基于多种空间信息的高光谱遥感图像分类方法
2019-05-23
哈尔滨工程大学 计算机科学与技术学院 哈尔滨 150001
在高光谱影像分类中,如果仅使用光谱特征而未考虑空间信息,会使得分类精度较低,与实际地表覆盖的连续性分布不相符。引入像素的空间信息,能够对原始图像数据进行更充分的挖掘和利用,获得空间连续性较好且精度较高的分类结果。光谱-空间特征相结合已成为当前高光谱遥感图像分类的研究热点之一[1-2]。空谱分类的关键性问题在于如何提取纹理、形状、对象、语义等空间信息,以及如何有效地融合光谱信息与空间特征[3-4]。
高光谱图像分类中常用的空间信息主要分为纹理信息、数学形态学信息和邻域信息3种。对于这3种空间信息的利用主要有两种形式。第一种形式把空间信息表示成特征向量,然后和光谱特征向量融合组成新的特征,再进行分类。这种形式主要利用纹理信息和数学形态学信息[5-7]。文献[5]提出了一种基于局部图的特征融合方法,将光谱信息和优化后的图像特征融合起来进行分类。文献[6]采用SC-MK算法对高光谱图像的过分割区域使用多核分类器分别对光谱信息和空间信息进行利用。也有研究者提出基于LBP的局部图像特征提取框架,用于高光谱图像分类,提取了Gobar特征和光谱特征进行融合。还有一些方法对用于学习图像进行非监督分层稀疏表示提取特征,并输入到分类器中进行分类[8]。第二种利用空间信息的方式是先进行分类,然后再用空间信息对分类结果进行优化。这种形式被称为后处理,一般利用的是图像的邻域信息[9-10]。以上这两种形式也可以结合在一起用来提高分类精度。
总的来说,高光谱图像分类多采用光谱特征和空间特征,再利用支持向量机等方法进行分类[11]。目前的高光谱图像空谱分类中,通常是利用某一种空间特征和一种光谱特征进行融合,然后进行分类,接着利用超像素分割结果带有的邻域信息对分类结果进行改善。这种方法能够在一定程度上取得不错的分类效果,但是存在一定的不足。首先,高光谱数据所含信息丰富,一种空间特征只能从一种角度去表达空间信息,并不能完整对图像的空间信息进行描述,这导致高光谱数据的信息利用率仍然较低。第二,在后处理阶段目前常用的做法是通过统计分类结果中每个超像素块区域包含的相同标签数目进行投票来确定。这种做法以超像素块作为单位对空间邻域信息进行利用,仍存在大量未达到投票阈值的像素并没有受到空间邻域信息的影响,空间信息利用率不高。
针对以上两点不足,本文提出一种新型的结合多种空间信息的高光谱遥感图像分类方法。为了解决单一特征描述能力的不足,本方法从纹理特征和数学形态学特征中各选一种具有代表性的特征和光谱特征进行融合,以提高特征的信息承载能力,为此,提出了一种自适应的特征融合方法,提高新特征的鲁棒性。为了解决后处理中超像素邻域信息利用不充分的问题,本方法利用超像素邻域信息对融合后的新特征进行指导和校正,让每个像素都能利用到超像素信息。
