高维空间可分性指标在转子诊断系统优化中的应用
2019-05-31徐搏超
徐搏超
中国大唐集团科学技术研究院有限公司华东电力实验研究院,合肥,230031
0 引言
汽轮机组作为发电厂的主体设备,由于结构众多、工况复杂,极易受到众多因素的干扰。当转子发生故障后,如何快速精准地确认故障是工程研究领域的难点。转子多故障诊断具有重要意义。
基于二叉树结构[1-2]的相关向量机(relevance vector machine, RVM)系统通过细化分类实现了多故障诊断,目前已得到广泛应用。文献 [3]表明,二叉树结构越靠近顶节点对系统的累积误差影响越大。为了提高系统分类精度,需要进行结构优化,提高上层节点的分类正确率。分类器中正负类样本的差异性决定了该节点的分类效率。为了抑制误差累积效应,对系统的优化策略依据相似度从小到大的顺序进行种类分割。目前常用的可分性判据中,基于后验概率的可分性判据[4]、基于类的概率密度函数[5]的可分性判据对样本数量依赖性较强,不适用于转子故障这类小样本问题。基于几何距离的可分性判据[6]一般用方差描述低维空间中样本特征向量的离散程度,相关向量机通过核函数将低维向量映射到高维空间后进行分类,在高维空间中样本方差并不能较好地克服度量集中效应。
高维向量之间的分数范数差值较大,故本文选用分数范数作为高维空间距离度量方法,研究高斯无穷维空间样本点的形式并进行改造,使其在满足工程精度的要求下便于计算距离;同时对传统的类间类内方差比值判据进行了改进,引入分数范数构造了一种适用于高斯核空间的可分性指标。
1 基于均衡二叉树的多分类系统
二叉树多分类是二叉树结构的多个分类器组合。对于k?类分类问题,二叉树算法仅需要构造k?-1个子分类,大幅度缩减了计算量。对于单个分类器而言,正负两类训练样本数量越均衡,该分类器精度越高[6]。同时为了兼顾故障诊断的时间成本,本文选择节点查询时间复杂度较低[7]的均衡二叉树作为系统结构图。
基于均衡二叉树算法的多分类系统训练过程是首先将样本数据按类别均分成两部分,随机标记为正负两类,训练出根节点分类器。分别对第一部分(左节点)和第二部分(右节点)中的类别再次进行均分,训练第二层分类器。以此类推,直至叶子节点中只包含一类样本。系统完成训练后,输入测试样本,样本依次经过各层分类器,最终会被归类到某一叶子节点中完成诊断。以四分类问题为例,其均衡二叉树结构见图1。
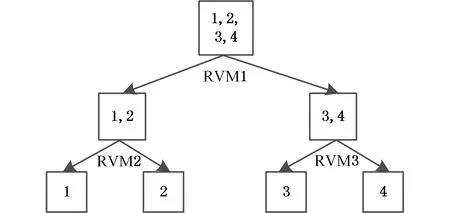
图1 均衡二叉树结构图Fig.1 Balanced binary tree structure diagram
2 基于分数范数的高斯核空间可分性指标
2.1 高维空间距离度量准则
高斯核函数空间是一个无穷维空间[8],为了找出适合高维空间的距离度量准则,首先需要了解数据点的分布情况。本文通过高维空间中最近邻分析的相关定理[9],研究样本点在高维映射空间内的分布规律。

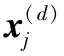
定理2(定理1逆定理) 假设样本数目n?足够大,使得
成立,如果
则对于任一ε?,有

上述定理表明,在高维空间中样本点范数的相对方差和相对差异都趋于零。上述方法对不同点的区分性很小。欧氏空间中方差度量的差异性随着样本维度的增长越来越弱,这种现象通常称为度量集中[10],这表明在高维空间中样本点趋于均匀分布。
文献 [11-12]表明e?p?范数中p?值对高维空间距离影响较大。机器学习算法在较小的p?值易于求得稀疏解。
定理3[13]设定样本集包含n?个d?维独立分布的样本点,则存在常数C?k?,使得

(1)
式中,x?i?为向量x的第i?个元素。
当p?<1时,该范数称为分数范数[14]。
2.2 高斯核函数空间样本点形式探究及改造
首先给出高斯核函数[15]表达式:
K?x,y=exp(-‖x-y‖2/(2σ?2))
(2)
式(2)的麦克劳林展开式如下:

为了保证一般性,设定σ?=1。
由上述公式推导可知,径向基核函数φ?(x)的定义式为



2.3 高斯核空间样本点可分性指标构造
高斯核空间属于无穷维空间,方差判据不能有效克服度量集中现象导致的样本点稀疏分布的难题。由上述分析可知,分数范数相较于p?>1时的范数在高维空间中度量效果更好,故选用分数范数作为高斯核空间样本点的可分性判据。可分性指标的构造求解过程如下:
给定两个原始数据集合X?={x1,x2,…,xi?},Y?={y1,y2,…,yj?},其中i?=1,2,…,n?1;j?=1,2,…,n?2。两样本集合映射后的均值向量分别为
(3)
类间距离度量用下式求解:
(4)
式中,μ?xi?和μ?yi?分别为向量μx?和μy?中第i?维数值。
X?和Y?的类内距离S?x?和S?y?分别为
(5)
(6)
式中,φ?m?(xi?)和φ?n?(yi?)分别为向量φ?(xi?)和φ?(yi?)中的第m?维和第n?维数值。
分类指标的优劣性体现在兼顾同类样本的内聚性和异类样本的排斥性。基于上述原则,构造可分性指标:
(7)
d?xy?越大,代表不同类的高维样本点距离越远,同时类内具有内聚性,这表明两类样本更易区分。
3 多故障分类系统节点优化实验
在Bently转子实验台上模拟汽轮机转子正常状态和转子质量不平衡、转子不对中、动静碰磨、油膜涡动4种常见振动故障信号。模拟设备转速3 000 r/min,采样频率1 280 Hz,采样点数为1 024。每类状态集前10组作为训练样本,后10组作为测试样本。
汽轮机故障信号特征大部分集中在前几阶倍频段中,因此首先使用希尔伯特振动分解(HVD)方法分解故障信号,进而选取半频、基频、二倍频和高频计算模糊熵值,最后组合这4个频段的特征值构建故障特征向量。通过RVM模型进行样本学习,完成模型训练。上述故障特征提取过程见图2。

图2 故障特征提取流程图Fig.2 Flowchart of fault feature extraction
3.1 实验1
以上述5种汽轮机运行状态为例,对二叉树分类系统进行节点优化。实验1中比较不同节点优化方法对系统最终分类精度的影响。对照方法通过求取不同故障种类样本特征向量的方差判断不同类别样本的可分性,进而进行正负类选取,样本可分性用下式度量:
(8)
其中,D?x?和D?y?表示样本X?和Y?基于方差算出的类内距离;D?xy?为不同类样本的类间距。d?xy?越大,X?和Y?两类样本在特征向量空间中的可区分性越大。
样本方差优化后的系统图见图3;通过本文提出的指标进行优化后的系统图见图4。完成优化后系统各层节点的值见表1,优化后系统的分类正确率见表2。

