一种基于改进差分进化的K-均值聚类算法研究∗
2019-06-01王凤领梁海英
王凤领 梁海英 张 波
(贺州学院数学与计算机学院 贺州 542899)
1 引言
差分进化算法(DE)是由Storn.R和Price.K提出的一种基于群体进化的启发式算法,该算法从原始种群开始,通过变异、交叉和选择操作来生成新种群,是一种随机的并行全局搜索算法,具有记忆个体最优解和种群内信息共享的特点,即通过种群内个体间的合作与竞争来实现对优化问题的求解。差分进化算法具有简单高效、收敛速度快、鲁棒性好等优点。如刘明广通过引入迁徙操作而提出一种改进差分进化算法,吴亮红提出的基于群体适应度二次变异的自适应方差的差分进化算法。
K-means算法是由Mac(lueen)提出的经典聚类分析算法。它具有算法简单,收敛快的优点,但算法的聚类结果容易受到初始聚类中心的影响,易于陷入局部最优。近年来,许多学者利用各种常用的智能优化算法来改进K-means算法,并取得了一些成果。基于差异进化的K-means算法的改进优于基于传统遗传算法和微粒群优化算法。但传统的差分进化算法也会造成全局寻优能力下降,基于传统差分进化的K均值改进算法的性能受到全局优化能力的影响。本文提出基于改进的差分进化的K均值聚类算法。结合改进的差分进化算法和K均值,实验结果表明,该算法具有更好的全局优化能力和更快的收敛性。
2 差分进化算法
2.1 研究现状
2013年,Liang Bai等提出一种快速全局K-means算法,有效提高算法的聚类速度。在2014年,Aristidis Likas和Grigorios Tzortzis提出一种基于权重的K-means算法。2015年,Li Ma等提出了一种改进的K-mean算法。近几年,国内外许多研究人员将K-means和DE算法组合,取得一些成果。2015年Wan-li Xiang等使用动态搅乱差分进化算法进行聚类。2008年Swagatam Das等提出了基于差分进化的自动聚类算法(ACDE)。乔艳霞等提出一种基于K-means的改进差分进化聚类算法,将差分进化算法用于K-means聚类。刘莉莉等改进自适应调整的控制参数、将差分进化算法用选择结构的多模式进化方案,并将其与K-means聚类算法相结合,有效地解决初始聚类中心的优化问题。高平,毛力等提出了一种基于改进差分进化的K-means聚类算法,通过Logistic变尺度混浊搜索,增强差分进化算法的全局寻优能力[1]。
