大数据时代高速铁路交通决策系统研究
2019-05-27王翠玲
崔 蕾,王翠玲
(烟台职业学院 信息工程系,山东 烟台264670)
我国高速铁路系统的规模正逐步增大,运营里程数也日益增加,高速铁路已经成为了人们出行的重要交通工具之一.随着高速铁路网络的不断扩大,客流量不断增多,我国高速铁路客票系统包含了大量的销售数据,急需采用更有效的方法对这些数据进行有效地分析,从而挖掘出其中蕴藏的客流规律.传统的高速铁路交通决策系统的分析主要采用Excel等软件对票务销售数据进行分析,通过柱状图、折线图等图形进行辅助分析,但这些方法无法有效地挖掘出高速铁路客流数据的潜在规律.
近年来,大数据技术发展非常迅速,能够对高速铁路的客流进行有效地挖掘,从乘客的需求出发,通过对已有的高速铁路交通系统中的历史数据进行分析和挖掘,寻求其中蕴含的规律,构建更为高效的决策系统.高速铁路交通系统的影响因素较多,例如铁路线路、固定行车设备等,如果无法实时地掌握客流动态,将出现客流流失、运输旺季系统紧张、运输淡季运输惨淡等情况.为此,高速铁路交通一直致力于运能和运量的合理协调,但仍缺乏一种更有效的交通决策系统.随着科学技术的快速发展,大数据在高速铁路交通系统的决策分析中具有非常重要的意义.大数据技术能够提供全面的分析客流分析的工具,为交通系统的决策分析提供有力的技术支持.利用数据技术能够探索高速铁路客流规律,对高速铁路交通系统特征进行仿真分析,可以有效地预测高速铁路交通的需求.在大数据时代,高速铁路交通系统储存着大量的多元化数据,可利用这些多元化数据构建基于大数据的高速铁路交通决策系统[1-2].
1 高速铁路交通决策系统的大数据属性偏序约简模型
定义(S,T,S0,L)为四元组的初始状态变迁系统,S表示全部状态的集合,T表示变迁集合,S0表示起始集合,L 表示标记函数,对于 α∈T,存在 α∈S×S.对于变迁 α∈T.当存在一个状态 α∈S′,能够使 α(S,S′)成立,此时,α在S′处于激活状态,否则,α在S′处于非激活状态,在S′处全部激活的变迁集合定义为Senabled.对于不同的状态S′,仅选择全部激活变迁集合Senabled的一个子集,定义其为充足集Sample,主要原因是要通过Senabled构建全状态图,并不属于非约简状态图[3].
若独立关系I⊆T×T具有对称性和反自反特性,对于任意s∈S,满足条件,即激活性条件:当(α,β)∈Senabled,则 α∈(β(s)enabled),交换性条件:当(α,β)∈Senabled,则 α( β(s))=α( β(S)).
状态映射到初始子命题集合的标记函数定义为L∶S→2Ap,已知命题集Ap′⊆Ap和变迁α∈T,对于s,s′∈S,若存在方程:s′=(α(s)),L(s)∩Ap′=L(s′)∩Ap′,则此时不可见.
若刻画在Sstutterig不发生变化,通过交换性和不可见性能够防止某些状态的出现,基于这一理论获得任意状态下的充足集合Aample,偏序约简算法通过充足集合Aample构建约简的状态图,针对不同的不涉及偏序约简算法的路径,在约简图中均存在和Sstutterig等效的路径,能保证约简状态图和全状态图关于Sstutterig等价.
确定充足集合Aample的约束条件:
条件1:Sample=Φ当且仅当Sample=Φ.
条件2:在全状态图中,起始于S的路径,均满足如下的条件:存在和Sample中变迁存在依赖关系的变迁,此时该变迁无法先于Sample中变迁进行操作.
条件3:当s不能完全展开,则存在一个变迁α∈Sample为不可见.
条件4:当一个回路存在一个状态,该状态下存在一个激活的变迁α,而该回路上全部状态s均不处于 Sample内,则该回路不存在[4].
通过偏序约简算法能有效地使高速铁路交通决策系统模型中的状态数量降低,减少算法搜索状态空间的规模.因为在高速铁路交通决策系统中存在能同时进行操作的变迁关系具有交换性特点,即当变迁关系通过不同的次序进行操作能获得一样的状态,从不同组合顺序变迁关系组织中选择一组即可.对高速铁路交通决策系统进行偏序约简分析的步骤如下:①可将高速铁路交通决策系统的属性看成变迁关系,属性值可视为变迁关系下的转换状态;②在任意顺序变迁关系组的转换下获得一样的结束状态时的变迁序列中删除多余的状态,仅保留主要的路径;③对主要路径的变迁关系进行解码,从而获得相应的输出属性[5].