本文采用总体的分类精度(Overall Accuracy , OA)和Kappa系数作为识别精度的评价指标[12-13],对Indian Pines图像,Salinas图像进行验证。试验结果表明,多种空间特征融合的效果优于单一空间特征,用超像素信息进行特征校正的方法的效果优于用超像素信息进行后处理的方法。
1 空间特征提取与融合
1.1 差分形态学特征
开运算和闭运算是最基本的形态学操作。这两个操作以结构元素(Structuring Elements,SE)为基础去掉亮的或暗的细节,保留相对稳定的全局特征。此外,形态学操作能够较好地保存形状信息而不引入噪声,随着结构元素尺度的变化,则会产生不同的形态学操作。
形态学剖面(Morphological Profiles,MP)是由一系列形态学操作构成的。对于图像I,假设OPSE(I)和CLSE(I)为使用SE元素的开操作和闭操作,则开运算和闭运算下的MP定义如下:
(1)
式中:λ为SE结构元素的半径。图像I进行一次开运算,得到图像I′,I′的每个像素点的值表示图像I对应像素点的一个特征值,用不同半径的SE结构进行开运算就会得到不同的SE操作下的特征值,闭运算同理。随着元素半径的逐步增加,开运算和闭运算下MP的差分DMP定义如下:
∀λ∈[1,n]}
∀λ∈[1,n]}(2)
通常将DMPOP和DMPCL串联构成一个新的向量DMP=[DMPOP,DMPCL]来表示图像的明暗纹理特征。对于高光谱图像,不同的层或降维后的不同层均可以提取DMP特征[13]。
1.2 Gabor特征
Gabor特征是一种纹理特征。因为纹理是由很多微小的纹理基元组合而成的,在纹理特征提取时应该着重考虑纹理的这些局部特征,所以现有的单层图像纹理特征提取方法一般都基于窗口滤波的方法。即用一个大小固定的窗口在单层的图像上移动,用这个窗口内除中心点以外的所有像素值的线性或者非线性组合来替换掉窗口中心点像素的值。窗口在整个图像上按像素点依次移动计算,就能够计算出图像中所有像素点的纹理特征。
用Gabor滤波器提取图像纹理特征时,和所有滤波器一样,用一个窗口在单层图像上移动进行卷积运算更新单层图像像素的值。Gabor滤波器窗口模板是由Gabor核决定的,二维Gabor核函数如下:
(3)
式中:λ为波长;θ为方向;ψ为相位偏移;γ为空间纵横比;b为带宽;σ为Gabor函数的高斯因子的标准差。 Gabor核根据不同的尺度和方向有不同的选择,并且每种核函数用于滤波都能提取到不同的纹理信息。在实际的应用中,一般选择5方向和8个尺度总共40个核函数对图像的一个波段进行滤波,每个像素能得到一个40维的纹理特征。