2.2 差分进化算法的关键操作
差分进化算法(DE)是一种典型的实数编码的进化算法,采用变异、杂交、选择等关键性操作从上一代种群到下一代种群的进化,以实现群体优化,下面将分析差分进化算法中涉及的几个操作[2]。
1)种群初始化
定义N×D的矩阵X用于存放当前种群的数据,其中,D为种群中个体的维数,N为种群的规模,随机产生N×D个服从均匀分布规律并满足特定约束条件的数据,放入矩阵X中,构成初始种群X(0)={X1(0),X2(0)…XN(0)}。
2)变异操作
令种群大小为N,当前进化个体Xi(t)(i=1,2,…,N)表示,t为当前进化个数。随机选择三个不同的个体,从当前进化群体中,并满足条件 r1,r2,r3∈{1,2,…,N},r1≠r2≠r3≠i,个体Xr2(t)和 Xr3(t)差值(Xr2(t)-Xr3(t))被看作个体Xr1(t)的扰动因子[2]。将因子和个体 Xi(t)相加以获得当前突变,突变操作的演变的对应个体Vi(t),如式(1)所示:

其中F为控制扰动因子的缩放系数。群体中个体由D个分量组成,那么变体个体Vi(t)也由D个分量组成,即Vi(t)=vr1(t),vr2(t),…,viD(t))。
3)交叉操作
生成随机整数r4,且 r4∈{1,2,…,N},离散变异个体Vi(t)与当前进化个体Xi(t)交叉以获得中间测试个体Ui(t),其将与 Xi(t)选择操作竞争,并且Ui(t)由D组分组成,即Ui(t)=(ui1(t),ui2(t),…,uiD(t))。其中第j个分量如式(2)所示:

r4是{1,2,…,D}中的随机整数,randj(0,1)表示服从(0,1)上均匀分布的随机数,并且r4可以保证在突变个体Vi(t)中存在至少一个维度分量,测试个体Ui(t),确保突变操作的作用力。CR是交叉概率,并且CR∈[0,1],CR概率越小,中间试验个体Ui(t)对当前进化个体Xi(t)的相似性越大。这可以帮助确保群体的多样性和算法的全局优化[3]。
4)选择操作
在最小化问题的情况下,适应度值越小越好[4]。如果Ui(t)的适应度值小于的适应度值,中间实验Ui(t)将替代新个体 Xi(t+1)中的当前个体Xi(t)。否则,当前进化的个体 Xi(t)将直接到下一代。如果个体适合度值由 f(Xi(t))表示,则选择操作可以式(3)表示如下:

5)参数设定
差分进化算法的主要控制参数有缩放系数、交叉概率CR以及F种群规模N。对差分进化算法的性能有着重要影响,尤其是缩放系数和交叉概率,在某种程度上决定算法的收敛速度和全局搜索能力[4]。
2.3 差分进化算法的步骤和流程
1)步骤
种群中的每个体都是求解问题的可行解,种群规模为N,个体的适应度表示为 f(Xi(t))函数,其中Xi(t)表示第t代种群的第i个个体,F是缩放系数,t是进化代数。CR表示交叉概率。养分进化算法的步骤描述为
步骤1:完成种群初始化,设群体大小N,缩放因子F∈[0,2],交叉概率 CR∈[0,1],进化代数t=0,随机生成初始种群 X(0)={X1(0),X2(0),…,XN(0)},其中,对任一个体 Xi(0)都含D个分量的向量,即 Xi(0)={Xi1(0),Xi2(0),…,XiD(0)};
步骤2:计算出每个体的适应度值 f(Xi(t)),对种群中的每个体进行评价;
步骤3:对种群个体 Xi(t)按式(1)完成变异操作,将得到变异个体Vi(t);
步骤5:对于最小化求解问题,具有小适应度函数值的个体进入下一代种群中继续进化。采取贪心策略,在选择操作过程中,择优选取,比较当前进化个体Xi(t)与相对应中间试验个体的适应度值。选择方式按式 Xi(t+1)进行;
步骤6:对种群X(t+1)中的个体进行检验,如果终止算法满足条件,则输出;否则t=t+1,转到步骤2。
2)算法流程
根据上述差分进化算法的描述,得到差分进化算法的流程图[5],如图1所示。
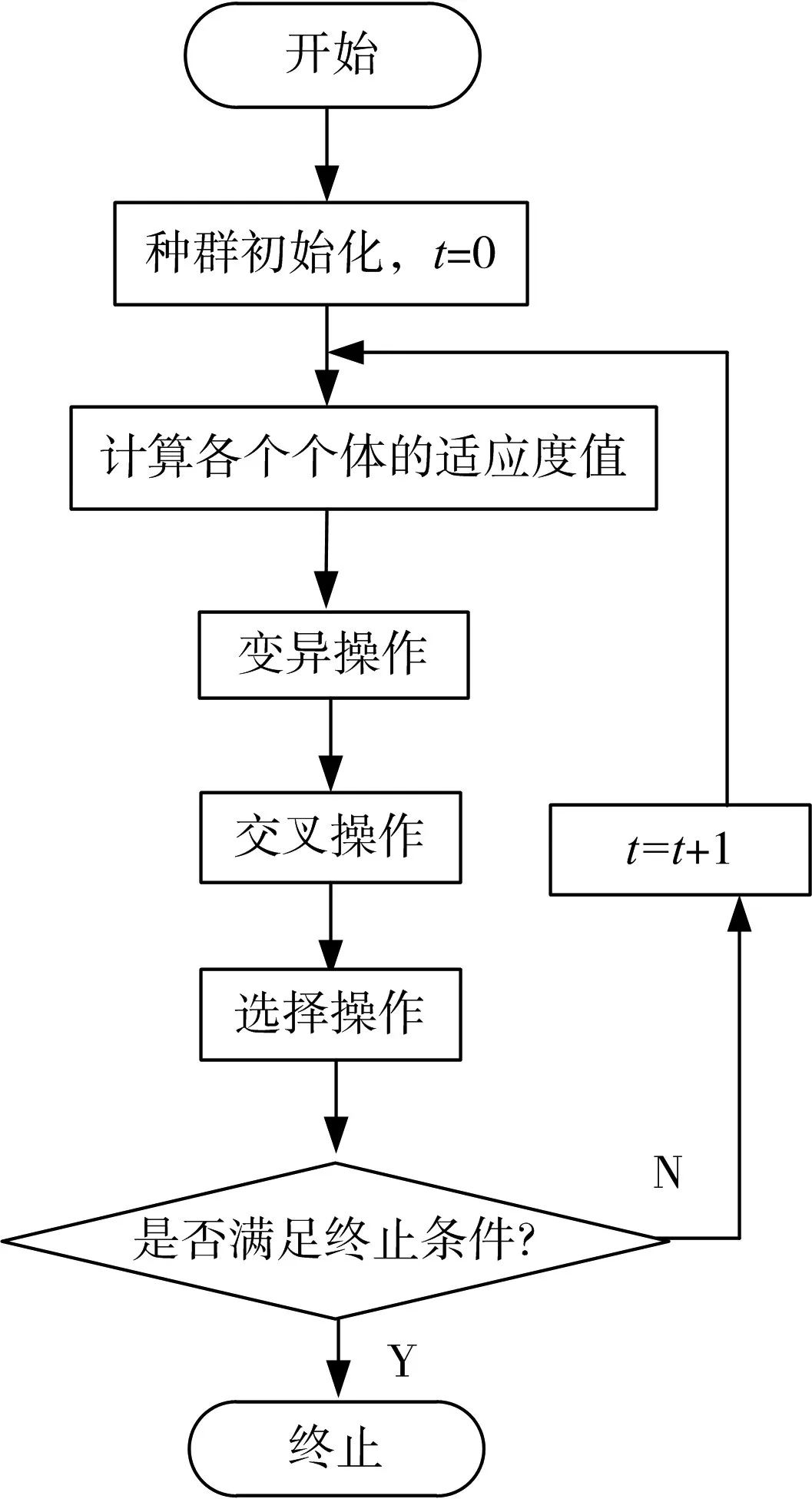
图1 差分进化算法的流程图
3 基于差分进化算法的K-均值聚类
差分进化算法是基于选择、交叉、变异操作的全局优化算法,差分算法用于操作对多个个体组成的群体,该群体中的个体经过优化,逐渐接近最优解,可通过K-均值聚类算法避免容易陷入局部最优解的缺陷,提高算法收敛速度和算法的稳定性[6]。
3.1 基于差分进化的K-均值聚类算法描述
首先需要对从数据集中随机选择的聚类中心进行编码,构建初始种群,然后进行差分进化算法的选择、交叉、变异等,以获得最佳个体,最后,最佳个体解码,获得最佳初始聚类中心并进行聚类[7]。其步骤如下。
输入:包含n个数据对象的数据集X、聚类数目K、缩放系数F、种群大小N、交叉概率CR。