高速铁路交通决策系统的属性偏序约简模型:高速铁路交通决策系统的信息决策表定义为三元组S=(U,A,V),其中 U 表示论域,用于描述全部对象的有限非空集合,满足条件:A=C∪{D},D∉C,C表示条件属性组成的集合,D表示决策属性.V表示属性a的值域[6],表达式为:
假定高速铁路交通决策系统信息决策表中∀ui∈U,初始状态定义为O,∀ci∈C(i∈(1,n),其中i表示正整数),Vci在变迁关系ci作用下的中间转换状态,VDi为O经过变迁{ci,D|i=1,2,…,n}转换后的结束状态[7],转换过程为:
假设在高速铁路交通决策系统信息决策表中有若干对象,使决策信息从同一状态量经过多个变迁关系Vci+1,Vci+2,…,Vci+k变换后获得若干对象,所对应状态量的值相等,同时在转换阶段没有值相等的状态量,即存在多个 ui∈U,使符合以上条件,此时能删除多余状态Vci+1,Vci+2,…,Vci+k.
2 高速铁路交通决策系统的仿真分析
2.1 高速铁路交通决策系统大数据分析算法流程
针对一个独立事件,产生机制通常都是任意的,但对高速铁路交通决策系统进行描述时,应该以独立事件的产生过程为依据综合权衡,所以就将形成庞大的空间状态.利用偏序约简算法能深入地分析高速铁路交通决策系统大数据,能有效地降低高速铁路交通决策系统的状态数量,有效地降低空间规模,且在系统分析时,能形成交换性特征.偏序约简算法还能对系统的不同属性进行深入分析,获得有效的决策.基于大数据偏序约简模型构建高速铁路交通决策系统的算法流程为:
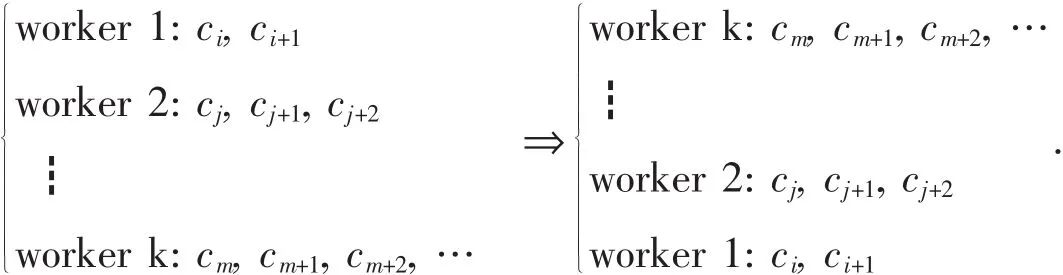
步骤1:依据决策属性D的k种取值,把高速铁路交通决策数据划分为k个等价类[8],表达式为:
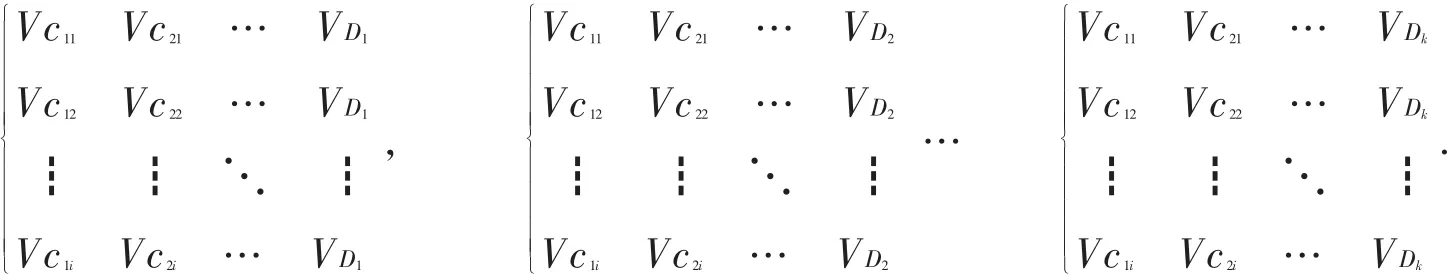
步骤2:调用k台worker进行属性值计算,并且从高到低进行排序,这样能够按照顺序通过集合中属性集按次序对高速铁路交通决策数据进行有效地分类,计算出相应的决策值,即:
步骤3:对k个等价类进行并集操作,操作模式为:
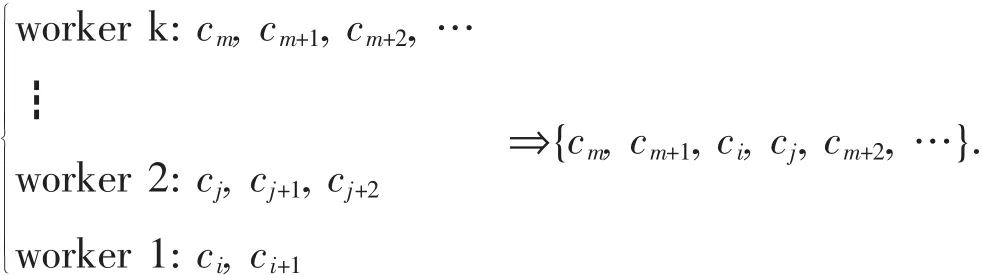
步骤4:依据以上步骤获得的属性值和排序结果输出约简结果.