1.3 多种特征融合
为了提高特征的鲁棒性,本文用多种空间特征进行融合,以差分形态学特征提取方法为基准,根据目标图片自适应的找出近似最优差分形态学特征,然后再融合固定的Gabor特征和光谱特征。
差分形态学特征分类精度和不同大小的结构元素SE的数量息息相关,如果不同大小的结构元素SE的数量越多,则差分形态学特征的维数越大。令SE的数量为m,差分形态学特征的维数为d,两者关系为d=2(m-1)。
不同维数的差分形态学特征最终的分类精度不同,为了选择最优维数的差分形态学特征,算法对不同维数的差分形态学特征的分类精度进行比较,选择最优精度的特征作为最优解。
算法用正方形作为结构元素,第i个结构元素的边长li定义如下:
li=3+2(i-1)(4)
如果结构元素的边长大于目标图像的最短边长,这样的结构元素是没有意义的。本算法用不同数量的结构元素提取差分形态学特征,然后进行取优。不同结构的数量不超过目标图像最短边长的一半。
目前Gabor滤波器提取特征一般都是取5个方向8个尺度共计40个核函数进行滤波处理,故本文也是采用40维的Gabor特征。首先对原始高光谱图像进行PCA降维处理,对第一主成分进行Gabor滤波,得到一个40维的Gabor特征向量。因为根据经验,光谱特征的识别精度比Gabor特征差,所以本文光谱特征的维数取Gabor特征的一半。
综上所述,本文提出的多种特征之间的融合方法具体步骤如下:
第1步:根据输入图像的最短边长,计算出最多能用多少个结构元素SE进行差分形态学特征提取。
第2步:用5个SE提取的特征进行分类,用10个SE提取的特征进行分类等等,每增加5个SE进行一次分类,一直到SE元素数量达到最大。
第3步:按步骤2选择出最优差分形态学特征之后,把它和40维的Gabor特征、20维的光谱特征进行横向融合,得到整个的融合特征向量。需要注意的是其中每一种特征都需要做数据归一化,最后整个的融合特征向量需要再次归一化。
2 方法介绍
2.1 超像素分割
在遥感领域,根据地理学第一定律可知,相邻的像素之间表示同一种事物的可能性远大于不相邻的像素,这种领域的空间信息在很多应用上都有指导性的用途,而把图像分割成很多包含相似视觉特征的超像素块,恰好能很好描述这种信息。所以超像素分割越来越多的应用在图像处理过程中,如图像分割、目标定位和物体识别等。