输出:输出最佳聚类结果。
步骤1编码:使用实数编码从数据集中随机选择聚类中心,对与可行解对应的编码进行编码;每个个体由K个聚类中心向量串组成,因为样本向量维数d,所以每个个体应该是K×d维向量[8]。具体编码如下:
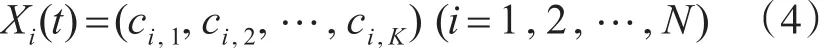
其中,Xi(t)为第t代种群的第i个个体,表示第i个个体的第j个聚类中心,迭代次数t的初始值为0。
步骤2种群初始化:从数据集K数据样本中随机选取个体作为初始种群,重复N次操作,构建初始种群。
步骤3评价种群中每一个体;计算个体Xi(t)的适应度值 f(Xi(t))。
步骤4变异操作:从种群中随机选择三个个体Xa,j(t),Xb,j(t),Xc,j(t),并且 a≠b≠c≠i,并按如下式进行计算得到变异个体Vi(t),Vi(t)为缩放系数。
步骤5交叉操作:种群中的个体Xi(t)和变异个体Vi(t)进行交叉操作,并按如下式进行计算得到中间试验个体Ui(t):

其中,rand(0,1)是在(0,1)上均匀分布的随机数,rand(i)是[1,K]上的随机数。 CR是交叉概率,CR∈[0,1]。
步骤6选择操作:在中间试验个体Ui(t)和当前进化个体Xi(t)之间,采用贪心算法计算和比较适应度值,确定个体的最小适合度值,即最佳个体进入下一代种群。
步骤7检验种群X(t+1)中的个体,若满足终止条件,则输出最佳个体并终止算法;否则,迭代次数t将增加1,并返回步骤2继续。
步骤8对输出的最佳个体进行解码,得到相应的最优聚类中心集,并将种群中的所有数据对象划分为相应的簇中,根据最近邻原则。
步骤9输出聚类结果。
3.2 基于差分进化的K-均值聚类算法流程
差分进化算法是具有强大的全局搜索能力的进化算法,应用于优化K-均值聚类算法的初始中心,有效克服K-均值聚类算法对初始中心值选择敏感缺陷,大大提高初始聚类中心的质量[9]。根据基于差分进化的K-均值聚类算法的描述,得到基于差分进化的K-均值聚类算法的流程图,如图2所示。
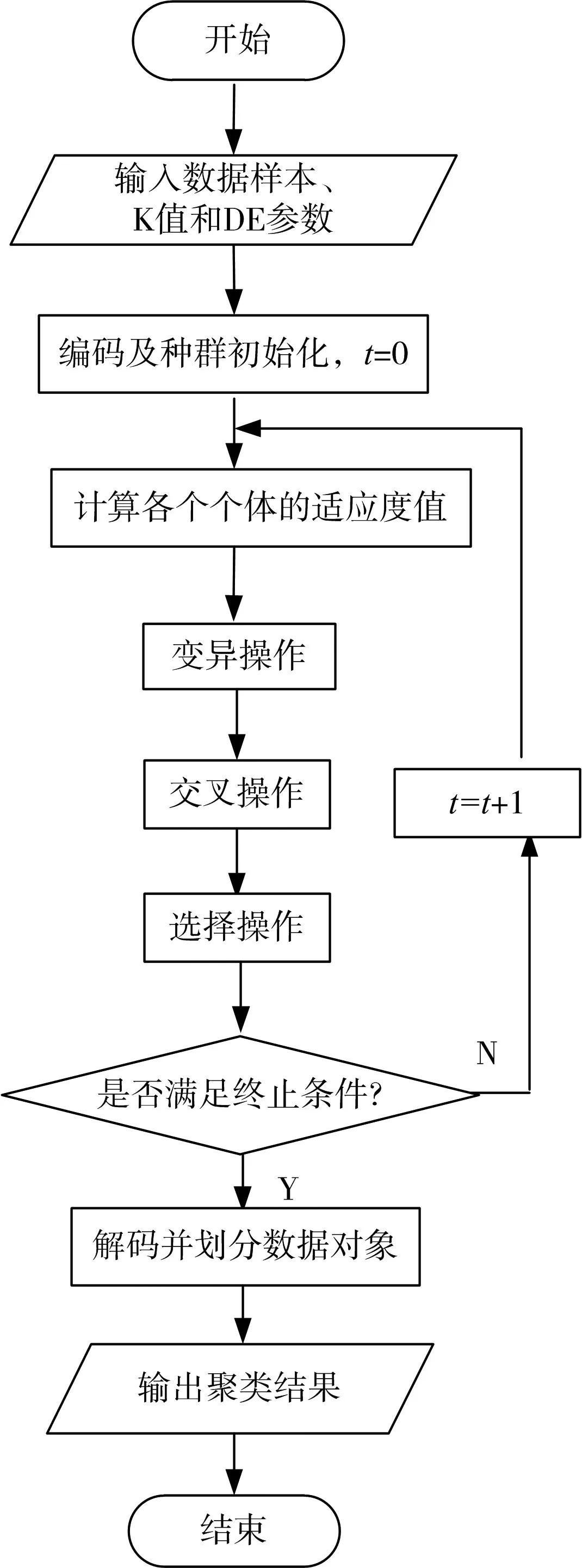
图2 基于差分进化的K-均值聚类算法的流程图
4 改进差分进化的K-均值聚类算法
