随机森林模型和决策树模型在肝硬化上消化道出血预后中的应用*
2019-05-24于大海罗艳虹刘近春张岩波
于大海 李 金 罗艳虹 刘近春 张岩波△
1.山西医科大学卫生统计教研室(030001) 2.山西医科大学第一医院
【提 要】 目的 探讨随机森林模型和决策树模型在肝硬化并发上消化道出血患者预后评估中的应用。方法 利用logistic回归方法从肝硬化住院患者病历资料中筛选出与并发上消化道出血有关联的变量;以筛选出的变量作为输入变量,以是否出血作为结局变量,分别建立随机森林、决策树和传统logistic回归模型,通过受试者工作特征曲线(ROC)来评价三种模型的性能。结果 logistic回归、决策树和随机森林模型在测试集中的准确率分别为81.5%、75.1%和88.9%,三种模型的ROC曲线下面积(AUC)分别为0.854、0.720和0.909;在随机森林模型的变量重要性评分中,血糖、胆固醇、血清钾、总蛋白、碱性磷酸酶、尿素氮等指标得分较高,提示这些指标或有临床意义。结论 随机森林模型在肝硬化上消化道出血患者的预后评估中具有较高的应用价值。
上消化道出血是肝硬化患者最常见和最危及生命的并发症之一,6周总死亡率为24%,1年总死亡率为40%[1,2]。上消化道出血患者的复发率高[3],这不仅会增加肝硬化患者的死亡风险,还会引发肝性脑病、感染、肝肾综合症等并发症。因此做好肝硬化上消化道出血的疾病风险和预后评估,可以有效减少上消化道出血及相关并发症的发生[4]。数据挖掘作为一种新兴的统计分析方法,被广泛应用于生物医学领域当中,它可以从复杂的医疗数据中提取有价值的信息,在疾病的诊断、治疗和预后等方面有极好的表现。
本研究采用肝硬化住院患者病历资料,探索随机森林和决策树模型在肝硬化患者并发上消化道出血预后评估中的应用价值,并与传统logistic回归模型进行比较,以期为疾病的早期干预提供辅助决策。
资料与方法
1.研究对象
