基于图像增强和深层CNN学习的交互行为识别*
2019-05-31徐鹏程刘本永
徐鹏程 ,刘本永
(1.贵州大学 大数据与信息工程学院,贵州 贵阳 550025;2.贵州大学 智能信息处理研究所,贵州 贵阳 550025)
0 引 言
行为识别是计算机视觉领域的一个研究热点。与图像分类相似,行为识别的目的是在一组图像序列或者视频中,让机器自动识别出未知行为的类别。行为识别在公共安全、远程医疗和虚拟现实等领域有着广泛的应用价值。Aggarwal等人[1]根据行为的复杂度把行为分为身体局部动作、简单行为、交互行为和人群行为。交互行为是较复杂的行为,近年来,研究人员提出了许多交互行为识别方法,主要有两种:一种是提取简单特征,用传统分类器分类(以下简称“简单特征法”),另一种是基于CNN识别。
简单特征法在小样本条件下表现出良好的分类性能。2010年韩磊等人[2]提出一种基于时空单词的双人交互行为识别算法,该算法从视频中提取时空兴趣点,并将聚类生成的时空码本分配给视频中各个人物。2014年Kong等人[3]提出用语义描述子对交互行为分类,该算法将交互行为分成多个部位的动作描述,通过多个部位的动作描述组合来表示某种交互行为。2015年Alazrai等人[4]提出基于解剖平面的交互行为识别算法,该算法用一种新颖的视角不变运动姿态几何描述符作为交互行为的表示。2017年Li等人[5]提出基于深度序列多特征融合的交互行为识别的算法,该算法对深度图像稀疏提取关键帧,然后融合轮廓特征和动作特征。虽然简单特征法在某些情况下能很好识别交互行为,但是常见的视频片段中人物做出的行为常常伴随遮挡、复杂背景和镜头抖动等问题,简单特征法不能很好解决这些问题。在大样本条件下,利用CNN可以较好的解决这些问题。
在视频图像处理领域,CNN主要用于图像分类,近几年ImageNet大规模视觉识别挑战赛(ILSVRC 2010~2017)[6]产生了很多优秀的CNN模型,比如AlexNet[7]、VGGNet[8]、GoogLeNet[9]和 ResNet[10]等。目前可以通过微调(Fine-tuning)的方法将CNN模型应用到双人交互行为识别研究上。早期基于CNN的交互行为识别主要使用浅层的CNN,各隐层之间都是基于全卷积计算,激活函数主要是sigmoid函数。这种方式往往需要设定过多的超参数,同时在做反向传播运算时sigmoid函数计算容易出现梯度爆炸和梯度消失等问题,因此对识别效果不太理想。Zhao等人[11]通过提取密集光流,然后输入到ResNet中训练,接着将结果输入到LSTM中训练,取得了较好的分类效果。Feichtenhofer等人[12]提出一种基于VGG-m-2048和VGG16的时域空域双CNN融合算法,在UCF101、hmdb51数据集上取得了很好的识别效果。
为了让CNN模型更好的提取交互行为特征,本文提出一种将原始视频帧进行图像增强再利用VGG16模型进行训练的算法。首先采用将原始数据集从RGB颜色空间转换到HSV颜色空间,其次根据min-max规范化算法对HSV颜色空间中S和V通道拉伸(H通道不变),然后再将数据从HSV颜色空间映射到RGB颜色空间,最后将图像增强后的数据输入到VGG16模型中进行学习训练。实验选用BIT-Interaction[3]数据集对本文算法进行验证,结果表明所探讨算法在交互行为识别上是有效的。
1 HSV颜色空间图像增强
图像增强目的是为了突出图像中不同物体特征之间的差异,通过一些方法有针对性地突出某些感兴趣特征和削弱不必要特征。数字视频由若干静态图像序列组成,根据人眼的视觉暂留原理,呈现出动态画面。因此突出视频中人物特征,只需对视频每一帧做图像增强即可。本文在数据预处理阶段图像增强流程如图1所示,其中S、V参量归一化是对S和V参量分别做min-max规范化处理[13]。