通过将差分进化算法引入到K-均值聚类算法,可优化初始聚类中心的选择过程,简便易行,提高聚类质量和收敛速度。交叉和突变操作确保种群进化的多样性和算法的全局搜索能力[10]。然而,随着差分进化代数的增加,种群的多样性将会变小,过早收敛到局部最小点,或者算法停滞不前[11]。因此,需要加强算法的局部搜索能力,特别是后期进化算法收敛速度。在本文中,提出一种改进的方案来提高算法的局部搜索能力[12]。
4.1 改进方案
1)加强局部搜索能力
与标准差分进化算法相比,全局优化能力并没有减弱,而且可以同时增强算法的局部搜索能力[13]。改进方案的基本思想是记录在算法变异操作中和个体Xi(t)对应的两个随机个体之间的差,即 Xr2(t)-Xr3(t),记为 Hi(t),即 Hi(t)=Xr2(t)-Xr3(t),在选择操作之后获到的个体Xi(t+1)为中心,Hi(t)为半径,并在此范围内继续搜索,产生新个体与 Xi(t+1)的适应度值,如果在此范围内搜索新产生的个体适应度值优于Xi(t+1),用个体(t+1)替代 Xi(t+1)将成为新的Xi(t+1),从而加强原差分进化算法的局部搜索功能[14]。
2)采用动态缩放系数
差分进化算法中设置控制参数对算法的性能有重要的影响。在本文中,采用开口向上抛物线方式取值缩放系数F,F的值如式(6):
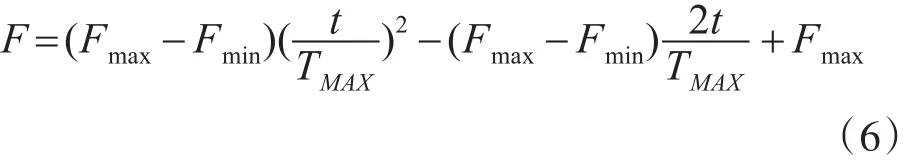
其中,Fmin为最小缩放系数,且Fmin=0.4,Fmax为最大缩放系数,且Fmax=0.9。t为当前进化的代数,TMAX为算法设定的最大进化代数。
3)采用动态交叉概率
在本文中,采取随进化代数线性增加的交叉概率取值策略,交叉概率CR对差分进化算法的收敛速度有直接和重要的影响,方法如式(7):

其中,CRmax为最大交叉概率,CRmax=0.9,CRmin为最小交叉概率,CRmin=0.3,t为当前进化代数,TMAX为算法设定的最大进化代数。
4.2 算法描述
根据上述改进方案,改进了标准差分进化算法,并将改进的差分进化算法应用于K-均值聚类算法中初始聚类中心的优化。对于一组聚类中心(c1,c2,…,cK),在K-均值聚类算法中,相应的类内距离定义为式(8):
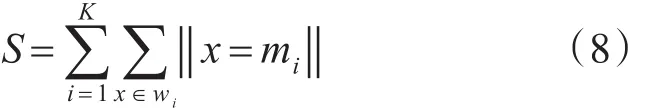
其中,mi为簇wi的中心,x是簇wi中的数据样本,通过计算簇wi中所有数据样本的均值来获得,本文中的适应度函数采用式(9):