本研究数据资料来源于山西省太原市某三甲医院消化内科,研究对象为2006年1月1日至2016年12月31日期间确诊为肝硬化的住院患者。研究对象纳入标准为:(1)第八版《内科学》中提到的肝硬化诊断标准[5];(2)有完整实验室检查资料的患者;排除标准为:(1)出血的诱因不是肝硬化患者;(2)入院前已经发生过出血的患者;(3)诊断为肝硬化上消化道出血后因自身或者其他原因出院的患者。
2.研究方法
(1)资料收集
由经过培训的课题组成员通过查阅医院病案室中的电子和纸质病历,收集资料主要包括患者的一般人口学资料、临床症状体征、实验室检查、辅助检查和用药情况等信息。利用EpiData(Version3.1)软件,自行建立肝硬化资料数据库。对数据资料进行双人独立录入,并进行逐一校正,期间共得到有效病历942份,其中肝硬化上消化道出血病历276份,占比为29.3%。
(2)数据处理
本研究数据采用分层抽样的方法,从上消化道出血病例和非上消化道出血病例中分别抽取2/3样本组成训练集用于构建模型,将剩余的1/3样本作为测试集用于评价模型性能。将变量筛选后得到的21个特征变量作为输入变量,将是否发生上消化道出血作为结局变量,在训练集中分别建立随机森林、logistic回归和决策树模型,最终在测试数据集中应用各模型对上消化道出血进行预后评估,P≤0.05被认为差异有统计学意义。
(3)logistic回归模型的建立
使用训练集在glm()函数下构建logistic模型;利用step()函数对构建的初始logistic模型进行基于AIC准则的逐步回归变量筛选。
(4)决策树模型的建立
本研究采用以下参数来建立初始决策树。tree0:叶结点的最小样本量参数minbucket设置为20;结点的最小样本量参数minsplit设置为20;进行交叉验证的剪枝折数参数xval设置为10;生成决策树的最大深度参数maxdepth设置为20;指定最小代价复杂度剪枝中的复杂度参数CP设置为0.01。
(5)随机森林模型的建立
在RStudio环境下,随机森林的建模过程中主要包含两个重要参数:ntree(树的数目)和mtry(随机选择特征的数目)。经验证,参数ntree设置为500,mtry设置为4时,随机森林模型表现最佳。