简单线性迭代算法(Simple Linear Iterative Clustering,SLIC)[14]是一种简单、快速的超像素生成算法,能够生成紧凑近似均匀的超像素块。SLIC算法不仅可以分割彩色图像,同时也兼容分割灰度图像,而且在使用上也很方便,只需要设置很少的参数。SLIC的基本思想是K-means聚类,把特征相似的像素的归为一类。但是和K-means不同的是,SLIC在聚类中加入空间位置的限制。
SLIC算法需要指定一个描述超像素块紧密程度的参数。如果这个参数越大,超像素块边界越平滑,此时超像素形状趋近圆形;如果参数值越小,部分超像素块的形状就会趋于扁平,并且边界中会出现一些比较尖锐的角。对于图像中纹理比较复杂的区域,超像素的边界一般都比较尖锐,并且有很多长条形的超像素出现,此时需要一个比较大的参数值让这些超像素趋于平滑;而对于图像中纹理比较简单的区域,超像素超像素块一般比较圆润,此时需要一个比较小的紧密度参数,让超像素的边界尖锐一些,更好地去描绘图像的纹理信息。如果根据经验来确定这个参数的大小,得到一个合理的值是很困难的,SLICO是SLIC超像素分割算法的改进算法,算法根据不同区域的纹理复杂度自动选择一个合适的参数值,使图像中的超像素块更加规整统一,能够避免形状不规则导致的分割效果偏差。
2.2 超像素信息融合
超像素领域信息是一种重要的空间信息,目前文献中一般利用超像素信息对分类结果进行后处理操作。具体操作是统计一个超像素中像素的标签,如果相同标签的数量占整个超像素块总像素数量的比例大于一定的值,则把超像素块中的所有像素标签统一。这种按照超像素为单位的校正方法不能很好地把超像素信息利用到每个像素。本文通过把超像素信息和用于分类的特征进行融合,让超像素信息能够对每个像素都进行指导,具体做法如图1所示,可描述为如下步骤:
第1步:按照超像素块的位置,计算每一个超像素区域的高光谱特征均值。把超像素块区域的特征看成向量集合xl={xn∈Rc,n=1,2,…,Nl},l=1,2,…,N,N为总的超像素块的个数。Nl为第l个超像素块中像素点的个数。第l个超像素块区域特征均值计算如下:
(5)
(6)
式中:α为权系数,根据经验值调整。

图1 特征“平滑移动”示意Fig.1 Illustration chart of feature translation
平滑移动算法把超像素信息融入高光谱的每个像素特征向量中去,提高了分类结果的精度,使得分类结果中每个像素标签的置信度都有所提高。此时,如果一个超像素块区域中含有大量具有相同标签的像素,则这个超像素块中,其他类别标签的像素属于误标像素的概率就高于平滑移动之前的误标概率。
2.3 本文高光谱图像分类算法描述
图2展示了融合SLICO空间信息的多特征融合分类算法的框架。具体的算法步骤描述如下:
第1步,将高光谱图像降为20维。
第2步,用光谱第一层主成份提取Gabor特征。取前20层主成份作为光谱特征。