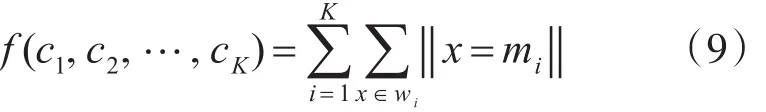
算法描述如下:
输入:含有n个数据对象的数据集X、聚类数目K、种群规模N。
输出:输出最佳聚类结果。
步骤1:用于对聚类中心进行编码以完成种群初始化:对于使用实际编码从数据中心对数据集进行随机选择,进化代数t=0,一组K个聚类中心对应于一个个体,因为聚类中心代表聚类,种群N的大小,表明初始种群代表N种聚类,单个体由K个基因位向量串组成,基因位代表聚类中心,编码如式(4)。
假设每个聚类中心的向量维数为d,数据样本的维数为d维,种群中的每个个体为K×d维向量。从数据集K数据样本中随机选择K个体的初始种群,重复N次操作,以构建初始种群。
步骤2:个体评价,计算每个个体的适应度值f(Xi(t))。
步骤3:变异操作,根据个体基因位进行变异,个体 Xi(t)按式 vij(t)=xaj(t)+F(xbj(t)-xcj(t))(j=1,2,…,K)计算得到变异个体Vi(t),记录两个随机个体 的 差 值 Hi(t)=Xb(t)-Xc(t) ,Hi(t)=(hi1(t),hi2(t),…,hiK(t))为缩放系数,按照公式 F=(Fmax-Fmin)执行动态递减策略取值。
步骤4:交叉操作,按照式 uij(t)=计算得到中间试验个体Ui(t),Ui(t)是由K维分量组成的,即Ui(t)=(ui1(t),ui2(t),…,uiK(t))。其中,CR为交叉概率,CR进行取值策略。随着进化代数的增加,CR的值线性增加。
步骤5:选择操作,中间试验个体Ui(t)和当前进化个体Xi(t)之间,哪个个体进入下一代种群中使用贪心选择策略来决定。择优选取当前进化个体Xi(t)与其对应中间试验个体Ui(t)的适应度值。对于最小化求解问题,具有较小适应度值的个体可能继续进化成下一代种群。按式进行选择。
步骤6:检验下一代种群中的个体,若满足终止条件,则输出最佳个体并终止算法;否则,迭代次数增加1,返回继续步骤2操作。
步骤7:对输出的最佳个体进行解码以获得相应的最优聚类中心集,并根据最近邻原则将种群中的所有数据对象划分为相应的簇。
步骤8:输出聚类结果。
4.3 算法流程
改进的差分进化算法的重要特征是添加二次选择和二次变异操作以增强局部搜索能力。同时,交叉概率和缩放因子不是固定值,是采用动态变化值策略[15]。