(6)统计学处理
模型的建立与评价均通过软件R i386 3.3.2实现:应用rpart程序包来建立决策树模型,随机森林模型的建立应用randomForest,利用glm()建立logistic回归模型。
结果
在模型训练之前,利用logistic回归进行自变量筛选:在训练数据集中,以肝硬化患者是否并发上消化道出血为因变量,以所收集病历资料中共86个指标为自变量建立logistic回归模型,检验水准设置为0.05。具体结果见表1。
1.logistic回归模型
将筛选出的变量纳入logistic回归模型,并在测试集中完成模型性能评价,与真实发生了上消化道出血的情况进行对比。进入模型的各变量见表2。
2.决策树模型
在本研究中,决策树模型选择信息熵作为分裂属性的度量标准。
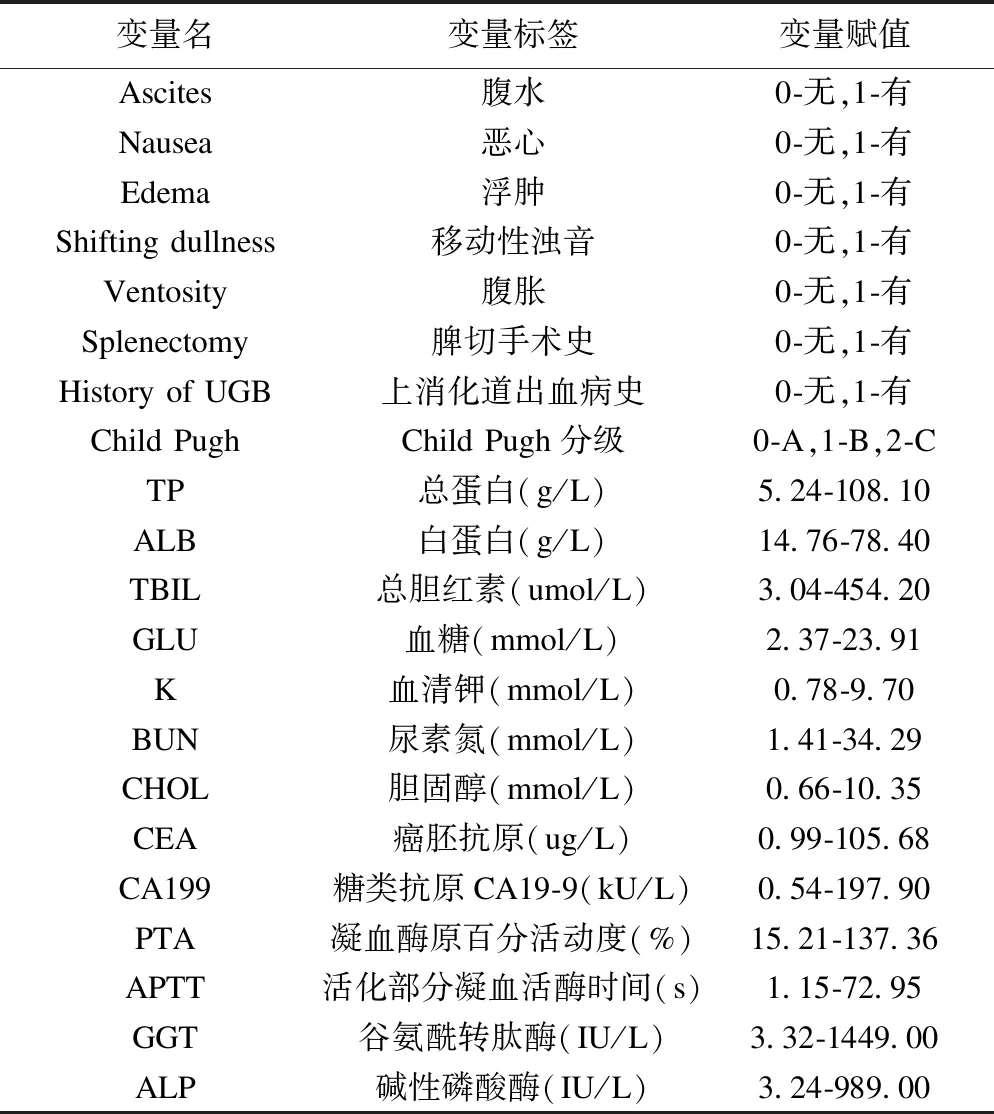
表1 各输入变量赋值表
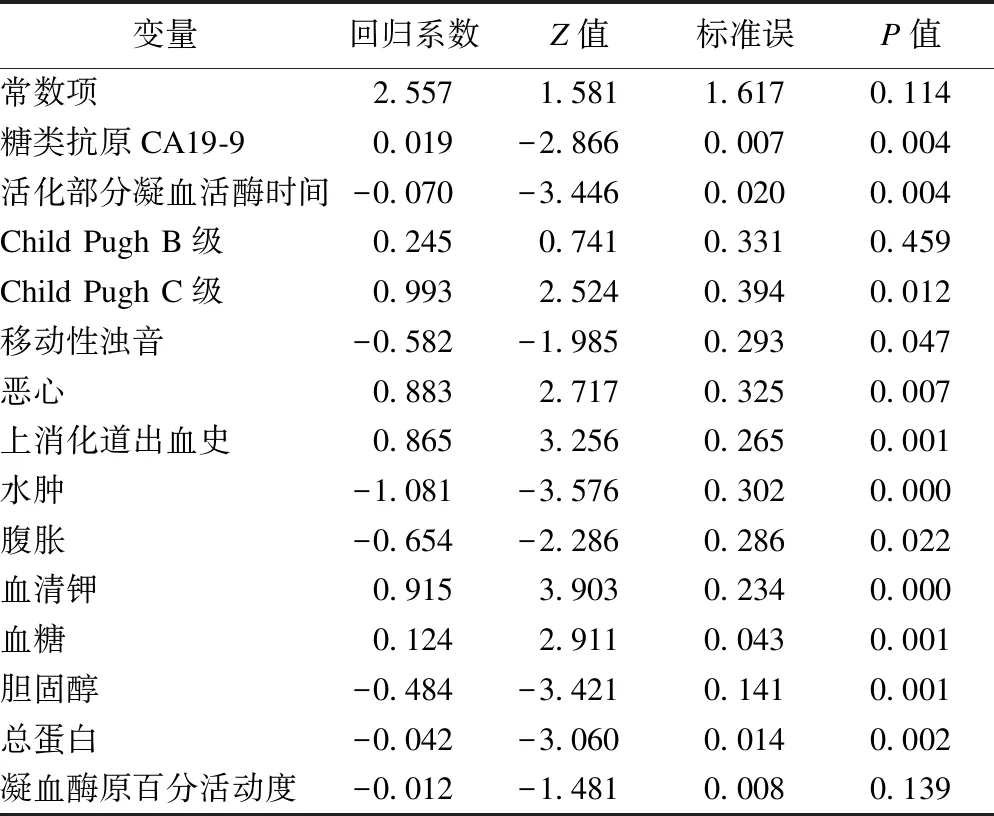
表2 logistic回归模型结果
在决策树的前剪枝过程中,前剪枝参数主要包括maxdepth、minbucket、minsplit等,在验证数据集中,通过选用不同的前剪枝参数来进行决策树模型的建立,结果发现改变前剪枝参数对决策树模型的准确度影响不大。本研究主要对决策树后剪枝过程中的最小代价复杂度参数CP进行选择,具体结果见表3及图1。
在CP值的选择原则中,通常考察模型的预测误差及其标准误。由表3可知,当分裂次数为5时,模型的预测误差最小为0.7746,由此建立CP值为0.025的决策树模型tree_cp1;当分裂次数为2时,决策树模型的树节点数为3(分裂次数+1),此时树模型的复杂性在所有模型中最低,由于CP值必须在0.0462~0.1590之间取值(本例中将CP值选为0.05),由此建立CP值为0.05的决策树模型tree_cp2;同时建立不进行最小代价复杂度剪枝的常规树模型tree_cp0。将上述三种决策树模型在测试集上进行预测性能的比较,结果显示tree_cp1的灵敏度和特异度之和最大。