图1 视频帧图像增强流程
1.1 颜色空间
颜色空间(又称彩色模型)是在某些标准下用可以接受的方式方便对色彩加以说明的颜色表示域。本质上,颜色空间是坐标轴和子空间的说明,其中,位于系统中的每个颜色都是由单个点来表示。常见颜色空间有RGB、HSV、YUV、Lab等[14]。
1.1.1 RGB颜色空间
RGB颜色空间包含红(R)、绿(G)、蓝(B)三个颜色分量,故RGB颜色空间又称三原色模式,大多数可见光都可以由三分量组合堆叠得到。当前主流的CRT显示器和液晶显示器大都采用RGB彩色模型。RGB颜色空间将每个分量分为256个灰度级并将其归一化到0~1范围内,其中灰度值越大表明颜色越深。
1.1.2 HSV颜色空间
HSV颜色空间是根据颜色特性而创建得来的,其符合人对颜色的直观感受,HSV颜色空间有两种模型,分别是倒六角锥模型和倒圆锥模型。
以倒圆锥模型为例,如图2所示,HSV颜色空间三个参量表示色彩的三要素:色调(H)、饱和度(S)和明度(V)。色调是色彩最主要特征,是区分不同色彩的主要标准。模型横切面角度表示H(0~360°)参量,不同角度表示不同色彩,例如0°对应红色、120°对应绿色、240°对应蓝色。饱和度表示色彩的鲜艳程度,圆锥中轴到圆锥母线的水平线段代表S参量,S(0~1)越大表示该色彩越鲜艳(越靠近圆锥边缘)。明度表示色彩的明暗程度,圆锥中轴自下而上的垂直线段代表V参量,V(0~1)越大表示色彩越明亮。

图2 HSV颜色空间的倒圆锥模型
1.2 颜色空间转换关系
1.2.1 RGB转换到HSV
对三个参量取值在[0,1]的RGB图像,转换到HSV颜色空间,H、S、V的计算过程如下:

1.2.2 HSV转换到RGB
HSV颜色空间图像映射到RGB颜色空间,RGB三个参量的计算过程如下:

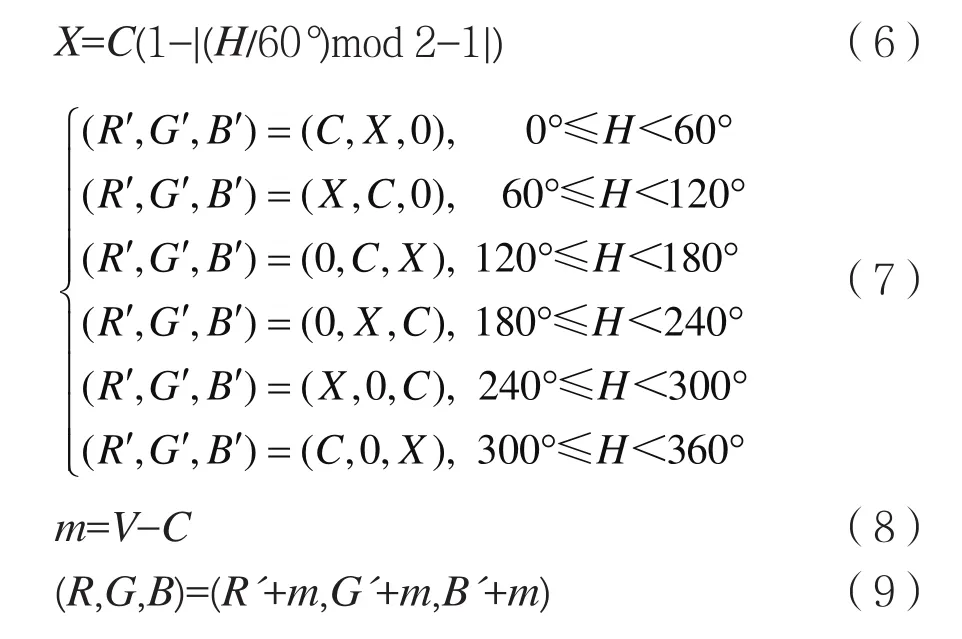
1.3 增强算法
在图像中,S和V参量的实际取值范围往往比[0,1]小,这就造成了图像中某些区域之间的对比度比较小。例如本文中图像增强的目的是增强人体(图中前景)特征,削弱背景特征。为了增大图像中各部分S或V参量的差异,对图像中各像素点S或V的实际取值范围进行拉伸,保持H不变。原图像像素点S或V值大的会更大,小的会更小。
min-max规范化(min-max normalization又称min-max scaling)是将原数据的取值范围缩放到[0,1]。HSV颜色空间图像中S参量的min-max规范化过程如式(10):
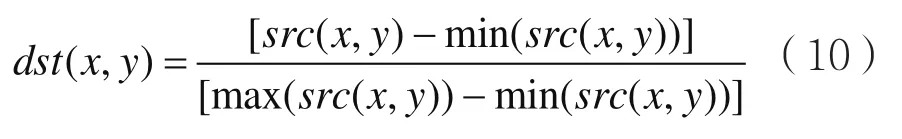
其中,src(x,y)是原始图像各像素点S参量值,max(src(x,y))和min (src(x,y))分别是原始图像所有像素点S参量的最大值和最小值,dst(x,y)是各像素点S参量min-max规范化后的值。V参量的变换过程与S参量一致。
2 深层CNN
2.1 CNN
CNN结构主要包含:卷积层、激活函数、池化层、全连接层和soft-max层。卷积层的主要作用是提特征,浅层卷积层提取低级图像特征,深层卷积层提取更抽象的特征。激活函数将卷积层的输出结果做非线性映射处理,从而增加网络的表达能力,常见的激活函数有sigmoid、tanh和ReLU[7]等。池化层在保留了上层特征图主要特征的同时还减少了下层的参数,其主要有max pooling和average pooling两种池化方式。全连接层把提取到的特征映射到样本的标记空间,起到分类器的作用。soft-max层将最后一层全连接层的输出结果映射到0~1范围内,根据得分高低判别分类,soft-max层神经元数目取决于样本的类别数。损失函数对权重(ω)和偏置(b)求偏导,根据BP算法更新ω和b,使损失函数值最优。
2.2 VGG16
2014年牛津大学视觉几何团队(Visual Geometry Group)提出VGGNet,并在当年的ILSVRC获得分类任务第二名和定位任务第一名。VGGNet在AlexNet基础上发展而来,首次使用小卷积核、小池化核同时增加了网络层数[8]。VGGNet主要有VGG16和VGG19两种网络模型,二者结构相同,但VGG19相比VGG16在图像分类上的识别率上提升不明显且增大了模型参数,为减小计算量,本文选用的网络模型是VGG16。
VGG16结构如图3所示,网络一共16个卷积层(包含最后三层全连接层),5个池化层和一个soft-max层。模型输入为224×224的三通道图片。卷积层均为3×3的小卷积核,滑动步长为1。堆叠2个或3个3×3的卷积核计算效果等于1个5×5或7×7的卷积核, 但计算量大大降低并且经过多次非线性变换后模型对特征的学习能力更强。卷积层输出结果输入到ReLU激活函数中,ReLU相比sigmoid函数有计算量较小、减少梯度消失、稀疏网络从而缓解出现过拟合现象等优点。池化核(本文使用的是max pooling)大小为2×2,滑动步长为2,其对特征降维的同时保留了原始特征的属性。最后是三个通道数分别为4 096、4 096和1 000的全连接层。soft-max层对ImageNet1000种类别分类。因本文使用的数据库有8个类别动作,需要微调FC1000和soft-max层。