基于上述改进差分进化的K-均值聚类算法的描述,得到改进差分进化的K-均值聚类算法流程图,如图3所示。

图3 基于改进差分进化的K-均值聚类算法流程图
4.4 实验结果及分析
采用UCI数据库中的三个数据集:IRIS数据集,Glass数据集和Vowel数据集被用作测试数据集。三个数据集用于测试K-均值聚类算法,基于差分进化算法的K-均值聚类算法和提出的基于改进差分进化的K-均值聚类算法的聚类效果。

表1 测试数据集特征描述
在基于差分进化K-均值聚类算法的仿真实验中,种群大小N占相应数据集维数D的10倍,最大迭代次数T设置为1800。交叉概率CR为0.5。缩放系数为0.6。在基于改进差分进化的K均值聚类算法的仿真实验中,种群大小N也取相应数据集的维数D的10倍,最大迭代次数T也被设置为1800,交叉概率CR和缩放系数F按公式自适应取值。K-均值聚类算法、基于差分进化的K-均值聚类算法和基于改进差分进化的K-均值聚类算法这三个测试数据集用于进行35次仿真实验。结果如表2所示。
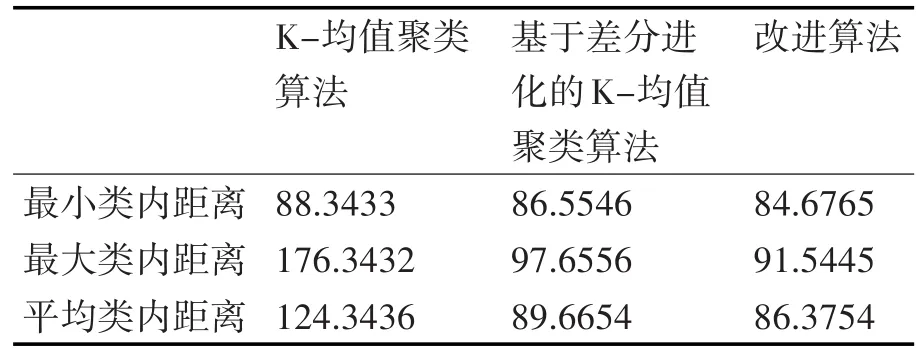
表2 IRIS数据集上的实验结果
对于Glass数据集,其实验结果如表3所示。
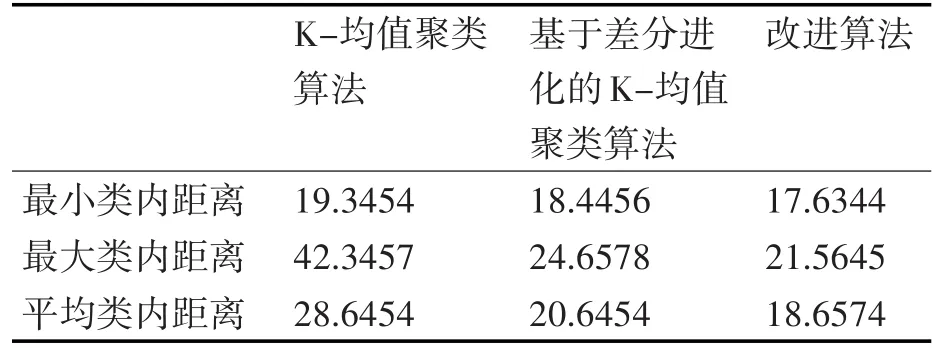
表3 Glass数据集上的实验结果
对Vowel数据集,实验结果如表4所示。
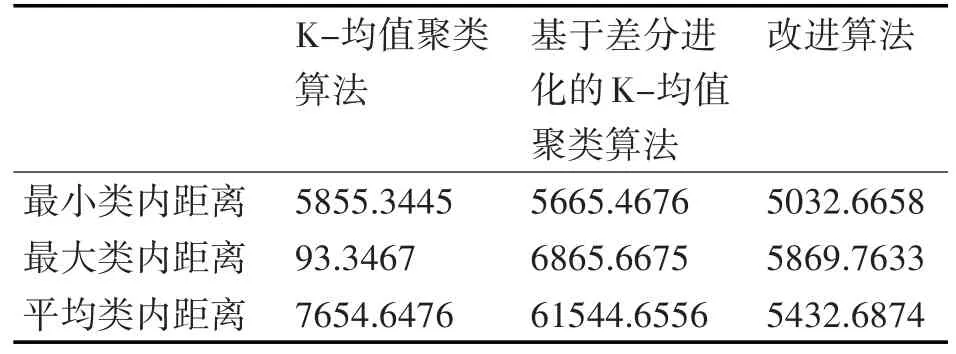
表4 在Vowel数据集上的实验结果
通过上述实验结果,我们可以发现随机选择初始聚类中心的K-均值聚类算法的聚类结果波动范围较大,稳定性差。因此,实验数据验证了基于差分进化和改进算法的K-均值聚类算法大大提高了聚类结果的稳定性和有效性,并且聚类质量得到了显着提高。从结果分析可以看出,提出的算法的聚类结果和质量优于基于标准差分进化的K均值聚类算法。改进算法的收敛速度比基于差分进化聚类算法的K-均值聚类算法的收敛速度快。
5 结语
针对基于差分进化的K均值聚类算法的缺陷,提出基于改进差分进化的K均值聚类算法,介绍改进算法的改进方案,步骤和具体流程。并对K-均值聚类算法、基于差分进化的K-均值聚类算法和改进算法进行仿真实验。结果表明,该算法具有收敛快的优点,不仅具有差分进化算法的全局优化能力,而且具有K-均值聚类算法的优点,搜索速度快,结果稳定。