在上述参数条件下进行建模,所得模型的灵敏度较低,因此我们将惩罚因子引入模型(通过损失矩阵loss实现)。本研究分别设置了1、1.5、2、2.5和4倍代价的损失矩阵,经测试数据集验证,c(0,3,1,0)损失矩阵拥有最高灵敏度(73.6%)。将其可视化呈现如图2所示。

表3 不同分裂次数时,决策树模型的预测误差估计及复杂度参数CP值

图1 预测误差随复杂度参数CP值的变化
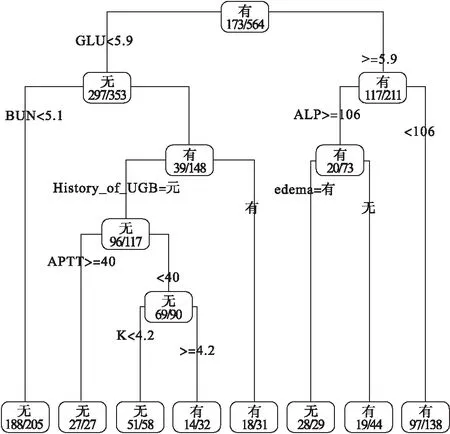
图2 决策树模型的可视化
3.随机森林模型
(1)棵数参数ntree的选择
将树的棵数分别设置为200、400、500、600和800,通过验证数据集验证,对不同树棵数的随机森林模型进行预测性能的比较,各模型性能具体结果如表4所示。
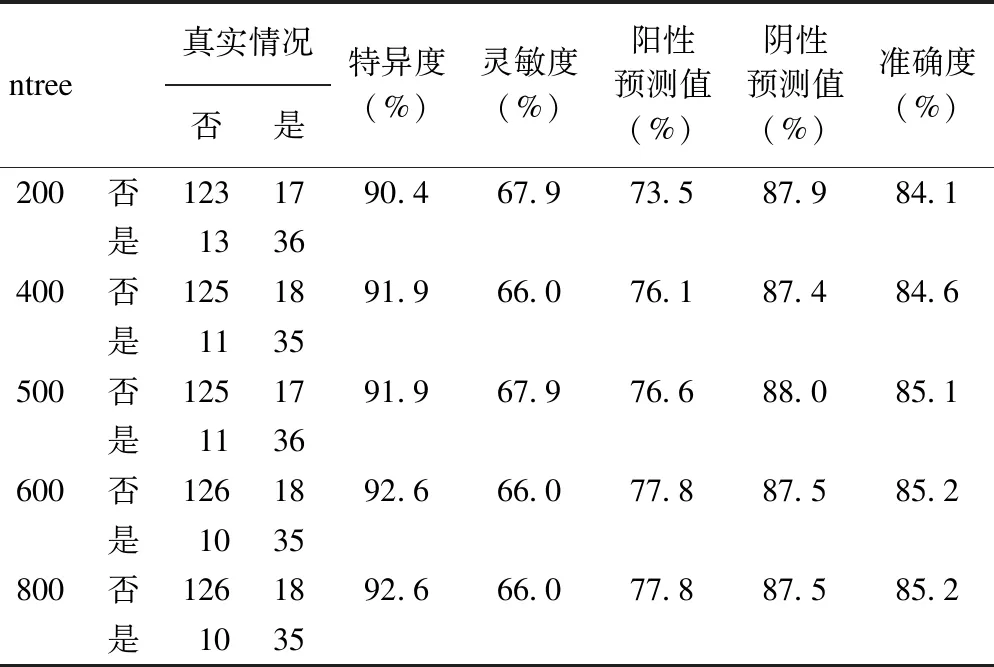
表4 不同树棵数的随机森林模型之预测性能比较
从表4中可以看出,五个不同参数模型的预测效果相差不大,当ntree≥500以后,模型的各项指标均趋于平稳,因此我们选择500作为参数ntree的值来进行建模。
(2)随机选择特征数目参数mtry的选择
本研究数据中共筛选出特征变量(自变量)21个,通常情况下,每个随机森林模型包含[log2(p)+1]个随机特征(p为特征变量个数),因此本研究中参数mtry应设置为5,我们将mtry分别设置为4、5、6、7、8、10在验证数据集中进行建模,各不同参数模型性能具体结果如表5所示。
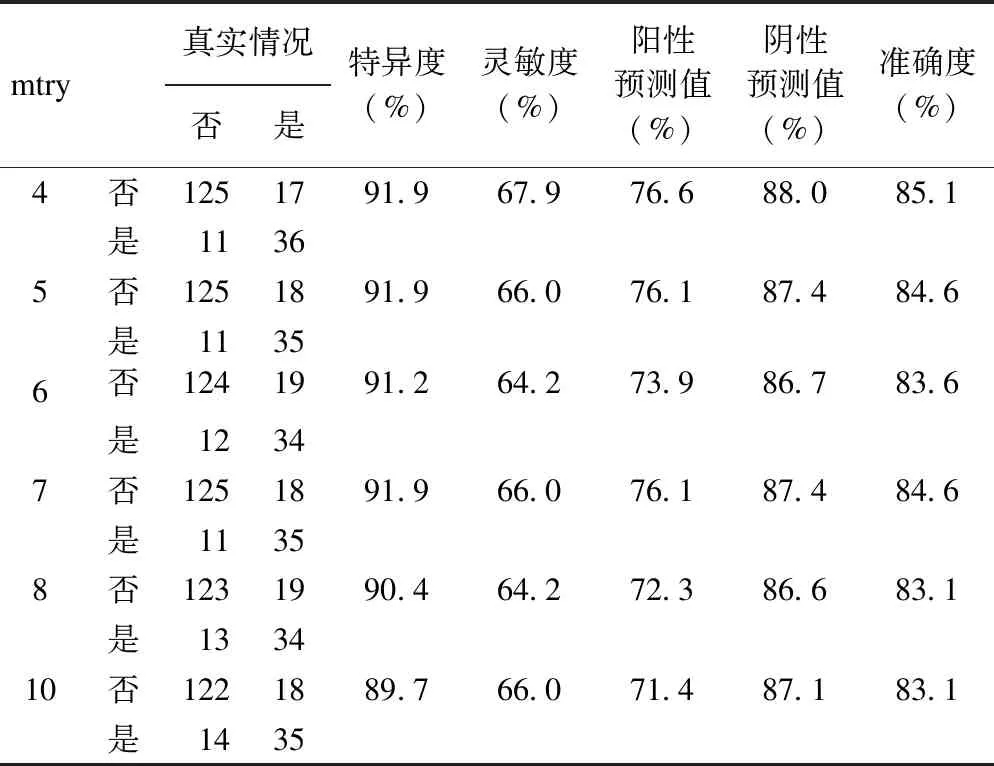
表5 不同特征选择数的随机森林模型的预测性能比较
结果发现,当随机特征选择数目参数参数mtry设置为4时,五个模型各评价指标都处于最高水平,所构建随机森林模型为最佳模型。
(3)输入变量重要程度度量