图3 VGG16网络结构
3 实验结果与分析
为了对比本文方法和文献[12]方法在交互行为识别上的实验结果,本文选用的数据集是北京理工大学的交互行为数据集(BIT-Interaction)[3]。该数据集包含八类交互动作(Bend、Box、Handshake、Hifive、Hug、Kick、Pat、Push),每类动作包含50段短视频。这些视频均是在不同自然场景下拍摄的,镜头固定。我们对该数据集多次实验取平均值,实验分为3个split,其中括号里指扩充数据集的分组。split1:15~50(29~100)为训练集,1~14(1~28)为验证集,101~114(101~128)为测试集;split2:1~14 和 29~50(1~28 和 57~100)为训练集,15~28(29~56)为验证集,115~128(129~156)为测试集;split3:1~28 和 43~50(1~56 和 85~100)为训练集,29~42(57~84)为验证集,129~142(157~184)为测试集。

图4 BIT-Interaction数据集
3.1 扩充数据集与图像增强
原始数据集在视频分帧后得到的图片数量较少,原始视频帧作为输入进行CNN训练容易出现过拟合问题。为解决上述问题,我们对数据集进行扩充。常见扩充数据集的方法有:翻转、旋转和拉伸等,本文采用镜像翻转和旋转的方法对数据集扩充,扩充后数据集的训练集和验证集每类动作共包含100个的帧序列。
从数据集中任选三张图片及对应图像增强后的图片如图5所示。

图5 原始视频帧(第一列)与图像增强帧(第二列)
从这两列图像中可以看出图像增强后的图像凸显或保持了人物轮廓,丰富了人物的纹理信息,增大了人物与背景的对比度,同时背景的纹理信息有所减少,例如图5(d)与图5(c)相比远处树木和建筑信息较少,人物细节信息更突出。虽然原始图像经过本文中的图像增强算法后不能准确反映真实场景信息,但凸显了人物(前景)特征,有益于接下来的CNN模型提取特征。
3.2 VGG16训练与测试
CNN模型选用在ImageNet预训练好的VGG16模型,针对现有分类问题进行微调(fine-tuning),原因是自己从头开始训练VGG16容易出现问题,fine-tuning初始化自己的网络能使网络较快收敛。把输入图片宽高随机修剪为224×224,为提高内存利用率,batchsize设置为256。为了减小网络收敛时在最优值附近小幅度波动,而不设定固定学习率,采取随着迭代次数增加逐渐减小学习率的方法,不同阶段学习率分别设置为:10-2、10-3、10-4。表1是原始数据集、数据集扩充和图像增强300次快拍训练得到模型在测试集上的准确率与平均准确率结果。

表1 测试识别率和平均识别率 /(%)
如表1所示,三种数据集的平均识别率分别为25.40%、95.01%、97.70%。可以很明显看出扩充数据后的识别准确率要远远好于原始数据集,原因是深层CNN训练数据集过少容易出现过拟合现象。在数据集样本足够大的情况下,对数据集进行图像增强操作的识别准确率均比未处理图像的提升了2.69%,这说明原始数据在图像增强后能够更好地凸显图片中人物特征。
近几年交互行为识别方法与本文方法识别准确率对比见表2,在数据集足够大的情况下,利用深度学习研究双人交互行为识别有很大的优势。另外,本文方法在数据预处理阶段对输入图像做图像增强处理进一步提高了识别准确率。

表2 几种方法在BIT-Interaction数据集上的识别率
4 结 语
本文在数据预处理阶段,为解决数据集不足的问题,对原始视频帧镜像翻转和旋转,提升了VGG16在BIT-Interaction数据集上的识别准确率。将RGB颜色空间映射到HSV颜色空间,对S和V参量分别做min-max 标准化处理,将所得结果映射到RGB颜色空间上作为CNN的输入,进一步提升了识别准确率。本文使用在ImageNet训练好的VGG16对本文需要解决的问题做fine-tuning,节省了对前期对网络参数训练的时间。
总体而言,深层CNN对双人交互行为有着较高的识别准确率,但严重依赖数据集样本数量。本文的在后续的工作中将适当减少网络层数,优化网络参数,使其对原始视频帧也有较高的识别率。