第3步,按第1.3节介绍的方法选择最优差分形态学特征。
第4步,把最优差分形态学特征与Gabor特征和光谱特征进行横向融合,得到融合后的特征向量。
第5步,用SLICO算法对光谱的前3个主成份进行超像素分割。
第6步,超像素信息和所提取特征按第2.2节的算法进行融合。
第7步,用融合了超像素信息的新特征进行分类,并且把分类结果和第3步得到的最优差分形态学特征的分类结果进行比较,选择较优的结果作为算法的输出结果。
第8步,用超像素信息对第7步得到的最优结果进行后处理。
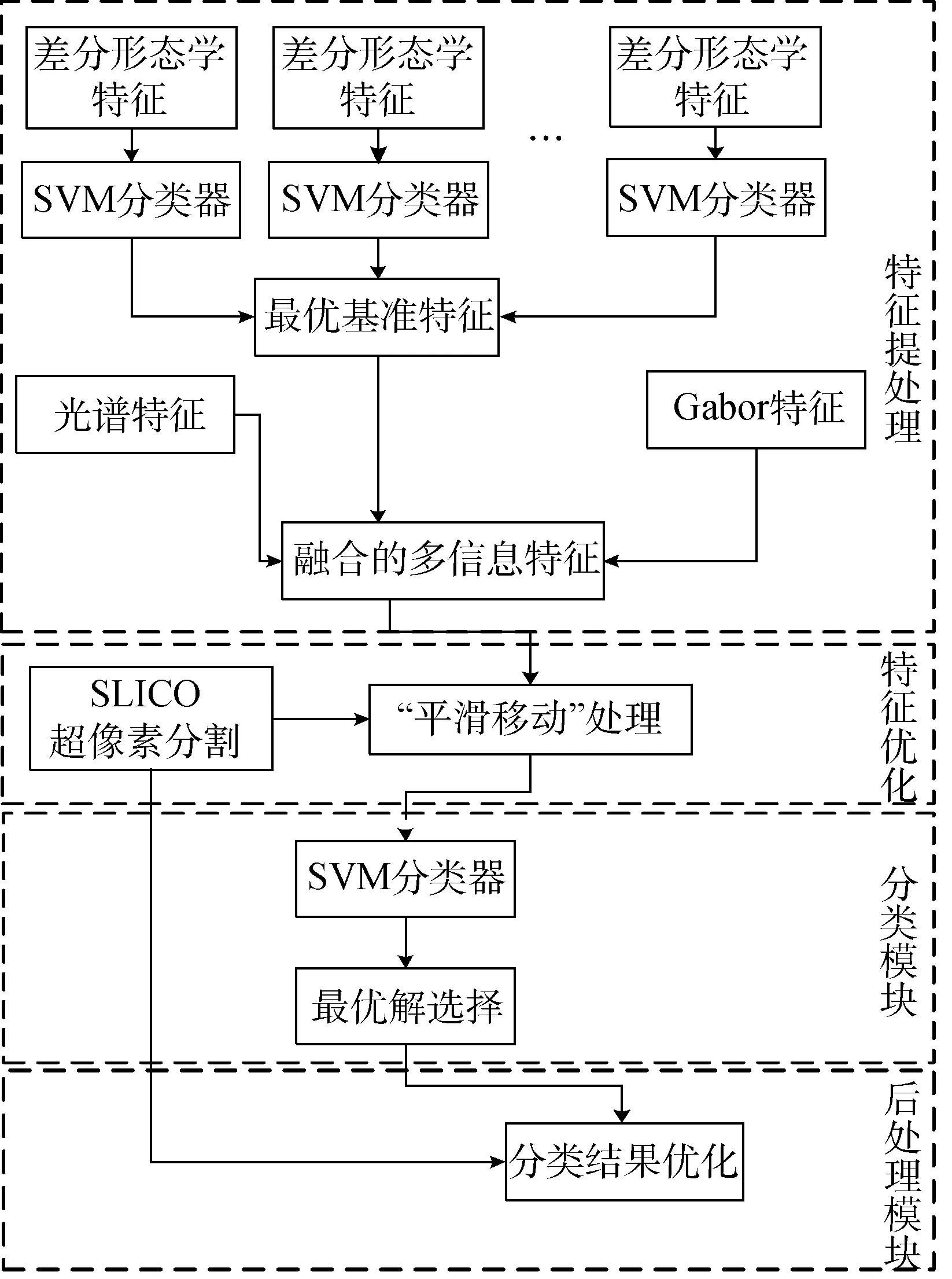
图2 多特征融合分类算法框架Fig.2 Illustration chart of multi-feature fusion classification
因为遥感图像的复杂多变性,多特征融合可能产生精度低于最优差分形态学特征进行分类的精度。为了避免这种情况,在第7步时对两者结果进行比较,选择最优解进行下述后处理。在第8步中再次利用SLICO超像素信息,根据超像素块中各个像素点类别标签的分布对分类结果进行纠正。
3 试验结果
3.1 试验数据集
本文用Indian Pines图像进行试验验证。印第安农林数据集来自光谱仪Airbome Visible Infra-Red Imaging Spectrometer(AVIRIS),是1992年在印第安纳州西北部印第安农林收集到的高光谱遥感图像,具有20m的空间分辨率,包含144×144个像元,220个波段。由于噪声和水吸收等因素除去其中的20个波段,剩余200个波段,包含16种植被,具体地物类别和样本个数见表1,样本总数10 366。

表1 Indian Pines图像每种类别的样本数
3.2 评价指标
在机器学习分类器的评价中,一般都需要输出分类任务的混淆矩阵M:
(7)
式中:c为分类任务中类别个数。混淆矩阵的每一列代表了预测类别,每一列的总数表示预测为该类别样本的数目;每一行代表了样本的真实归属类别,每一行的样本总数表示该类别的样本实例的数目。所以mij表示实际上为第i类且预测为第j类的样本的数量。
通过混淆矩阵,可以得到很多分类信息,但缺点是不直观,在评价分类器性能时一般都是利用混淆矩阵中的数据计算出一些相对比较直观的数据进行评价。在高光谱分类任务中,如果没有特殊的任务需求,一般只关注分类的整体效果,不需要对一个特定的类别进行着重观察,所以本文采取其中一个评价标准,即总体分类精度:
(8)
式中:N为所有测试样本数量;mii为正确分类的样本个数。