如果某些输入变量对结局有重要影响,那么在这些输入变量的取值上随机添加噪音以后,将对结局的输出结果有显著性影响。各输入变量对随机森林模型总体预测准确度的影响情况如表6所示。

表6 输入变量重要性测度
由表6可知,血糖、胆固醇、血清钾、总蛋白、碱性磷酸酶、尿素氮等指标对随机森林模型准确度影响较大,提示这些指标或有较大的临床意义。
4.三种模型性能的比较
将最终logistic回归模型、随机森林模型和决策树模型,在测试数据集中进行测试,并将测试结果与真实情况进行对比,结果如表7所示。
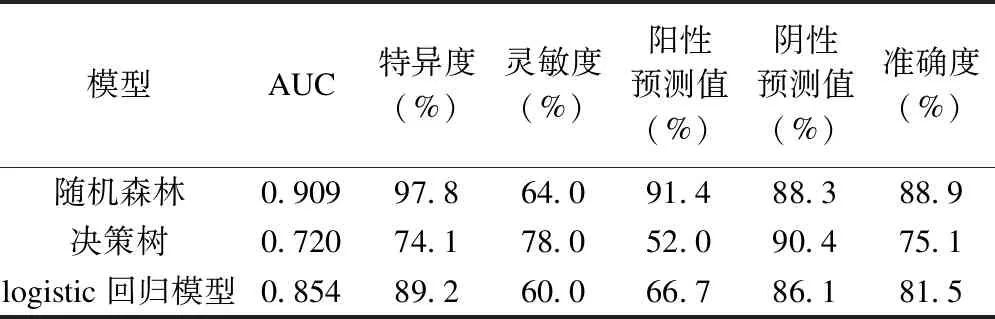
表7 logistic回归、随机森林和决策树模型在测试集中的模型性能比较

图3 logistic、决策树和随机森林模型在测试集中的ROC曲线
由表7中各项指标可知,logistic回归模型表现一般;决策树模型的灵敏度(78.0%)和阴性预测值(90.4%)为三模型中最佳,但其他指标均较低,AUC值仅为0.720;随机森林模型的阳性预测值、特异度和准确度较其他两种模型表现出色,同时随机森林的AUC最高为0.909。ROC曲线图中,曲线下面积越大即AUC取值越大,说明模型性能越好。综上所述,随机森林模型和决策树模型在肝硬化上消化道出血预后评估中都有不错的表现,并且在很多方面优于传统的logistic回归模型,可为肝硬化并发上消化道出血患者的预后与预防性治疗提供借鉴。
讨论
肝硬化并发上消化道出血以其病死率高、复发风险高、并发症多等特点,被国内外学者广泛关注。通过模型构建对肝硬化上消化道出血进行预后评估,为上消化道出血患者的干预和治疗提供合理建议,有利于延长患者的生存期,提高患者生命质量。目前针对肝硬化上消化道出血的研究,大多数学者通过评分系统或预后指数来预测肝硬化患者发生上消化道出血的可能[6-10]。本文通过回顾性的方法收集住院患者病历资料,从病历资料中筛选变量,应用随机森林、决策树和传统logistic回归三种算法构建不同的预后模型,结果表明,随机森林模型和决策树模型的综合性能优于传统logistic模型,为探索肝硬化上消化道出血的发生发展提供了新的方向,具有重要的理论意义和临床价值。