2.2 实例分析
为了验证高速铁路交通决策系统的大数据分析算法的有效性,利用设计的算法进行仿真分析.以某市高铁火车站为例,研究该火车站从10:10-12:20这一时间段旅客换乘决策分析.火车站在该时间段一共有10列高速列车到站(见表1).
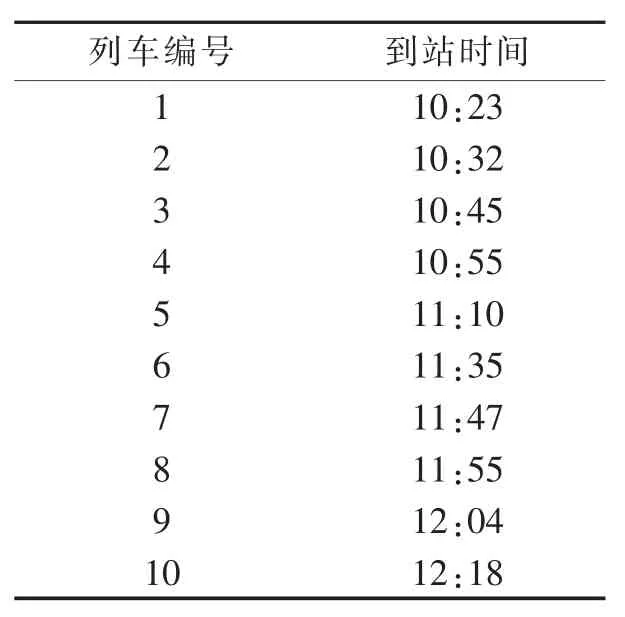
表 1 某火车站在 10∶10-12∶20时间段到站的列车表
客流水平速度分布、客流楼梯下行和客流楼梯上行速度分布分别见图1~图3.从图1可以看出,客流水平速度在0.9~1.1 m/s之间的比例最高;从图2可以看出,客流楼梯下行速度在1 m/s的比例最高,达到了42%;从图3可以看出,客流楼梯上行速度在0.7 m/s时的比例最高,高达66%.从图1~图3可得客流水平速度、客流楼梯下行速度和上行速度的分布规律,依据客流不同行为的速度预测出高峰时期,掌握客流的分布情况.

图1 客流水平速度分布图
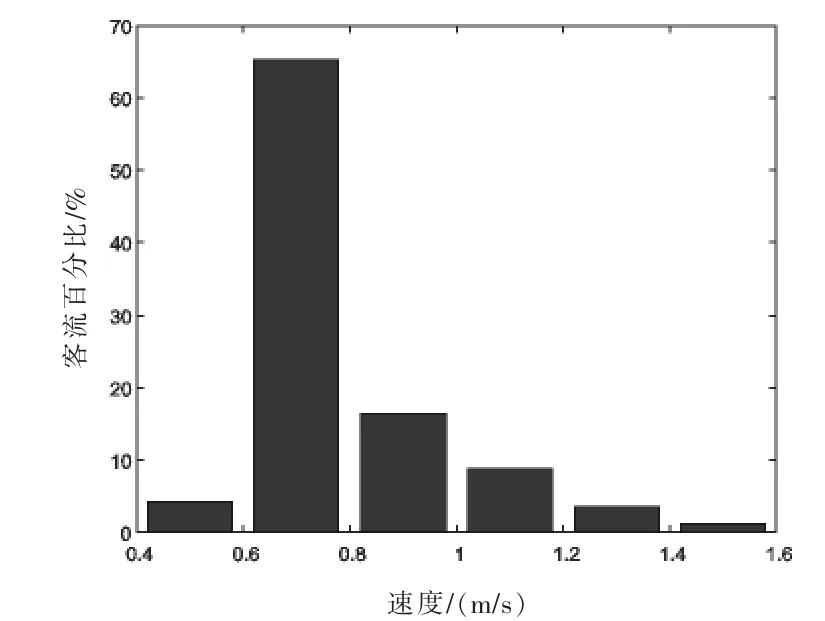
图3 客流楼梯上行速度分布图
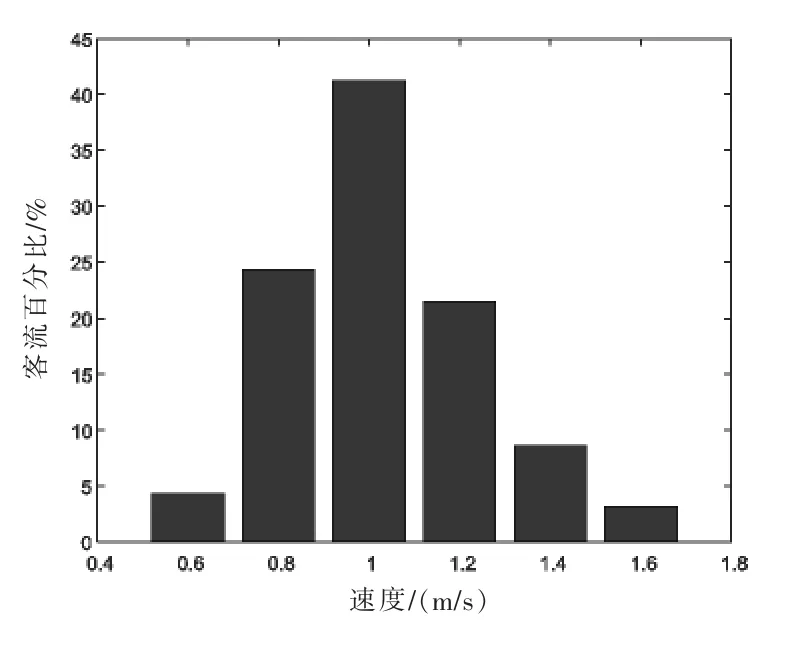
图2 客流楼梯下行速度分布图