总体分类精度OA可以描述分类结果的整体性能,但在类别不平衡的情况下,OA有一定的局限性,比如一个样本数量很少的类别,即使这个类别的所有样本错分,对OA的影响也很小。为此,本文中增加了另一个评价标准——Kappa系数:
式中:mi+为第i行的总观测数;m+i为第i列的总观测数。
在统计学中Kappa系数是用来度量两个被观测对象的一致程度,在高光谱分类中则用来度量样本预测值和真实值之间的一致程度。Kappa值的取值在0~1之间,Kappa系数的值越大,说明预测结果和真实结果越接近,反之则说明预测结果和真实结果相差越大,分类效果则越差[15-17]。
3.3 试验结果
为了验证本文算法的有效性,分3个部分进行验证。
(1)单一特征分类方法和本文方法的对比
为了验证多特征融合的有效性,本节把只用Gabor特征、只用差分形态学特征和只用光谱特征的分类结果的OA和Kappa系数和本文方法的分类结果的OA和Kappa系数进行比较。试验使用Indian Pines图像,每一类训练样本抽取总体样本的5%,且不少于10个样本。为了排除干扰,本节所有试验都不融合超像素信息,且不进行后处理操作。
表2展示了不同的差分形态学特征的分类的OA和Kappa系数。Indian Pines图像大小为145×145×200像素,而第40个结构元素的边长为83像素,长度已经大于Indian Pines图像最短边长的一半,所以结构元素取到35是合理的。结构元素数量取10的时候,所得到的差分形态学特征取的分类结果OA和Kappa同时达到最大,分别为0.951 765和0.945 01。
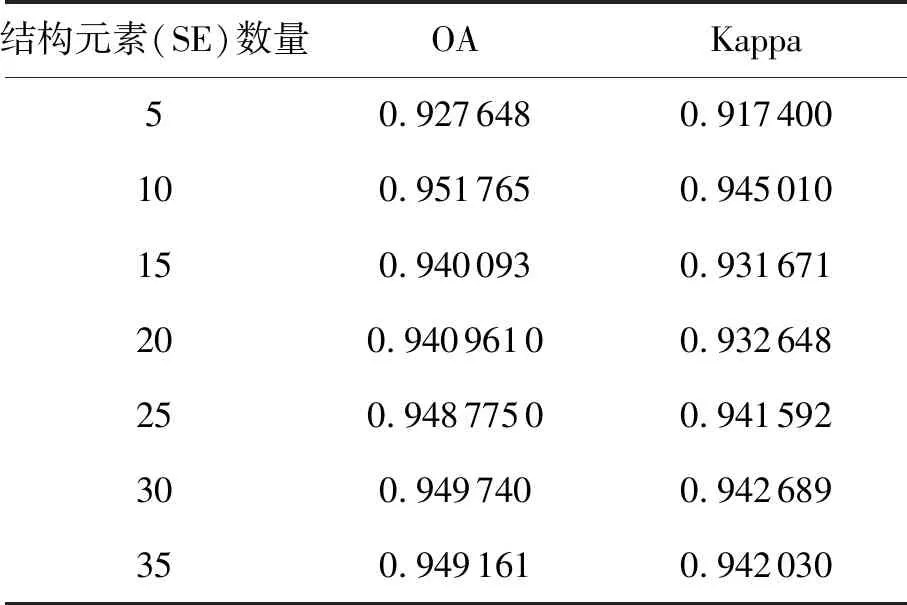
表2 Indian Pines图像不同差分形态学特征的分类结果
表3给出了Indian Pines图像不同特征的试验数据,融合特征的OA和Kappa经过Gabor特征和光谱特征的修正,比表2中最优的差分形态学特征的OA和Kappa都有了提高。
图3展示了Indian Pines图像的不同特征的分类效果。图3(a)为只用40维光谱特征得到的分类结果,图中有大量的“椒盐噪点”,图3(b)为最优差分形态学特征得到的分类结果,整体效果较好,不同类别相邻的区域存在部分误分。图3(c)为只用Gabor特征得到的分类结果。图3(d)为用融合特征得到的结果图。图中标记了4个区域,正方形区域,椭圆区域,三角形区域和六边形区域。对于正方形区域,最优差分形态学特征的分类结果图3(b)有误分情况,通过Gabor特征图3(c)得到改正,使得融合特征图3(d)得到正确的结果。对于椭圆区域,图3(b)同样部分误分,通过Gabor特征和光谱特征得到改正。对于三角形区域,光谱特征对结果优化取到了很大的作用。对于六边形区域,图3(b)分类结果正确,Gabor特征和光谱特征的影响,融合特征图3(d)在这个区域上部分误分。