1.传统logistic回归
logistic回归适用范围广,应用灵活,对于特定的回归问题来讲,它的表现甚至会优于某些相对复杂的机器学习算法。在本研究中,最终logistic模型的准确度为81.5%,高于决策树模型(75.1%)。logistic回归的分析结果展现了LogitP对自变量的数量依存关系,但在交互作用方面的处理效果不如决策树和随机森林模型[11]。
2.决策树
决策树算法是一种基于树结构进行决策的机器学习算法,它呈现倒置的树型,一般由一个根结点、若干内结点和叶结点组成,其中根结点包含样本全集,叶结点表示分类结果,剩余结点则对应于属性决策[12]。决策树的生成过程遵循“分而治之”的原则[13]。它最重要的特征是将一个复杂的决策过程转化为一系列简单的决定,以提供一个通俗、易懂的解决方案[9]。
在进行数据分析时,变量量纲、离群值以及有偏分布对决策树模型的影响不大,但有些情况下,决策树模型处理数值型输入变量的方式会造成有价值数据的损失[14]。此外模型参数、训练数据集和测试数据集的比例,不合理数据的处理等因素,对决策树模型的综合性能都有一定的影响[15]。不同于随机森林的“黑箱式”模式,决策树模型更加简明清晰,通俗易懂,它的每一个分支都可以被重新定义,这一特点为复杂的临床研究环境提供了重要契机。
3.随机森林
随机森林(random forests,RF)是一种以决策树为基分类器的集成算法。随机森林的每个结点在选择划分属性时,从全集中随机抽取一个子集(通常取[log2(m)+1]个属性,m为属性总数),选取该子集中的最优属性。在基决策树的建立过程中,对输入数据进行列采样,最终模型的预测结果由多个决策树的分类结果投票决定。不同于决策树算法的是,在进行Bagging集成的过程中引入随机特征选择与树的完全分裂,增加了结果的多样性[12]。
