一种基于遗传算法和神经网络的硬判决译码方案
2019-05-23周湘贞
周湘贞
(郑州升达经贸管理学院 信息工程系, 郑州 451191)
1 背景
时至今日,纠错码技术已成为实现及时可靠通信的不可或缺的手段和方法。然而,纠错码的软判决技术却一直存在适用范围小、计算复杂度高等问题,现有技术条件下难以在合理有限的时间内得到较好的解决[1-2]。另外,一般的译码算法为串行处理,仅适合于低、中速的数字通信系统[3-4]。目前,数字通信和信息存储系统正朝着高速度、高带宽、高可靠性方向发展,这就对纠错码技术提出了新的要求,译码问题已成为纠错码发展的一大瓶颈。
Berlekamp等[3]证明了一般纠错码的译码问题是一类NP( Non-deterministic Polynomial)复杂问题,可等价为组合优化问题处理。智能算法(intelligent algorithm,IA)作为一种通过模仿自然世界的内在自适应优化机制获取解决复杂组合优化问题的信息的处理技术被引入到纠错码技术中[4-6]。利用智能算法的自适应优化以及快速并行处理等机理解决纠错码译码技术所面临的困难具有重要的理论意义与实用价值。
本文在传统硬判决的基础上提出一种基于遗传算法和神经网络智能算法的纠错译码方案,即遗传神经网络译码(GND)方案。GND方案继承了遗传算法的并行、自优化特性及神经网络的模式分类能力,在保证译码质量的基础上降低了传统软判决译码的复杂性,提高了译码速度。
2 遗传算法(GA)和神经网络(NN)
2.1 遗传算法
遗传算法(GA)是J.Hollnad受生物进化论启发而提出的一种基于“适者生存”自然法则的高度并行、随机和自适应的优化算法。它衍生于生物遗传进化机制,模拟基因重组与进化的自然过程,进行类似于自然选择、配对交叉和变异的运算,经过多次重复迭代(即世代遗传)得到最终优化结果[7-9]。遗传算法主要有以下特点:
1) 继承自然进化过程所固有的并行性,即同时有大量物种彼此独立地通过自然选择、交配和基因突变向前进化。这一特性使其可同时对搜索空间的多个解进行评估,极大地提升了解决问题的速度;
2) 采用概率变迁规则来指导搜索,使个体不断地改变,群体得以朝着最优方向演化,具有启发式搜索能力,解决问题质量高;
3) 采用自然进化机制来表现复杂现象,能够快速可靠地求解非常困难的问题。
遗传算法解决优化问题时,需要依据具体问题设定GA参数,这些参数包括种群中个体的数量、交叉概率、变异概率、遗传代数。
2.2 神经网络
神经网络擅长从复杂或不精确的数据中提取有意义的信息,可用来提取复杂的模式和检测人类或其他计算机技术难以发现的趋势。基于一定的学习算法,神经网络在学习过程中根据环境产生的数据对调整网络的状态。学习算法描述了神经网络如何根据训练数据对网络的状态进行调整[10]。当给定输入时,受过训练的神经网络可以提供与目标结果非常相似的预测。神经网络的特点包括[11-12]:
1) 自适应学习:可以从给定的初始训练或经验数据中学习如何完成任务。
2) 自组织:神经网络可以自行构建自己的结构或在学习过程中自行展示接收的信息。
3) 实时操作:人工神经网络计算可以并行运行,特殊的硬件设备在设计和制作时都可以利用这种能力。
4) 容错性:一个网络的局部破坏会导致相应的性能退化。然而,神经网络即使主要部分受到损伤,网络的一些能力仍可使用。
3 GND译码方案
本文对遗传算法与神经网络算法进行了融合,提出一种基于遗传算法和神经网络智能算法的纠错译码方案,即遗传神经网络译码(GND)方案。在GND译码方案中,将神经网络作为对遗传算法优化性能的补充加入遗传算法的个体适应度评估机制中,如图1所示。以分组码(n,k)为例,在适应度评估机制中,神经网络充当一个模式分类器的角色,它根据遗传算法个体所代表的码字与最近可用码字之间的汉明距离对遗传个体进行分类,与最近码字之间汉明距离相同的遗传个体被分为一类。这一操作利用译码标准阵中码字校正子与陪集首之间的一一对应关系,通过神经网络将输入的遗传个体的校正子序列映射为与之对应的陪集首的重量(陪集首的重量)来实现。神经网络得到的结果作为补偿因子加入遗传算法的评价机制中,以进一步加强遗传算法的优化性能。

图1 GND算法流程
3.1 译码方案模型
以分组码(n,k)为例, GND译码的实现过程如下:
1) 训练神经网络:GND译码中需要用到的神经网络如图2所示,其作为一个分类器由3层网络构成,即输入层、隐含层和输出层。输入层由n-k个神经元组成,输出层有1个神经元,隐含层包括(2/3)(n-k+t+1)个神经元,其中k为码的信息位个数,t为该码的最大纠错个数。这一操作按照以下步骤实现:将校正子序列作为输入训练模式,与其对应的错误模式的重量w作为目标输出,使之输入一个校正子便能得到对应的错误图样的重量w(w=1,2,3…,n),校正子S可以根据遗传算法个体所代表的码字R和码的校验矩阵H得到,即:
S=R·H′
(1)
根据最小距离译码准则和标准阵理论可知:码字与最近可用码字之间的汉明距离越大,则标准阵中其所对应的的陪首集重量越大,即可能含有的错误比特数越多,将其对应校正子作为输入的神经网络的输出值也越大。

图2 神经网络分类器
2) 使用遗传算法优化得到一个与传输序列更似然的码字:
步骤1种群初始化:生成2t个n位的二进制向量作为初始种群。
对于种群的第1个个体成员P1:将匹配滤波器输出的硬判决序列R(r1,r2,…,rn)设置为种群的第1个个体。
(2)
其中:Q(q1,q2,…,qn)为接收到的未经匹配滤波器硬判决量化的实数序列。
对于种群的其他2t-1个个体成员Pi:将由随机产生的均匀二进制修正序列T(t1,t2,…,t2t-1)和硬判决序列R相加得到,即
Pi=mod(R+T,2), 2≤i≤2t
T=rand[0,1]