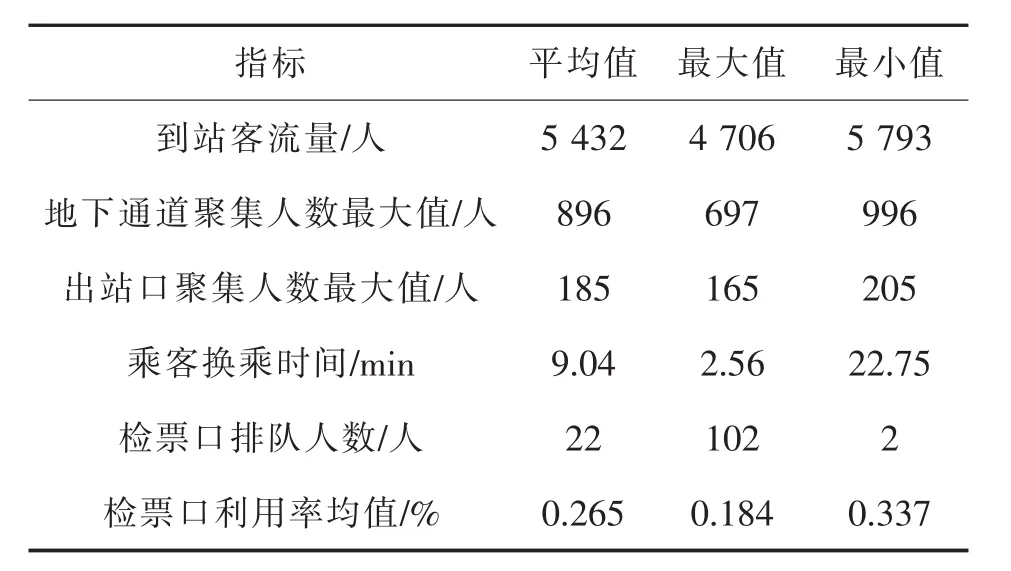
表2 火车站高速列车决策系统
利用设计的大数据分析算法对火车站的决策系统进行分析(见表2).到站客流量平均值处于5 432,地下通道聚集人数最大值为896,出战口聚集人数最大值为185,这些数据指出了火车站高速列车客流情况,能确定出高峰进站和出站的客流压力.乘客换乘时间为9.04 min,检票口排队人数为22人,检票口利用率均值为0.265,根据这些速度可推算出高峰客流量,获得换乘位置和检票口的客流密度,客流较为均匀,较为松散,不易发生拥堵现象.
根据仿真结果可知,利用大数据分析算法可有效地掌握高速铁路客流量的分布情况,做出恰当的交通决策,能有效地控制到站客流量、地下通道聚集人数最大值、出站口聚集人数最大值、乘客换乘时间、检票口排队人数及利用率,为乘客提供更优质的服务,降低事故的发生率.
3 结语
基于大数据分析的高速铁路交通决策系统能有效地管理综合信息,对高速铁路事故成因进行分析,能对客流疏散进行合理规划,并且能够对高速铁路交通安全进行预警,实现对高速铁路交通系统有效决策,有利于高速铁路管理者提出合理的事故预防措施和安全管理措施,为高速铁路的安全管理提出优化决策.