较传统logistic回归方法,随机森林通过随机特征选择平衡了样本误差,较仅以单一测试样本进行拟合的logistic模型结果更具说服力。与其他机器学习算法相比,随机森林具有以下几个优点:随机特征选择思想使得随机森林相比于其他分类器(包括判别分析,支持向量机,神经网络等)表现的更优秀,并且它在处理过拟合问题上也十分得心应手[16];随机森林模型对缺失数据和噪声的有效处理也是许多模型无法做到的[17];它只选择很少一部分最重要的特征,因此它在处理特征数目或者样本量极大的问题时,具有较好的表现;对于大部分的数据问题来说,它都是有效的通用模型[18]。
4.病历数据在疾病预后评估模型建立中存在的不足及解决方法
医疗大数据可以从各种影像图像、病人访谈、实验室检查及医生的观察和解释等资料中获取,患者病历中往往会对上述资料进行详细阐述,这些重要的临床数据与患者的诊断、治疗和预后都有着密不可分的关系[19]。
但病历数据的二次利用过程中可能存在以下缺点:(1)调查对象为固定医院患者,选择偏倚无法避免;(2)病历资料多为二手数据,不同患者的病历存在差异以及课题组成员的录入问题等因素往往会导致数据质量参差不齐,导致构建模型效果欠佳;(3)在模型构建过程中,非结构化数据未得到充分利用。非结构化数据是相对于结构化数据而言的,其数据结构不规则、不完整,格式多样,没有特定的数据模板。病历中的非结构化数据主要包括住院患者治疗过程中所产生的影像、切片等图像资料,同时还包括病人主诉、病人护理情况、主治医师意见等文字资料,这些资料中都蕴含着大量宝贵的医学信息,如果不能被有效利用,将造成严重的资源浪费。
本研究将会继续从以下几个方面对模型加以改进:(1)在模型构建过程中,充分利用非结构化数据,通过引入基于NoSQL的非结构化数据管理系统,完善电子病历系统;(2)改善模型识别能力,同时引入深度学习算法,提高模型性能;(3)通过患者随访不断进行数据更新,扩展数据的纵向跨度;(4)将调查对象范围继续扩展,如扩展到下级医院、社区服务中心等,以期控制选择性偏倚。