图3 样本方差指标优化后系统图Fig.3 Optimized system chart based onsample variance index
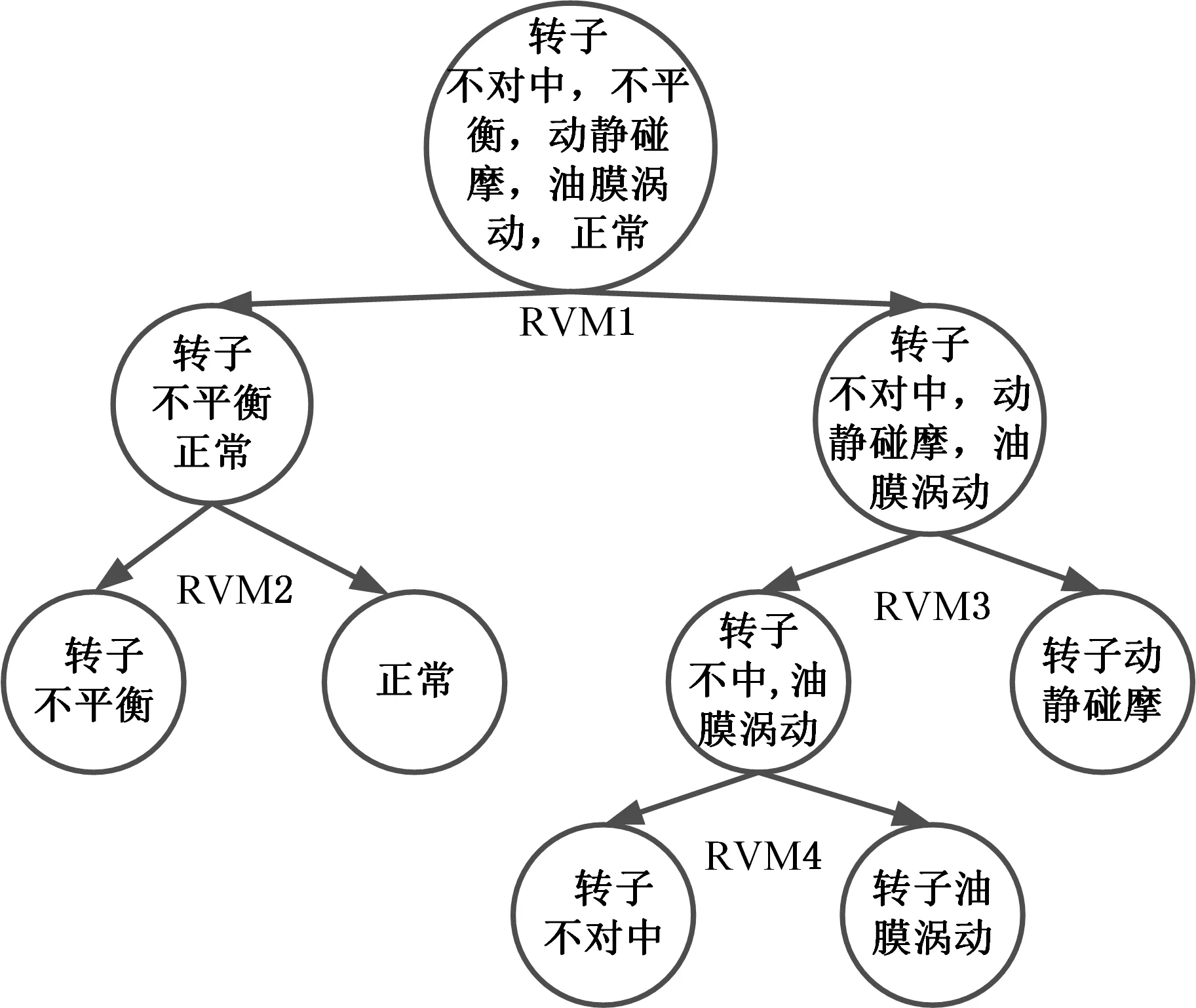
图4 高维可分性指标优化后系统图Fig.4 Optimized system chart based on high-dimensionalspace separability index

dxyRVM1 RVM2RVM3RVM4样本方差0.061 90.838 60.117 92.742 3本文方法0.137 42.140 02.946 11.076 4

表2 优化后系统的分类正确率
由表2可以看出,本文提出的高维空间可分性指标相较于传统的基于样本特征向量空间的方差指标,更能准确反映样本在高斯核空间内的可分性。本文方法优化后的系统分类准确性更高。
3.2 实验2
智能诊断方法[16-17]通过充分发掘数据间的内在关联,避免了复杂的数学建模过程,成为故障诊断技术发展的新方向。本文选用粒子群算法优化(PSO)的聚类算法对样本进行实验,实验过程首先根据训练样本间的距离相关性等特征将训练样本聚成不同类别;再根据待测试样本与训练样本间的匹配性进行划分。PSO算法中群体粒子50个,最大迭代次数为400次,结果见表3。

表3 聚类算法分类结果
对比智能诊断算法和均衡二叉树系统的诊断性能,结果见表4。由表4可以看出,基于均衡二叉树的多分类系统相较于聚类算法,分类准确率更高,时间成本更低。

表4 聚类算法和本文方法的结果比较
4 结论
(1)二叉树系统结构中,各节点的正负类选取会综合影响系统的分类精度。因此对多分类系统结构进行优化,抑制误差累积效应可以有效提高系统分类正确率。
(2)高斯核函数将样本特征向量映射到无穷维空间中寻求分类超平面。样本特征向量的方差属于低维空间中的距离度量方法,并不能有效反映高斯核空间中样本点的距离分布规律。本文引入分数范数的概念对高维空间中的距离进行度量。实验表明,本文提出的高维可分性指标相较于传统的方差指标,能更有效地判断样本在高维空间中的可分性。
(3)基于本文提出的指标进行优化后的系统,相较于智能诊断算法,在分类正确率和耗时方面也具有一定的优势。
