性软件但被分类器划分为恶意软件的实例数;
4)True negatives(TN):被正确地划分为恶意软件的个数,即实际为恶意软件且被分类器划分为恶意软件的实例数。
正确率:表示分对的样本数除以所有的样本数,通常来说,正确率越高,分类器越好。
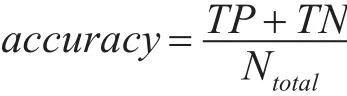
式中,Ntotal代表总样本数,也等于TP+FP+FN+TN。
灵敏度:表示的是所有Android良性软件中被分对的比例,衡量了分类器对良性软件的识别能力。
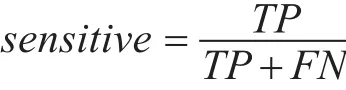
特效度:表示的是所有Android恶意软件中被分对的比例,衡量了分类器对恶意软件的识别能力。

精度:表示被分为Android良性软件中的实际为良性软件的比例,是精确性的度量。
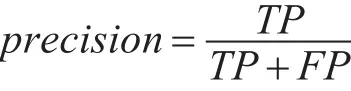
为了验证本文提出的算法的有效性,分别与仅采用单一分类器:朴素贝叶斯、C4.5、感知机和SVM算法检测方法进行了比较分析,并且采用不同方式提取权限特征表示应用样本的情况,实验结果如表所示。
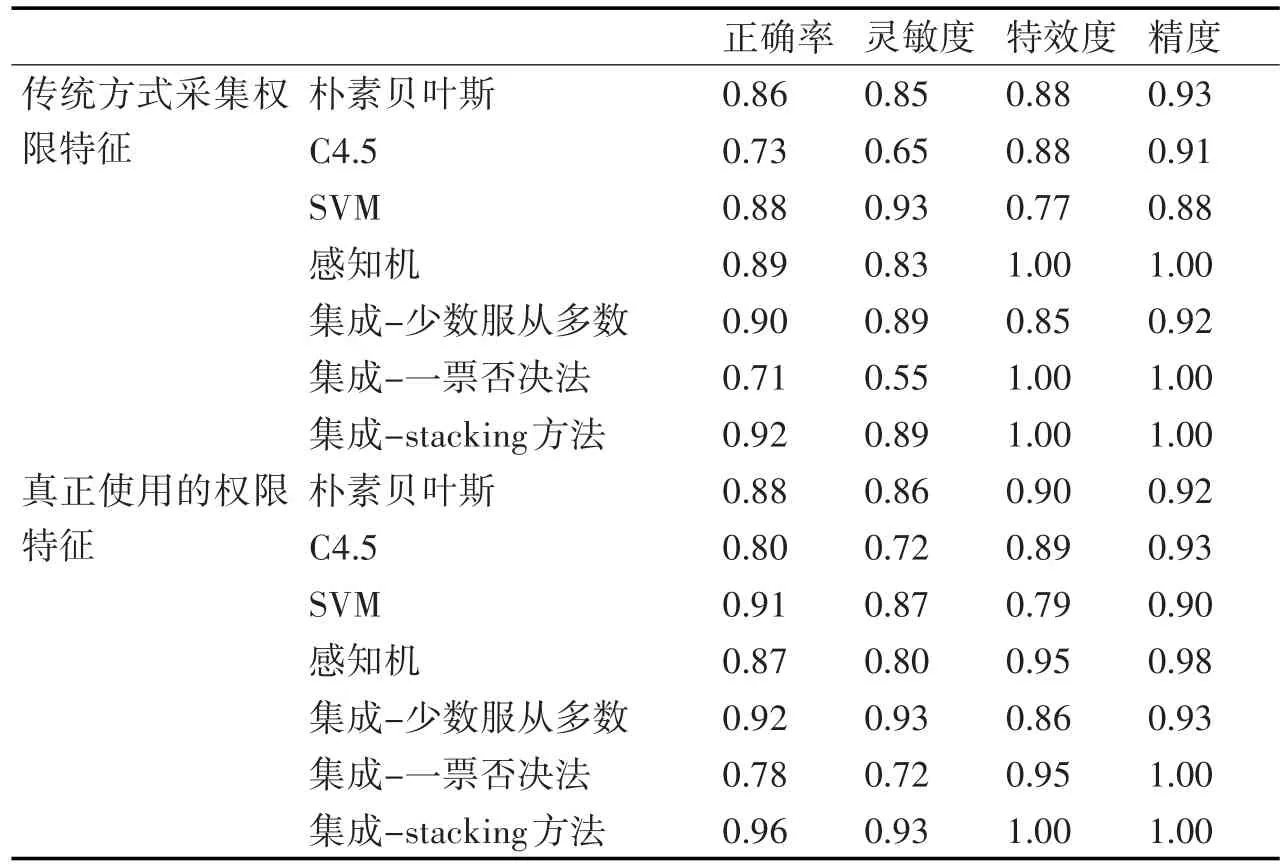
表1 实验结果
3.3 结果分析
从表1中可以看出,1)和传统的直接分析Manifest文件提取权限特征相比,本文提出的根据api调用来剔除没有使用过的权限的权限特征提取方法训练出来的分类器有更好的性能;2)同种特征值情况下,基于Stacking的集成方式相对于单分类器和其他两种集成方法有更好的分类器性能。总的说来,更为精确的特征提取能带来更好的训练效果,基于Stacking集成分类算法的检测精度也要优于采用单一分类器的分类效果。
4 结语
本文对现有的基于权限特征的恶意应用的检测技术上进行了分析和改进,采用更加准确的特征提取方法,并设计基于Stacking的集成方式提高安卓程序检测的性能,但是也存在着将合法应用判定为恶意应用的误差,这是算法需要进一步改进的地方。未来工作中,可以从两方面进行进一步研究:1)除了采用权限特征作为分类的特征输入,还可以采用动态分析的方法获取系统运行时的特征,如系统函数调用特征、文件读写操作特征、数据库操作特征、网络流量、电池消耗等,更丰富的特征将进一步提高检测效果[13~16]。2)单一的分类算法不能充分发挥特征在恶意应用检测时所做的贡献,所以本文基于Stacking的集成方法中第一层分类器采用4种基分类器,未来我们可以尝试添加更多不同的分类器,也可以尝试使用深度学习来训练分类器,更多的算法成果集成会有更好的结果。