表3 Indian Pines图像融合特征的分类结果
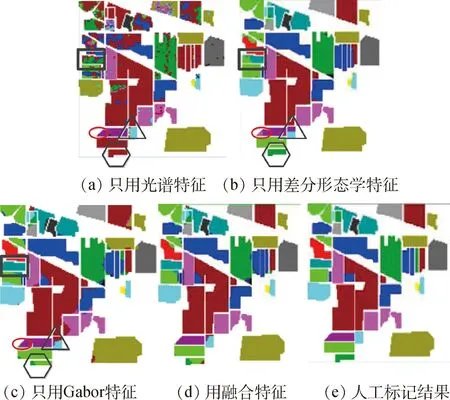
图3 Indian Pines图像不同特征的分类结果Fig.3 Classification result of different features of Indian Pines image
(2)特征和超像素信息融合的有效性验证
本节试验分别用Gabor特征,差分形态学、光谱特征和融合特征和超像素信息进行融合,然后用SVM进行分类。每一类样本取5%作为训练样本并且每一类训练样本至少取10个。Gabor特征维数取40维,光谱特征取20维,差分形态学取10个结构元素,即54维特征,融合特征为3者的横向融合。“平滑移动”比例系数α取0.7。
为了验证融合超像素的方法优于后处理的方法。对比试验设计为:用原始特征送入SVM分类进行分类,然后对结果进行后处理;特征融合超像素信息后送入SVM进行分类。训练样本、特征的选取和第一部试实验相同。表4为两种方法的对比结果,可以很明显地看出对于所有的特征,融合超像素信息的方法均优于后处理的方法。
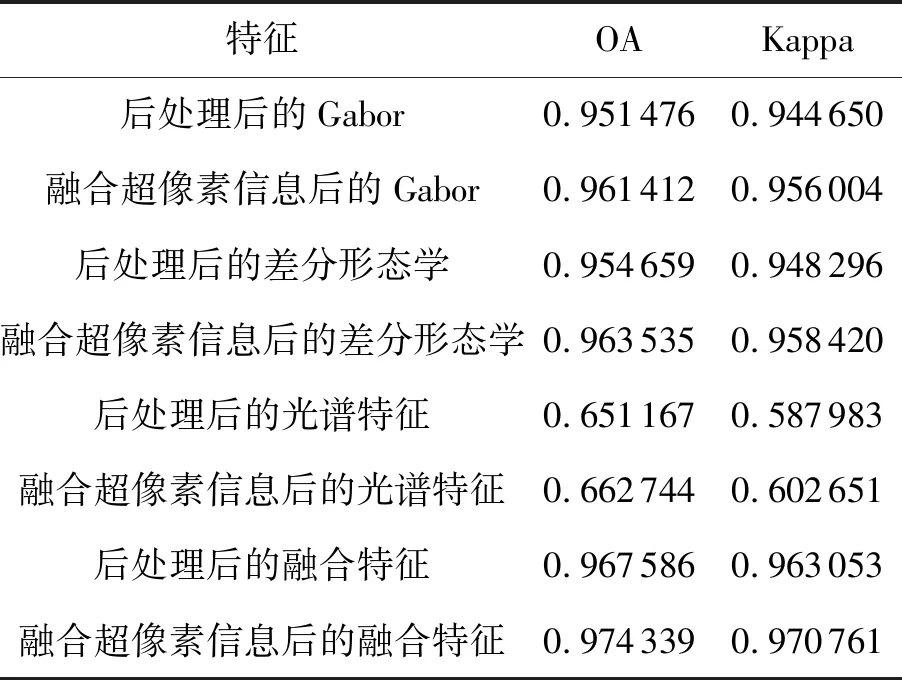
表4 融合超像素信息的分类结果
(3)和现有的空谱分类方法进行对比
选用了4个近年来提出的具有代表性的方法和本文算法进行了比较。对比方法为DTBS-SVM[18], BS-SVM[19], NLGD-SVM[20]和FS-SMLRSSAMRF[21]。4种方法都用Indian Pines图像进行了试验。训练样本取5%。表5给出了Indian Pines图像上不同方法的试验数据,从表中可以看出,无论OA还是Kappa,本算法都优于其他算法。
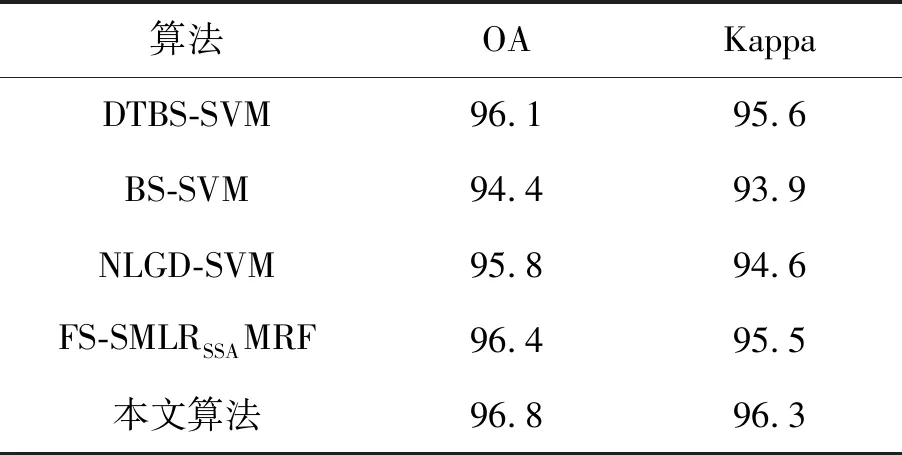
表5 Indian Pines图像不同分类方法结果对比
4 结束语
本文提出了一种结合多种空间特征的高光谱分类方法。光谱特征、差分形态学特征和Gabor特征融合得到的新特征的分类结果并不一定优于其中一种特征分类结果的最优值,因此本文将最优差分形态学特征与Gabor特征和光谱特征融合,分类结果与最优差分形态学特征的结果进行比较,输出较优的分类结果。通过试验证明了该方法的有效性,评价指标OA和Kappa均有一定的提升。同时提出了一种用超像素信息对特征进行“平滑移动”的后处理方法,把超像素信息融入到每个像素特征向量中。进一步的研究方向是加深对特征融合的理解和研究,自适应地控制调节纹理特征和光谱特征的比例等。