(3)
步骤2个体适应度评价:
对遗传算法个体的适应度进行评价
(4)
其中:λ(P,Q)为相关函数,用来计算遗传体Pi和接收实数序列Q之间的欧氏距离。个体与接收的实属序列越相似,则λ的值越大。
(5)
Weight(Error class(Indiv.)) 为神经网络的输出结果,它作为一个补偿因子,代表遗传个体所对应码字的最可能的错误图样的重量。遗传个体所含错误比特数越少,Weight(Error class(Indiv.))的值就越小,最终fitness的值就会越大。要得到penalty,需要先利用式(1)计算待评估遗传个体的校正子序列S,再将S输入神经网络。
步骤3自然选择:基于轮盘赌选择法或其他选择方法从初始种群中选择优秀的个体参与遗传,个体被选择参与遗传的概率由其适应度决定。适应度越高,被选中的概率越大。一般地,第i个个体被选中的概率为
(6)
步骤4配对交叉:被选中的个体将随机进行配对,通过将自身部分元素(码元)与对方交叉产生新个体。配对交叉的方法有多种,最常见的有单点交叉和多点交叉。本研究中选择单点交叉,交叉概率设为0.9。
步骤5遗传变异:针对随机选择过程d中产生的新个体,对其进行变异处理(将个体的某位元素(码元)翻转,即由0→1或1→0),本研究中的变异概率设置为0.025。
步骤6遗传终止:遗传将在遗传世代数达到预设值时终止,此时种群中适应度最高的个体将被输出;若未达到预设值则跳转步骤1继续遗传过程,本研究中遗传世代数设置为20。
3) 将遗传算法输出的最佳序列输入硬判决纠错译码器进行译码,得到最终译码结果。
3.2 GND译码性能分析
3.2.1算法复杂度分析
GND算法的计算开销主要包括遗传算法模块的优化、神经网络的分类和硬判决译码器的纠错,其中遗传算法模块所占比例最大。就神经网络部分而言,只要网络被训练好,在其使用模式时只需简单的加乘法和权累加运算,计算开销非常小。本研究按照整个译码过程中所需的加法和乘法计算量对译码算法的复杂度进行评估。以线性分组码BCH(n,k,dh,t)为例,其中dh为分组码的最小汉明距离,t为分组码的最大纠错个数。
1) 遗传算法优化模块:遗传算法需要进行gen代遗传,每代中有2(dh/2-1)个个体需要被处理,每次处理将执行(n-1)次加法和n次乘法,最终需要执行2(dh/2-1)·gen·(n-1)次加法操作和2(dh/2-1)·gen·n次乘法操作;
2) 神经网络分类模块:本研究中的神经网络分类器共有(2/3)(n-k+t+1)个隐单元。一个已经训练好的神经网络在使用模式时,每个隐单元需执行(n-k-1)次加法和(n-k)次乘法,输出单元执行(2/3)(n-k+t+1)-1次加法和(2/3)(n-k+t+1)次乘法。因此,对于一个输入,在整个译码过程中,神经网模块需进行{(2/3)(n-k+t+1)+n-k-2}·gen·2t次加法运算以及{(2/3)(n-k+t+1)+n-k}·gen·2t次乘法运算。
3) 硬判决译码器模块:以BCH的BM译码算法为例,其每次硬判决译码需要执行(2nt+2t2-t)次加法运算和(2nt+2t2)次乘法运算。
若将硬判决量化视为加法运算,则GND算法与Chase2、GPD算法复杂度对比情况见表1。以BCH(31,16,7,3)码为例,采用GND译码的复杂度见表2。表2中还给出了传统软判决译码Chase2和文献[13]的一种基于遗传算法的GPD译码方案的复杂度对比。
分析表2数据可知:3种译码中GND译码的计算开销量最小,其次是GPD译码,软判决Chase2的计算量最大。这是由于在译码过程中,Chase2和GPD算法利用额外的软信息产生候选序列,而GND直接对解调器的滤波器输出进行处理,不借用软信息生成候选空间。由此可看出:GND算法是一种复杂度相对较低,可操作性强的译码方法。

表1 GND算法与Chase2、GPD算法复杂度对比情况

表2 BCH(31,16)的GND算法与Chase2、GPD算法复杂度对比情况
3.2.2误比特性能分析
本文在仿真模拟时使用BCH(31,16)作为译码对象,参数设置见表3。为进行性能对比,同时模拟了MLD最佳译码算法。文献[13]中的GPD译码、Chase2软判决译码以及BM硬判决译码的误比特性能见图3。图3中,R代表接收调制器的匹配滤波器输出,BER表示误码率,SNR(dB)表示信噪比。

表3 默认参数值
分析图3可知:各种译码算法通过对解调器的匹配滤波器输出结果R采取不同的处理方法都能不同程度地降低接收序列的误码率。例如,图3中误码率为10-4时,BM硬判决译码在匹配滤波器的输出结果基础上可多获得约1.5 dB的增益,GND算法约为2 dB, Chase2算法约为2.4 dB,GPD译码约为2.6 dB,MLD译码约为3.8 dB。由此可知:GND译码拥有较好的纠错性能,接近传统的软判决译码。GND译码虽然不如Chase2和文献[11]中的GPD算法获得的增益大,但如前文分析,由于不需要利用信道统计概率软信息生成搜索空间,GND算法复杂度相对Chase2软译码和GPD译码降低很多,其实用性更强。综合来看,GND算法在译码复杂度和译码纠错性之间取得了较好的折衷,是一种优异的新型译码方法。
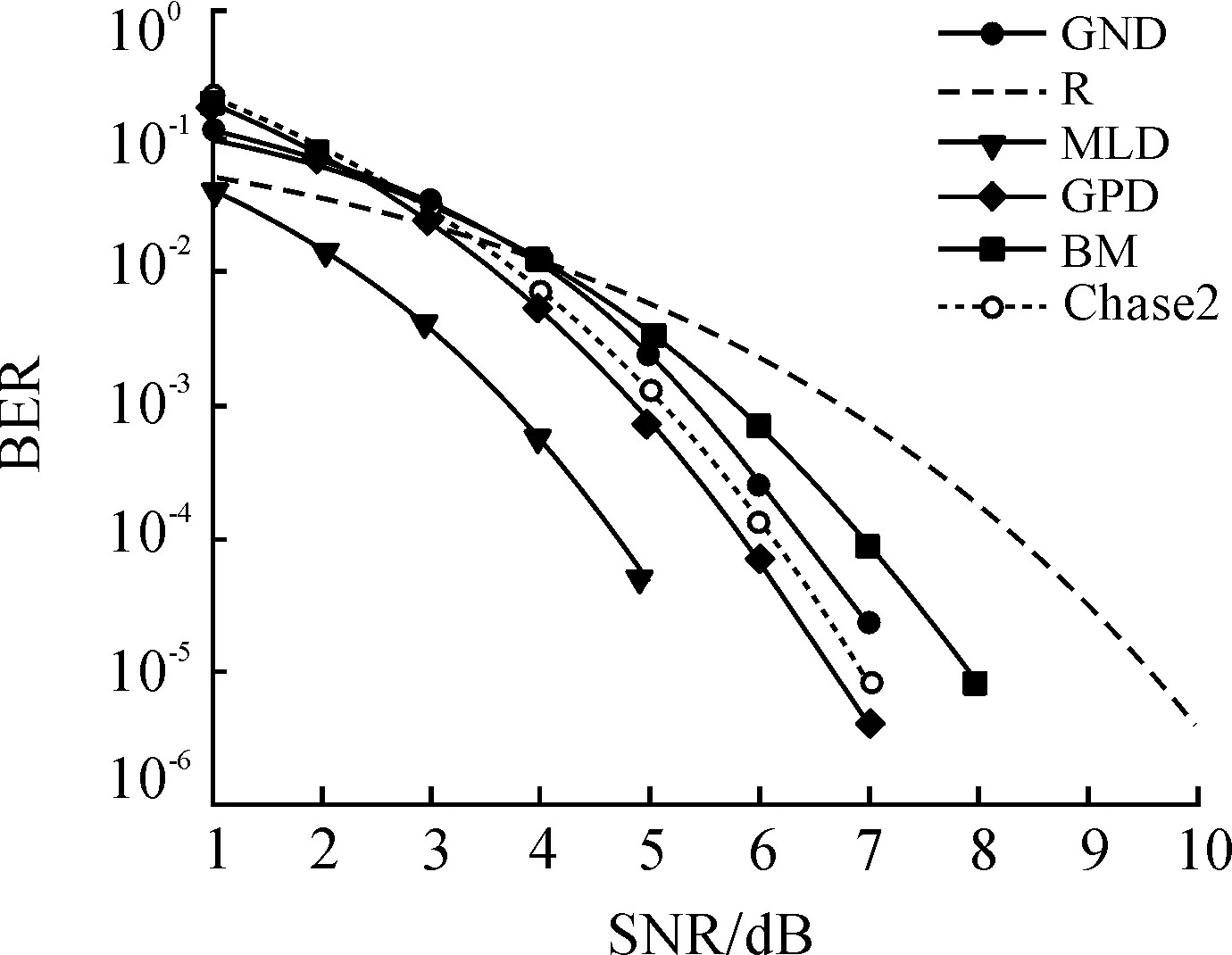
图3 GND译码算法性能仿真结果
4 结束语
本文提出了一种基于遗传算法和神经网络的纠错码硬判决译码(GND)方案。GND译码方案在传统硬判决译码器的基础上利用引入神经网络的遗传算法对解调器的匹配滤波器的硬判决输出序列做进一步优化,恢复出可信性较高的传输信息,从而提高硬判决译码器的纠错性能。由理论分析与仿真结果可知:本文提出的GND算法是一种译码复杂度较低、纠错性能较好和实用性较强的译码方案。
